
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Los Grandes Modelos Lingüísticos (LLM) han cobrado gran importancia en el desarrollo de modelos de aprendizaje automático, sobre todo para mejorar las capacidades de los algoritmos de procesamiento del lenguaje natural. Desde los chatbots a los generadores de contenidos, estos modelos transforman la forma en que interactuamos con la tecnología.
Sin embargo, a medida que la presencia de LLM crece en número y complejidad, la evaluación de su rendimiento adquiere mayor importancia. Sin una evaluación adecuada y precisa, saber si un modelo funciona como se espera o necesita ajustes es todo un reto.
Aquí es donde entra en juego MLflow. MLflow es una herramienta de código abierto diseñada para facilitar la gestión de experimentos de aprendizaje automático. Nos ayuda a hacer un seguimiento de los resultados de los distintos experimentos, a gestionar los modelos y a mantenerlo todo organizado.
En este tutorial, exploraremos el papel de MLflow en la mejora de los flujos de trabajo LLM. Te guiaré a través de su configuración y te mostraré cómo registrar métricas y seguir parámetros en experimentos LLM. Por último, veremos cómo MLflow apoya la gestión y el despliegue eficaces de los modelos.
MLflow es una plataforma de código abierto diseñada para gestionar el ciclo de vida integral del aprendizaje automático. Proporciona herramientas para agilizar el proceso de desarrollo, seguimiento y despliegue de modelos de aprendizaje automático.
Tanto si trabajamos en un pequeño proyecto como si gestionamos experimentos complejos con grandes modelos, MLflow puede ayudarnos a mantenernos organizados y eficientes.
Algunas de las ventajas de utilizar MLflow en el ciclo de vida del aprendizaje automático son:
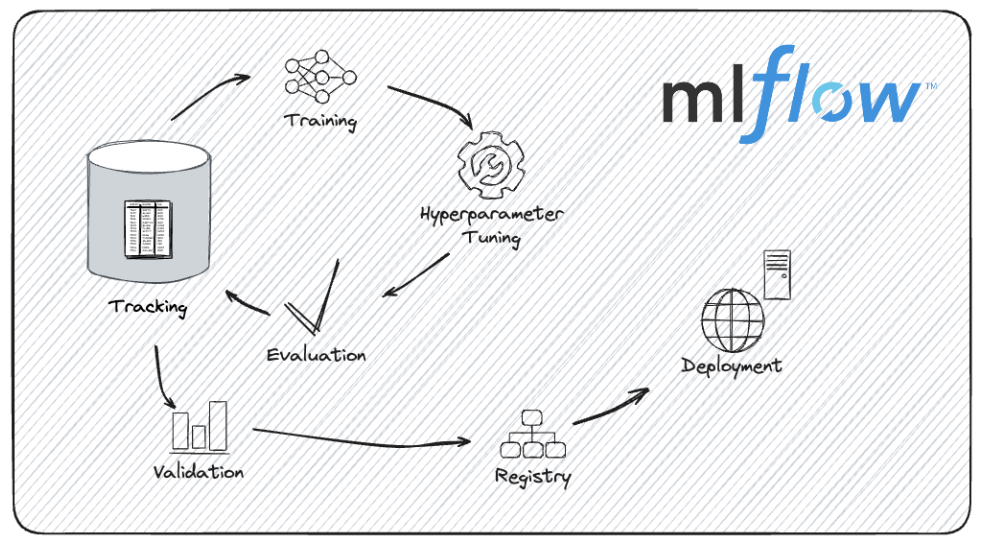
El ciclo de vida del desarrollo de modelos con MLflow. Fuente de la imagen: Documentación de MLflow.
MLflow está diseñado para que la gestión de proyectos de aprendizaje automático sea más sencilla y transparente. Esto es especialmente útil cuando se trabaja con modelos complejos como los LLM, como veremos ahora.
Utilizar MLflow para la evaluación LLM tiene varias ventajas, como el seguimiento de las versiones del modelo, el registro de las métricas de evaluación y la comparación del rendimiento entre campos.
Veamos estas ventajas con más detalle.
El desarrollo de los LLM implica iteraciones y mejoras frecuentes. Cada nueva versión aporta pequeñas mejoras o cambios de comportamiento. MLflow gestiona estas diferentes iteraciones haciendo un seguimiento sistemático de las versiones del modelo. Esta capacidad nos permite reproducir resultados, comparar distintas versiones de forma eficaz y mantener un historial claro de la evolución del modelo.
Digamos que estamos experimentando con distintas técnicas de ajuste; MLflow puede ayudarnos a gestionar y revisar los resultados de cada versión, facilitando la identificación de la iteración que produce el mejor rendimiento.
Como MLflow garantiza que cada experimento y sus resultados asociados se registran exhaustivamente, podemos compartir con confianza nuestros descubrimientos, sabiendo que otros pueden reproducir exactamente nuestros resultados.
Si nuestro proyecto implica experimentar con diferentes arquitecturas LLM o metodologías de entrenamiento, las capacidades de seguimiento de MLflow harán que documentar y compartir nuestro trabajo sea más fácil.
Evaluar los LLM implica controlar varias métricas, como la precisión, la perplejidad y la puntuación F1, entre otras.
La funcionalidad de registro de MLflow nos permite registrar estas métricas de forma eficaz y organizada. El análisis de estas métricas nos da una buena idea del rendimiento de nuestro modelo.
Por ejemplo, podríamos querer comparar cómo afectan distintos hiperparámetros o conjuntos de datos de entrenamiento a las métricas de rendimiento del modelo. Con MLflow, podemos registrar y visualizar estas métricas para extraer información procesable.
A medida que los modelos se despliegan y utilizan en aplicaciones del mundo real, pueden experimentar una deriva del modelo, en la que su rendimiento se degrada debido a cambios en los datos o en el entorno. Podemos aprovechar MLflow para supervisar y gestionar la deriva del modelo mediante el seguimiento del rendimiento del modelo a lo largo del tiempo.
Podemos establecer evaluaciones periódicas y utilizar MLflow para registrar y analizar cómo cambian las métricas de rendimiento, tomando decisiones procesables en tiempo real.
Una de las ventajas más importantes de MLflow es su capacidad para simplificar las comparaciones exhaustivas de modelos. Al almacenar registros detallados de diferentes experimentos, MLflow nos permite comparar el rendimiento de varios LLM y configuraciones de hiperparámetros uno al lado del otro.
Encontrar los hiperparámetros correctos puede determinar el éxito de un modelo al desarrollar LLMs.
Imagina que estamos afinando un LLM y queremos evaluar el impacto de diferentes ajustes de los hiperparámetros. Utilizando MLFlow, podemos registrar y comparar los resultados de varias tasas de aprendizaje, tamaños de lote o tasas de abandono para determinar qué configuración produce el mejor rendimiento, optimizando nuestro proceso de desarrollo de modelos.
Las funcionalidades de registro y seguimiento de modelos de MLflow entran en juego cuando se evalúan múltiples LLM para su despliegue.
Supongamos que tenemos varias versiones de un modelo lingüístico que estamos considerando para un entorno de producción. MLflow puede ayudarnos a registrar las métricas de rendimiento de cada modelo, compararlas y tomar una decisión informada basada en pruebas empíricas y no sólo en la intuición.
Ahora que tenemos una idea más clara de MLflow y sus ventajas, ¡manos a la obra!
Aprende a trabajar con LLMs en Python directamente en tu navegador

Antes de evaluar los LLM con MLflow, necesitamos configurar la plataforma adecuadamente. Esto implica instalar MLflow, configurar opcionalmente un servidor de seguimiento para el registro remoto, y asegurarnos de que nuestro entorno está preparado para gestionar los experimentos y hacer un seguimiento de los resultados.
Veamos cómo hacerlo.
1. Asegúrate de que Python está instalado:
En primer lugar, tenemos que asegurarnos de que tenemos Python instalado en nuestra máquina. MLflow es compatible con Python 3.6 y superiores (ten en cuenta que Python 3.8 está obsoleto, por lo que se recomienda usar Python >= 3.9). Podemos comprobar nuestra versión de Python con:
python --version2. Crea un entorno virtual (opcional pero recomendable):
Es una buena práctica utilizar un entorno virtual al realizar experimentos con MLFlow, sobre todo si trabajamos con Mac OS X. Podemos crear uno utilizando venv o virtualenv.
python -m venv mlflow-envActivamos el entorno virtual:
On Windows:
mlflow-env\Scripts\activateEn Mac/Linux:
source mlflow-env/bin/activate3. Instala MLflow con pip:
Con el entorno virtual activado (si se utiliza), podemos instalar MLflow mediante pip:
pip install mlflow4. Instala dependencias adicionales:
MLflow tiene algunas dependencias opcionales para mejorar la funcionalidad. Si necesitamos utilizar funciones específicas, como la capacidad de servir modelos de MLflow, tenemos que instalar gunicorn.
pip install gunicornSi utilizamos bibliotecas como TensorFlow o PyTorch, puede que tengamos que instalar sus respectivas integraciones MLflow:
pip install mlflow[extras]4. Verifica la instalación:
A continuación, debemos asegurarnos de que MLflow está instalado correctamente comprobando su versión:
mlflow --versionSi trabajamos en un entorno colaborativo o si debemos realizar un registro remoto, debemosconfigurar un servidor de seguimiento MLflow. Esta función nos permite centralizar el seguimiento y la gestión de nuestros experimentos.
1. Ejecuta el servidor de seguimiento:
Podemos iniciar el servidor MLflow especificando el almacén backend y la ubicación del artefacto.
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlruns--backend-store-uri especifica dónde se almacenan los datos del experimento. Podemos utilizar cualquier sistema de bases de datos (PostgreSQL, MySQL, etc.).--default-artifact-root especifica el directorio donde se almacenan los artefactos, por ejemplo, los archivos del modelo.2. Configura el servidor de seguimiento:
Tenemos que asegurarnos de que nuestros clientes MLflow están configurados para iniciar sesión en el servidor de seguimiento. Podemos establecer la variable de entorno MLFLOW_TRACKING_URI para que apunte a nuestro servidor.
export MLFLOW_TRACKING_URI=http://localhost:50003. Accede a la IU de seguimiento:
Ahora podemos abrir un navegador web y navegara http://localhost:5000 para acceder a la interfaz de usuario de MLflow. Esta interfaz nos permite ver experimentos, comparar resultados y gestionar tus proyectos MLflow, como veremos más adelante.
Con MLflow configurado y listo, es hora de sumergirse en las tareas principales de cargar y evaluar los LLM. Veamos cómo podemos seleccionar un LLM preentrenado, cargarlo utilizando distintas bibliotecas y preparar un conjunto de datos de evaluación para medir el rendimiento del modelo.
A la hora de seleccionar un LLM preentrenado, las bibliotecas como Hugging Face Transformers ofrecen muchas opciones. Por ejemplo, podemos cargar un modelo preentrenado, como GPT (para generación de textos) o BERT (para clasificación de textos y otras tareas).
1. Instala transformadores de caras abrazables
En primer lugar, nos aseguraremos de tener instalada la biblioteca Transformers Cara Abrazada. Podemos conseguirlo utilizando pip.
pip install transformers2. Carga un modelo preentrenado y un tokenizador
Ahora, cargamos el modelo BERT utilizando la biblioteca transformers, incluyendo tanto el modelo como el tokenizador, que son necesarios para procesar el texto y generar predicciones.
from transformers import (
BertForSequenceClassification,
BertTokenizer
)
# Load pre-trained model and tokenizer
model_name = "textattack/bert-base-uncased-yelp-polarity"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)El modelo bert-base-uncased se utiliza cuando los datos de texto con los que trabajamos están mayoritariamente en minúsculas y mayúsculas, pero no necesitamos que el modelo diferencie entre palabras en mayúsculas y minúsculas.
Para evaluar un LLM, necesitamos un conjunto de datos adecuado que se ajuste a la tarea que estamos evaluando. Veamos cómo preparar un conjunto de datos de evaluación basado en texto para el análisis de sentimientos:
1. Carga o crea y preprocesa el conjunto de datos
Nuestros datos pueden almacenarse en varios lugares: en el disco de nuestra máquina local, en un repositorio de Github, o en The Hugging Face Hub, una extensa colección de conjuntos de datos de investigación populares y comisariados por la comunidad.
Para este tutorial, utilizaremos un gran conjunto de datos de críticas de películas para el análisis de sentimientosllamado IMDB. Utilizaremos la biblioteca datasets para cargar el conjunto de datos preconstruido:
Instalar la biblioteca de conjuntos de datos:
pip install datasetsCargar un conjunto de datos:
from datasets import load_dataset
# Load the dataset IMDb for sentiment analysis
dataset = load_dataset("imdb")2. Preprocesamiento para el análisis de sentimientos
Utilizaremos el tokenizador BERT previamente cargado para preprocesar el conjunto de datos para el análisis de sentimientos.
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(preprocess_function, batched=True)Ahora que nuestros LLM están cargados y nuestro conjunto de datos de evaluación preparado, es hora de ejecutar las evaluaciones y registrar las métricas.
1. Importar MLflow e iniciar un nuevo experimento
Para hacer un seguimiento de los experimentos con MLflow, primero tenemos que iniciar un nuevo experimento y registrar los metadatos pertinentes, como el nombre del modelo, la versión y los parámetros de evaluación.
import mlflow
import mlflow.pytorch
# Start a new experiment
mlflow.set_experiment("LLM_Evaluation")
with mlflow.start_run() as run:
# Log experiment metadata
mlflow.log_param("model_name", "bert")
mlflow.log_param("model_version", "v1.0")
mlflow.log_param("evaluation_task", "sentiment_analysis")2. Parámetros de evaluación del registro
Ahora podemos registrar cualquier parámetro relacionado con el proceso de evaluación, como el tamaño del conjunto de datos de evaluación o las configuraciones específicas utilizadas durante la evaluación.
with mlflow.start_run() as run:
mlflow.log_param("dataset_size", len(dataset['test']))Una vez que hemos entrenado y realizado las predicciones correspondientes con nuestro modelo, podemos evaluar el LLM y registrar diversas métricas que reflejen su rendimiento.
El análisis de sentimientos es un problema de clasificación, por lo que podemos evaluar nuestro modelo utilizando métricas como la precisión y la puntuación F1. Para las tareas de generación de texto, se suelen utilizar métricas como la puntuación BLEU o la perplejidad.
from sklearn.metrics import accuracy_score, f1_score
# Assuming y_true and y_pred are true labels and model predictions
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
with mlflow.start_run() as run:
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)Una vez que se han seguido múltiples ejecuciones de evaluación con MLflow, comparar su rendimiento es esencial para determinar los modelos y configuraciones de mejor rendimiento.
Vamos a entender cómo realizar el seguimiento de varias ejecuciones y utilizar la interfaz de usuario de MLflow para visualizar y comparar los resultados de forma eficaz.
En primer lugar, necesitamos realizar un seguimiento de varias ejecuciones dentro del mismo experimento o entre diferentes experimentos para comparar el rendimiento de diferentes versiones del LLM.
1. Registrar varias ejecuciones
Podemos registrar varias ejecuciones en un mismo experimento iniciando nuevas ejecuciones para cada modelo o configuración que queramos evaluar.
models = [("bert-base-cased", "v1.0"), ("bert-base-uncased", "v1.0")]
y_pred_dict = {
"bert-base-cased": y_pred_case,
"bert-base-uncased": y_pred_uncase
}
for model_name, model_version in models:
with mlflow.start_run() as run:
# Log model and version
mlflow.log_param("model_name", model_name)
mlflow.log_param("model_version", model_version)
# Perform evaluation and log metrics
y_pred = y_pred_dict[model_name]
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)2. Experimentos de seguimiento con diferentes modelos
Imaginemos que queremos evaluar distintos tipos de modelos. Para ello, podemos utilizar MLFlow para crear un experimento y registrar juntos los modelos.
Realizar el registro de modelos en MLFlow es lo mismo que hacer el control de versiones de los modelos de aprendizaje automático. Registrar los detalles del modelo y del entorno garantiza la reproducibilidad.
En primer lugar, prepararemos un experimento. A continuación, registramos cada modelo en una ejecución MLFlow independiente, incluyendo los ID de ejecución y las rutas de los artefactos.
# Create an experiments for the different models
mlflow.set_experiment("sentiment_analysis_comparison")
model_names = ["bert-base-cased", "bert-base-uncased"]
run_ids = []
artifact_paths = []
for model, name in zip([betcased, bertuncased], model_names):
with mlflow.start_run(run_name=f"log_model_{name}"):
artifact_path = f"models/{name}"
mlflow.pyfunc.log_model(
artifact_path=artifact_path,
python_model=model,
)
run_ids.append(mlflow.active_run().info.run_id)
artifact_paths.append(artifact_path)Ahora, podemos evaluar los modelos y registrar los resultados. MLflow proporciona una API, mlflow.evaluate(), para ayudar a evaluar nuestros LLM.
for i in len(model_names):
with mlflow.start_run(run_id=run_ids[i]):
# reopen the run with the stored run ID
evaluation_results = mlflow.evaluate(
model=f"runs:/{run_ids[i]}/{artifact_paths[i]}",
model_type="text",
data=dataset['test'],
)Después de haber registrado las diferentes métricas y modelos en MLFlow, podemos hacer una comparación. Podemos utilizar la interfaz de fácil uso de MLflow para visualizar y comparar las métricas de evaluación de diferentes ejecuciones. Para ello, tenemos que iniciar el servidor MLflow si aún no está en funcionamiento
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlrunsA continuación, abrimos un navegador web y navegamos hasta http://localhost:5000 para acceder a la interfaz de usuario de MLflow. En la interfaz de usuario de MLflow, vamos a la página "Experimentos" para ver todos nuestros experimentos. Hacemos clic en el nombre del experimento para ver una lista de las ejecuciones asociadas a él.
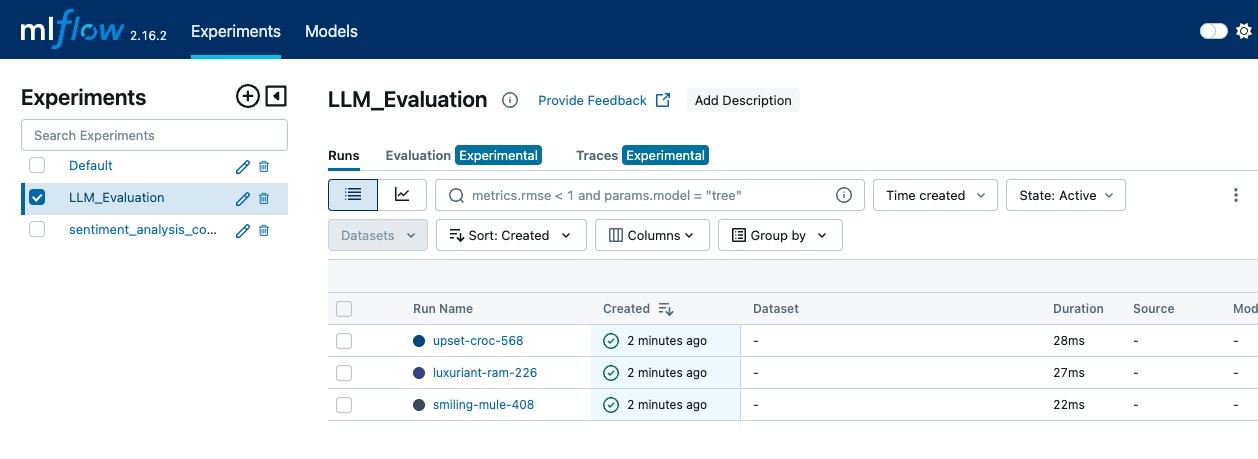
La interfaz MLFLow muestra la pestaña Experimentos, donde se pueden ver las distintas ejecuciones y los eventos de registro-imagen por Autor.
Dentro de un experimento, podemos comparar distintas ejecuciones seleccionando varias y viendo sus métricas una al lado de la otra.
La interfaz de usuario nos permite ver una representación visual de métricas como la precisión, la puntuación F1 y otras métricas de evaluación. También podemos utilizar las visualizaciones integradas de MLflow para generar diagramas y gráficos que nos permitan realizar comparaciones más detalladas.
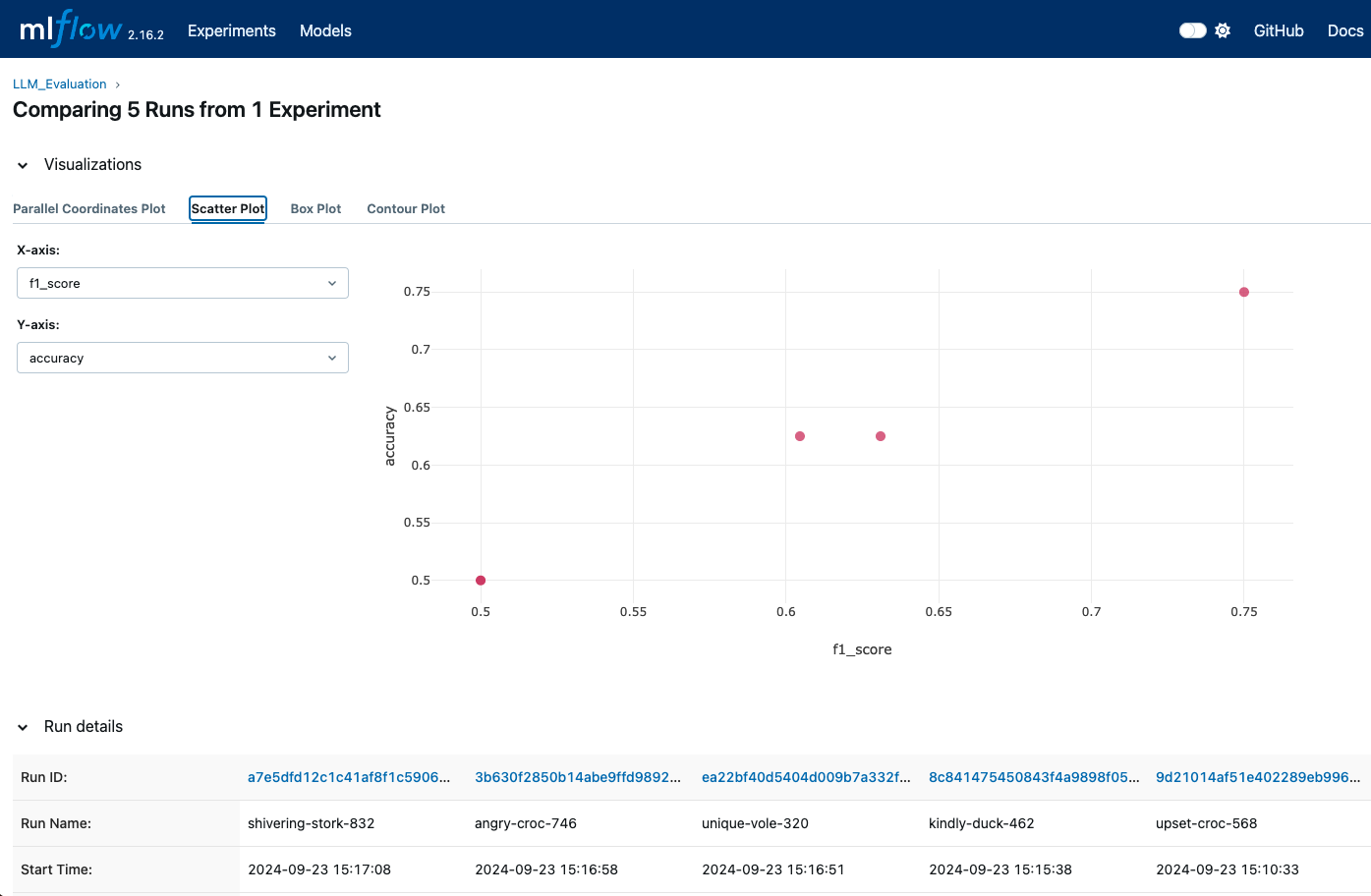
Las visualizaciones de MLFlow pueden mostrarnos cuándo se registran diferentes ejecuciones para que podamos comparar diferentes métricas-imagen por Autor.
La interfaz de usuario de MLflow proporciona gráficos y registros detallados de cada ejecución. Podemos acceder a estos registros y visualizaciones para comprender qué modelo o configuración funciona mejor en función de las métricas registradas.
Para una evaluación más profunda y completa de los LLM, MLflow ofrece técnicas avanzadas que mejoran el seguimiento y el análisis. Repasaremos cómo registrar los artefactos del modelo para realizar un seguimiento exhaustivo y utilizar MLflow para el ajuste de hiperparámetros con el fin de optimizar el rendimiento de LLM .
Registrar los artefactos del modelo es muy importante para conservar y analizar los detalles de nuestros experimentos. Los artefactos pueden proporcionar una imagen completa del rendimiento de nuestro modelo y ayudar a reproducir los resultados.
Entre los artefactos que podemos registrar, podemos encontrar:
joblib para scikit-learn o el formato SavedModel de TensorFlow).He aquí un ejemplo:
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
with mlflow.start_run() as run:
# Log the model
mlflow.pytorch.save_model(model, "model")
# Log the model weights
joblib.dump(model, "model_weights.pkl")
mlflow.log_artifact("model", artifact_path="model")
# Log the confusion matrix as image
confusion_matrix = pd.DataFrame(confusion_matrix(y_test, predictions))
cm = ConfusionMatrixDisplay(confusion_matrix=cm)
plt.savefig("confusion_matrix.png")
mlflow.log_artifact("confusion_matrix.png")
# Generate predictions
outputs = dataset['test']
outputs['prediction'] = model.predict(dataset['test'])
with open("generated_outputs.txt", "w") as f:
for output in outputs:
f.write(output + "\n")
# Log the file
mlflow.log_artifact("generated_outputs.txt")El ajuste de los hiperparámetros es una parte fundamental de la optimización del rendimiento del LLM. En nuestros experimentos, podemos utilizar MLflow para registrar distintas configuraciones de hiperparámetros. Esto nos permite comparar los efectos de varios ajustes y encontrar la configuración óptima.
from transformers import Trainer, TrainingArguments
def train_and_log_model(model, lr, bs):
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=learning_rate,
evaluation_strategy="epoch")
trainer = Trainer(model=model,
args=training_args,
train_dataset=(X_train, y_train)
eval_dataset=(X_test, y_test))
with mlflow.start_run() as run:
# Log hyperparameters
mlflow.log_param("learning_rate", lr)
mlflow.log_param("batch_size", bs)
trainer.train()
eval_result = trainer.evaluate()
mlflow.log_metric("eval_accuracy",
eval_result['eval_accuracy'])
hyperparameter_grid = [{"learning_rate": 5e-5, "batch_size": 8},
{"learning_rate": 3e-5, "batch_size": 16}]
for params in hyperparameter_grid:
train_and_log_model(params["learning_rate"],
params["batch_size"])Otra ventaja de MLflow es que puede utilizarse con bibliotecas de optimización de hiperparámetros como Optuna o Ray Tune para automatizar el proceso de ajuste.
Una evaluación precisa de los LLM implica algo más que ejecutar pruebas y registrar métricas. Requiere un enfoque estratégico para garantizar la coherencia, la precisión y la eficacia. Adoptar las mejores prácticas puede aumentar la fiabilidad y eficacia del proceso de evaluación.
Utilizar conjuntos de datos estables y representativos es una de las primeras cosas que contribuyen a una evaluación eficaz. Si nos aseguramos de que nuestros conjuntos de datos de evaluación son estables y representativos de las tareas para las que está diseñado nuestro LLM, obtendremos comparaciones significativas a lo largo del tiempo y entre distintos modelos o versiones. Si el conjunto de datos cambia, puede ser difícil asignar los cambios de rendimiento al modelo y no al propio conjunto de datos.
No sólo el conjunto de datos, sino también cómo lo preprocesamos es importante. Ws necesario aplicar los mismos pasos de preprocesamiento a todos los conjuntos de datos de evaluación para garantizar resultados comparables. Esto incluye la tokenización, la normalización y el tratamiento de casos especiales. Un preprocesamiento coherente garantiza que las variaciones en el rendimiento del modelo no se deban a diferencias en el tratamiento de los datos.
Como hemos visto antes, utilizar el registro de modelos de MLflow para permitir el control de versiones nos ayuda a realizar un seguimiento de las distintas versiones de nuestros LLM. Esto facilita comparar el rendimiento del modelo y volver a versiones anteriores si es necesario. Debemos registrar todos los detalles y hacer un seguimiento de los cambios realizados en los modelos, incluidas las modificaciones de la arquitectura, los hiperparámetros o los datos de entrenamiento.
Por último, automatizar el proceso de evaluación integrándolo en los conductos de integración continua/despliegue continuo (CI/CD) puede ayudarnos a asegurarnos de que los modelos se evalúan de forma coherente y puntual cada vez que se realizan actualizaciones. Deberíamos establecer evaluaciones programadas para valorar periódicamente el rendimiento del modelo. Esto nos ayuda a controlar la deriva del modelo y a garantizar que los modelos cumplen las normas de rendimiento a lo largo del tiempo.
Evaluar eficazmente los LLM requiere un enfoque estructurado y sistemático, y MLflow proporciona un marco de apoyo a este proceso.
En este tutorial, instalamos MLflow y configuramos un servidor de seguimiento. A continuación, evaluamos nuestro LLM registrando métricas importantes, seguimos múltiples ejecuciones para compararlas y utilizamos la interfaz de usuario de MLflow para visualizar y analizar estas comparaciones de forma eficaz.
Si quieres llevar tus conocimientos sobre MLflow al siguiente nivel, ¡consulta nuestro curso Introducción a MLflow!
¡Aprende más sobre los LLM con estos cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
15 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita

