
Programa
Fundamentos da IA
10 h
O HumanEval é um conjunto de dados de referência desenvolvido pela OpenAI que avalia o desempenho de modelos de linguagem grandes (LLMs) em tarefas de geração de código. Ele se tornou uma ferramenta importante para avaliar os recursos dos modelos de IA na compreensão e geração de códigos.
Neste tutorial, aprenderemos sobre o HumanEval e a métrica pass@k. Além disso, avaliaremos os recursos de geração de código do modelo codeparrot-small em 164 problemas.
Para o processo de avaliação da HumanEval, usaremos o Hugging Face para carregar o conjunto de dados, o modelo e as métricas necessárias. Se você é relativamente novo no mundo dos LLMs e em tudo o que eles podem alcançar, confira nosso Curso de desenvolvimento de grandes modelos de linguagem.

Imagem do autor
HumanEval foi desenvolvido pela OpenAI como um conjunto de dados de avaliação projetado especificamente para grandes modelos de linguagem. Ele serve como referência para avaliar os LLMs em tarefas de geração de código, concentrando-se na capacidade dos modelos de compreender a linguagem, raciocinar e resolver problemas relacionados a algoritmos e matemática simples.
O conjunto de dados consiste em 164 problemas de programação escritos à mão, cada um incluindo uma assinatura de função, docstring, corpo e vários testes de unidade, com uma média de 7,7 testes por problema.
No exemplo abaixo, clonaremos o repositório de avaliação humana, instalaremos os pacotes Python necessários e, em seguida, executaremos a avaliação da correção funcional no conjunto de dados de exemplo.
$ git clone https://github.com/kingabzpro/human-eval
$ pip install -e human-eval
$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonlObtivemos o resultado em termos de pass@k e, em nosso caso, pass@1. Essa métrica indica a taxa de sucesso de 50% de um modelo na primeira tentativa. Aprenderemos sobre essa métrica em detalhes na próxima seção.
Reading samples...
6it [00:00, 2465.79it/s]
Running test suites...
100%|█████████████████████████████████████████████| 6/6 [00:03<00:00, 1.97it/s]
Writing results to data/example_samples.jsonl_results.jsonl...
100%|██████████████████████████████████████████| 6/6 [00:00<00:00, 12035.31it/s]
{'pass@1': 0.4999999999999999}Leia a avaliação do LLM em: Metrics, Methodologies, Best Practices blog para que você saiba como avaliar os LLMs usando as principais métricas, metodologias e práticas recomendadas para tomar decisões informadas.
O HumanEval é diferente das métricas tradicionais baseadas em correspondências. Ele usa uma abordagem mais prática chamada "correção funcional", que usa a métrica pass@k para avaliar a probabilidade de que pelo menos uma das principais amostras de código geradas por k para um problema seja aprovada nos testes de unidade.
Essa mudança de similaridade de texto para correção funcional fornece uma avaliação mais significativa da capacidade de um modelo de resolver desafios de programação. Esse processo é semelhante ao modo como os desenvolvedores testam seu código por meio de testes unitários para avaliar sua correção.
Você pode ver a fórmula matemática para calcular a métrica pass@k abaixo:
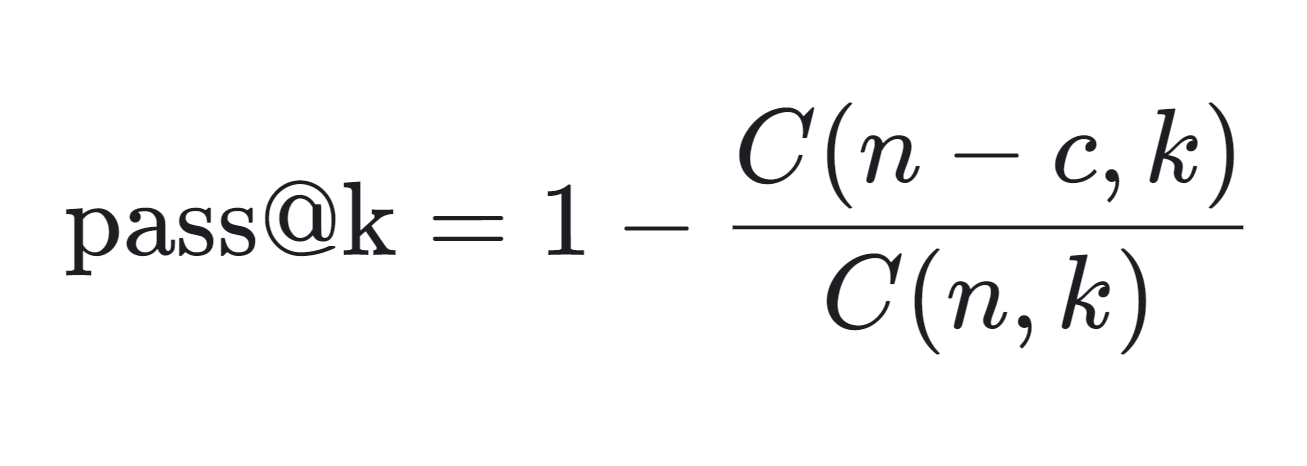
A métrica pass@k é calculada da seguinte forma:
A métrica pass@k é particularmente útil para avaliar o desempenho prático dos modelos de geração de código, pois reflete a probabilidade de gerar uma solução correta em um número limitado de tentativas.
A métrica é amplamente usada em ambientes competitivos, como tabelas de classificação hospedadas por Papers with Codeem que os modelos são classificados com base em suas pontuações pass@k, incluindo pass@10 e pass@100.
O HumanEval garante que o código gerado seja sintaticamente correto e funcionalmente eficaz.
Neste projeto, carregaremos o OpenAI HumanEval do OpenAI e executaremos a avaliação da correção funcional no codeparrot/codeparrot-small.
Estamos selecionando um modelo de geração de código menor para acelerar o tempo de avaliação, pois vamos executar vários loops: loop externo 164 (número de problemas) e loop interno 5 (número de amostras geradas para um único problema).
Começaremos instalando o aplicativo Evaluate da biblioteca Python da Hugging Face. O Evaluate é uma biblioteca avançada que permite que você avalie facilmente modelos de aprendizado de máquina e conjuntos de dados em vários domínios com uma única linha de código, garantindo consistência e reprodutibilidade, seja em máquinas locais ou em configurações de treinamento distribuídas.
%%capture
%pip install evaluateAlém disso, configure uma variável de ambiente que nos permitirá executar a avaliação do modelo.
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"Carregaremos o conjunto de dados openai_humaneval do Hugging Face. Esse conjunto de dados contém 164 problemas de programação em Python e inclui texto natural em inglês encontrado em comentários e docstrings.
Também carregaremos a métrica de avaliação code_eval, o que nos permitirá executar o benchmark HumanEval.
from datasets import load_dataset
from evaluate import load
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm import tqdm
# Load HumanEval dataset
human_eval = load_dataset("openai_humaneval")['test']
# Load code evaluation metric
code_eval_metric = load("code_eval")Carregue o modelo CodeParrot e o tokenizador do Hugging Face Hub. O CodeParrot é um modelo baseado em GPT-2 com 110 milhões de parâmetros que foram treinados especificamente para gerar código Python.
# Specify the model name or path
model_name = "codeparrot/codeparrot-small"
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.eval()Defina pad_token_id e pad_token_id e redimensione os embeddings do modelo se os novos tokens forem adicionados.
# Set pad_token_id and pad_token_id if not already set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = 0 # Commonly used pad token ID
if tokenizer.eos_token_id is None:
tokenizer.eos_token_id = 2 # Commonly used eos token ID for Llama
# Ensure the tokenizer has the pad and eos tokens
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '<pad>'})
if tokenizer.eos_token is None:
tokenizer.add_special_tokens({'eos_token': '</s>'})
# Resize model embeddings if new tokens were added
if len(tokenizer) > model.config.vocab_size:
model.resize_token_embeddings(len(tokenizer))Esta é a seção principal onde a mágica acontece. Executaremos o HumanEval para cinco amostras por problema, com um total de 164 problemas a serem avaliados. O loop externo extrairá o prompt e o teste do conjunto de dados. Usando o prompt, ele gerará cinco amostras diferentes para o mesmo problema.
Ao final desse processo, teremos duas listas: test_cases e candidates.
Essa configuração permite uma avaliação abrangente e a comparação das soluções geradas com os casos de teste.
# Set the number of candidates per problem
num_samples_per_problem = 5 # Adjust as needed for pass@k computation
# Lists to store test cases and predictions
test_cases = []
candidates = []
# Create a progress bar for the outer loop (problems)
print("Generating code solutions...")
for problem in tqdm(human_eval, desc="Problems", unit="problem"):
prompt = problem['prompt']
test_code = problem['test']
# Store the test cases
test_cases.append(test_code)
# Generate multiple candidate solutions for each problem
problem_candidates = []
# Create a progress bar for the inner loop (samples per problem)
for _ in range(num_samples_per_problem):
# Encode the prompt and get attention mask
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Generate code with attention mask and proper token IDs
with torch.no_grad():
outputs = model.generate(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_length=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
num_return_sequences=1,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Remove the prompt from the generated code
generated_code = generated_code[len(prompt):]
problem_candidates.append(generated_code)
# Add the candidates for the current problem
candidates.append(problem_candidates)
print("Code generation complete.")Saída:
Generating code solutions...
Problems: 100%|██████████| 164/164 [34:35<00:00, 12.66s/problem]
Code generation complete.Agora, calcularemos a taxa de aprovação em diferentes valores de k (1 e 5) para as amostras de código geradas, comparando-as com casos de teste de referência, usando uma métrica de avaliação pass@k e, em seguida, exibiremos a taxa de sucesso como uma porcentagem para cada valor de k.
# Compute pass@k
k_values = [1, 5]
print("Evaluating generated code...")
pass_at_k, results = code_eval_metric.compute(
references=test_cases,
predictions=candidates,
k=k_values,
num_workers=4, # Adjust based on your system
timeout=10.0, # Adjust the timeout as needed
)
# Print the results
for k in k_values:
print(f"Pass@{k}: {pass_at_k[f'pass@{k}'] * 100:.2f}%")Os resultados mostram que 27,07% das amostras de código geradas passam nos critérios de avaliação ao considerar o principal candidato (Pass@1), enquanto 65,85% passam ao considerar os cinco principais candidatos (Pass@5). Esse desempenho é considerado bom, especialmente porque estamos usando um modelo de linguagem menor para gerar o código Python.
No entanto, quando comparado com o GPT-4o, que tem uma taxa de Pass@1 de 90,2%, os resultados parecem ser insuficientes.
Evaluating generated code...
Pass@1: 27.07%
Pass@5: 65.85%Se você estiver tendo problemas para executar o código acima, verifique HumanEval com o DeepEval do Kaggle.
Você também pode aprender a simplificar suas avaliações de LLM com o MLflow seguindo o guia Avaliação de LLMs com o MLflow para você.
O conjunto de dados HumanEval é relativamente simples e pode representar apenas parcialmente os desafios de programação do mundo real. Além disso, há preocupações quanto ao ajuste excessivo, pois os modelos podem ser treinados em conjuntos de dados semelhantes, o que poderia levar a um melhor desempenho especificamente no HumanEval.
Portanto, ao avaliar modelos de linguagem grandes (LLMs) para recursos de geração de código, é essencial considerar várias métricas de desempenho, como MBPP (Mostly Basic Python Problems), ClassEval, DevQualityEval e outras.
Conclua o curso Fundamentos de IA e obtenha conhecimento prático sobre tópicos populares de IA, como ChatGPT, modelos de linguagem grandes, IA generativa e muito mais.
Principais cursos de IA
Programa
Programa
Programa
blog
Stanislav Karzhev
9 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali

