
Cursus
Principes fondamentaux de l'IA
10 h
HumanEval est un ensemble de données de référence développé par l'OpenAI qui évalue les performances des grands modèles de langage (LLM) dans les tâches de génération de code. Il est devenu un outil important pour évaluer les capacités des modèles d'IA à comprendre et à générer du code.
Dans ce tutoriel, nous allons découvrir HumanEval et la métrique pass@k. En outre, nous évaluerons les capacités de génération de code du modèle codeparrot-small sur 164 problèmes.
Pour le processus d'évaluation de HumanEval, nous utiliserons l'outil Hugging Face pour charger le jeu de données, le modèle et les métriques nécessaires. Si vous êtes relativement novice dans le monde des LLM et de ce qu'ils peuvent accomplir, consultez notre cours de Développer de grands modèles de langage.

Image par l'auteur
HumanEval a été développé par l'OpenAI en tant qu'ensemble de données d'évaluation spécialement conçu pour les modèles de langage de grande taille. Il sert de référence pour évaluer les LLM sur des tâches de génération de code, en se concentrant sur la capacité des modèles à comprendre le langage, à raisonner et à résoudre des problèmes liés à des algorithmes et à des mathématiques simples.
L'ensemble de données se compose de 164 problèmes de programmation écrits à la main, chacun comprenant une signature de fonction, une chaîne de documentation, un corps et plusieurs tests unitaires, avec une moyenne de 7,7 tests par problème.
Dans l'exemple ci-dessous, nous allons cloner le référentiel d'évaluation humaine, installer les paquets Python nécessaires, puis exécuter l'évaluation de la correction fonctionnelle sur le jeu de données d'exemple.
$ git clone https://github.com/kingabzpro/human-eval
$ pip install -e human-eval
$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonlNous avons obtenu le résultat en termes de pass@k et, dans notre cas, de pass@1. Cette mesure indique le taux de réussite de 50 % d'un modèle au premier essai. Nous verrons cette mesure en détail dans la section suivante.
Reading samples...
6it [00:00, 2465.79it/s]
Running test suites...
100%|█████████████████████████████████████████████| 6/6 [00:03<00:00, 1.97it/s]
Writing results to data/example_samples.jsonl_results.jsonl...
100%|██████████████████████████████████████████| 6/6 [00:00<00:00, 12035.31it/s]
{'pass@1': 0.4999999999999999}Lisez l'évaluation deLLM : Métriques, méthodologies, meilleures pratiques blog pour apprendre à évaluer les LLM à l'aide de métriques clés, de méthodologies et de meilleures pratiques afin de prendre des décisions éclairées.
HumanEval est différent des mesures traditionnelles basées sur les correspondances. Il utilise une approche plus pratique appelée "correction fonctionnelle", qui utilise la métrique pass@k pour évaluer la probabilité qu'au moins un des k premiers échantillons de code générés pour un problème passe les tests unitaires.
Ce passage de la similarité textuelle à la correction fonctionnelle permet une évaluation plus significative de la capacité d'un modèle à résoudre des problèmes de programmation. Ce processus est similaire à la manière dont les développeurs testent leur code à l'aide de tests unitaires afin d'en évaluer l'exactitude.
Vous trouverez ci-dessous la formule mathématique permettant de calculer la métrique pass@k :
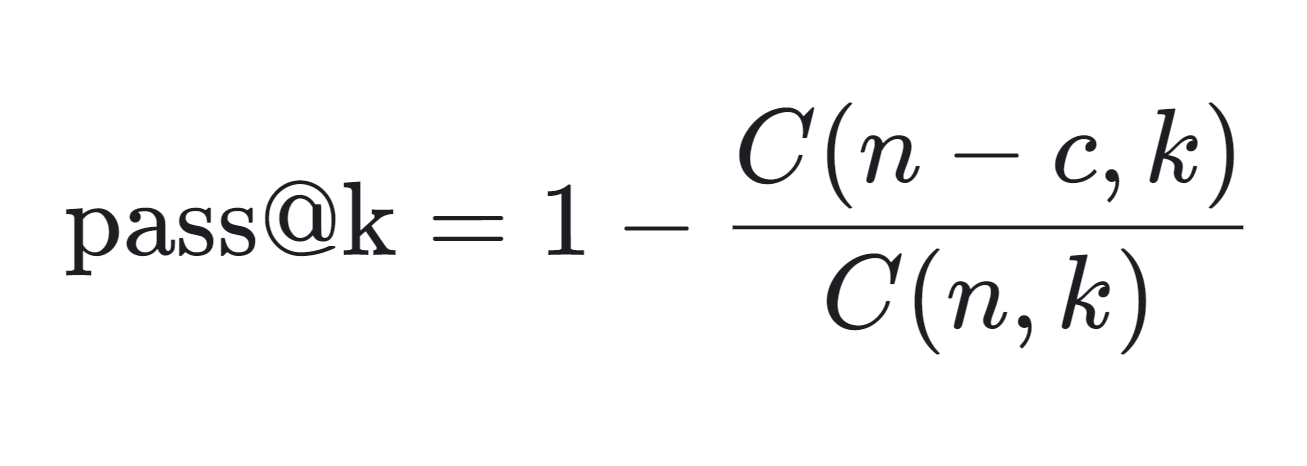
La métrique pass@k est calculée comme suit :
La métrique pass@k est particulièrement utile pour évaluer les performances pratiques des modèles de génération de code, car elle reflète la probabilité de générer une solution correcte en un nombre limité de tentatives.
Cette mesure est largement utilisée dans les environnements compétitifs, tels que les tableaux de classement hébergés par Papers with Codeoù les modèles sont classés en fonction de leur score pass@k, y compris pass@10 et pass@100.
HumanEval garantit que le code généré est syntaxiquement correct et fonctionnellement efficace.
Dans ce projet, nous chargerons le logiciel OpenAI HumanEval et lancerons l'évaluation de la correction fonctionnelle sur la base de données de codeparrot/codeparrot-small.
Nous choisissons un modèle de génération de code plus petit pour accélérer le temps d'évaluation car nous allons exécuter plusieurs boucles : boucle extérieure 164 (nombre de problèmes) et boucle intérieure 5 (nombre d'échantillons générés pour un seul problème).
Nous commencerons par installer le logiciel Évaluer la bibliothèque Python par Hugging Face. Evaluate est une bibliothèque puissante qui vous permet d'évaluer facilement des modèles d'apprentissage automatique et des ensembles de données dans divers domaines avec une seule ligne de code, en garantissant la cohérence et la reproductibilité, que ce soit sur des machines locales ou dans des configurations d'apprentissage distribuées.
%%capture
%pip install evaluateDéfinissez également une variable d'environnement qui nous permettra d'exécuter l'évaluation du modèle.
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"Nous allons charger l'ensemble de données openai_humaneval de Hugging Face. Cet ensemble de données contient 164 problèmes de programmation Python et inclut du texte naturel anglais trouvé dans les commentaires et les docstrings.
Nous chargerons également la métrique d'évaluation code_eval, ce qui nous permettra d'exécuter le benchmark HumanEval.
from datasets import load_dataset
from evaluate import load
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm import tqdm
# Load HumanEval dataset
human_eval = load_dataset("openai_humaneval")['test']
# Load code evaluation metric
code_eval_metric = load("code_eval")Chargez le modèle CodeParrot et le tokenizer à partir du Hub Hugging Face. CodeParrot est un modèle basé sur GPT-2 avec 110 millions de paramètres qui ont été spécifiquement entraînés pour générer du code Python.
# Specify the model name or path
model_name = "codeparrot/codeparrot-small"
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.eval()Définissez les adresses pad_token_id et pad_token_id et redimensionnez le modèle d'intégration si de nouveaux tokens sont ajoutés.
# Set pad_token_id and pad_token_id if not already set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = 0 # Commonly used pad token ID
if tokenizer.eos_token_id is None:
tokenizer.eos_token_id = 2 # Commonly used eos token ID for Llama
# Ensure the tokenizer has the pad and eos tokens
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '<pad>'})
if tokenizer.eos_token is None:
tokenizer.add_special_tokens({'eos_token': '</s>'})
# Resize model embeddings if new tokens were added
if len(tokenizer) > model.config.vocab_size:
model.resize_token_embeddings(len(tokenizer))Il s'agit de la section principale où la magie opère. Nous utiliserons HumanEval pour cinq échantillons par problème, avec un total de 164 problèmes à évaluer. La boucle extérieure extrait l'invite et le test de l'ensemble de données. À l'aide de l'invite, il générera cinq échantillons différents pour le même problème.
À la fin de ce processus, nous aurons deux listes : test_cases et candidates.
Cette configuration permet une évaluation et une comparaison complètes des solutions générées par rapport aux cas de test.
# Set the number of candidates per problem
num_samples_per_problem = 5 # Adjust as needed for pass@k computation
# Lists to store test cases and predictions
test_cases = []
candidates = []
# Create a progress bar for the outer loop (problems)
print("Generating code solutions...")
for problem in tqdm(human_eval, desc="Problems", unit="problem"):
prompt = problem['prompt']
test_code = problem['test']
# Store the test cases
test_cases.append(test_code)
# Generate multiple candidate solutions for each problem
problem_candidates = []
# Create a progress bar for the inner loop (samples per problem)
for _ in range(num_samples_per_problem):
# Encode the prompt and get attention mask
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Generate code with attention mask and proper token IDs
with torch.no_grad():
outputs = model.generate(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_length=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
num_return_sequences=1,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Remove the prompt from the generated code
generated_code = generated_code[len(prompt):]
problem_candidates.append(generated_code)
# Add the candidates for the current problem
candidates.append(problem_candidates)
print("Code generation complete.")Sortie :
Generating code solutions...
Problems: 100%|██████████| 164/164 [34:35<00:00, 12.66s/problem]
Code generation complete.Nous allons maintenant calculer le taux de réussite à différentes valeurs de k (1 et 5) pour les échantillons de code générés en les comparant à des cas de test de référence, en utilisant une métrique d'évaluation pass@k, puis nous produirons le taux de réussite sous forme de pourcentage pour chaque valeur de k.
# Compute pass@k
k_values = [1, 5]
print("Evaluating generated code...")
pass_at_k, results = code_eval_metric.compute(
references=test_cases,
predictions=candidates,
k=k_values,
num_workers=4, # Adjust based on your system
timeout=10.0, # Adjust the timeout as needed
)
# Print the results
for k in k_values:
print(f"Pass@{k}: {pass_at_k[f'pass@{k}'] * 100:.2f}%")Les résultats montrent que 27,07 % des échantillons de code générés satisfont aux critères d'évaluation lorsque l'on considère le premier candidat (Pass@1), tandis que 65,85 % satisfont aux critères lorsque l'on considère les cinq premiers candidats (Pass@5). Cette performance est considérée comme bonne, d'autant plus que nous utilisons un modèle de langue plus petit pour générer le code Python.
Cependant, si l'on compare avec le GPT-4o, qui a un taux de réussite de 90,2 %, les résultats semblent insuffisants.
Evaluating generated code...
Pass@1: 27.07%
Pass@5: 65.85%Si vous avez des difficultés à exécuter le code ci-dessus, vérifiez les points suivants HumanEval avec le cahier Kaggle DeepEval de Kaggle.
Vous pouvez également apprendre à rationaliser vos évaluations de LLM avec MLflow en suivant les instructions suivantes Évaluation des LLM avec MLflow en suivant le tutoriel.
L'ensemble de données HumanEval est relativement simple et peut ne représenter que partiellement les défis de programmation du monde réel. En outre, il existe des préoccupations concernant l'ajustement excessif, car les modèles peuvent être formés sur des ensembles de données similaires, ce qui pourrait conduire à une amélioration des performances sur HumanEval en particulier.
Par conséquent, lors de l'évaluation des modèles de grands langages (LLM) pour les capacités de génération de code, il est essentiel de prendre en compte plusieurs mesures de performance, telles que MBPP (Mostly Basic Python Problems), ClassEval, DevQualityEval, et d'autres.
Terminez le cours sur les Fondamentaux de l'IA et acquérez des connaissances pratiques sur des sujets d'IA populaires tels que le ChatGPT, les grands modèles de langage, l'IA générative, et plus encore.
Principaux cours sur l'IA
Cursus
Cursus
Cursus
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach