
Track
AI Fundamentals
10 hr
HumanEval is a benchmark dataset developed by OpenAI that evaluates the performance of large language models (LLMs) in code generation tasks. It has become a significant tool for assessing the capabilities of AI models in understanding and generating code.
In this tutorial, we will learn about HumanEval and the pass@k metric. Additionally, we will evaluate the code generation capabilities of the codeparrot-small model on 164 problems.
For the HumanEval evaluation process, we will be using the Hugging Face ecosystem to load the dataset, the model, and the necessary metrics. If you’re relatively new to the world of LLMs and all they can achieve, check out our Developing Large Language Models course.

Image by Author
HumanEval was developed by OpenAI as an evaluation dataset specifically designed for large language models. It serves as a reference benchmark for evaluating LLMs on code generation tasks, focusing on the models' ability to comprehend language, reason, and solve problems related to algorithms and simple mathematics.
The dataset consists of 164 hand-written programming problems, each including a function signature, docstring, body, and several unit tests, with an average of 7.7 tests per problem.
In the example below, we will clone the human evaluation repository, install the necessary Python packages, and then run the functional correctness evaluation on the example dataset.
$ git clone https://github.com/kingabzpro/human-eval
$ pip install -e human-eval
$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonlWe got the result in terms of pass@k, and, in our case, pass@1. This metric indicates a model's 50% success rate on the first attempt. We will learn about this metric in detail in the next section.
Reading samples...
6it [00:00, 2465.79it/s]
Running test suites...
100%|█████████████████████████████████████████████| 6/6 [00:03<00:00, 1.97it/s]
Writing results to data/example_samples.jsonl_results.jsonl...
100%|██████████████████████████████████████████| 6/6 [00:00<00:00, 12035.31it/s]
{'pass@1': 0.4999999999999999}Read the LLM Evaluation: Metrics, Methodologies, Best Practices blog to learn how to evaluate LLMs using key metrics, methodologies, and best practices to make informed decisions.
HumanEval is different from traditional match-based metrics. It uses a more practical approach called 'functional correctness.' which uses the pass@k metric to evaluate the probability that at least one of the top k-generated code samples for a problem passes the unit tests.
This shift from text similarity to functional correctness provides a more meaningful assessment of a model's ability to solve programming challenges. This process is similar to how developers test their code through unit testing to evaluate its correctness.
We can see the mathematical formula for calculating the pass@k metric below:
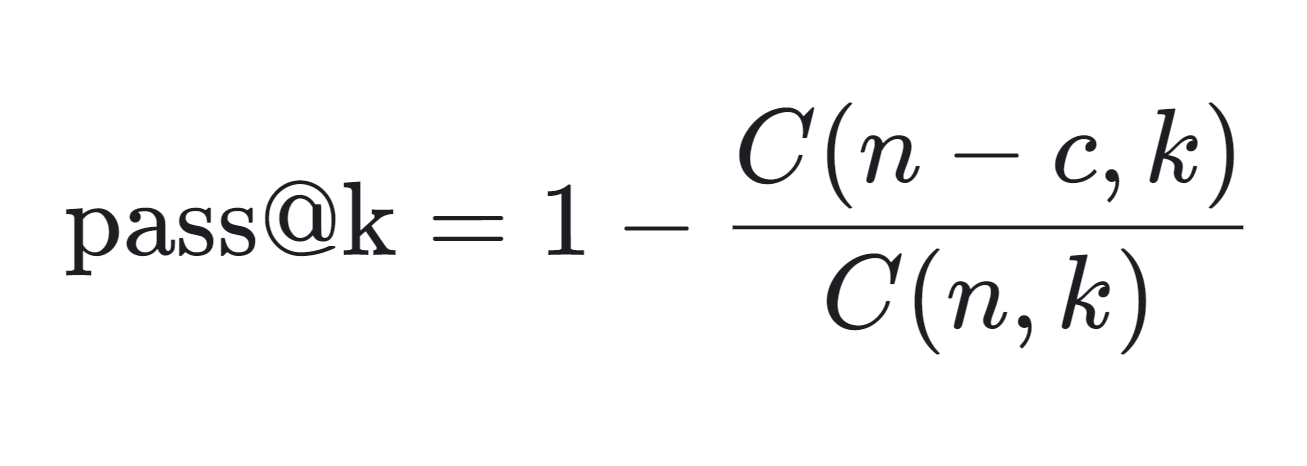
The pass@k metric is calculated as follows:
The pass@k metric is particularly useful in assessing the practical performance of code generation models, as it reflects the likelihood of generating a correct solution within a limited number of attempts.
The metric is widely used in competitive environments, such as leaderboards hosted by Papers with Code, where models are ranked based on their pass@k scores, including pass@10 and pass@100.
HumanEval ensures that the generated code is syntactically correct and functionally effective.
In this project, we will load the OpenAI HumanEval dataset and run the functional correctness evaluation on the codeparrot/codeparrot-small.
We are selecting a smaller code generation model for faster evaluation time as we are going to run multiple loops: outer loop 164 (Number of problems) and inner loop 5 (number of samples generated for a single problem).
We will start by installing the Evaluate Python Library by Hugging Face. Evaluate is a powerful library that allows you to easily evaluate machine learning models and datasets across various domains with a single line of code, ensuring consistency and reproducibility, whether on local machines or in distributed training setups.
%%capture
%pip install evaluateAlso, set up an environment variable that will allow us to run the model evaluation.
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"We will load the openai_humaneval dataset from Hugging Face. This dataset contains 164 Python programming problems and includes English natural text found in comments and docstrings.
We will also load the code_eval evaluation metric, enabling us to run the HumanEval benchmark.
from datasets import load_dataset
from evaluate import load
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm import tqdm
# Load HumanEval dataset
human_eval = load_dataset("openai_humaneval")['test']
# Load code evaluation metric
code_eval_metric = load("code_eval")Load the CodeParrot model and tokenizer from the Hugging Face Hub. CodeParrot is a GPT-2-based model with 110 million parameters that have been specifically trained to generate Python code.
# Specify the model name or path
model_name = "codeparrot/codeparrot-small"
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.eval()Set the pad_token_id and pad_token_id and resize the model embeddings if the new tokens are added.
# Set pad_token_id and pad_token_id if not already set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = 0 # Commonly used pad token ID
if tokenizer.eos_token_id is None:
tokenizer.eos_token_id = 2 # Commonly used eos token ID for Llama
# Ensure the tokenizer has the pad and eos tokens
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '<pad>'})
if tokenizer.eos_token is None:
tokenizer.add_special_tokens({'eos_token': '</s>'})
# Resize model embeddings if new tokens were added
if len(tokenizer) > model.config.vocab_size:
model.resize_token_embeddings(len(tokenizer))This is the main section where the magic happens. We will run the HumanEval for five samples per problem, with a total of 164 problems to evaluate. The outer loop will extract the prompt and test from the dataset. Using the prompt, it will generate five different samples for the same problem.
By the end of this process, we will have two lists: test_cases and candidates.
This setup allows for comprehensive evaluation and comparison of the generated solutions against the test cases.
# Set the number of candidates per problem
num_samples_per_problem = 5 # Adjust as needed for pass@k computation
# Lists to store test cases and predictions
test_cases = []
candidates = []
# Create a progress bar for the outer loop (problems)
print("Generating code solutions...")
for problem in tqdm(human_eval, desc="Problems", unit="problem"):
prompt = problem['prompt']
test_code = problem['test']
# Store the test cases
test_cases.append(test_code)
# Generate multiple candidate solutions for each problem
problem_candidates = []
# Create a progress bar for the inner loop (samples per problem)
for _ in range(num_samples_per_problem):
# Encode the prompt and get attention mask
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Generate code with attention mask and proper token IDs
with torch.no_grad():
outputs = model.generate(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_length=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
num_return_sequences=1,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Remove the prompt from the generated code
generated_code = generated_code[len(prompt):]
problem_candidates.append(generated_code)
# Add the candidates for the current problem
candidates.append(problem_candidates)
print("Code generation complete.")Output:
Generating code solutions...
Problems: 100%|██████████| 164/164 [34:35<00:00, 12.66s/problem]
Code generation complete.Now, we will compute the pass rate at different values of k (1 and 5) for generated code samples by comparing them against reference test cases, using a pass@k evaluation metric, and then output the success rate as a percentage for each k value.
# Compute pass@k
k_values = [1, 5]
print("Evaluating generated code...")
pass_at_k, results = code_eval_metric.compute(
references=test_cases,
predictions=candidates,
k=k_values,
num_workers=4, # Adjust based on your system
timeout=10.0, # Adjust the timeout as needed
)
# Print the results
for k in k_values:
print(f"Pass@{k}: {pass_at_k[f'pass@{k}'] * 100:.2f}%")The results show that 27.07% of the generated code samples pass the evaluation criteria when considering the top candidate (Pass@1), while 65.85% pass when considering the top five candidates (Pass@5). This performance is considered good, especially since we are using a smaller language model to generate the Python code.
However, when compared to GPT-4o, which has a Pass@1 rate of 90.2%, the results appear to be lacking.
Evaluating generated code...
Pass@1: 27.07%
Pass@5: 65.85%If you are having trouble running the above code, please check HumanEval with the DeepEval Kaggle notebook.
You can also learn how to streamline your LLM evaluations with MLflow by following the Evaluating LLMs with MLflow tutorial.
The HumanEval dataset is relatively simple and may only partially represent real-world programming challenges. Additionally, there are concerns about overfitting, as models might be trained on similar datasets, which could lead to improved performance on HumanEval specifically.
Therefore, when evaluating large language models (LLMs) for code generation capabilities, it's essential to consider multiple performance metrics, such as MBPP (Mostly Basic Python Problems), ClassEval, DevQualityEval, and others.
Complete the AI Fundamentals skill tack and gain actionable knowledge on popular AI topics like ChatGPT, large language models, generative AI, and more.
Top AI Courses
Track
Track
Track
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Maria Eugenia Inzaugarat
Tutorial
Josep Ferrer
code-along
Andrea Valenzuela
