programa
Desarrollo de aplicaciones de IA
21 h
La evaluación de los LLM requiere un enfoque global, que emplee una serie de medidas para valorar diversos aspectos de su rendimiento. En este debate, exploramos los criterios clave de evaluación de los LLM, como la precisión y el rendimiento, el sesgo y la imparcialidad, así como otras métricas importantes.
Medir con precisión el rendimiento es un paso importante para comprender las capacidades de un LLM. Esta sección se sumerge en las principales métricas utilizadas para evaluarla precisión y el rendimiento de .
La perplejidad es una métrica fundamental para evaluar y medir la capacidad de un LLM para predecir la siguiente palabra de una secuencia. Así es como podemos calcularlo:
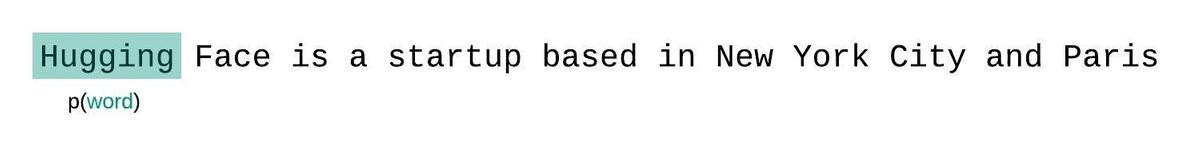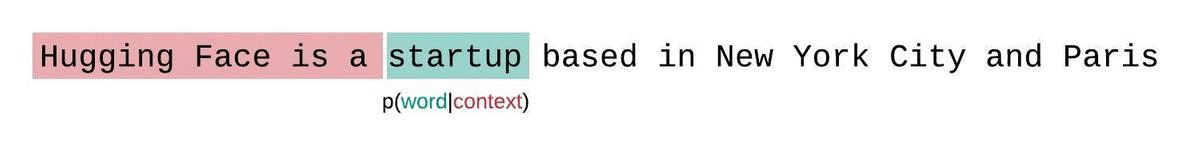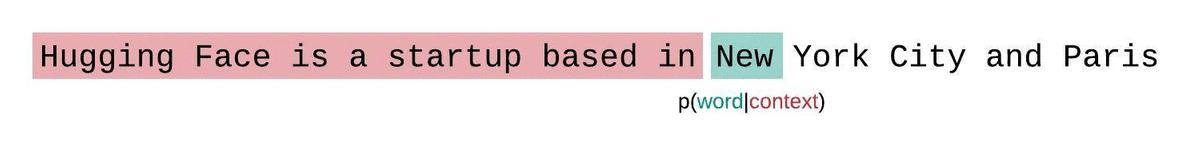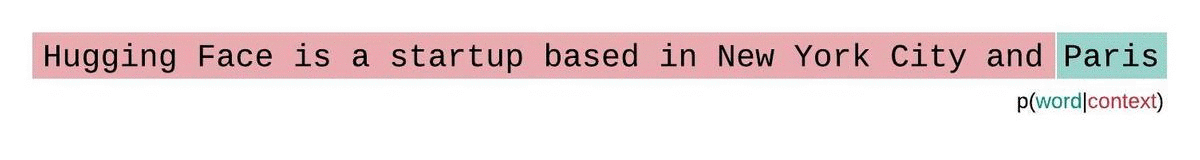
Las puntuaciones de perplejidad más bajas indican que el modelo predice la palabra siguiente con más precisión, lo que refleja un mejor rendimiento. Esencialmente, cuantifica lo bien que una distribución de probabilidad o un modelo predictivo predice una muestra.
Para los LLM, una perplejidad menor significa que el modelo tiene más confianza en sus predicciones de palabras, lo que conduce a una generación de textos más coherente y adecuada al contexto.
La precisión es una métrica muy utilizada para tareas de clasificaciónque representa la proporción de predicciones correctas realizadas por el modelo. Aunque se trata de una métrica típicamente intuitiva, en el contexto de las tareas de generación abiertas, a menudo puede ser engañosa.
Por ejemplo, al generar textos creativos o con matices contextuales, la "corrección" del resultado no es tan fácil de definir como en tareas como el análisis de sentimiento o la clasificación temática. Por lo tanto, aunque la precisión es útil para tareas específicas, debe complementarse con otras métricas al evaluar los LLM.
Las puntuaciones BLEU (Bilingual Evaluation Understudy) y ROUGE (Recall-Oriented Understudy for Gisting Evaluation) se utilizan para evaluar la calidad del texto generado comparándolo con los textos de referencia.
BLEU tiene que ver con la precisión: si una traducción automática utiliza exactamente las mismas palabras que una traducción humana, obtiene una puntuación BLEU alta. Por ejemplo, si la referencia humana es "El gato está en la colchoneta", y la salida de la máquina es "El gato se sienta en la colchoneta", la puntuación BLEU sería alta porque muchas palabras se solapan.
ROUGE se centra en el recuerdo: comprueba si el texto generado por la máquina capta todas las ideas importantes de la referencia humana. Digamos que un resumen escrito por humanos es "El estudio descubrió que las personas que hacen ejercicio regularmente tienden a tener una presión arterial más baja". Si el resumen generado por la IA es "El ejercicio está relacionado con la disminución de la presión arterial", ROUGE le daría una puntuación alta porque capta el punto principal aunque la redacción sea diferente.
Estas métricas son beneficiosas para tareas como traducción automáticaresumen y generación de textos, ya que proporcionan una evaluación cuantitativa del grado en que el resultado del modelo se ajusta a los textos de referencia generados por humanos.
Garantizar la equidad y reducir los prejuicios en los LLM es esencial para que las solicitudes sean equitativas. Aquí cubrimos las métricas clave para evaluar el sesgo y la imparcialidad en los LLM.
La paridad demográfica indica si el rendimiento de un modelo es coherente en los distintos grupos demográficos. Evalúa la proporción de resultados positivos entre grupos definidos por atributos como la raza, el sexo o la edad.
Alcanzar la paridad demográfica significa que las predicciones del modelo no están sesgadas hacia ningún grupo en particular, lo que garantiza la justicia y la equidad en sus aplicaciones.
La igualdad de oportunidades se centra en si los errores del modelo se distribuyen uniformemente entre los distintos grupos demográficos. Evalúa las tasas de falsos negativos de cada grupo, validando que el modelo no falla de forma desproporcionada en determinados grupos demográficos.
Esta métrica es crucial para aplicaciones en las que la equidad y la igualdad de acceso son esenciales, como los algoritmos de contratación o los procesos de aprobación de préstamos.
La imparcialidad contrafáctica evalúa si las predicciones de un modelo cambiarían si ciertos atributos sensibles fueran diferentes. Se trata de generar ejemplos contrafactuales en los que se modifica el atributo sensible (por ejemplo, el sexo o la raza) manteniendo constantes otras características.
Si la predicción del modelo cambia en función de esta alteración, indica un sesgo relacionado con el atributo sensible. La imparcialidad contrafáctica es vital para identificar y mitigar sesgos que pueden no ser evidentes a través de otras métricas.
Además del rendimiento y la equidad, existen otros criterios útiles para una evaluación exhaustiva de los LLM. Esta sección destaca estos aspectos.
La fluidez evalúa la naturalidad y la corrección gramatical del texto generado. Un LLM fluido produce resultados fáciles de leer y comprender, imitando el flujo del lenguaje humano.
Esto puede evaluarse mediante herramientas automatizadas o el juicio humano, centrándose en aspectos como la gramática, la sintaxis y la legibilidad general.
La coherencia ayuda a analizar el flujo lógico y la consistencia del texto generado. Un texto coherente mantiene una estructura clara y una progresión lógica de las ideas, por lo que resulta fácil de seguir para los lectores. La coherencia es especialmente importante en textos más largos, como ensayos o artículos, en los que es fundamental mantener una narrativa coherente.
La Factualidad evalúa la exactitud de la información proporcionada por el LLM, especialmente en tareas de búsqueda de información. Esta métrica confirma que el modelo genera texto que no sólo es verosímil, sino también factualmente correcto.
La veracidad es indispensable para aplicaciones como la generación de noticias, los contenidos educativos y la atención al cliente, donde el objetivo principal es proporcionar información precisa.

Una evaluación sólida de los LLM implica integrar enfoques cuantitativos y cualitativos. Esta sección detalla una serie de metodologías, como conjuntos de datos de referencia, técnicas de evaluación humana y métodos de evaluación automatizada, para evaluar a fondo el rendimiento del LLM.
Los conjuntos de datos de referencia son herramientas valiosas para evaluar los LLM, ya que proporcionan tareas estandarizadas que permiten realizar análisis comparativos entre distintos modelos. Estos conjuntos de datos ayudan a establecer una línea de base para el rendimiento del modelo y facilitan la evaluación comparativa.
Los conjuntos de datos de referencia son herramientas importantes para evaluar los LLM, ya que proporcionan tareas estandarizadas que permiten realizar análisis comparativos entre distintos modelos. Algunos de los conjuntos de datos de referencia más populares para diversas tareas de procesamiento del lenguaje natural (PLN) son:
Aunque los puntos de referencia existentes tienen un valor incalculable, la creación de conjuntos de datos personalizados es vital para la evaluación específica del dominio. Los conjuntos de datos personalizados nos permiten adaptar el proceso de evaluación a los requisitos y retos exclusivos de la aplicación o industria específica.
Por ejemplo, un atención sanitaria podría crear un conjunto de datos de historiales médicos y notas clínicas para evaluar la capacidad de un LLM para manejar la terminología y el contexto médicos. Los conjuntos de datos personalizados garantizan que el rendimiento del modelo se ajuste a los casos de uso del mundo real, proporcionando información más relevante y procesable.
Los métodos de evaluación humana son indispensables para valorar los aspectos matizados de los resultados del LLM que las métricas automatizadas podrían pasar por alto. Estas técnicas implican la opinión directa de jueces humanos, lo que ofrece una visión cualitativa del rendimiento del modelo.
La evaluación humana sigue siendo una norma de oro para evaluar la calidad de los resultados de los LLM. Los métodos de evaluación directa consisten en recabar opiniones de jueces humanos mediante encuestas y escalas de valoración.
Estos métodos pueden captar aspectos matizados de la calidad del texto, como la fluidez, la coherencia y la relevancia, que las métricas automatizadas podrían pasar por alto. Los jueces humanos pueden proporcionar información cualitativa sobre puntos fuertes y débiles concretos, ayudando a identificar áreas específicas de mejora.
El juicio comparativo implica técnicas como la comparación por pares, en la que los evaluadores humanos comparan directamente los resultados de diferentes modelos. Este método puede ser más fiable que las escalas de valoración absoluta, ya que reduce la subjetividad asociada a las valoraciones individuales.
Se pide a los evaluadores que elijan el mejor resultado de los pares de textos generados, lo que proporciona una clasificación relativa del rendimiento del modelo. El juicio comparativo es especialmente útil para afinar los modelos y seleccionar las variantes más eficaces.
Los métodos de evaluación automatizados proporcionan una forma rápida y objetiva de evaluar el rendimiento del LLM. Estos métodos emplean diversas métricas para cuantificar distintos aspectos de los resultados de los modelos, garantizando una evaluación exhaustiva.
Las métricas automatizadas proporcionan una forma rápida y objetiva de evaluar el rendimiento del LLM. Métricas como la perplejidad y el BLEU se utilizan mucho para evaluar diversos aspectos de la generación de textos.
Como ya se ha dicho, la perplejidad mide la capacidad de predicción del modelo, y las puntuaciones más bajas indican un mejor rendimiento. BLEU, por su parte, evalúa la calidad del texto generado comparándolo con textos de referencia, centrándose en la precisión de n-gramas.
La evaluación adversarial implica someter a los LLM a ataques adversarios para comprobar su robustez. Estos ataques están diseñados para explotar los puntos débiles y los sesgos del modelo, revelando vulnerabilidades que podrían no ser evidentes mediante los métodos de evaluación estándar.
Un ataque adversario podría consistir en introducir datos ligeramente alterados o engañosos para analizar cómo responde el modelo. Este enfoque es útil para aplicaciones en las que la fiabilidad y la seguridad se tienen muy en cuenta, ya que ayuda a identificar y mitigar los riesgos potenciales.

Para evaluar eficazmente las capacidades de los LLM, debe seguirse un enfoque estratégico. Adoptar las mejores prácticas garantiza que tu proceso de evaluación sea exhaustivo, transparente y adaptado a tus requisitos exclusivos. Aquí cubrimos las mejores prácticas a seguir.
|
Buenas prácticas |
Descripción |
Caso de ejemplo |
Métrica(s) relevante(s) |
|
Definir objetivos claros |
Identifica las tareas y objetivos que debe alcanzar el LLM antes de iniciar el proceso de evaluación. |
Mejorar el rendimiento de la traducción automática de un LLM |
Puntuaciones BLEU/ROUGE |
|
Ten en cuenta a tu público |
Adapta la evaluación a los usuarios previstos del LLM, teniendo en cuenta sus expectativas y necesidades. |
LLM para generar texto |
Perplejidad, Fluidez, Coherencia |
|
Transparencia y reproducibilidad |
Asegúrate de que el proceso de evaluación esté bien documentado y pueda ser reproducido por otros para su verificación y mejora. |
Publicar el conjunto de datos de evaluación y el código utilizado para evaluar las capacidades del LLM |
Cualquier métrica relevante, dependiendo de la tarea específica y los objetivos de la evaluación |
Esta guía ha proporcionado una visión global de las métricas y metodologías esenciales para evaluar los LLM, desde la perplejidad y la precisión hasta las medidas de sesgo y equidad.
Empleando técnicas de evaluación tanto cuantitativas como cualitativas y ateniéndonos a las mejores prácticas, podemos garantizar una evaluación exhaustiva y fiable de estos modelos.
Con este conocimiento, estamos mejor equipados para seleccionar e implantar los LLM que mejor se adapten a nuestras necesidades, garantizando su rendimiento y fiabilidad óptimos dentro de las aplicaciones que elijamos.
Los mejores cursos de IA
programa
Curso
Curso
blog
Stanislav Karzhev
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan

