
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
Comencemos por analizar los componentes básicos fundamentales de LangGraph. Estos elementos nos permiten crear flujos de trabajo estructurados, con estado y escalables para desarrollar agentes de IA avanzados.
El estado es un objeto de memoria compartida que fluye a través del gráfico. Almacena toda la información relevante, como mensajes, variables, resultados intermedios e historial de decisiones. LangGraph gestiona el estado automáticamente, lo que hace que el desarrollo sea más eficiente.
Para complementar el estado, hay funciones de apoyo más avanzadas, como puntos de control, memoria local de subprocesos y persistencia entre sesiones. A lo largo de la ejecución, el estado se ejecuta continuamente, como se muestra en el siguiente diagrama: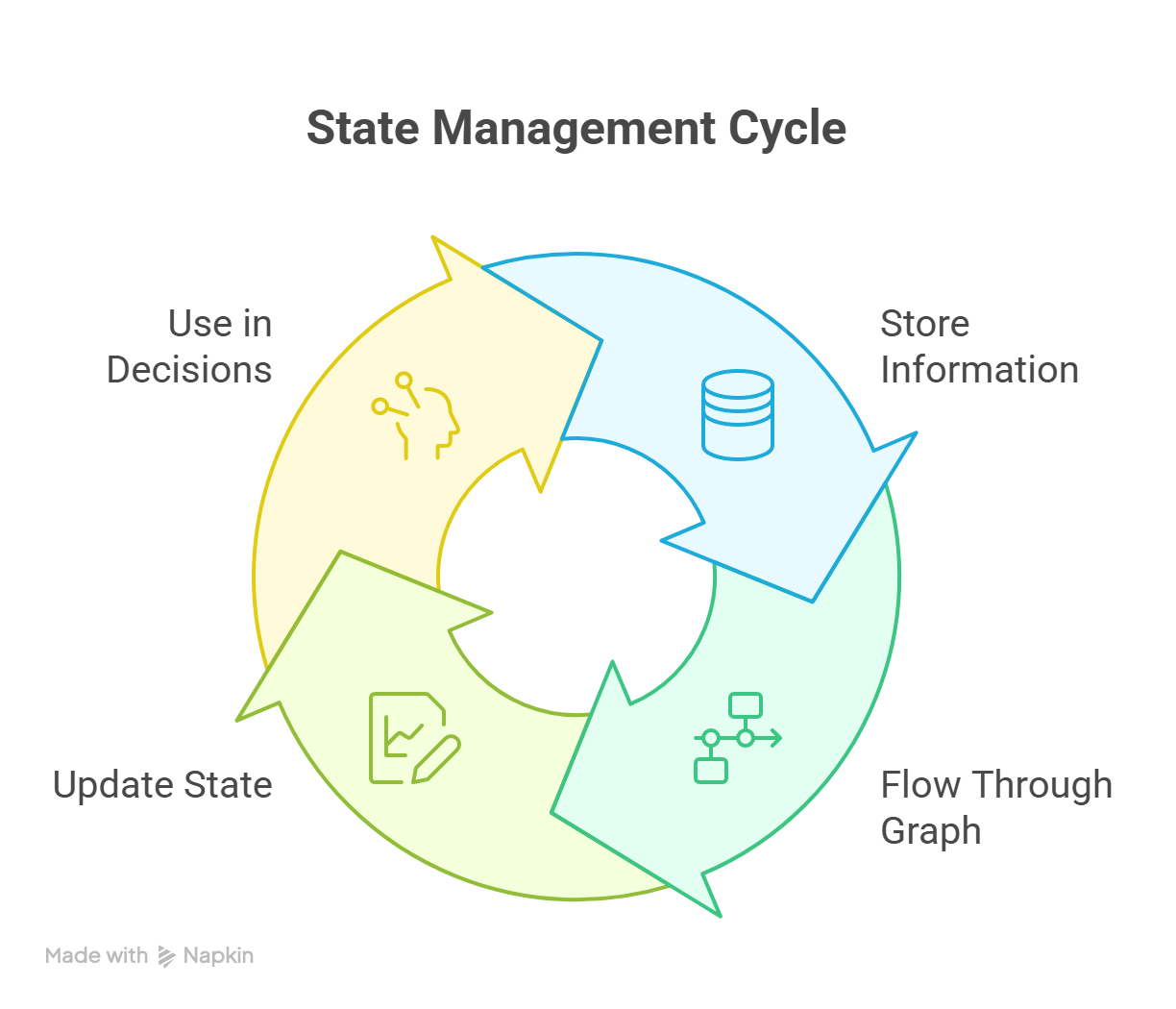 .
.
Ciclo de gestión estatal en LangGraph que muestra actualizaciones continuas en todos los nodos.
Un nodo es una unidad funcional única en el flujo de trabajo. Puede realizar diversasacciones e es, tales como:
Cada nodo toma el estado actual y devuelve un estado actualizado.
Los bordes definen las transiciones entre nodos. Determinan el flujo de control del gráfico y pueden admitir:
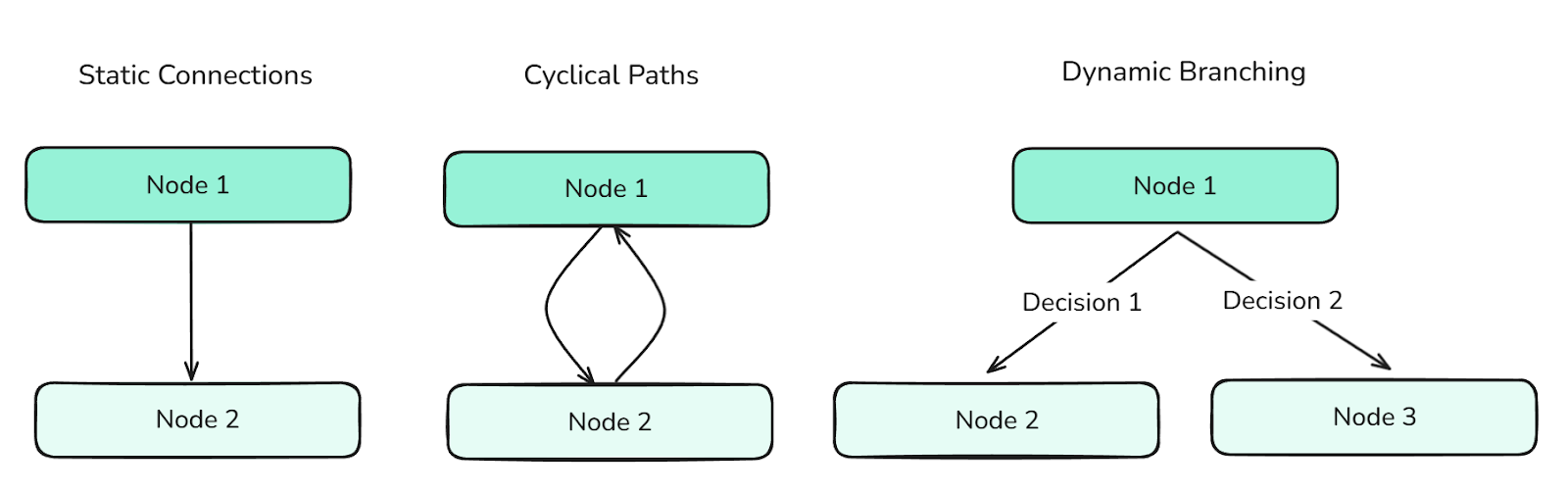
Los diferentes tipos de aristas definen el flujo entre los nodos y controlan la información a través del grafo.
Los bordes son esenciales para orquestar comportamientos complejos de los agentes.
Un gráfico en LangGraph define la estructura del flujo de trabajo agentico y consta de nodos conectados por aristas.
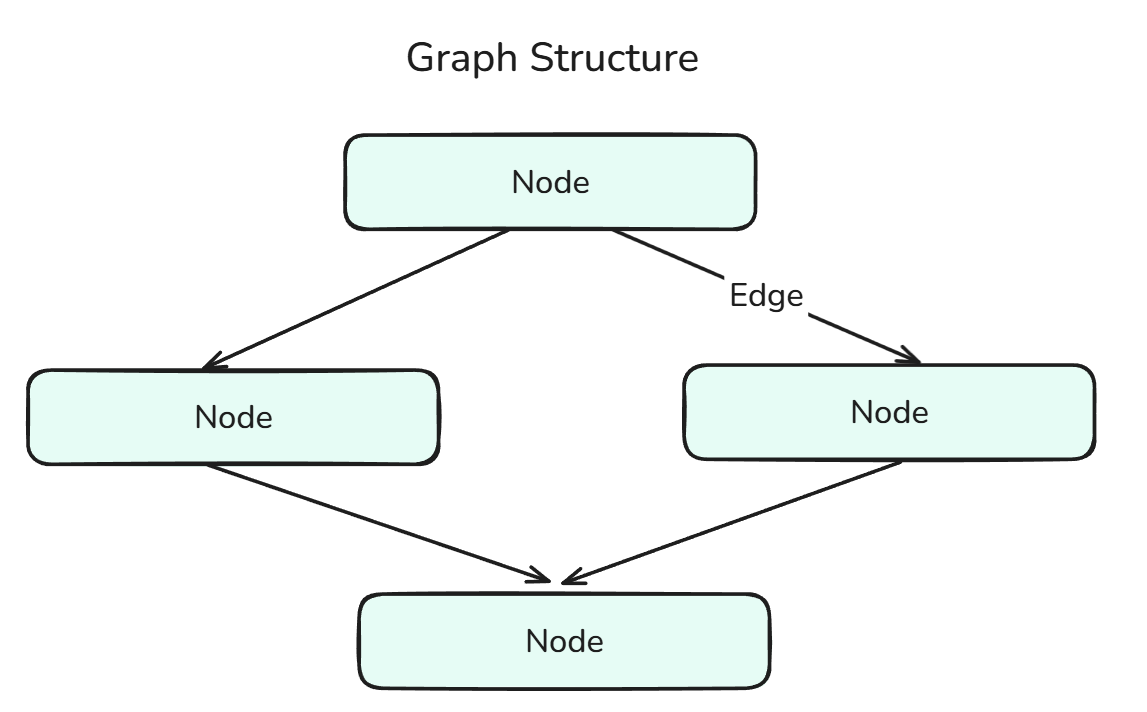
La estructura gráfica es una combinación de nodos y aristas.
El StateGraph es un gráfico especializado que mantiene y actualiza un estado compartido durante toda la ejecución. Permite tomar decisiones basadas en el contexto y mantener la memoria persistente a lo largo de todos los pasos. Podemos pensar en esto como la fusión de State y Graph.
Una herramienta es cualquier función externa o interna que un agente puede invocar, como una búsqueda web, una calculadora o una utilidad personalizada. Hay dos tipos de herramientas:
Un ToolNode es un tipo de nodo dedicado a la ejecución de herramientas dentro del gráfico. Nos permite a los programadores integrar herramientas sin escribir lógica adicional de envoltura. Podemos pensar en esto como la fusión de Tool y Node.
Los mensajes son elementos de datos estructurados (como la entrada del usuario, la salida del sistema, las respuestas intermedias, etc.) que se mueven a través del gráfico y se almacenan en el estado. Permiten la trazabilidad, el almacenamiento y el contexto de las decisiones de los agentes, lo que ayuda a tomar decisiones más informadas.
Hay varios tipos de mensajes en LangGraph:
HumanMessage, AIMessage o SystemMessage, hereda de BaseMessage.Ahora codificaremos estos agentes en LangGraph, centrándonos en comprender los diferentes métodos y pasos que intervienen en la codificación, así como en la visualización de estos agentes.
Empecemos por crear un único agente sin herramientas ni memoria. Empecemos con las importaciones:
from typing import TypedDict, List
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from dotenv import load_dotenvLa primera línea indica « TypedDict », que es una anotación de tipo definida así en Python:
from typing import TypedDict
class Student(TypedDict):
name: str
grade: float
s1: Student = {"name": "Sam", "grade": 92.5}Básicamente, un « TypedDict » es un diccionario que cuenta con sólidas medidas de seguridad de tipos, fundamentales para el desarrollo de agentes de IA.
HumanMessage Ya deberías estar familiarizado con esto, ya que lo hemos comentado anteriormente.
ChatOpenAI, sin embargo, es nuevo. Hagamos un pequeño desvío para explicarlo.
A través de Langchain, podemos utilizar la familia de bibliotecas de modelos de lenguaje ( Chat ), que básicamente nos permite utilizar modelos de muchos proveedores de LLM diferentes, como OpenAI, Anthropic, Ollama, etc., a través de sus respectivas bibliotecas, como ChatOpenAI, ChatAnthropic, ChatOllama, etc.
Básicamente, sus parámetros y uso son similares, lo que permite la modularidad en nuestro código. Puedes encontrar pasos más detallados en la documentación de LangChain.
Por último, el StateGraph que hemos cubierto anteriormente, y el Start y el End son los puntos inicial y final de nuestro gráfico.
Continuemos:
load_dotenv() # Obtaining over secret keys
# Creation of the state using a Typed Dictionary
class AgentState(TypedDict):
messages: List[HumanMessage] # We are going to be storing Human Messages (the user input) as a list of messages
llm = ChatOpenAI(model="gpt-4o") # Our model choice
# This is an action - the underlying function of our node
def process(state: AgentState) -> AgentState:
response = llm.invoke(state["messages"])
print(f"\nAI: {response.content}")
return state
graph = StateGraph(AgentState) # Initialization of a Graph
graph.add_node("process_node", process) # Adding nodes
graph.add_edge(START, "process_node") # Adding edges
graph.add_edge("process_node", END)
agent = graph.compile() # Compiling the graphAnalicemos con más detalle los métodos « .add_node() » y « .add_edge() ».
add.node(): Hay dos parámetros principales en los que debes centrarte: el nombre del nodo y la acción subyacente. La acción subyacente, en nuestro caso, « process() », es la lógica principal detrás del nodo, es decir, las acciones que se completan cuando llegamos a esta etapa. El nombre del nodo puede ser cualquiera, incluso el mismo que el de la función, aunque eso podría resultar bastante confuso a la hora de depurar.add_edge.(): De nuevo, hay dos parámetros principales en los que debes centrarte: los nodos inicial y final del borde. Ten en cuenta que lo que se introduce es el nombre del nodo, no la acción subyacente.Veamos un ejemplo práctico:
user_input = input("Enter: ")
while user_input != "exit":
agent.invoke({"messages": [HumanMessage(content=user_input)]})
user_input = input("Enter: ")El fragmento de código anterior nos permite llamar al agente varias veces. Visualmente hablando, el agente de IA que hemos construido tiene este aspecto:
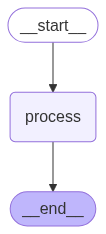
Un agente secuencial completa tareas paso a paso en un orden predefinido, sin ramificaciones ni razonamientos.
Para obtener dicha visualización, podemos utilizar el siguiente código (Nota: utilizamos el gráfico compilado):
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))Los agentes ReAct, agentes que razonan y actúan, son muy comunes en la industria debido a su facilidad de creación y su solidez. Dado que son tan comunes, LangGraph cuenta con un método integrado que podemos aprovechar para crear este tipo de agentes.
Afortunadamente, solo necesitamos dos importaciones adicionales:
from langgraph.prebuilt import create_react_agent
from langchain_google_community import GmailToolkitEl método ` create_react_agent ` es el que creará los agentes ReAct por nosotros.
tools = [GmailToolkit()] # We are using the Inbuilt Gmail tool
llm = ChatOllama(model="qwen2.5:latest") # Leveraging Ollama Models
agent = create_react_agent(
model = llm, # Choice of the LLM
tools = tools, # Tools we want our LLM to have
name = "email_agent", # Name of our agent
prompt = "You are my AI assistant that has access to certain tools. Use the tools to help me with my tasks.", # System Prompt
)Lo mejor de usar esto es que podemos crear múltiples agentes y arquitecturas más complejas.
También podemos crear nuestras propias herramientas personalizadas.
@tool
def send_email(email_address: str, email_content: str) -> str:
"""
Sends an email to a specified recipient with the given content.
Args:
email_address (str): The recipient's email address (e.g., 'example@example.com')
email_content (str): The body of the email message to be sent
Returns:
str: A confirmation message indicating success or failure
Example:
>>> send_email('john.doe@example.com', 'Hello John, just checking in!')
'Email successfully sent to john.doe@example.com'
"""
# Tool Logic goes here
return "Done!"Como se ha mencionado anteriormente, hay dos aspectos principales que son importantes a la hora de crear herramientas personalizadas:
Los agentes ReAct tienen este aspecto:
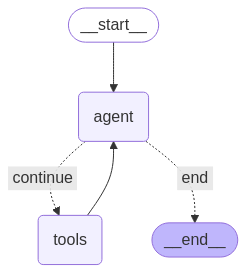
Un agente ReAct alterna entre el razonamiento (pensamientos) y las acciones para resolver tareas paso a paso.
Al definir el « State » (estado de la aplicación) para sistemas agenticos más complejos y robustos, es recomendable utilizar funciones reductoras (Reducer Functions) o simplemente reductoras ( reducers). Las reductoras ( reducers ) son anotaciones de datos que garantizan que cada vez que un nodo devuelve un mensaje, este se añade a la lista existente en el estado, en lugar de sobrescribir el valor anterior. Esto permite a nuestro estado crear el contexto.
# State with reducer function
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], operator.add]Este código integra la función reductora operator.add con el estado, garantizando que se conserven todos los mensajes.
En esta sección nos centraremos en un componente fundamental de todos los agentes: la memoria. La memoria es extremadamente importante para un agente, ya que proporciona el contexto necesario para hacerlo más robusto y fiable. Exploremos las diferentes formas en que podemos gestionar la memoria en nuestros agentes.
El estado ( ) es el elemento más importante en LangGraph y, naturalmente, hay múltiples formas de almacenar el estado externamente. Algunos de los dispositivos de almacenamiento externo más populares son:
Todas estas bibliotecas se pueden encontrar en la documentación.
Por ahora, veremos el SQLite:
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:") # This is for connecting to the SQLite database
graph = graph_builder.compile(checkpointer=memory) # Compiling graph with checkpointer as SQLite backendUso de SQLite es una forma sencilla de añadir persistencia a nuestros agentes. La persistencia es la capacidad de mantener el contexto en diferentes interacciones.
Todo esto es para almacenar y actualizar el estado. Ahora veamos cómo utilizar y gestionar ese estado de forma eficaz, especialmente la lista « messages », que se vuelve bastante grande a medida que avanza la conversación.
LangGraph proporciona soporte nativo para memoria de almacenamiento ( )a corto y largo plazo. Exploremos estas opciones.
La memoria a corto plazo permite a nuestros agentes recordar el historial de mensajes durante una sesión, lo que resulta útil para conversaciones de varios turnos.
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
# Invoking the Graph with our message
agent_graph.invoke(
{"messages": [{"role": "user", "content": "What's the weather today?"}]},
{"configurable": {"thread_id": "session_42"}},
)En el ejemplo anterior, el identificador de sesión ( thread_id ) se utiliza para identificar de forma única una conversación o sesión.
La memoria a largo plazo persiste a lo largo de varias sesiones y es perfecta para recordar cosas como nombres, objetivos o configuraciones, es decir, cosas importantes que se necesitan en todas las sesiones.
from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
long_term_store = InMemoryStore()
builder = StateGraph(...)
agent = builder.compile(store=long_term_store)Sin embargo, dado que nuestra conversación puede ser muy extensa, necesitamos una forma de limitar el historial de mensajes. Aquí es donde entra en juego el recorte.
En el ejemplo siguiente, eliminamos tokens del principio del historial de mensajes (debido a la línea: strategy="first") para que, tras el recorte, nos queden como máximo 150 tokens.
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
trimmed = trim_messages(
messages=state["messages"],
strategy="first", # remove the messages from beginning
token_counter=count_tokens_approximately,
max_tokens=150
)Otra forma de reducir el historial de mensajes es mediante la síntesis. Esto permite conservar información importante en todo el historial de mensajes, en lugar de simplemente recortar tokens de una parte de la conversación.
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
summary_node = SummarizationNode(
model=summary_llm, # Our summarization LLM
max_tokens=300, # Total token limit
max_tokens_before_summary=150, # when to start summarizing
max_summary_tokens=150, # summary size
token_counter=count_tokens_approximately
)Es importante señalar que la síntesis la realiza un LLM subyacente, en este caso summary_llm, que puede ser cualquier LLM.
La última operación principal necesaria en la gestión de memoria es Eliminar. Para eliminar los mensajes seleccionados, podemos utilizar este código:
from langchain_core.messages import RemoveMessage
def clean_state(state):
# Remove all tool-related messages
to_remove = [RemoveMessage(id=msg.id) for msg in state["messages"] if msg.role == "tool"]
return {"messages": to_remove}En el código anterior, hemos eliminado todos los mensajes relacionados con las herramientas, que podrían ser redundantes (ya que, en realidad, el Tool-Message es para el LLM elaborar su respuesta después de utilizar la herramienta).
Sin embargo, si queremos eliminar todo el historial de mensajes, podemos hacerlo así:
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain_core.messages import RemoveMessage
def reset_history(state):
# Remove entire conversation history
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}En general, LangGraph es una potente biblioteca que ofrece un enfoque estructurado y escalable para crear sistemas agenticos. Modelar la lógica como un gráfico de nodos y aristas, con estado compartido y memoria persistente, nos permite desarrollar agentes robustos que pueden razonar, interactuar y adaptarse con el tiempo.
A medida que los sistemas se vuelven más complejos, este marco proporciona las herramientas necesarias para gestionar la memoria, coordinar el uso de herramientas y mantener el contexto a largo plazo, todo ello sin perder su modularidad y capacidad de ampliación.
Ahora que ya tienes los componentes básicos, estás preparado para diseñar e implementar agentes de IA robustos capaces de gestionar flujos de trabajo del mundo real.
Para seguir aprendiendo, no te pierdas nuestro curso Creación de sistemas multiagente con LangGraph. También puedes consultar nuestro curso Diseño de sistemas agenticos con LangChain, así como nuestro tutorial sobre RAG agénico.
Cursos más populares de DataCamp
Curso
Curso
Curso
blog
blog
Abid Ali Awan
10 min
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Ryan Ong

