
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
Lass uns erst mal die grundlegenden Bausteine von LangGraph anschauen. Mit diesen Elementen können wir strukturierte, zustandsbehaftete und skalierbare Workflows für die Entwicklung fortschrittlicher KI-Agenten erstellen.
Der Status „ “ ist ein gemeinsames Speicherobjekt, das durch den Graphen fließt. Es speichert alle wichtigen Infos wie Nachrichten, Variablen, Zwischenergebnisse und den Verlauf der Entscheidungen. LangGraph kümmert sich automatisch um den Status, was die Entwicklung effizienter macht.
Um den Status zu ergänzen, gibt's noch ein paar coole Features wie Checkpointing, Thread-lokaler Speicher und Persistenz über mehrere Sitzungen hinweg. Während der ganzen Ausführung wird der Zustand immer weiter ausgeführt, wie im Diagramm unten gezeigt: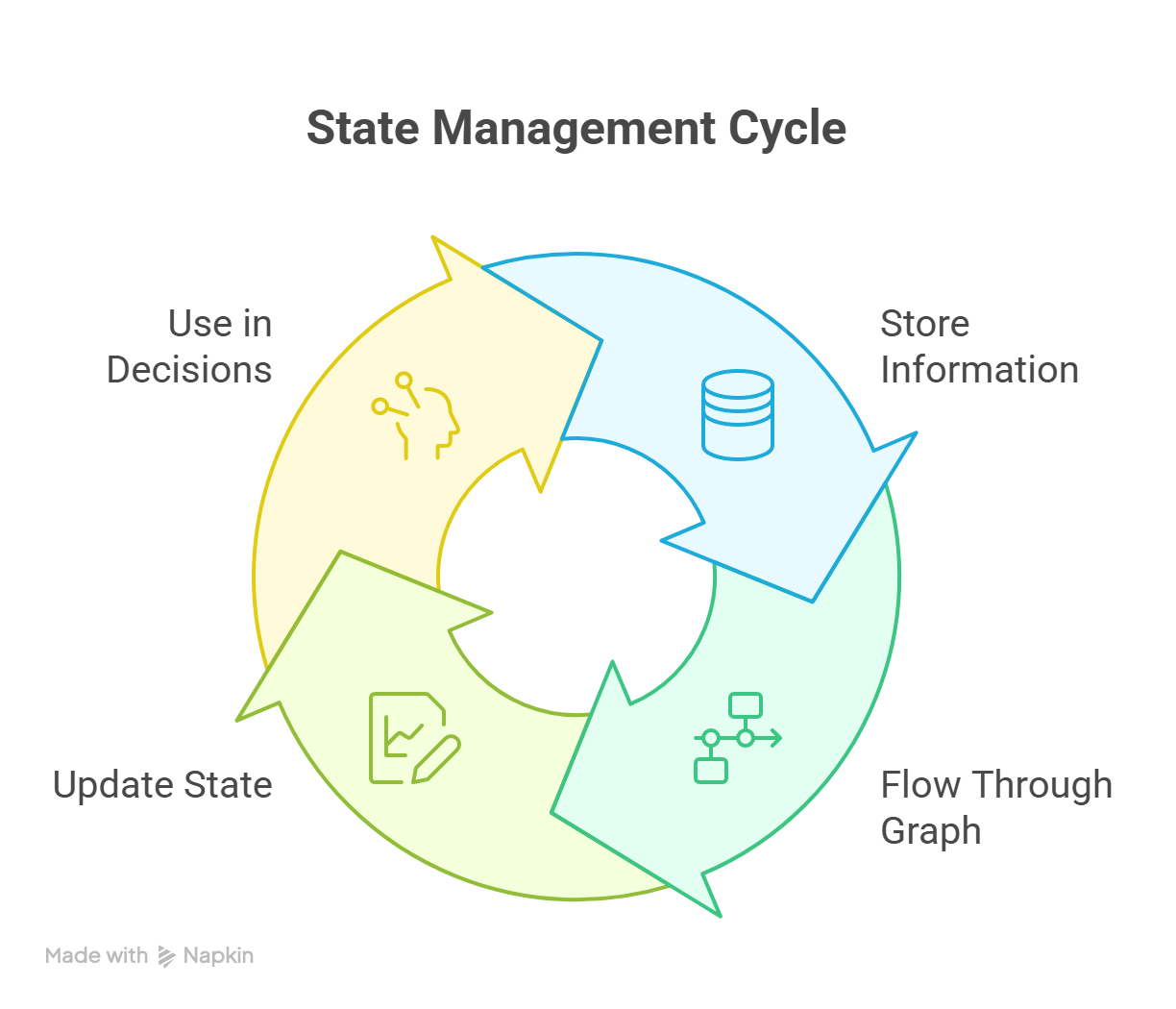
Zustandsverwaltungszyklus in LangGraph, der die ständigen Aktualisierungen über alle Knoten hinweg zeigt
Ein Knoten ist eine einzelne funktionelle Einheit im Arbeitsablauf. Es kann verschiedene„ “-Aktionen ausführen, zum Beispiel:
Jeder Knoten nimmt den aktuellen Status und gibt einen aktualisierten Status zurück.
Kanten zeigen, wie die Knoten miteinander verbunden sind. Sie bestimmen den Kontrollfluss des Graphen und können Folgendes unterstützen:
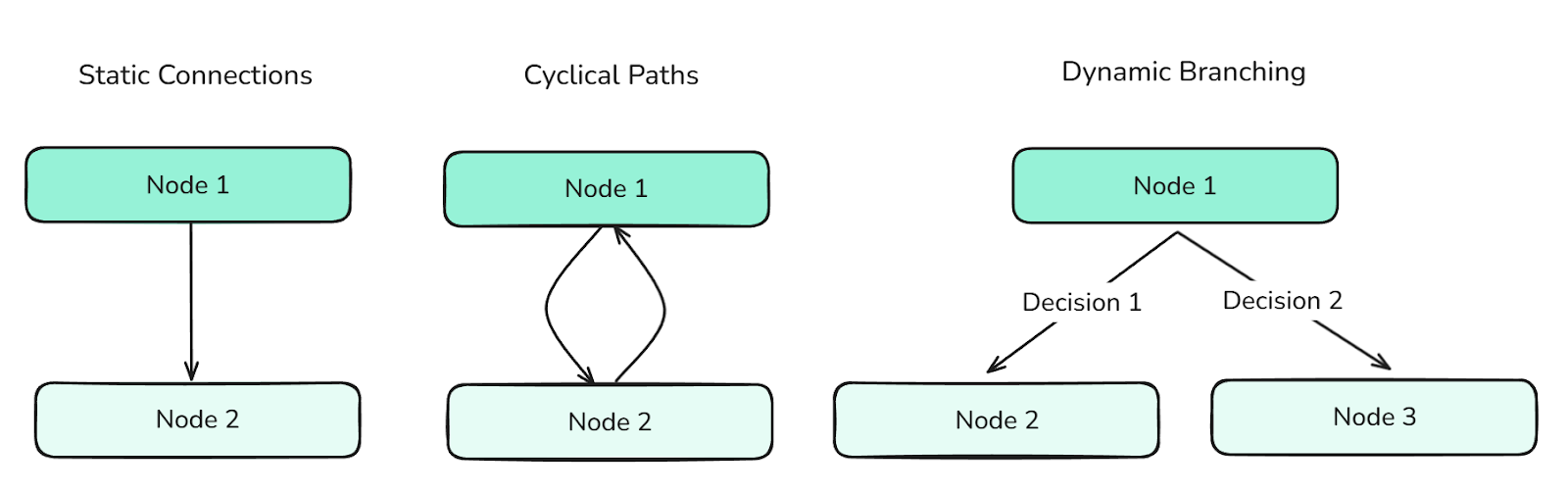
Verschiedene Arten von Kanten bestimmen den Fluss zwischen den Knoten und steuern die Infos im Graphen.
Kanten sind super wichtig, um komplexe Agentenverhalten zu koordinieren.
Ein Diagramm in LangGraph zeigt die Struktur des agentenbasierten Workflows und besteht aus Knoten, die durch Kanten verbunden sind.
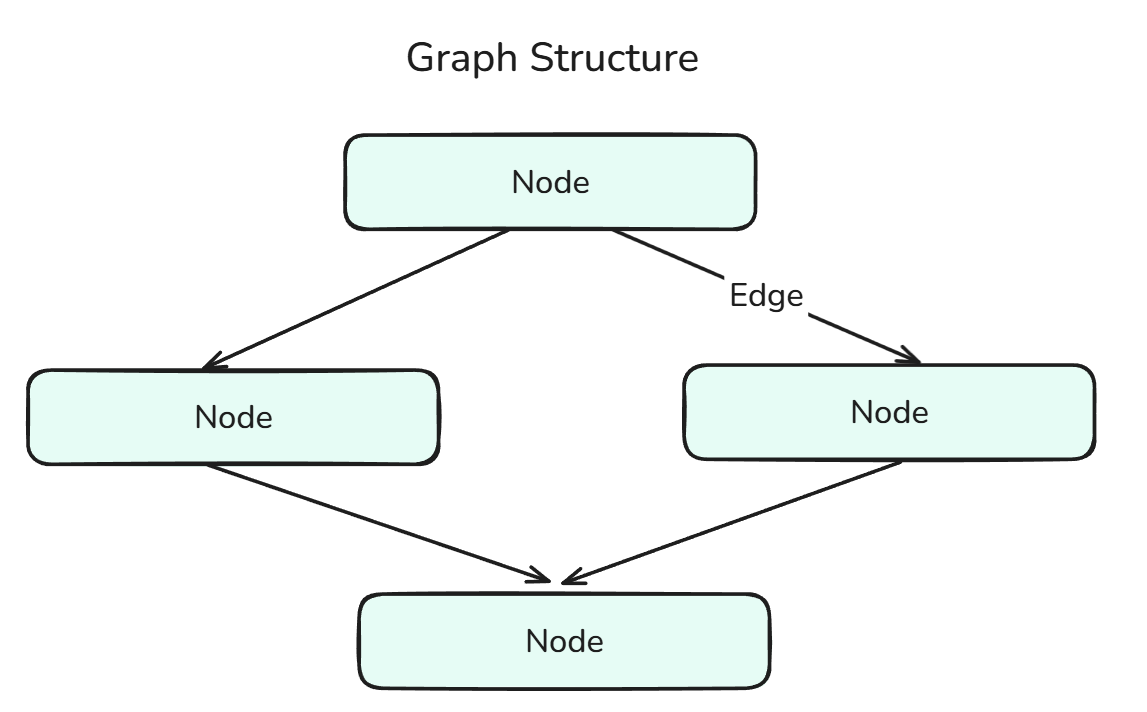
Eine Graphstruktur ist eine Kombination aus Knoten und Kanten.
Der StateGraph- ist ein spezielles Diagramm, das während der Ausführung einen gemeinsamen Status speichert und aktualisiert. Es ermöglicht kontextbezogene Entscheidungen und speichert alles über mehrere Schritte hinweg. Wir können uns das wie eine Mischung aus State und Graph vorstellen.
Ein Tool ist jede externe oder interne Funktion, die ein Agent aufrufen kann, z. B. eine Websuche, ein Taschenrechner oder ein benutzerdefiniertes Dienstprogramm. Es gibt zwei Arten von Tools:
Ein ToolNode- ist ein spezieller Knotentyp zum Ausführen von Tools innerhalb des Graphen. Damit können wir Entwickler Tools einbauen, ohne extra Wrapper-Logik schreiben zu müssen. Wir können uns das wie eine Mischung aus Tool und Node vorstellen.
Nachrichten „ “ sind strukturierte Datenelemente (wie Benutzereingaben, Systemausgaben, Zwischenantworten usw.), die durch den Graphen wandern und im Status gespeichert werden. Sie machen es möglich, Entscheidungen von Agenten nachzuvollziehen, zu speichern und in einen Kontext zu setzen, was dabei hilft, fundiertere Entscheidungen zu treffen.
In LangGraph gibt's mehrere MessageTypes:
HumanMessage “, „ AIMessage “ oder „ SystemMessage “ – kommt von „ BaseMessage “.Jetzt programmieren wir diese Agenten in LangGraph und schauen dabei genau, wie die verschiedenen Methoden und Schritte beim Programmieren funktionieren und wie man diese Agenten visualisieren kann.
Lass uns einen einzelnen Agenten ohne Tools oder Speicher erstellen. Fangen wir mit den Importen an:
from typing import TypedDict, List
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from dotenv import load_dotenvDie erste Zeile enthält „ TypedDict “, eine Typ-Anmerkung, die in Python wie folgt definiert ist:
from typing import TypedDict
class Student(TypedDict):
name: str
grade: float
s1: Student = {"name": "Sam", "grade": 92.5}Im Grunde ist ein „ TypedDict ” ein Wörterbuch mit starken Maßnahmen zur Typsicherheit, was für die Entwicklung von KI-Agenten echt wichtig ist.
HumanMessage Das solltest du jetzt schon kennen, weil wir das schon besprochen haben.
ChatOpenAIDas ist allerdings neu. Lass uns kurz abschweifen, um das zu erklären.
Mit Langchain können wir die „ Chat ”-Familie nutzen, die es uns im Grunde ermöglicht, Modelle von vielen verschiedenen LLM-Anbietern wie OpenAI, Anthropic, Ollama usw. über ihre jeweiligen Bibliotheken wie ChatOpenAI, ChatAnthropic, ChatOllama usw. zu verwenden.
Im Grunde sind ihre Einstellungen und wie man sie benutzt ziemlich ähnlich, was unseren Code modular macht. Genauere Schritte findest du in der LangChain-Dokumentation.
Zu guter Letzt sind die schon erwähnten Seiten „ StateGraph “, „ Start “ und „ End “ der Anfang und das Ende unseres Diagramms.
Weiter geht's:
load_dotenv() # Obtaining over secret keys
# Creation of the state using a Typed Dictionary
class AgentState(TypedDict):
messages: List[HumanMessage] # We are going to be storing Human Messages (the user input) as a list of messages
llm = ChatOpenAI(model="gpt-4o") # Our model choice
# This is an action - the underlying function of our node
def process(state: AgentState) -> AgentState:
response = llm.invoke(state["messages"])
print(f"\nAI: {response.content}")
return state
graph = StateGraph(AgentState) # Initialization of a Graph
graph.add_node("process_node", process) # Adding nodes
graph.add_edge(START, "process_node") # Adding edges
graph.add_edge("process_node", END)
agent = graph.compile() # Compiling the graphLass uns die Methoden „ .add_node() “ und „ .add_edge() “ genauer anschauen.
add.node(): Es gibt zwei wichtige Sachen, auf die du achten musst: den Namen des Knotens und die Aktion, die dahintersteckt. Die zugrunde liegende Aktion, in unserem Fall „ process() ”, ist die Hauptlogik hinter dem Knoten, also die Aktionen, die ausgeführt werden, wenn wir diese Stufe erreichen. Der Name des Knotens kann beliebig sein, sogar derselbe wie die Funktion, obwohl das beim Debuggen ziemlich verwirrend sein kann!add_edge.(): Es gibt wieder zwei Hauptparameter, auf die du achten musst, nämlich den Start- und den Endknoten der Kante. Beachte, dass der Name des Knotens eingegeben wird, nicht die zugrunde liegende Aktion.Schauen wir uns mal ein praktisches Beispiel an:
user_input = input("Enter: ")
while user_input != "exit":
agent.invoke({"messages": [HumanMessage(content=user_input)]})
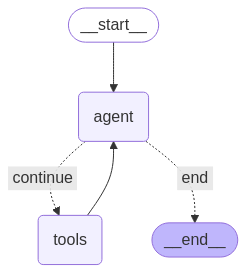
user_input = input("Enter: ")Mit dem obigen Code können wir den Agenten mehrmals aufrufen. Optisch sieht der von uns entwickelte KI-Agent so aus:
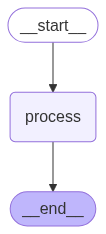
Ein sequenzieller Agent erledigt Aufgaben Schritt für Schritt in einer festgelegten Reihenfolge, ohne abzuzweigen oder zu überlegen.
Um so was zu sehen, kannst du den folgenden Code nehmen (Achtung: Wir benutzen den kompilierten Graphen):
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))ReAct-Agenten, also Agenten, die denken und handeln können, sind in der Industrie echt weit verbreitet, weil sie einfach zu erstellen und trotzdem robust sind. Da sie so häufig vorkommen, hat LangGraph eine eingebaute Methode, mit der wir solche Agenten erstellen können.
Zum Glück brauchen wir nur zwei zusätzliche Importe:
from langgraph.prebuilt import create_react_agent
from langchain_google_community import GmailToolkitDie Methode „ create_react_agent “ erstellt die ReAct-Agenten für uns.
tools = [GmailToolkit()] # We are using the Inbuilt Gmail tool
llm = ChatOllama(model="qwen2.5:latest") # Leveraging Ollama Models
agent = create_react_agent(
model = llm, # Choice of the LLM
tools = tools, # Tools we want our LLM to have
name = "email_agent", # Name of our agent
prompt = "You are my AI assistant that has access to certain tools. Use the tools to help me with my tasks.", # System Prompt
)Das Beste daran ist, dass wir mehrere Agenten erstellen und komplexere Architekturen aufbauen können.
Wir können auch unsere eigenen Tools machen.
@tool
def send_email(email_address: str, email_content: str) -> str:
"""
Sends an email to a specified recipient with the given content.
Args:
email_address (str): The recipient's email address (e.g., 'example@example.com')
email_content (str): The body of the email message to be sent
Returns:
str: A confirmation message indicating success or failure
Example:
>>> send_email('john.doe@example.com', 'Hello John, just checking in!')
'Email successfully sent to john.doe@example.com'
"""
# Tool Logic goes here
return "Done!"Wie oben erwähnt, gibt es zwei wichtige Punkte, die bei der Erstellung benutzerdefinierter Tools zu beachten sind:
ReAct-Agenten sehen so aus:
Ein ReAct-Agent wechselt zwischen Überlegungen (Gedanken) und Aktionen, um Aufgaben Schritt für Schritt zu lösen.
Wenn du die „ State ” für kompliziertere, robuste agentenbasierte Systeme festlegst, ist es eine gute Idee, „Reducer Functions” oder einfach „ reducers ” zu verwenden. „ reducers ” sind Datenanmerkungen, die dafür sorgen, dass jedes Mal, wenn ein Knoten eine Nachricht zurücksendet, diese an die vorhandene Liste im Status angehängt wird, anstatt den vorherigen Wert zu überschreiben. So kann unser Staat den Kontext aufbauen.
# State with reducer function
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], operator.add]Dieser Code verbindet die Reduzierungsfunktion „ operator.add “ mit dem Status, sodass alle Nachrichten erhalten bleiben.
In diesem Abschnitt geht's um einen wichtigen Teil von jedem Agenten – den Speicher. Das Gedächtnis ist für einen Agenten super wichtig, weil es den Kontext liefert, den er braucht, um robuster und zuverlässiger zu sein. Schauen wir mal, wie wir den Speicher in unseren Agenten verwalten können.
Der Zustands ist das wichtigste Element in LangGraph, und natürlich gibt es mehrere Möglichkeiten, den Zustand extern zu speichern. Einige der beliebtesten externen Speichermedien sind:
Alle diese Bibliotheken findest du in der Dokumentation.
Jetzt schauen wir uns mal SQLite an:
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:") # This is for connecting to the SQLite database
graph = graph_builder.compile(checkpointer=memory) # Compiling graph with checkpointer as SQLite backendMit SQLite SQLite ist eine einfache Möglichkeit, unseren Agenten Persistenz hinzuzufügen. Beharrlichkeit ist die Fähigkeit, den Zusammenhang zwischen verschiedenen Interaktionen aufrechtzuerhalten.
Das ist alles zum Speichern und Aktualisieren des Status. Schauen wir uns jetzt an, wie man diesen Status effektiv nutzt und verwaltet, vor allem die Liste „ messages “, die mit fortschreitender Konversation ziemlich lang wird.
LangGraph bietet native Unterstützung für Kurzzeit- und Langzeit sspeicher. Schauen wir uns das mal an.
Dank Kurzzeitgedächtnis können sich unsere Agenten den Nachrichtenverlauf während einer Sitzung merken, was bei Gesprächen mit mehreren Runden echt praktisch ist.
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
# Invoking the Graph with our message
agent_graph.invoke(
{"messages": [{"role": "user", "content": "What's the weather today?"}]},
{"configurable": {"thread_id": "session_42"}},
)Im obigen Beispiel wird die „ thread_id “ verwendet, um eine Unterhaltung oder Sitzung eindeutig zu identifizieren.
Das Langzeitgedächtnis bleibt über mehrere Sitzungen hinweg erhalten und eignet sich super zum Speichern von Namen, Zielen oder Einstellungen – also wichtigen Sachen, die man immer wieder braucht.
from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
long_term_store = InMemoryStore()
builder = StateGraph(...)
agent = builder.compile(store=long_term_store)Da unsere Unterhaltung aber ziemlich lang werden kann, brauchen wir eine Möglichkeit, den Verlauf unserer Nachrichten zu begrenzen. Hier kommt das Trimmen ins Spiel.
Im folgenden Beispiel löschen wir Tokens vom Anfang des Nachrichtenverlaufs (wegen der Zeile: strategy="first"), sodass nach dem Trimmen höchstens 150 Tokens übrig bleiben.
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
trimmed = trim_messages(
messages=state["messages"],
strategy="first", # remove the messages from beginning
token_counter=count_tokens_approximately,
max_tokens=150
)Eine andere Möglichkeit, den Nachrichtenverlauf zu verkürzen, ist die Zusammenfassung. So bleiben wichtige Infos im ganzen Nachrichtenverlauf erhalten, statt dass nur Teile aus der Unterhaltung rausgeschnitten werden.
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
summary_node = SummarizationNode(
model=summary_llm, # Our summarization LLM
max_tokens=300, # Total token limit
max_tokens_before_summary=150, # when to start summarizing
max_summary_tokens=150, # summary size
token_counter=count_tokens_approximately
)Wichtig ist, dass die Zusammenfassung von einem zugrunde liegenden LLM gemacht wird, in diesem Fall summary_llm, das kann aber irgendein LLM sein.
Der letzte wichtige Schritt beim Speichermanagement ist das Löschen. Um ausgewählte Nachrichten zu löschen, kannst du diesen Code verwenden:
from langchain_core.messages import RemoveMessage
def clean_state(state):
# Remove all tool-related messages
to_remove = [RemoveMessage(id=msg.id) for msg in state["messages"] if msg.role == "tool"]
return {"messages": to_remove}Im obigen Code haben wir alle toolbezogenen Meldungen gelöscht, die überflüssig sein könnten (da realistisch gesehen die Tool-Message für die LLM dazu dient, nach der Verwendung des Tools eine Antwort zu erstellen).
Wenn wir aber den ganzen Nachrichtenverlauf löschen wollen, können wir das so machen:
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain_core.messages import RemoveMessage
def reset_history(state):
# Remove entire conversation history
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}Insgesamt ist LangGraph eine starke Bibliothek, die einen strukturierten und skalierbaren Ansatz zum Aufbau von agentenbasierten Systemen bietet. Wenn wir Logik als ein Diagramm aus Knoten und Kanten mit gemeinsamem Status und dauerhaftem Speicher modellieren, können wir robuste Agenten entwickeln, die denken, interagieren und sich im Laufe der Zeit anpassen können.
Wenn Systeme immer komplexer werden, bietet dieses Framework die Tools, die man braucht, um den Speicher zu verwalten, die Nutzung von Tools zu koordinieren und den Kontext langfristig beizubehalten – und das alles modular und erweiterbar.
Jetzt, wo die wichtigsten Teile fertig sind, kannst du robuste KI-Agenten entwickeln und einsetzen, die echte Arbeitsabläufe im Alltag meistern.
Wenn du weiterlernen willst, schau dir unbedingt unseren Kurs „ „Multi-Agent-Systeme mit LangGraph erstellen“an. Du kannst dir auch unseren Kurs „ Kurs „Entwerfen agenterischer Systeme mit LangChain”und unser Tutorial zu „Agentic RAG“ansehen.
Top-Kurse von DataCamp
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
