
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.1K
Commençons par examiner les éléments fondamentaux de LangGraph. Ces éléments nous permettent de créer des flux de travail structurés, avec état et évolutifs pour développer des agents IA avancés.
L'état est un objet de mémoire partagée qui circule dans le graphe. Il stocke toutes les informations pertinentes telles que les messages, les variables, les résultats intermédiaires et l'historique des décisions. LangGraph gère automatiquement l'état, ce qui rend le développement plus efficace.
Pour compléter le système d'état, des fonctionnalités avancées sont disponibles, telles que les points de contrôle, la mémoire locale par thread et la persistance entre sessions. 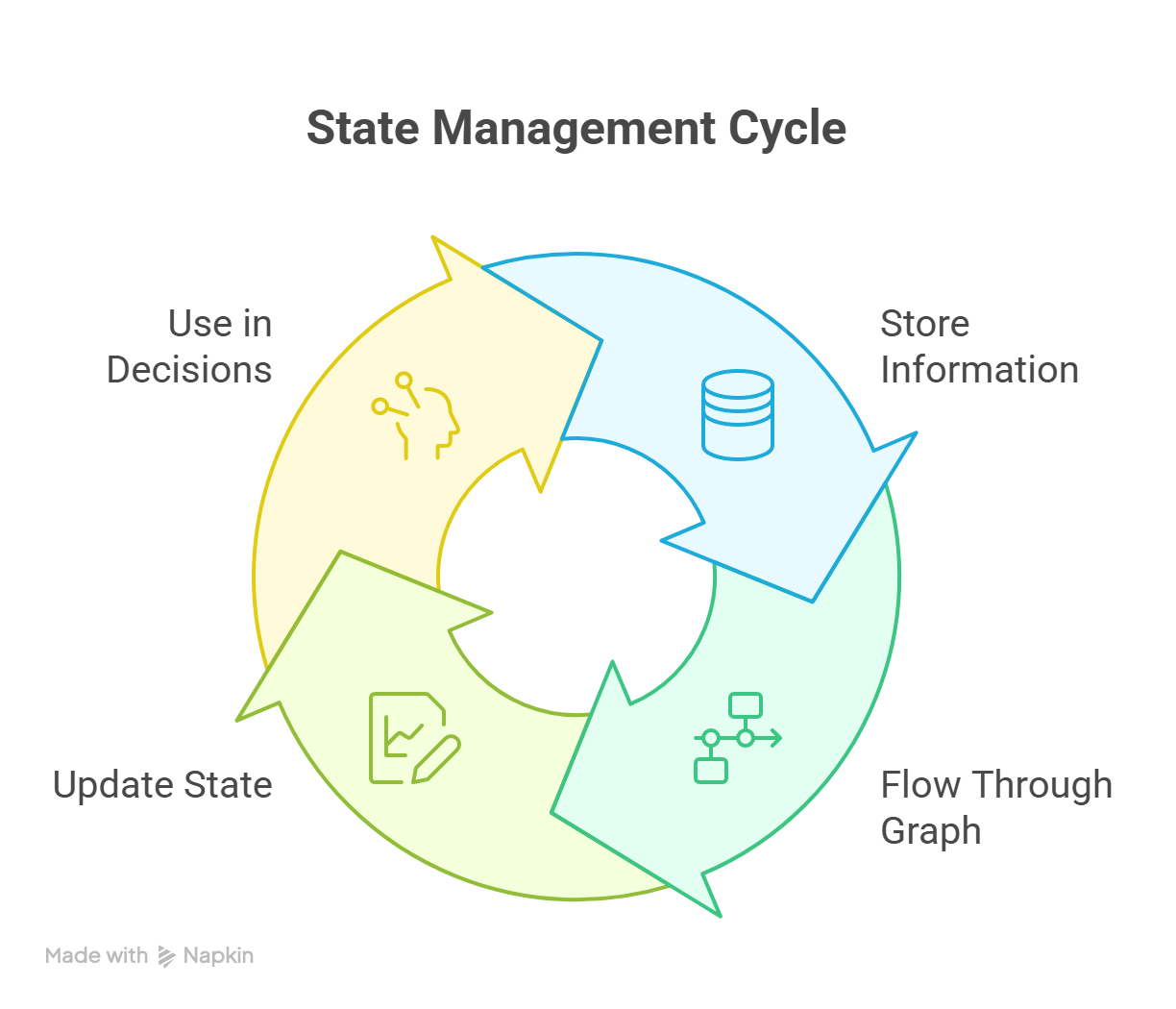 Tout au long de l'exécution, l'état est exécuté en continu, comme illustré dans le diagramme ci-dessous :
Tout au long de l'exécution, l'état est exécuté en continu, comme illustré dans le diagramme ci-dessous :
Cycle de gestion d'état dans LangGraph montrant les mises à jour continues entre les nœuds
Une unité fonctionnellede nœud est une unité fonctionnelle unique dans le flux de travail. Il peut effectuer diversesactions d', telles que :
Chaque nœud prend en compte l'état actuel et renvoie un état mis à jour.
Les arêtes définissent les transitions entre les nœuds. Ils déterminent le flux de contrôle du graphe et peuvent prendre en charge :
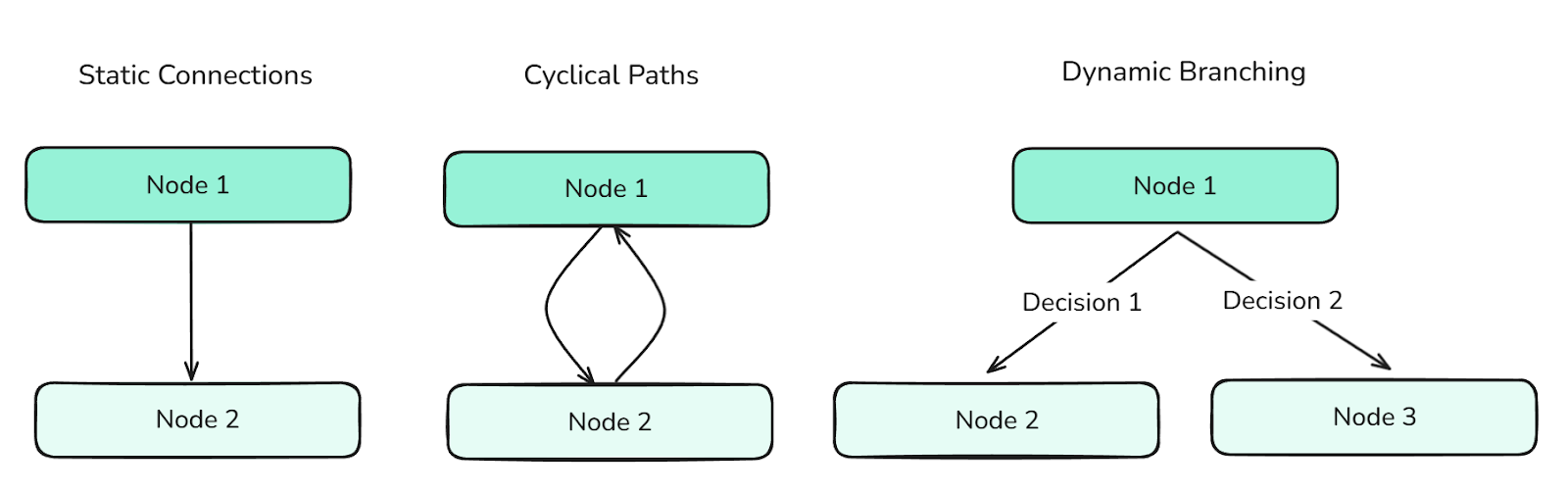
Différents types d'arêtes définissent le flux entre les nœuds et contrôlent les informations à travers le graphe.
Les arêtes sont essentielles pour orchestrer les comportements complexes des agents.
Un graphique dans LangGraph définit la structure du flux de travail agentique et se compose de nœuds reliés par des arêtes.
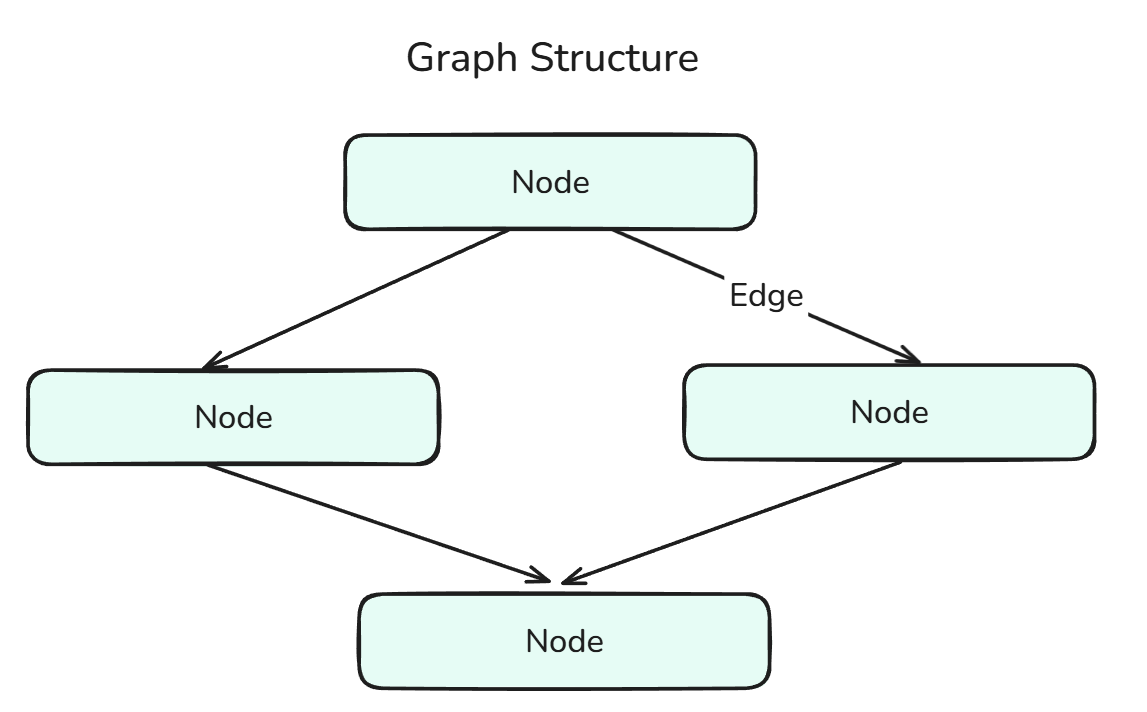
La structure graphique est une combinaison de nœuds et d'arêtes.
L' StateGraph est un graphe spécialisé qui maintient et met à jour un état partagé tout au long de l'exécution. Il permet une prise de décision contextuelle et une mémoire persistante à toutes les étapes. Nous pouvons considérer cela comme la fusion de State et Graph.
Un outil est toute fonction externe ou interne qu'un agent peut appeler, telle qu'une recherche sur le Web, une calculatrice ou un utilitaire personnalisé. Il existe deux types d'outils :
Un ToolNode est un type de nœud dédié à l'exécution d'outils au sein du graphe. Cela nous permet, en tant que développeurs, d'intégrer des outils sans avoir à écrire de code supplémentaire. Nous pouvons considérer cela comme la fusion de Tool et Node.
Les messages sont des éléments de données structurés (tels que les entrées utilisateur, les sorties système, les réponses intermédiaires, etc.) qui se déplacent dans le graphe et sont stockés dans l'état. Ils permettent la traçabilité, la mémorisation et la contextualisation des décisions des agents, ce qui contribue à la prise de décisions plus éclairées.
Il existe plusieurs types de messages dans LangGraph :
HumanMessage, AIMessage ou SystemMessage, hérite de BaseMessage.Nous allons maintenant coder ces agents dans LangGraph, en nous concentrant sur la compréhension des différentes méthodes et étapes impliquées dans le codage ainsi que dans la visualisation de ces agents.
Commençons par créer un seul agent sans outils ni mémoire. Commençons par les importations :
from typing import TypedDict, List
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from dotenv import load_dotenvLa première ligne indique l'TypedDict, qui est une annotation de type définie comme suit en Python :
from typing import TypedDict
class Student(TypedDict):
name: str
grade: float
s1: Student = {"name": "Sam", "grade": 92.5}Essentiellement, un dictionnaire de type ( TypedDict ) est un dictionnaire doté de mesures robustes de sécurité des types, essentielles pour le développement d'agents IA.
HumanMessage Vous devriez maintenant être familier avec ce concept, car nous en avons déjà discuté précédemment.
ChatOpenAICependant, ce qui est nouveau, c'est que Faisons un petit détour pour expliquer cela.
Grâce à Langchain, nous pouvons utiliser la famille d'outils d'interface utilisateur ( Chat ), qui nous permet essentiellement d'utiliser des modèles provenant de nombreux fournisseurs de LLM différents, tels que OpenAI, Anthropic, Ollama, etc., via leurs bibliothèques respectives, telles que ChatOpenAI, ChatAnthropic, ChatOllama, etc.
Fondamentalement, leurs paramètres et leur utilisation sont similaires, ce qui permet une modularité dans notre code. Vous trouverez des étapes plus détaillées dans la documentation LangChain. documentation LangChain.
Enfin, l'StateGraph, que nous avons déjà mentionné, ainsi que les sites Start et End constituent les points de départ et d'arrivée de notre graphique.
Continuons :
load_dotenv() # Obtaining over secret keys
# Creation of the state using a Typed Dictionary
class AgentState(TypedDict):
messages: List[HumanMessage] # We are going to be storing Human Messages (the user input) as a list of messages
llm = ChatOpenAI(model="gpt-4o") # Our model choice
# This is an action - the underlying function of our node
def process(state: AgentState) -> AgentState:
response = llm.invoke(state["messages"])
print(f"\nAI: {response.content}")
return state
graph = StateGraph(AgentState) # Initialization of a Graph
graph.add_node("process_node", process) # Adding nodes
graph.add_edge(START, "process_node") # Adding edges
graph.add_edge("process_node", END)
agent = graph.compile() # Compiling the graphExaminons plus en détail les méthodes « .add_node() » et « .add_edge() ».
add.node(): Il existe deux paramètres principaux sur lesquels vous devez vous concentrer : le nom du nœud et l'action sous-jacente. Dans notre cas, l'action sous-jacente - process() - constitue la logique principale derrière le nœud, c'est-à-dire les actions qui sont effectuées lorsque nous arrivons à cette étape. Le nom du nœud peut être n'importe quoi, même le même que celui de la fonction, bien que cela puisse prêter à confusion lors du débogage.add_edge.(): Il y a à nouveau deux paramètres principaux sur lesquels vous devez vous concentrer, à savoir les nœuds de début et de fin de l'arête. Veuillez noter que c'est le nom du nœud qui est saisi, et non l'action sous-jacente.Prenons un exemple concret :
user_input = input("Enter: ")
while user_input != "exit":
agent.invoke({"messages": [HumanMessage(content=user_input)]})
user_input = input("Enter: ")Le code ci-dessus nous permet d'appeler l'agent plusieurs fois. Visuellement, l'agent IA que nous avons conçu se présente comme suit :
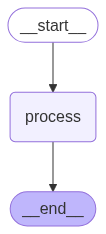
Un agent séquentiel exécute des tâches étape par étape dans un ordre prédéfini, sans ramification ni raisonnement.
Pour obtenir une telle visualisation, nous pouvons utiliser le code suivant (remarque : nous utilisons le graphique compilé) :
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))Les agents ReAct, agents raisonnants et agissants, sont extrêmement courants dans l'industrie, en raison de leur facilité de création et de leur robustesse. Étant donné leur grande fréquence, LangGraph dispose d'une méthode intégrée que nous pouvons exploiter pour créer de tels agents.
Heureusement, nous n'avons besoin que de deux importations supplémentaires :
from langgraph.prebuilt import create_react_agent
from langchain_google_community import GmailToolkitLa méthode create_react_agent permet de créer les agents ReAct pour nous.
tools = [GmailToolkit()] # We are using the Inbuilt Gmail tool
llm = ChatOllama(model="qwen2.5:latest") # Leveraging Ollama Models
agent = create_react_agent(
model = llm, # Choice of the LLM
tools = tools, # Tools we want our LLM to have
name = "email_agent", # Name of our agent
prompt = "You are my AI assistant that has access to certain tools. Use the tools to help me with my tasks.", # System Prompt
)L'avantage principal de cette solution réside dans la possibilité de créer plusieurs agents et des architectures plus complexes.
Nous pouvons également créer nos propres outils personnalisés.
@tool
def send_email(email_address: str, email_content: str) -> str:
"""
Sends an email to a specified recipient with the given content.
Args:
email_address (str): The recipient's email address (e.g., 'example@example.com')
email_content (str): The body of the email message to be sent
Returns:
str: A confirmation message indicating success or failure
Example:
>>> send_email('john.doe@example.com', 'Hello John, just checking in!')
'Email successfully sent to john.doe@example.com'
"""
# Tool Logic goes here
return "Done!"Comme indiqué précédemment, deux éléments principaux sont importants lors de la création d'outils personnalisés :
Les agents ReAct se présentent comme suit :
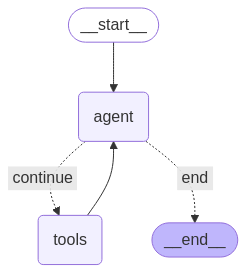
Un agent ReAct alterne entre le raisonnement (pensées) et les actions pour résoudre des tâches étape par étape.
Lors de la définition de l'State e pour des systèmes agentique plus complexes et robustes, il est recommandé d'utiliser des fonctions réductrices ou simplement des « reducers ». Les « reducers » sont des annotations de données qui garantissent que chaque fois qu'un nœud renvoie un message, celui-ci est ajouté à la liste existante dans l'état, plutôt que de remplacer la valeur précédente. Cela permet à notre État de mettre en place le contexte.
# State with reducer function
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], operator.add]Ce code intègre la fonction réductrice operator.add à l'état, garantissant ainsi que tous les messages sont conservés.
Dans cette section, nous nous intéresserons à un composant essentiel de tout agent : la mémoire. La mémoire est extrêmement importante pour un agent, car elle fournit le contexte nécessaire pour le rendre plus robuste et fiable. Explorons les différentes façons de gérer la mémoire dans nos agents.
L'état ( ) est l'élément le plus important dans LangGraph, et il existe naturellement plusieurs façons de stocker l'état en externe. Voici quelques-uns des périphériques de stockage externes les plus populaires :
Toutes ces bibliothèques sont disponibles dans la documentation. documentation.
Pour l'instant, nous allons examiner SQLite :
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:") # This is for connecting to the SQLite database
graph = graph_builder.compile(checkpointer=memory) # Compiling graph with checkpointer as SQLite backendUtilisation de SQLite est un moyen simple d'ajouter la persistance à nos agents. La persistance est la capacité à maintenir le contexte à travers différentes interactions.
Tout cela sert à stocker et à mettre à jour l'état. Voyons maintenant comment utiliser et gérer efficacement cet état, en particulier la liste d'messages, qui devient assez longue à mesure que la conversation se poursuit.
LangGraph offre une prise en charge native de la mémoire vive ( )à court et à long terme. Explorons-les.
La mémoire à court terme permet à nos agents de se souvenir de l'historique des messages pendant une session, ce qui est utile pour les conversations à plusieurs tours.
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
# Invoking the Graph with our message
agent_graph.invoke(
{"messages": [{"role": "user", "content": "What's the weather today?"}]},
{"configurable": {"thread_id": "session_42"}},
)Dans l'exemple ci-dessus, l'thread_id est utilisé pour identifier de manière unique une conversation ou une session.
La mémoire à long terme persiste au-delà de plusieurs sessions et est idéale pour se souvenir de choses telles que des noms, des objectifs ou des paramètres, c'est-à-dire des éléments importants qui sont nécessaires d'une session à l'autre.
from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
long_term_store = InMemoryStore()
builder = StateGraph(...)
agent = builder.compile(store=long_term_store)Cependant, comme notre conversation peut devenir longue, nous avons besoin d'un moyen de limiter l'historique de nos messages. C'est là que le rognage entre en jeu.
Dans l'exemple ci-dessous, nous supprimons les tokens au début de l'historique des messages (en raison de la ligne : strategy="first") afin qu'après le rognage, il ne reste au maximum que 150 tokens.
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
trimmed = trim_messages(
messages=state["messages"],
strategy="first", # remove the messages from beginning
token_counter=count_tokens_approximately,
max_tokens=150
)Une autre méthode pour réduire l'historique des messages consiste à les résumer. Cela permet de conserver les informations importantes dans l'historique des messages, plutôt que de simplement supprimer des tokens d'une partie de la conversation.
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
summary_node = SummarizationNode(
model=summary_llm, # Our summarization LLM
max_tokens=300, # Total token limit
max_tokens_before_summary=150, # when to start summarizing
max_summary_tokens=150, # summary size
token_counter=count_tokens_approximately
)Il est important de noter que la synthèse est effectuée par un LLM sous-jacent, dans ce cas summary_llm, qui peut être n'importe quel LLM.
La dernière opération principale requise dans la gestion de la mémoire est la suppression. Pour supprimer les messages sélectionnés, nous pouvons utiliser ce code :
from langchain_core.messages import RemoveMessage
def clean_state(state):
# Remove all tool-related messages
to_remove = [RemoveMessage(id=msg.id) for msg in state["messages"] if msg.role == "tool"]
return {"messages": to_remove}Dans le code ci-dessus, nous avons supprimé tous les messages liés aux outils, qui pouvaient être redondants (car, en réalité, le message Tool-Message est destiné au LLM à élaborer sa réponse après avoir utilisé l'outil).
Toutefois, si nous souhaitons supprimer l'historique complet des messages, nous pouvons procéder comme suit :
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain_core.messages import RemoveMessage
def reset_history(state):
# Remove entire conversation history
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}Dans l'ensemble, LangGraph est une bibliothèque puissante qui offre une approche structurée et évolutive pour la création de systèmes agentés. La modélisation de la logique sous forme de graphe de nœuds et d'arêtes, avec un état partagé et une mémoire persistante, nous permet de développer des agents robustes capables de raisonner, d'interagir et de s'adapter au fil du temps.
À mesure que les systèmes gagnent en complexité, ce cadre fournit les outils nécessaires pour gérer la mémoire, coordonner l'utilisation des outils et maintenir le contexte à long terme, tout en restant modulaire et extensible.
Les composants essentiels étant désormais en place, vous êtes prêt à concevoir et à déployer des agents IA robustes capables de gérer des flux de travail réels.
Pour continuer à vous former, nous vous invitons à consulter notre cours intitulé « Construire des systèmes multi-agents avec LangGraph. Vous pouvez également consulter notre cours « Concevoir des systèmes agentique avec LangChain »et notre tutoriel sur le RAG agentique.
Meilleurs cours DataCamp
Cours
Cours
Cours