
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
Vamos começar falando sobre os blocos básicos do LangGraph. Esses elementos nos permitem criar fluxos de trabalho estruturados, com estado e escaláveis para construir agentes de IA avançados.
O estado é um objeto de memória compartilhada que flui pelo gráfico. Ele guarda todas as informações importantes, como mensagens, variáveis, resultados intermediários e histórico de decisões. O LangGraph cuida do estado automaticamente, deixando o desenvolvimento mais eficiente.
Para ajudar o Estado, tem recursos de suporte mais avançados, como checkpointing, memória local de thread e persistência entre sessões. Durante toda a execução, o estado é executado continuamente, como mostra o diagrama abaixo: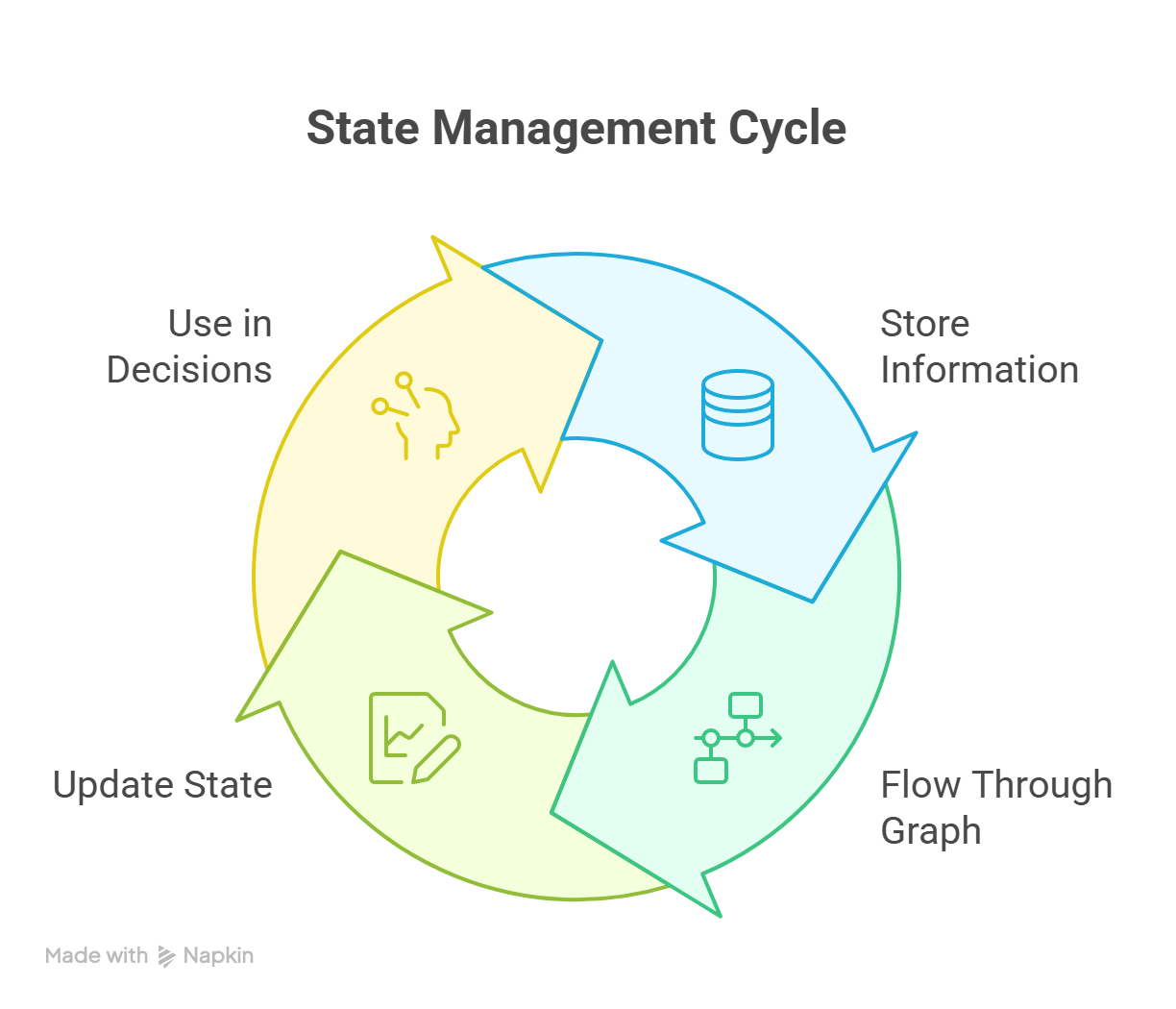
Ciclo de gerenciamento de estado no LangGraph mostrando atualizações contínuas entre os nós
Um nó é uma unidade funcional única no fluxo de trabalho. Ele pode fazer váriascoisas legais como , tipo:
Cada nó pega o estado atual e devolve um estado atualizado.
As arestas definem as transições entre os nós. Eles decidem como o fluxo de controle do gráfico vai rolar e podem dar suporte a:
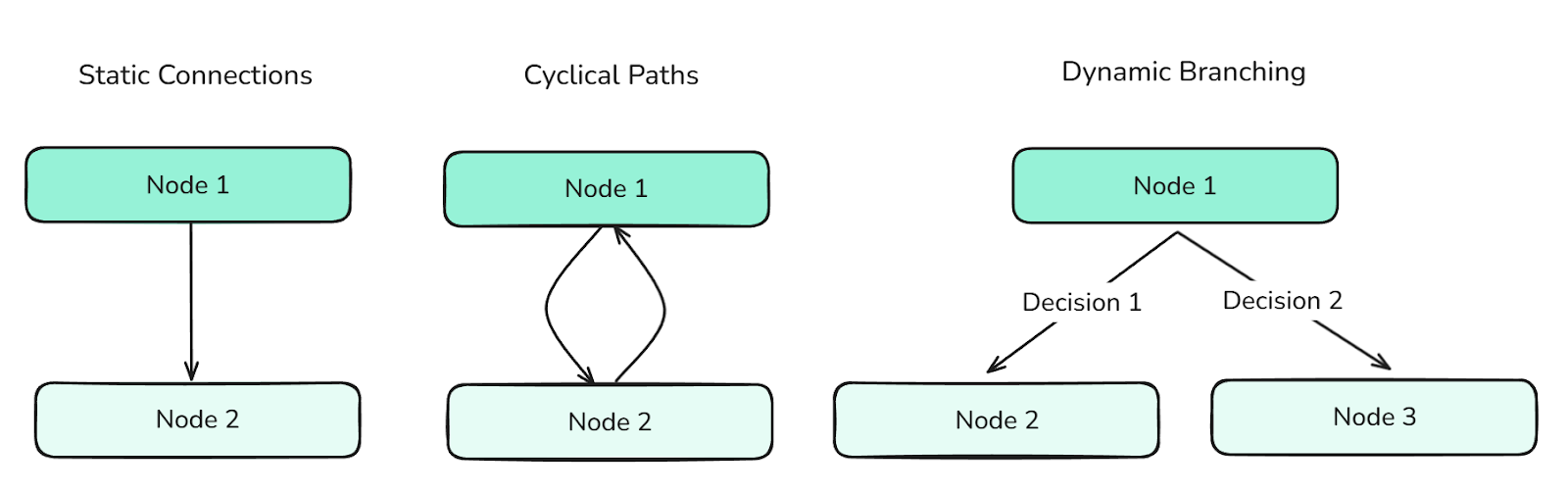
Diferentes tipos de arestas definem o fluxo entre os nós e controlam as informações através do gráfico.
As bordas são essenciais para organizar comportamentos complexos de agentes.
Um gráfico no LangGraph mostra como funciona o fluxo de trabalho dos agentes e é feito de nós conectados por arestas.
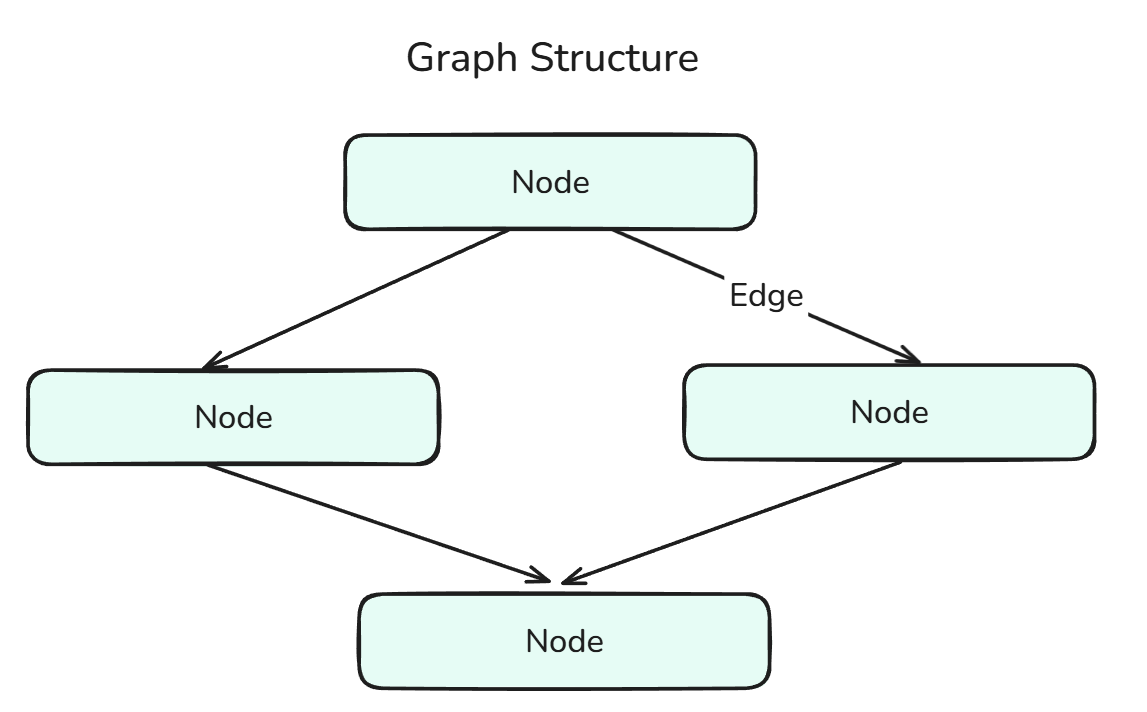
A estrutura do gráfico é uma combinação de nós e arestas.
O StateGraph é um gráfico especializado que mantém e atualiza um estado compartilhado durante toda a execução. Isso permite tomar decisões com base no contexto e manter a memória entre as etapas. Podemos pensar nisso como a fusão de State e Graph.
Uma ferramenta é qualquer função externa ou interna que um agente pode chamar, como uma pesquisa na web, calculadora ou utilitário personalizado. Existem dois tipos de ferramentas:
Um ToolNode ( ) é um tipo de nó dedicado para executar ferramentas dentro do gráfico. Isso permite que a gente, desenvolvedores, integre ferramentas sem precisar escrever mais código. Podemos pensar nisso como a fusão de Tool e Node.
As mensagens são elementos de dados estruturados (como a entrada do usuário, a saída do sistema, respostas intermediárias, etc.) que se movem pelo gráfico e são armazenadas no estado. Elas permitem rastreabilidade, memória e contexto para as decisões dos agentes, o que ajuda a tomar decisões mais informadas.
Tem vários tipos de mensagens no LangGraph:
HumanMessage, AIMessage ou SystemMessage — herda de BaseMessage.Agora vamos codificar esses agentes no LangGraph, focando em entender os diferentes métodos e etapas envolvidos na codificação, bem como na visualização desses agentes.
Vamos começar criando um único agente sem ferramentas nem memória. Vamos começar com as importações:
from typing import TypedDict, List
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from dotenv import load_dotenvA primeira linha diz “ TypedDict ”, que é uma anotação de tipo definida assim em Python:
from typing import TypedDict
class Student(TypedDict):
name: str
grade: float
s1: Student = {"name": "Sam", "grade": 92.5}Basicamente, um dicionário de segurança de tipos ( TypedDict ) é um dicionário que tem medidas robustas de segurança de tipos, que são essenciais para o desenvolvimento de agentes de IA.
HumanMessage já deve estar familiarizado com isso, pois discutimos isso anteriormente.
ChatOpenAI, no entanto, é novidade. Vamos dar uma volta pra explicar isso.
Com o Langchain, dá pra usar a família de modelos de linguagem aberta ( Chat ), que basicamente permite usar modelos de vários fornecedores de LLM, como OpenAI, Anthropic, Ollama, etc., através das respectivas bibliotecas, como ChatOpenAI, ChatAnthropic, ChatOllama, etc.
Basicamente, os parâmetros e o uso deles são parecidos, o que deixa nosso código mais modular. Passo a passo mais detalhado pode ser encontrado na Documentação do LangChain.
Por último, o StateGraph que falamos antes, e o Start e End são o começo e o fim do nosso gráfico.
Vamos continuar:
load_dotenv() # Obtaining over secret keys
# Creation of the state using a Typed Dictionary
class AgentState(TypedDict):
messages: List[HumanMessage] # We are going to be storing Human Messages (the user input) as a list of messages
llm = ChatOpenAI(model="gpt-4o") # Our model choice
# This is an action - the underlying function of our node
def process(state: AgentState) -> AgentState:
response = llm.invoke(state["messages"])
print(f"\nAI: {response.content}")
return state
graph = StateGraph(AgentState) # Initialization of a Graph
graph.add_node("process_node", process) # Adding nodes
graph.add_edge(START, "process_node") # Adding edges
graph.add_edge("process_node", END)
agent = graph.compile() # Compiling the graphVamos falar mais sobre os métodos .add_node() e .add_edge().
add.node(): Tem dois parâmetros principais que você precisa prestar atenção: o nome do nó e a ação por trás dele. A ação subjacente, no nosso caso - process() é a lógica principal por trás do nó, ou seja, quais ações são concluídas quando chegamos a esta etapa. O nome do nó pode ser qualquer coisa, até mesmo o mesmo que a função, embora isso possa ser bem confuso na hora de depurar!add_edge.(): Tem de novo dois parâmetros principais que você precisa prestar atenção, que são os nós inicial e final da aresta. Lembre-se de que o nome do nó é o que é inserido, não a ação por trás dele.Vamos ver um exemplo prático:
user_input = input("Enter: ")
while user_input != "exit":
agent.invoke({"messages": [HumanMessage(content=user_input)]})
user_input = input("Enter: ")O código acima permite que a gente chame o Agente várias vezes. Olha só como é o Agente de IA que a gente criou:
Um Agente Sequencial faz as tarefas passo a passo numa ordem pré-definida, sem ramificações ou raciocínio.
Para ver isso, dá pra usar o código a seguir (lembra que estamos usando o gráfico compilado):
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))Agentes ReAct, ou agentes que raciocinam e agem, são super comuns na indústria, porque são fáceis de criar e são bem robustos. Como eles são tão comuns, o LangGraph tem um método embutido que a gente pode usar pra criar esses Agentes.
Felizmente, só precisamos de duas importações adicionais:
from langgraph.prebuilt import create_react_agent
from langchain_google_community import GmailToolkitO método ` create_react_agent ` é o que vai criar os agentes ReAct pra gente.
tools = [GmailToolkit()] # We are using the Inbuilt Gmail tool
llm = ChatOllama(model="qwen2.5:latest") # Leveraging Ollama Models
agent = create_react_agent(
model = llm, # Choice of the LLM
tools = tools, # Tools we want our LLM to have
name = "email_agent", # Name of our agent
prompt = "You are my AI assistant that has access to certain tools. Use the tools to help me with my tasks.", # System Prompt
)A melhor parte de usar isso é que a gente pode criar vários agentes e arquiteturas mais complexas.
Também podemos criar nossas próprias ferramentas personalizadas.
@tool
def send_email(email_address: str, email_content: str) -> str:
"""
Sends an email to a specified recipient with the given content.
Args:
email_address (str): The recipient's email address (e.g., 'example@example.com')
email_content (str): The body of the email message to be sent
Returns:
str: A confirmation message indicating success or failure
Example:
>>> send_email('john.doe@example.com', 'Hello John, just checking in!')
'Email successfully sent to john.doe@example.com'
"""
# Tool Logic goes here
return "Done!"Como já falamos, tem duas coisas principais que são importantes na hora de criar ferramentas personalizadas:
Os agentes ReAct têm a seguinte aparência:
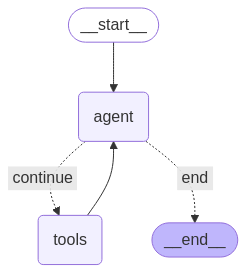
Um Agente ReAct alterna entre raciocínio (pensamentos) e ações para resolver tarefas passo a passo.
Ao definir o “ State ” para sistemas agentic mais complicados e robustos, é uma boa ideia usar funções redutoras ou simplesmente “ reducers ”. “ reducers ” são anotações de dados que garantem que, cada vez que um nó retorna uma mensagem, ela é anexada à lista existente no estado, em vez de sobrescrever o valor anterior. Isso permite que o nosso estado crie o contexto.
# State with reducer function
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], operator.add]Esse código junta a função redutora operator.add com o estado, garantindo que todas as mensagens sejam guardadas.
Nesta seção, vamos focar em um componente essencial de todo agente: a memória. A memória é super importante pra um agente, porque dá o contexto necessário pra ele ficar mais robusto e confiável. Vamos ver as diferentes maneiras de gerenciar a memória nos nossos agentes.
O estado ( ) é o elemento mais importante no LangGraph e, claro, tem várias maneiras de guardar o estado fora do programa. Alguns dos dispositivos de armazenamento externo mais populares são:
Todas essas bibliotecas podem ser encontradas na documentação.
Por enquanto, vamos dar uma olhada no SQLite:
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:") # This is for connecting to the SQLite database
graph = graph_builder.compile(checkpointer=memory) # Compiling graph with checkpointer as SQLite backendUsando SQLite é uma maneira fácil de adicionar persistência aos nossos agentes. Persistência é a capacidade de manter o contexto em diferentes interações.
Tudo isso é pra guardar e atualizar o estado. Agora vamos ver como usar e gerenciar esse estado de forma eficaz, especialmente a lista “ messages ”, que fica bem grande conforme a conversa vai rolando.
O LangGraph oferece suporte nativo para memóriade curto e longo prazo ( ). Vamos dar uma olhada nisso.
A memória de curto prazo permite que nossos agentes lembrem o histórico das mensagens durante uma sessão, o que é útil para conversas com várias respostas.
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
checkpointer = InMemorySaver()
builder = StateGraph(...)
graph = builder.compile(checkpointer=checkpointer)
# Invoking the Graph with our message
agent_graph.invoke(
{"messages": [{"role": "user", "content": "What's the weather today?"}]},
{"configurable": {"thread_id": "session_42"}},
)No exemplo acima, o “ thread_id ” é usado pra identificar de forma única uma conversa ou sessão.
A memória de longo prazo fica guardada mesmo depois de várias sessões e é perfeita pra lembrar coisas como nomes, objetivos ou configurações - coisas importantes que a gente precisa lembrar em várias sessões.
from langgraph.store.memory import InMemoryStore
from langgraph.graph import StateGraph
long_term_store = InMemoryStore()
builder = StateGraph(...)
agent = builder.compile(store=long_term_store)Mas, como a nossa conversa pode ficar grande, precisamos de uma maneira de limitar o histórico das nossas mensagens. É aí que entra o corte.
No exemplo abaixo, estamos removendo tokens do início do histórico de mensagens (por causa da linha: strategy="first") para que, depois de cortar, fiquemos com no máximo 150 tokens.
from langchain_core.messages.utils import trim_messages, count_tokens_approximately
trimmed = trim_messages(
messages=state["messages"],
strategy="first", # remove the messages from beginning
token_counter=count_tokens_approximately,
max_tokens=150
)Outra maneira de reduzir o histórico de mensagens é resumindo. Isso permite que as informações importantes sejam guardadas em todo o histórico de mensagens, em vez de só cortar partes da conversa.
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
summary_node = SummarizationNode(
model=summary_llm, # Our summarization LLM
max_tokens=300, # Total token limit
max_tokens_before_summary=150, # when to start summarizing
max_summary_tokens=150, # summary size
token_counter=count_tokens_approximately
)É importante notar que a síntese é feita por um LLM subjacente, neste caso summary_llm, que pode ser qualquer LLM.
A última operação principal necessária no gerenciamento de memória é a exclusão. Para apagar as mensagens selecionadas, dá pra usar esse código:
from langchain_core.messages import RemoveMessage
def clean_state(state):
# Remove all tool-related messages
to_remove = [RemoveMessage(id=msg.id) for msg in state["messages"] if msg.role == "tool"]
return {"messages": to_remove}No código acima, a gente apagou todas as mensagens relacionadas à ferramenta, que poderiam ser redundantes (já que, na prática, a ferramenta não precisa saber que a mensagem foi enviada pela ferramenta). Tool-Message é para o LLM criar sua resposta depois de usar a ferramenta).
Mas, se a gente quiser apagar todo o histórico de mensagens, dá pra fazer assim:
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain_core.messages import RemoveMessage
def reset_history(state):
# Remove entire conversation history
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}No geral, LangGraph é uma biblioteca poderosa que oferece uma abordagem estruturada e escalável para a construção de sistemas agenticos. Modelar a lógica como um gráfico de nós e arestas, com estado compartilhado e memória persistente, nos permite desenvolver agentes robustos que podem raciocinar, interagir e se adaptar ao longo do tempo.
À medida que os sistemas ficam mais complexos, essa estrutura oferece as ferramentas necessárias para gerenciar a memória, coordenar o uso de ferramentas e manter o contexto a longo prazo — tudo isso sem deixar de ser modular e extensível.
Com os componentes principais já prontos, você está pronto pra criar e usar agentes de IA que funcionam bem e conseguem lidar com fluxos de trabalho reais.
Para continuar aprendendo, não deixe de conferir nosso curso, Construindo Sistemas Multiagentes com LangGraph. Você também pode ver nosso curso Designing Agentic Systems with LangChaine nosso tutorial sobre RAG Agênico.
Principais cursos da DataCamp
Curso
Curso
Curso
blog
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer


