programa
Desarrollo de aplicaciones de IA
21 h
Llama 3.1 es una buena opción para la RAG, una técnica que combina los sistemas de recuperación con las capacidades de generación de texto de los modelos lingüísticos para garantizar resultados más precisos y relevantes.
En la RAG, un sistema de recuperación examina primero grandes conjuntos de datos para encontrar la información más relevante, que el modelo lingüístico utiliza después para generar la respuesta final. Esto es especialmente útil para tareas como responder preguntas, crear chatbots y manejar tareas con mucha información, en las que los modelos lingüísticos tradicionales podrían dar respuestas obsoletas o irrelevantes.
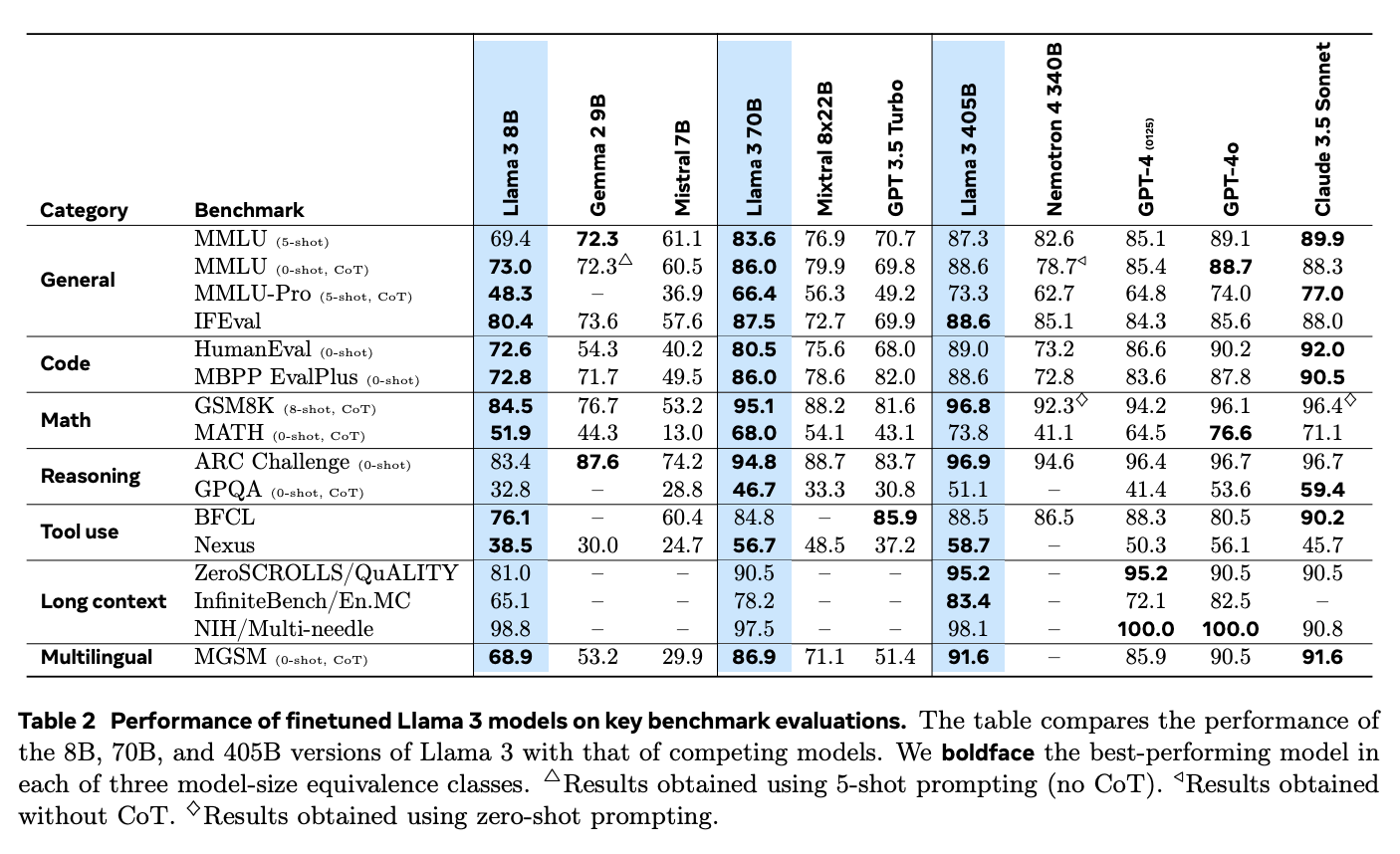
Con su capacidad para manejar hasta 128.000 tokens y su compatibilidad con varios idiomas, Llama 3.1 mejora la calidad y fiabilidad de los contenidos generados por IA en los sistemas RAG.
Fuente: La manada de modelos Llama 3
Además, Llama 3.1 destaca en aplicaciones RAG cuando se compara con modelos de código cerrado como GPT-4o y Claude 3.5 Sonnet. Su gran capacidad de razonamiento y su habilidad para procesar textos largos le permiten manejar mejor las preguntas complejas y ofrecer respuestas más pertinentes.
En la prueba comparativa Aguja en un Pajar (NIH), que pone a prueba la capacidad de un modelo para encontrar fragmentos concretos de información ("agujas") en grandes volúmenes de texto ("pajares"), Llama 3.1 destaca con una tasa de recuperación casi perfecta en todos los tamaños de modelo. Esto demuestra su capacidad para gestionar tareas de búsqueda complejas, lo que lo hace ideal para los sistemas GAR que necesitan extraer información precisa de grandes conjuntos de datos.
El modelo también obtuvo unos resultados excepcionales en la prueba comparativa Multiaguja, que requiere recuperar varias piezas de información con precisión. Sus resultados casi perfectos en esta prueba demuestran aún más su capacidad para manejar tareas de recuperación complejas.
Para configurar una aplicación RAG con Llama 3.1, son necesarios varios pasos. Incluyen la descarga del modelo Llama 3.1 a tu máquina local, la configuración del entorno, la carga de las bibliotecas necesarias y la creación de un mecanismo de recuperación. Por último, combinaremos esto con un modelo lingüístico para construir una aplicación completa.
A continuación encontrarás una guía clara, paso a paso, que te ayudará a poner en marcha una aplicación RAG utilizando Llama 3.1.
En primer lugar, instala la aplicación Ollama, que nos permite ejecutar Llama 3.1 y otros modelos lingüísticos de código abierto en tu máquina local. Puedes descargar la aplicación Ollama desde su sitio web oficial.
Una vez que hayas instalado y abierto Ollama, el siguiente paso es descargar el modelo Llama 3.1 en tu máquina local. Para este tutorial, utilizaremos la versión de parámetros 8B. Para descargarlo, abre tu terminal y ejecuta la siguiente línea de comandos:
ollama run llama3.1Cuando el modelo termine de descargarse, estaremos preparados para conectarlo mediante Langchain, para lo cual te mostraremos cómo hacerlo en secciones posteriores.
Antes de empezar, asegúrate de que tienes instaladas las bibliotecas Python adecuadas. Necesitaremos bibliotecas como langchain, langchain_community, langchain-ollama, langchain_openai. Si aún no los has instalado, puedes hacerlo utilizando pip con este comando:
pip install langchain langchain_community langchain-openai scikit-learn langchain-ollamaEl primer paso para crear tu sistema GAR es cargar los documentos que queremos utilizar como base de conocimientos. En este ejemplo, utilizaremos páginas web como fuente.
He aquí cómo hacerlo:
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# List of URLs to load documents from
urls = [
"<https://lilianweng.github.io/posts/2023-06-23-agent/>",
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>",
"<https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/>",
]
# Load documents from the URLs
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]Aquí se utiliza WebBaseLoader para obtener el contenido de cada URL proporcionada. Las listas anidadas de documentos resultantes se combinan en una única lista plana llamada docs_list, lo que nos da una lista de documentos.
Para que el proceso de recuperación sea más eficaz, dividimos los documentos en trozos más pequeños utilizando la dirección RecursiveCharacterTextSplitter. Esto ayuda al sistema a manejar y buscar el texto con mayor eficacia.
Podemos configurar el divisor de texto especificando el tamaño del trozo y el solapamiento. Por ejemplo, en el código siguiente, estamos configurando un divisor de texto con un tamaño de trozo de 250 caracteres y sin solapamiento.
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs_list)A continuación, tenemos que convertir los trozos de texto en incrustacionesque luego se almacenan en un almacén vectorial, lo que permite una recuperación rápida y eficaz basada en la similitud.
Para ello, utilizamos OpenAIEmbeddings para generar incrustaciones para cada trozo de texto, que luego se almacenan en un SKLearnVectorStore. El almacén vectorial está configurado para devolver los 4 documentos más relevantes para cualquier consulta, configurándolo con as_retriever(k=4).
from langchain_community.vectorstores import SKLearnVectorStore
from langchain_openai import OpenAIEmbeddings
# Create embeddings for documents and store them in a vector store
vectorstore = SKLearnVectorStore.from_documents(
documents=doc_splits,
embedding=OpenAIEmbeddings(openai_api_key="api_key"),
)
retriever = vectorstore.as_retriever(k=4)En este paso, configuraremos el LLM y crearemos una plantilla de consulta para generar respuestas basadas en los documentos recuperados.
En primer lugar, tenemos que definir una plantilla de pregunta que indique al LLM cómo debe dar formato a sus respuestas. Esta plantilla indica al modelo que utilice los documentos proporcionados para responder a las preguntas de forma concisa, utilizando un máximo de tres frases. Si el modelo no puede encontrar una respuesta, simplemente debe decir que no lo sabe.
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for the LLM
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)A continuación, nos conectamos al modelo Llama 3.1 utilizando ChatOllama de Langchain, que hemos configurado con un ajuste de temperatura de 0 para obtener respuestas coherentes.
# Initialize the LLM with Llama 3.1 model
llm = ChatOllama(
model="llama3.1",
temperature=0,
)Por último, creamos una cadena que combina la plantilla de aviso con el LLM y utiliza StrOutputParser para garantizar que la salida sea una cadena limpia y sencilla, adecuada para su visualización.
# Create a chain combining the prompt template and LLM
rag_chain = prompt | llm | StrOutputParser()En este paso, combinaremos el recuperador y la cadena RAG para crear una aplicación RAG completa. Lo haremos creando una clase llamada RAGApplication que se encargará tanto de la recuperación de documentos como de la generación de respuestas.
La clase RAGApplication tiene el método run que recibe la pregunta del usuario, utiliza el recuperador para encontrar documentos relevantes y, a continuación, extrae el texto de esos documentos. A continuación, pasa la pregunta y el texto del documento a la cadena RAG para generar una respuesta concisa.
# Define the RAG application class
class RAGApplication:
def __init__(self, retriever, rag_chain):
self.retriever = retriever
self.rag_chain = rag_chain
def run(self, question):
# Retrieve relevant documents
documents = self.retriever.invoke(question)
# Extract content from retrieved documents
doc_texts = "\\n".join([doc.page_content for doc in documents])
# Get the answer from the language model
answer = self.rag_chain.invoke({"question": question, "documents": doc_texts})
return answerPor último, estamos listos para probar nuestra aplicación RAG con algunas preguntas de ejemplo para asegurarnos de que funciona correctamente. Puedes ajustar la plantilla de consulta o la configuración de recuperación para mejorar el rendimiento o adaptar la aplicación a necesidades específicas.
# Initialize the RAG application
rag_application = RAGApplication(retriever, rag_chain)
# Example usage
question = "What is prompt engineering"
answer = rag_application.run(question)
print("Question:", question)
print("Answer:", answer)Question: What is prompt engineering
Answer: Prompt engineering refers to methods for communicating with Large Language Models (LLMs) to steer their behavior towards desired outcomes without updating the model weights. It's an empirical science that requires experimentation and heuristics, aiming at alignment and model steerability. The goal is to optimize prompts to achieve specific results, often using techniques like iterative prompting or external tool use.Las funciones avanzadas de Llama 3.1 y su compatibilidad con el GAR la hacen ideal para varias aplicaciones impactantes.
Para desarrollo de chatbotsAl integrar Llama 3.1 con RAG, los chatbots pueden dar respuestas más precisas y contextualizadas accediendo a bases de datos o de conocimiento externas. Esto garantiza que la información facilitada a los usuarios sea actual y pertinente, lo que es especialmente importante en campos como la atención al cliente, donde las respuestas puntuales y precisas pueden aumentar enormemente la satisfacción y la eficacia del usuario. La compatibilidad de Llama 3.1 con varios idiomas también la hace eficaz para atender a una base de usuarios diversa.
En los sistemas de respuesta a preguntas, Llama 3.1 aborda las limitaciones de los modelos lingüísticos tradicionales que sólo se basan en sus conjuntos de datos internos. Al utilizar la GAR para acceder a información actualizada de fuentes externas, Llama 3.1 mejora la precisión y fiabilidad de sus respuestas. Esto es especialmente útil en campos como sanidad y educacióndonde es esencial disponer de información precisa y actualizada.
Por ejemplo, un asistente médico de IA impulsado por Llama 3.1 puede proporcionar a los profesionales sanitarios las últimas investigaciones o pautas de tratamiento consultando bases de datos médicas en tiempo real, lo que ayuda a tomar mejores decisiones clínicas.
Llama 3.1 también es muy eficaz para tareas intensivas en conocimiento, como generar informes detallados o realizar investigaciones minuciosas. Al utilizar la GAR para extraer información de una amplia gama de fuentes, los modelos Llama 3.1 pueden ofrecer análisis más completos y matizados, lo que los convierte en herramientas valiosas para profesionales de áreas como la investigación, las finanzas y la planificación estratégica.
Implementar una aplicación RAG con Llama 3.1 utilizando Ollama y Langchain ofrece una buena solución para crear modelos lingüísticos avanzados y conscientes del contexto.
Siguiendo los pasos descritos -configurar el entorno, cargar y procesar documentos, crear incrustaciones e integrar el recuperador con el LLM- puedes construir un sistema GAR funcional capaz de recuperar información relevante y proporcionar respuestas precisas.
La integración de Llama 3.1 con RAG es especialmente valiosa para aplicaciones del mundo real, como chatbots, sistemas de respuesta a preguntas y herramientas de investigación, donde es importante el acceso a información externa actualizada.
¡Aprende a crear aplicaciones de IA!
programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Ryan Ong


