Curso
Aprendizaje no supervisado en Python
4 h
179.6K
Practica la carga de un archivo Pickled de Python con este ejercicio práctico.
¿Estás cansado de volver a ejecutar tu código Python cada vez que tienes que acceder a un marco de datos, una variable o un modelo de machine learning creados previamente?
La serialización de objetos puede ser la solución que buscas.
Es el proceso de almacenar una estructura de datos en memoria para poder cargarla o transmitirla cuando sea necesario sin perder su estado actual.
Aquí tienes un sencillo diagrama que explica cómo funciona la serialización:
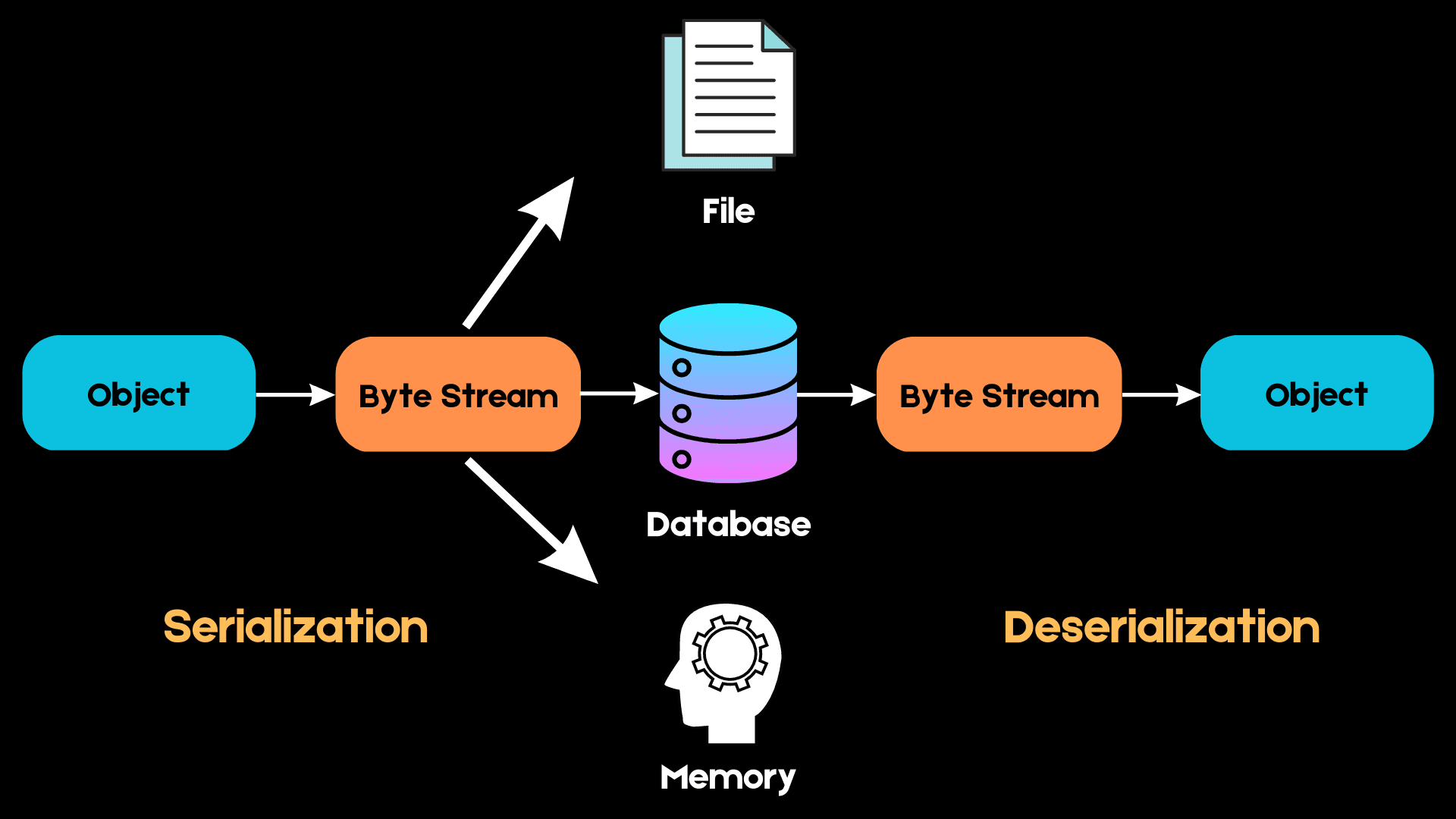
Imagen del autor
En Python, trabajamos con estructuras de datos de alto nivel, como listas, tuplas y conjuntos. Sin embargo, cuando queremos almacenar estos objetos en la memoria, hay que convertirlos en una secuencia de bytes que el ordenador pueda entender. Este proceso se llama serialización.
La próxima vez que queramos acceder a la misma estructura de datos, esta secuencia de bytes debe convertirse de nuevo en el objeto de alto nivel en un proceso conocido como deserialización.
Podemos utilizar formatos como JSON, XML, HDF5 y Pickle para la serialización. En este tutorial, aprenderemos sobre la biblioteca Pickle de Python para la serialización. Cubriremos sus usos y comprenderemos cuándo debes elegir Pickle en lugar de otros formatos de serialización.
Por último, aprenderemos a utilizar la biblioteca Pickle de Python para serializar listas, diccionarios, marcos de datos Pandas, modelos de machine learning, etc.
Más información sobre Python y machine learning
Curso
Curso
Curso
Tutorial
Kurtis Pykes
Tutorial
Théo Vanderheyden
Tutorial
Moez Ali
Tutorial
Natassha Selvaraj
