
Curso
Introducción a Python
4 h
6.9M
En el fondo, los generadores de Python son un tipo especial de función o incluso una expresión compacta que produce una secuencia de valores perezosamente. Piensa en los generadores como en una cinta transportadora en una fábrica: En lugar de apilar todos los productos en un solo lugar y quedarte sin espacio, procesa cada artículo a medida que baja por la línea. Esto hace que los generadores sean eficientes en memoria y una extensión natural del protocolo iterator de Python, que sustenta muchas de las herramientas integradas de Python, como los bucles for y las comprensiones.
La magia de los generadores reside en la palabra clave yield. A diferencia de return,, que produce un único valor y sale de la función, yield produce un valor, detiene la ejecución de la función y guarda su estado. Cuando se vuelve a llamar al generador, éste retoma la operación donde la dejó.
Por ejemplo, imagina que estás leyendo un archivo de registro masivo línea por línea. Un generador puede procesar cada línea como leída sin cargar todo el archivo en la memoria. Esta "evaluación perezosa" diferencia a los generadores de las funciones tradicionales y los convierte en una herramienta imprescindible para las tareas sensibles al rendimiento.
Practiquemos un poco para hacernos a la idea. Aquí tienes una función generadora que produce los primeros n enteros.
def generate_integers(n):
for i in range(n):
yield i # Pauses here and returns i
# Using the generator
for num in generate_integers(5):
print(num)0
1
2
3
4He creado una imagen para ayudarte a ver lo que ocurre bajo el capó:
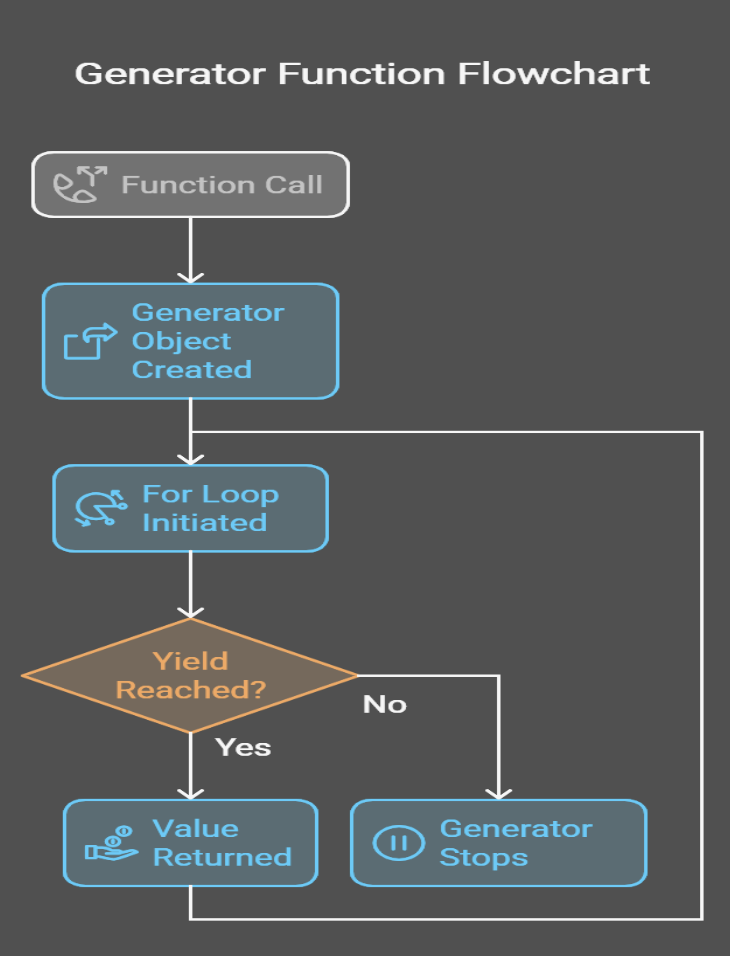
Los generadores pueden implementarse de múltiples formas. Dicho esto, hay dos formas principales: las funciones generadoras y las expresiones generadoras.
Una función generadora se define como una función normal, pero utiliza la palabra clave yield en lugar de return. Cuando se llama, devuelve un objeto generador sobre el que se puede iterar.
def count_up_to(n):
count = 1
while count <= n:
yield count
count += 1
# Using the generator
counter = count_up_to(5)
for num in counter:
print(num)1
2
3
4
5En el ejemplo anterior, podemos ver que cuando se llama a la función count_up_to, ésta devuelve un objeto generador. Cada vez que el bucle for solicita un valor, la función se ejecuta hasta que llega a yield, produciendo el valor actual de count y conservando su estado entre iteraciones para que pueda reanudarse exactamente donde lo dejó.
Las expresiones de generador son una forma compacta de crear generadores. Son similares a las comprensiones de listas, pero con paréntesis en lugar de corchetes.
# List comprehension (eager evaluation)
squares_list = [x**2 for x in range(5)] # [0, 1, 4, 9, 16]
# Generator expression (lazy evaluation)
squares_gen = (x**2 for x in range(5))
# Using the generator
for square in squares_gen:
print(square)0
1
4
9
16Entonces, ¿cuál es la diferencia entre una comprensión de lista y una expresión generadora? La comprensión de lista crea toda la lista en memoria, mientras que la expresión generadora produce valores de uno en uno , ahorrando memoria. Si no estás familiarizado con las comprensiones de listas, puedes leer sobre ellas en nuestro Tutorial Python de Comprensión de Listas.
Los iteradores tradicionales en Python requerían clases con métodos explícitos __iter__() y __next__(), lo que implicaba un montón de repeticiones y gestión manual del estado, mientras que las funciones generadoras simplifican el proceso preservando automáticamente el estado y eliminando la necesidad de estos métodos, como demuestra una sencilla función que devuelve el cuadrado de cada número hasta n.
Al explicar qué son los generadores de Python, también he transmitido parte de la idea de por qué se utilizan. En esta sección, quiero entrar un poco más en detalle. Porque los generadores no son sólo una función extravagante de Python, sino que realmente resuelven problemas reales.
A diferencia de las listas o matrices, que almacenan todos sus elementos en memoria simultáneamente, los generadores producen valores sobre la marcha, por lo que sólo mantienen un elemento en memoria cada vez.
Por ejemplo, considera la diferencia entre range() de Python 2 y xrange():
range() creaba una lista en memoria, lo que podía ser problemático para rangos grandes.
xrange() actuaba como un generador, produciendo valores perezosamente.
Como el comportamiento de xrange() era más útil, ahora, en Python 3, range() también se comporta como un generador, por lo que evita la sobrecarga de memoria de almacenar todos los valores simultáneamente.
Para mostrar la idea, comparemos el uso de memoria al generar una secuencia de 10 millones de números:
import sys
# Using a list
numbers_list = [x for x in range(10_000_000)]
print(f"Memory used by list: {sys.getsizeof(numbers_list) / 1_000_000:.2f} MB")
# Using a generator
numbers_gen = (x for x in range(10_000_000))
print(f"Memory used by generator: {sys.getsizeof(numbers_gen)} bytes")Memory used by list: 89.48 MB
Memory used by the generator: 112 bytesComo puedes ver, el generador casi no utiliza memoria en comparación con la lista, y esta diferencia es significativa.
Gracias a la evaluación perezosa, los valores se calculan sólo cuando es necesario. Esto significa que puedes empezar a procesar datos inmediatamente sin esperar a que se genere toda la secuencia.
Por ejemplo, imagina que sumas los cuadrados del primer millón de números:
# Using a list (eager evaluation)
sum_of_squares_list = sum([x**2 for x in range(1_000_000)])
# Using a generator (lazy evaluation)
sum_of_squares_gen = sum(x**2 for x in range(1_000_000))Aunque ambos enfoques dan el mismo resultado, la versión del generador evita crear una lista masiva, por lo que obtenemos el resultado más rápidamente.
Los generadores simplifican la implementación de los iteradores eliminando el código repetitivo. Compara un iterador basado en clases con una función generadora:
Aquí tienes el iterador basado en clases:
class SquaresIterator:
def __init__(self, n):
self.n = n
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current >= self.n:
raise StopIteration
result = self.current ** 2
self.current += 1
return result
# Usage
squares = SquaresIterator(5)
for square in squares:
print(square)Aquí tienes la función generadora:
def squares_generator(n):
for i in range(n):
yield i ** 2
# Usage
squares = squares_generator(5)
for square in squares:
print(square)La versión del generador es más corta, más fácil de leer y no requiere código repetitivo. Es un ejemplo perfecto de la filosofía de Python: lo simple es mejor.
Por último, quiero decir que los generadores son especialmente adecuados para representar secuencias infinitas, algo que es sencillamente imposible con las listas. Por ejemplo, considera la secuencia de Fibonacci:
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# Usage
fib = fibonacci()
for _ in range(10):
print(next(fib))0
1
1
2
3
5
8
13
21
34Este generador puede producir números de Fibonacci indefinidamente sin agotar la memoria. Otros ejemplos son el procesamiento de flujos de datos en directo o el trabajo con datos de series temporales.
Ahora, veamos algunas ideas más difíciles. En esta sección, exploraremos cómo componer generadores y utilizar métodos generadores únicos como .send(), .throw(), y .close().
Los generadores pueden combinarse. Puedes transformar, filtrar y procesar datos modularmente encadenando generadores.
Supongamos que tienes una secuencia infinita de números y quieres elevar al cuadrado cada número y filtrar los resultados impares:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
def square_numbers(sequence):
for num in sequence:
yield num ** 2
def filter_evens(sequence):
for num in sequence:
if num % 2 == 0:
yield num
# Compose the generators
numbers = infinite_sequence()
squared = square_numbers(numbers)
evens = filter_evens(squared)
# Print the first 10 even squares
for _ in range(10):
print(next(evens))0
4
16
36
64
100
144
196
256
324El proceso consiste en que la función infinite_sequence genera números indefinidamente, mientras que la square_numbers produce el cuadrado de cada número, y luego filter_evens filtra los números impares para producir sólo cuadrados pares. Nuestro itinerario profesional de Desarrollador Python Asociado se centra en este tipo de cosas, para que puedas ver cómo construir y depurar canalizaciones complejas utilizando generadores, así como iteradores y comprensiones de listas.
Los generadores vienen con métodos avanzados que permiten la comunicación bidireccional y la terminación controlada.
El método .send() te permite pasar valores a un generador, convirtiéndolo en una coroutina. Esto es útil para crear generadores interactivos o con estado.
def accumulator():
total = 0
while True:
value = yield total
if value is not None:
total += value
# Using the generator
acc = accumulator()
next(acc) # Start the generator
print(acc.send(10)) # Output: 10
print(acc.send(5)) # Output: 15
print(acc.send(20)) # Output: 35Funciona así:
El generador comienza con next(acc) para inicializarlo.
Cada llamada a .send(value) pasa un valor al generador, que se asigna a value en la sentencia yield.
El generador actualiza su estado (total) y da el nuevo resultado.
El método .throw() te permite lanzar una excepción dentro del generador, lo que puede ser útil para gestionar errores o señalar condiciones específicas.
def resilient_generator():
try:
for i in range(5):
yield i
except ValueError:
yield "Error occurred!"
# Using the generator
gen = resilient_generator()
print(next(gen)) # Output: 0
print(next(gen)) # Output: 1
print(gen.throw(ValueError)) # Output: "Error occurred!"Así es como funciona:
El generador suele funcionar hasta que se llama a .throw().
La excepción se lanza dentro del generador, que puede gestionarla mediante un bloque try-except.
El método .close() detiene un generador lanzando una excepción GeneratorExit. Esto es útil para limpiar recursos o detener generadores infinitos.
def infinite_counter():
count = 0
try:
while True:
yield count
count += 1
except GeneratorExit:
print("Generator closed!")
# Using the generator
counter = infinite_counter()
print(next(counter)) # Output: 0
print(next(counter)) # Output: 1
counter.close() # Output: "Generator closed!"Y así es como funciona:
El generador funciona hasta que se llama a .close().
Se lanza la excepción GeneratorExit, lo que permite al generador limpiar o registrar un mensaje antes de terminar.
Espero que llegues a apreciar que los generadores son útiles. En esta sección, voy a intentar resaltar los casos de uso para que puedas imaginarte cómo funcionan realmente para ti en tu día a día.
Uno de los retos más comunes en la ciencia de datos es trabajar con conjuntos de datos demasiado grandes para caber en la memoria. Los generadores proporcionan una forma de procesar esos datos línea por línea.
Imagina que tienes un archivo CSV de 10 GB con datos de ventas y necesitas filtrar los registros de una región concreta. A continuación te explicamos cómo puedes utilizar una tubería generadora para conseguirlo:
import csv
def read_large_csv(file_path):
""" Generator to read a large CSV file line by line."""
with open(file_path, mode="r") as file:
reader = csv.DictReader(file)
for row in reader:
yield row
def filter_by_region(data, region):
""" Generator to filter rows by a specific region."""
for row in data:
if row["Region"] == region:
yield row
# Generator pipeline
file_path = "sales_data.csv"
region = "North America"
data = read_large_csv(file_path)
filtered_data = filter_by_region(data, region)
# Process the filtered data
for record in filtered_data:
print(record)Esto es lo que ocurre:
read_large_csv lee el archivo línea por línea, mostrando cada fila como un diccionario.
filter_by_region filtra las filas en función de la región especificada.
El pipeline procesa los datos de forma incremental, evitando la sobrecarga de memoria.
Este enfoque beneficia a los flujos de trabajo de extracción, transformación y carga, en los que los datos deben limpiarse y transformarse antes del análisis. Verás este tipo de cosas en nuestro curso de ETL y ELT en Python.
A veces los datos llegan como un flujo continuo. Piensa en datos de sensores, transmisiones en directo o redes sociales.
Supón que trabajas con dispositivos IoT que generan lecturas de temperatura cada segundo. Quieres calcular la temperatura media a lo largo de una ventana deslizante de 10 lecturas:
def sensor_data_stream():
"""Simulate an infinite stream of sensor data."""
import random
while True:
yield random.uniform(0, 100) # Simulate sensor data
def sliding_window_average(stream, window_size):
""" Calculate the average over a sliding window of readings."""
window = []
for value in stream:
window.append(value)
if len(window) > window_size:
window.pop(0)
if len(window) == window_size:
yield sum(window) / window_size
# Generator pipeline
sensor_stream = sensor_data_stream()
averages = sliding_window_average(sensor_stream, window_size=10)
# Print the average every second
for avg in averages:
print(f"Average temperature: {avg:.2f}")He aquí la explicación:
sensor_data_stream simula un flujo infinito de lecturas de los sensores.
sliding_window_average mantiene una ventana deslizante de las 10 últimas lecturas y obtiene su media.
La canalización procesa los datos en tiempo real, lo que la hace ideal para la supervisión y el análisis.
Los generadores también se utilizan en situaciones en las que el tamaño de los datos es impredecible o cuando no deja de llegar/es infinito.
Al raspar sitios web, a menudo no sabes cuántas páginas o elementos necesitarás procesar. Los generadores te permiten manejar esta imprevisibilidad con elegancia:
def scrape_website(url):
""" Generator to scrape a website page by page."""
while url:
# Simulate fetching and parsing a page
print(f"Scraping {url}")
data = f"Data from {url}"
yield data
url = get_next_page(url) # Hypothetical function to get the next page
# Usage
scraper = scrape_website("https://example.com/page1")
for data in scraper:
print(data)En las simulaciones, como los métodos de Montecarlo o el desarrollo de juegos, los generadores pueden representar secuencias infinitas o dinámicas:
def monte_carlo_simulation():
""" Generator to simulate random events for Monte Carlo analysis."""
import random
while True:
yield random.random()
# Usage
simulation = monte_carlo_simulation()
for _ in range(10):
print(next(simulation))Debido a su funcionamiento, los generadores destacan en situaciones en las que la eficiencia de la memoria es crítica, pero (te sorprenderá saberlo) no siempre son la opción más rápida. Comparemos los generadores con las listas para comprender sus ventajas y desventajas.
Anteriormente, mostramos cómo los generadores eran mejores que las listas en términos de memoria. Esta fue la parte en la que comparamos el uso de memoria al generar una secuencia de 10 millones de números. Hagamos ahora algo diferente, una comparación de velocidad:
import time
# List comprehension
start_time = time.time()
sum([x**2 for x in range(1_000_000)])
print(f"List comprehension time: {time.time() - start_time:.4f} seconds")
# Generator expression
start_time = time.time()
sum(x**2 for x in range(1_000_000))
print(f"Generator expression time: {time.time() - start_time:.4f} seconds")List comprehension time: 0.1234 seconds
Generator expression time: 0.1456 secondsAunque un generador ahorra memoria, en este caso, en realidad es más lento que la lista. Esto se debe a que, para este conjunto de datos más pequeño, existe la sobrecarga de pausar y reanudar la ejecución.
La diferencia de rendimiento es insignificante para conjuntos de datos pequeños, pero para conjuntos de datos grandes, el ahorro de memoria de los generadores suele compensar la ligera penalización de velocidad.
Por último, veamos algunos errores o problemas comunes:
Una vez agotado un generador, no se puede reutilizar. Tendrás que volver a crearlo si quieres iterar de nuevo.
gen = (x for x in range(5))
print(list(gen)) # Output: [0, 1, 2, 3, 4]
print(list(gen)) # Output: [] (the generator is exhausted)Como los generadores producen valores bajo demanda, es posible que los errores o efectos secundarios no aparezcan hasta que se itere el generador.
Para conjuntos de datos pequeños o tareas sencillas, la sobrecarga de utilizar un generador puede no compensar el ahorro de memoria. Considera este ejemplo en el que estoy materializando datos para varias iteraciones.
# Generator expression
gen = (x**2 for x in range(10))
# Materialize into a list
squares = list(gen)
# Reuse the list
print(sum(squares)) # Output: 285
print(max(squares)) # Output: 81Para recapitular, daré algunas normas muy generales sobre cuándo utilizar los generadores. Utilízalo para:
Cuándo materializar los datos en su lugar (convertir en una lista)
A lo largo de este artículo, hemos explorado cómo los generadores pueden ayudarte a afrontar los retos del mundo real en la ciencia de datos, desde el procesamiento de grandes conjuntos de datos hasta la construcción de canalizaciones de datos en tiempo real. Sigue practicando. La mejor forma de dominar los generadores es utilizarlos en tu propio trabajo. Para empezar, intenta sustituir una comprensión de lista por una expresión generadora o refactoriza un bucle para convertirlo en una función generadora.
Una vez que domines los conceptos básicos, podrás explorar temas nuevos y más avanzados que se basen en el concepto de generador:
Coroutines: Utiliza .send() y .throw() para crear generadores que puedan recibir y procesar datos, permitiendo la comunicación bidireccional.
Programación asíncrona: Combina generadores con la biblioteca asyncio de Python para crear aplicaciones eficientes y no bloqueantes.
Concurrencia: Aprende cómo los generadores pueden implementar la multitarea cooperativa y la concurrencia ligera.
Sigue aprendiendo y conviértete en un experto. Realiza hoy mismo nuestro itinerario profesional de Desarrollador Python o nuestro itinerario profesional de Programación Python. Haz clic en el siguiente enlace para empezar.
Aprende Python con DataCamp
Curso
Curso
Curso
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
Duong Vu
