
Kurs
Einführung in Python
4 Std.
6.9M
Im Kern sind Python-Generatoren eine besondere Art von Funktion oder sogar ein kompakter Ausdruck, der eine Folge von Werten erzeugt. Stell dir die Generatoren wie ein Fließband in einer Fabrik vor: Anstatt alle Produkte an einem Ort zu stapeln, so dass der Platz knapp wird, bearbeitest du jeden Artikel, wenn er in die Reihe kommt. Das macht Generatoren speichereffizient und zu einer natürlichen Erweiterung des iterator Protokolls von Python, das viele der in Python integrierten Werkzeuge wie for-Schleifen und Comprehensions unterstützt.
Die Magie hinter den Generatoren liegt in dem Schlüsselwort yield. Im Gegensatz zu return,, das einen einzigen Wert ausgibt und die Funktion beendet, erzeugt yield einen Wert, hält die Ausführung der Funktion an und speichert ihren Zustand. Wenn der Generator erneut aufgerufen wird, macht er dort weiter, wo er aufgehört hat.
Stell dir zum Beispiel vor, du liest eine große Logdatei Zeile für Zeile. Ein Generator kann jede Zeile beim Lesen verarbeiten, ohne die gesamte Datei in den Speicher zu laden. Diese "faule Auswertung" unterscheidet Generatoren von traditionellen Funktionen und macht sie zu einem idealen Werkzeug für leistungsabhängige Aufgaben.
Lass uns ein bisschen üben, um den Dreh rauszukriegen. Hier ist eine Generatorfunktion, die die ersten n ganzen Zahlen erzeugt.
def generate_integers(n):
for i in range(n):
yield i # Pauses here and returns i
# Using the generator
for num in generate_integers(5):
print(num)0
1
2
3
4Ich habe eine Grafik erstellt, damit du siehst, was unter der Haube passiert:
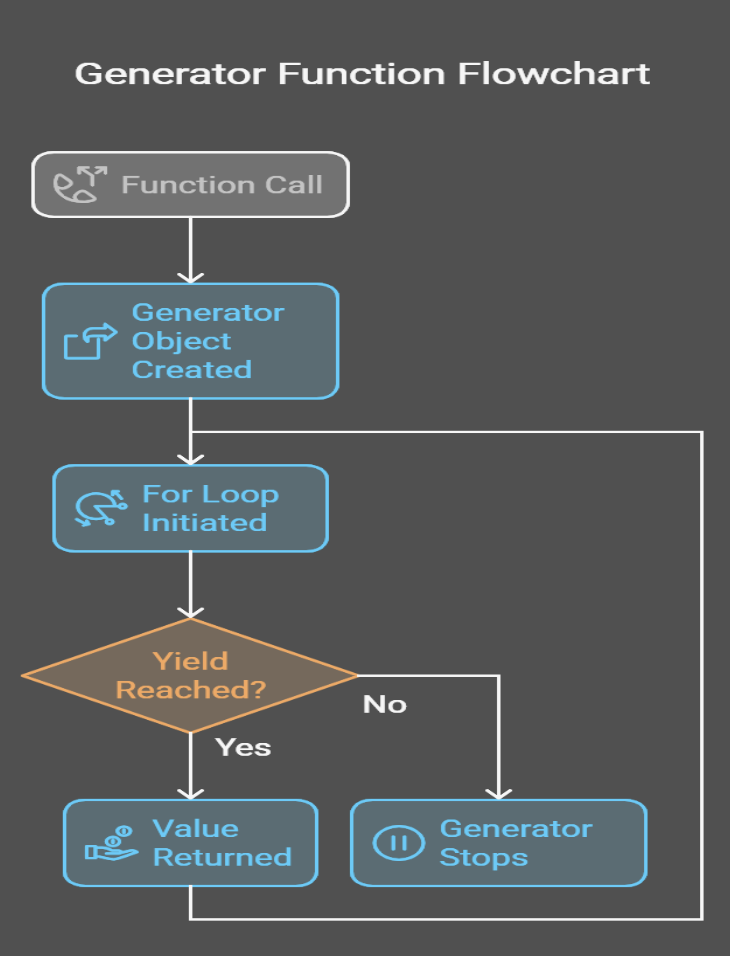
Generatoren können auf verschiedene Arten implementiert werden. Dabei gibt es zwei Hauptmöglichkeiten: Generatorfunktionen und Generatorausdrücke.
Eine Generatorfunktion wird wie eine reguläre Funktion definiert, verwendet aber das Schlüsselwort yield anstelle von return.. Wenn sie aufgerufen wird, gibt sie ein Generatorobjekt zurück, über das iteriert werden kann.
def count_up_to(n):
count = 1
while count <= n:
yield count
count += 1
# Using the generator
counter = count_up_to(5)
for num in counter:
print(num)1
2
3
4
5Anhand des obigen Beispiels sehen wir, dass die Funktion count_up_to ein Generator-Objekt zurückgibt, wenn sie aufgerufen wird. Jedes Mal, wenn die for-Schleife einen Wert anfordert, läuft die Funktion so lange, bis sie auf yield trifft. Dabei wird der aktuelle Wert von count erzeugt und der Zustand zwischen den Iterationen beibehalten, sodass die Funktion genau dort weitermachen kann, wo sie aufgehört hat.
Generatorausdrücke sind ein kompakter Weg, um Generatoren zu erstellen. Sie sind ähnlich wie Listenauffassungen, aber mit Klammern statt eckigen Klammern.
# List comprehension (eager evaluation)
squares_list = [x**2 for x in range(5)] # [0, 1, 4, 9, 16]
# Generator expression (lazy evaluation)
squares_gen = (x**2 for x in range(5))
# Using the generator
for square in squares_gen:
print(square)0
1
4
9
16Was ist also der Unterschied zwischen einem Listenverständnis und einem Generatorausdruck? Das Listenverständnis erstellt die gesamte Liste im Speicher, während der Generatorausdruck einen Wert nach dem anderen erzeugt und so Speicherplatz spart. Wenn du mit List Comprehensions nicht vertraut bist, kannst du sie in unserem Python List Comprehension Tutorial nachlesen.
Herkömmliche Iteratoren in Python erforderten Klassen mit expliziten Methoden __iter__() und __next__(), was eine Menge Boilerplate und manuelle Zustandsverwaltung mit sich brachte, während Generatorfunktionen den Prozess vereinfachen, indem sie den Zustand automatisch beibehalten und diese Methoden überflüssig machen - wie eine einfache Funktion zeigt, die das Quadrat jeder Zahl bis n liefert.
Als ich erklärt habe, was Python-Generatoren sind, habe ich auch erklärt, warum sie verwendet werden. In diesem Abschnitt möchte ich ein wenig mehr ins Detail gehen. Denn Generatoren sind nicht nur ein schickes Python-Feature, sondern sie lösen tatsächlich echte Probleme.
Im Gegensatz zu Listen oder Arrays, die alle Elemente gleichzeitig im Speicher ablegen, erzeugen Generatoren Werte im laufenden Betrieb, sodass sie immer nur ein Element im Speicher halten.
Betrachte zum Beispiel den Unterschied zwischen range() und xrange() in Python 2:
range() eine Liste im Speicher erstellt, was bei großen Bereichen problematisch sein kann.
xrange() hat sich wie ein Generator verhalten und träge Werte produziert.
Weil das Verhalten von xrange() nützlicher war, verhält sich range() in Python 3 jetzt auch wie ein Generator und vermeidet so den Speicher-Overhead, der durch das gleichzeitige Speichern aller Werte entsteht.
Um die Idee zu verdeutlichen, vergleichen wir den Speicherverbrauch beim Erzeugen einer Folge von 10 Millionen Zahlen:
import sys
# Using a list
numbers_list = [x for x in range(10_000_000)]
print(f"Memory used by list: {sys.getsizeof(numbers_list) / 1_000_000:.2f} MB")
# Using a generator
numbers_gen = (x for x in range(10_000_000))
print(f"Memory used by generator: {sys.getsizeof(numbers_gen)} bytes")Memory used by list: 89.48 MB
Memory used by the generator: 112 bytesWie du siehst, verbraucht der Generator im Vergleich zur Liste fast keinen Speicher, und dieser Unterschied ist erheblich.
Dank der "Lazy Evaluation" werden Werte nur bei Bedarf berechnet. Das bedeutet, dass du sofort mit der Verarbeitung der Daten beginnen kannst, ohne darauf zu warten, dass die gesamte Sequenz erstellt wird.
Stell dir zum Beispiel vor, du addierst die Quadrate der ersten 1 Million Zahlen:
# Using a list (eager evaluation)
sum_of_squares_list = sum([x**2 for x in range(1_000_000)])
# Using a generator (lazy evaluation)
sum_of_squares_gen = sum(x**2 for x in range(1_000_000))Während beide Ansätze das gleiche Ergebnis liefern, vermeidet die Generatorversion die Erstellung einer riesigen Liste, sodass wir das Ergebnis schneller erhalten.
Generatoren vereinfachen die Implementierung von Iteratoren, indem sie den Boilerplate-Code eliminieren. Vergleiche einen klassenbasierten Iterator mit einer Generatorfunktion:
Hier ist der klassenbasierte Iterator:
class SquaresIterator:
def __init__(self, n):
self.n = n
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current >= self.n:
raise StopIteration
result = self.current ** 2
self.current += 1
return result
# Usage
squares = SquaresIterator(5)
for square in squares:
print(square)Hier ist die Generatorfunktion:
def squares_generator(n):
for i in range(n):
yield i ** 2
# Usage
squares = squares_generator(5)
for square in squares:
print(square)Die Generator-Version ist kürzer, einfacher zu lesen und benötigt keinen Boilerplate-Code. Es ist ein perfektes Beispiel für die Python-Philosophie: Einfach ist besser.
Abschließend möchte ich noch sagen, dass Generatoren hervorragend dazu geeignet sind, unendliche Sequenzen darzustellen, was mit Listen einfach unmöglich ist. Betrachte zum Beispiel die Fibonacci-Folge:
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# Usage
fib = fibonacci()
for _ in range(10):
print(next(fib))0
1
1
2
3
5
8
13
21
34Dieser Generator kann unendlich viele Fibonacci-Zahlen erzeugen, ohne dass der Speicherplatz ausgeht. Andere Beispiele sind die Verarbeitung von Live-Datenströmen oder die Arbeit mit Zeitreihendaten.
Jetzt wollen wir uns ein paar schwierigere Ideen ansehen. In diesem Abschnitt lernen wir, wie man Generatoren zusammensetzt und einzigartige Generatormethoden wie .send(), .throw() und .close() verwendet.
Generatoren können kombiniert werden. Du kannst Daten modular umwandeln, filtern und verarbeiten, indem du Generatoren miteinander verkettest.
Nehmen wir an, du hast eine unendliche Folge von Zahlen und möchtest jede Zahl quadrieren und ungerade Ergebnisse herausfiltern:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
def square_numbers(sequence):
for num in sequence:
yield num ** 2
def filter_evens(sequence):
for num in sequence:
if num % 2 == 0:
yield num
# Compose the generators
numbers = infinite_sequence()
squared = square_numbers(numbers)
evens = filter_evens(squared)
# Print the first 10 even squares
for _ in range(10):
print(next(evens))0
4
16
36
64
100
144
196
256
324Bei diesem Prozess erzeugt die Funktion infinite_sequence unendlich viele Zahlen, während die Funktion square_numbers das Quadrat jeder Zahl liefert und dann filter_evens ungerade Zahlen herausfiltert, um nur gerade Quadrate zu erhalten. In unserem Lernpfad für Associate Python Developer lernst du, wie man komplexe Pipelines mit Generatoren, Iteratoren und List Comprehensions erstellt und debuggt .
Die Generatoren verfügen über fortschrittliche Methoden, die eine Zwei-Wege-Kommunikation und eine kontrollierte Beendigung ermöglichen.
Mit der Methode .send() kannst du Werte an einen Generator zurückgeben und ihn so in eine Coroutine verwandeln. Dies ist nützlich, um interaktive oder zustandsabhängige Generatoren zu erstellen.
def accumulator():
total = 0
while True:
value = yield total
if value is not None:
total += value
# Using the generator
acc = accumulator()
next(acc) # Start the generator
print(acc.send(10)) # Output: 10
print(acc.send(5)) # Output: 15
print(acc.send(20)) # Output: 35So funktioniert es:
Der Generator startet mit next(acc), um ihn zu initialisieren.
Jeder Aufruf von .send(value) übergibt einen Wert an den Generator, der in der Anweisung yield value zugewiesen wird.
Der Generator aktualisiert seinen Zustand (total) und liefert das neue Ergebnis.
Mit der Methode .throw() kannst du innerhalb des Generators eine Ausnahme auslösen, die für die Fehlerbehandlung oder zur Signalisierung bestimmter Bedingungen hilfreich sein kann.
def resilient_generator():
try:
for i in range(5):
yield i
except ValueError:
yield "Error occurred!"
# Using the generator
gen = resilient_generator()
print(next(gen)) # Output: 0
print(next(gen)) # Output: 1
print(gen.throw(ValueError)) # Output: "Error occurred!"So funktioniert das hier:
Der Generator läuft normalerweise, bis .throw() aufgerufen wird.
Die Ausnahme wird innerhalb des Generators ausgelöst, der sie mit einem try-except Block behandeln kann.
Die Methode .close() stoppt einen Generator, indem sie eine GeneratorExit Ausnahme auslöst. Dies ist nützlich, um Ressourcen aufzuräumen oder unendliche Generatoren zu stoppen.
def infinite_counter():
count = 0
try:
while True:
yield count
count += 1
except GeneratorExit:
print("Generator closed!")
# Using the generator
counter = infinite_counter()
print(next(counter)) # Output: 0
print(next(counter)) # Output: 1
counter.close() # Output: "Generator closed!"Und so funktioniert's:
Der Generator läuft, bis .close() aufgerufen wird.
Die Ausnahme GeneratorExit wird ausgelöst, damit der Generator vor dem Beenden eine Meldung aufräumen oder protokollieren kann.
Ich hoffe, du erkennst langsam, dass Generatoren nützlich sind. In diesem Abschnitt werde ich versuchen, die Anwendungsfälle hervorzuheben, damit du dir vorstellen kannst, wie sie in deinem Alltag funktionieren.
Eine der häufigsten Herausforderungen in der Datenwissenschaft ist die Arbeit mit Datensätzen, die zu groß sind, um in den Speicher zu passen. Generatoren bieten eine Möglichkeit, solche Daten Zeile für Zeile zu verarbeiten.
Stell dir vor, du hast eine 10 GB große CSV-Datei mit Verkaufsdaten und musst die Datensätze nach einer bestimmten Region filtern. Hier erfährst du, wie du eine Generator-Pipeline verwenden kannst, um dies zu erreichen:
import csv
def read_large_csv(file_path):
""" Generator to read a large CSV file line by line."""
with open(file_path, mode="r") as file:
reader = csv.DictReader(file)
for row in reader:
yield row
def filter_by_region(data, region):
""" Generator to filter rows by a specific region."""
for row in data:
if row["Region"] == region:
yield row
# Generator pipeline
file_path = "sales_data.csv"
region = "North America"
data = read_large_csv(file_path)
filtered_data = filter_by_region(data, region)
# Process the filtered data
for record in filtered_data:
print(record)Hier ist, was passiert ist:
read_large_csv liest die Datei Zeile für Zeile und gibt jede Zeile als Wörterbuch aus.
filter_by_region filtert Zeilen nach der angegebenen Region.
Die Pipeline verarbeitet Daten inkrementell, um eine Überlastung des Speichers zu vermeiden.
Dieser Ansatz kommt Workflows zum Extrahieren, Transformieren und Laden zugute, bei denen die Daten vor der Analyse bereinigt und transformiert werden müssen. Du wirst diese Art von Dingen in unserem Kurs ETL und ELT in Python sehen.
Daten kommen manchmal in einem kontinuierlichen Strom an. Denk an Sensordaten, Live Feeds oder soziale Medien.
Angenommen, du arbeitest mit IoT-Geräten, die jede Sekunde eine Temperaturmessung durchführen. Du möchtest die Durchschnittstemperatur über ein gleitendes Fenster von 10 Messwerten berechnen:
def sensor_data_stream():
"""Simulate an infinite stream of sensor data."""
import random
while True:
yield random.uniform(0, 100) # Simulate sensor data
def sliding_window_average(stream, window_size):
""" Calculate the average over a sliding window of readings."""
window = []
for value in stream:
window.append(value)
if len(window) > window_size:
window.pop(0)
if len(window) == window_size:
yield sum(window) / window_size
# Generator pipeline
sensor_stream = sensor_data_stream()
averages = sliding_window_average(sensor_stream, window_size=10)
# Print the average every second
for avg in averages:
print(f"Average temperature: {avg:.2f}")Hier ist die Erklärung:
sensor_data_stream simuliert einen unendlichen Strom von Sensormessungen.
sliding_window_average behält ein gleitendes Fenster der letzten 10 Messwerte bei und liefert deren Durchschnitt.
Die Pipeline verarbeitet Daten in Echtzeit und ist damit ideal für die Überwachung und Analyse.
Generatoren werden auch in Situationen eingesetzt, in denen die Datengröße nicht vorhersehbar ist oder wenn sie einfach unendlich ist.
Wenn du Websites scannst, weißt du oft nicht, wie viele Seiten oder Elemente du verarbeiten musst. Mit Generatoren kannst du diese Unvorhersehbarkeit elegant handhaben:
def scrape_website(url):
""" Generator to scrape a website page by page."""
while url:
# Simulate fetching and parsing a page
print(f"Scraping {url}")
data = f"Data from {url}"
yield data
url = get_next_page(url) # Hypothetical function to get the next page
# Usage
scraper = scrape_website("https://example.com/page1")
for data in scraper:
print(data)In Simulationen, wie z.B. Monte-Carlo-Methoden oder der Spieleentwicklung, können Generatoren unendliche oder dynamische Abläufe darstellen:
def monte_carlo_simulation():
""" Generator to simulate random events for Monte Carlo analysis."""
import random
while True:
yield random.random()
# Usage
simulation = monte_carlo_simulation()
for _ in range(10):
print(next(simulation))Aufgrund ihrer Funktionsweise eignen sich Generatoren hervorragend für Szenarien, in denen die Speichereffizienz entscheidend ist, aber (du wirst überrascht sein) sie sind nicht immer die schnellste Option. Vergleichen wir die Generatoren mit den Listen, um ihre Vorteile zu verstehen.
Zuvor haben wir gezeigt, dass Generatoren in Bezug auf den Speicherplatz besser sind als Listen. In diesem Teil haben wir den Speicherverbrauch beim Generieren einer Folge von 10 Millionen Zahlen verglichen. Lass uns jetzt etwas anderes machen, einen Geschwindigkeitsvergleich:
import time
# List comprehension
start_time = time.time()
sum([x**2 for x in range(1_000_000)])
print(f"List comprehension time: {time.time() - start_time:.4f} seconds")
# Generator expression
start_time = time.time()
sum(x**2 for x in range(1_000_000))
print(f"Generator expression time: {time.time() - start_time:.4f} seconds")List comprehension time: 0.1234 seconds
Generator expression time: 0.1456 secondsEin Generator spart zwar Speicherplatz, ist aber in diesem Fall sogar langsamer als die Liste. Das liegt daran, dass bei diesem kleineren Datensatz der Aufwand für das Anhalten und Wiederaufnehmen der Ausführung zu groß ist.
Bei kleinen Datenmengen ist der Leistungsunterschied vernachlässigbar, aber bei großen Datenmengen überwiegen die Speicherplatzeinsparungen der Generatoren oft den leichten Geschwindigkeitsverlust.
Zum Schluss wollen wir uns noch einige häufige Fehler oder Probleme ansehen:
Wenn ein Generator erschöpft ist, kann er nicht wieder verwendet werden. Du musst sie neu erstellen, wenn du sie erneut iterieren willst.
gen = (x for x in range(5))
print(list(gen)) # Output: [0, 1, 2, 3, 4]
print(list(gen)) # Output: [] (the generator is exhausted)Da Generatoren Werte bei Bedarf erzeugen, können Fehler oder Seiteneffekte erst auftreten, wenn der Generator iteriert wird.
Bei kleinen Datensätzen oder einfachen Aufgaben ist der Overhead, der durch die Verwendung eines Generators entsteht, die Speicherersparnis möglicherweise nicht wert. Betrachte dieses Beispiel, in dem ich Daten für mehrere Iterationen materialisiere.
# Generator expression
gen = (x**2 for x in range(10))
# Materialize into a list
squares = list(gen)
# Reuse the list
print(sum(squares)) # Output: 285
print(max(squares)) # Output: 81Zusammenfassend möchte ich einige sehr allgemeine Regeln für den Einsatz von Generatoren aufstellen. Verwendung für:
Wann Daten stattdessen materialisiert werden sollen (in eine Liste konvertieren)
In diesem Artikel haben wir untersucht, wie Generatoren dir helfen können, echte Herausforderungen in der Datenwissenschaft zu meistern, von der Verarbeitung großer Datenmengen bis hin zum Aufbau von Echtzeit-Datenpipelines. Übe weiter. Der beste Weg, Generatoren zu beherrschen, ist, sie in deiner eigenen Arbeit einzusetzen. Versuche zunächst, ein Listenverständnis durch einen Generatorausdruck zu ersetzen oder eine Schleife in eine Generatorfunktion umzuwandeln.
Sobald du die Grundlagen beherrschst, kannst du neue und fortgeschrittenere Themen erkunden, die auf dem Generatorenkonzept aufbauen:
Coroutines: Verwende .send() und .throw(), um Generatoren zu erstellen, die Daten empfangen und verarbeiten können und so eine Zwei-Wege-Kommunikation ermöglichen.
Asynchrone Programmierung: Kombiniere die Generatoren mit der asyncio-Bibliothek von Python, um effiziente, blockierungsfreie Anwendungen zu erstellen.
Gleichzeitigkeit: Lerne, wie Generatoren kooperatives Multitasking und leichtgewichtige Gleichzeitigkeit implementieren können.
Lerne weiter und werde ein Experte. Nimm noch heute an unserem Lernpfad für Python-Entwickler/innen oder an unserem Lernpfad für Python-Programmierer/innen teil. Klicke auf den Link unten, um loszulegen.
Lerne Python mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
