
Course
Introduction to Python
4 hr
6.9M
At their core, Python generators are a special kind of function or even a compact expression that produces a sequence of values lazily. Think of generators as a conveyor belt in a factory: Instead of stacking all the products in one place and running out of space, you process each item as it comes down the line. This makes generators memory-efficient and a natural extension of Python's iterator protocol, which underpins many of Python's built-in tools like for loops and comprehensions.
The magic behind generators lies in the yield keyword. Unlike return, which outputs a single value and exits the function, yield produces a value, pauses the function's execution, and saves its state. When the generator is called again, it picks up where it left off.
For example, imagine you're reading a massive log file line by line. A generator can process each line as read without loading the entire file into memory. This "lazy evaluation" sets generators apart from traditional functions and makes them a go-to tool for performance-sensitive tasks.
Let’s practice a bit to get the hang of the idea. Here is a generator function that produces the first n integers.
def generate_integers(n):
for i in range(n):
yield i # Pauses here and returns i
# Using the generator
for num in generate_integers(5):
print(num)0
1
2
3
4I created a visual to help you see what’s happening under the hood:
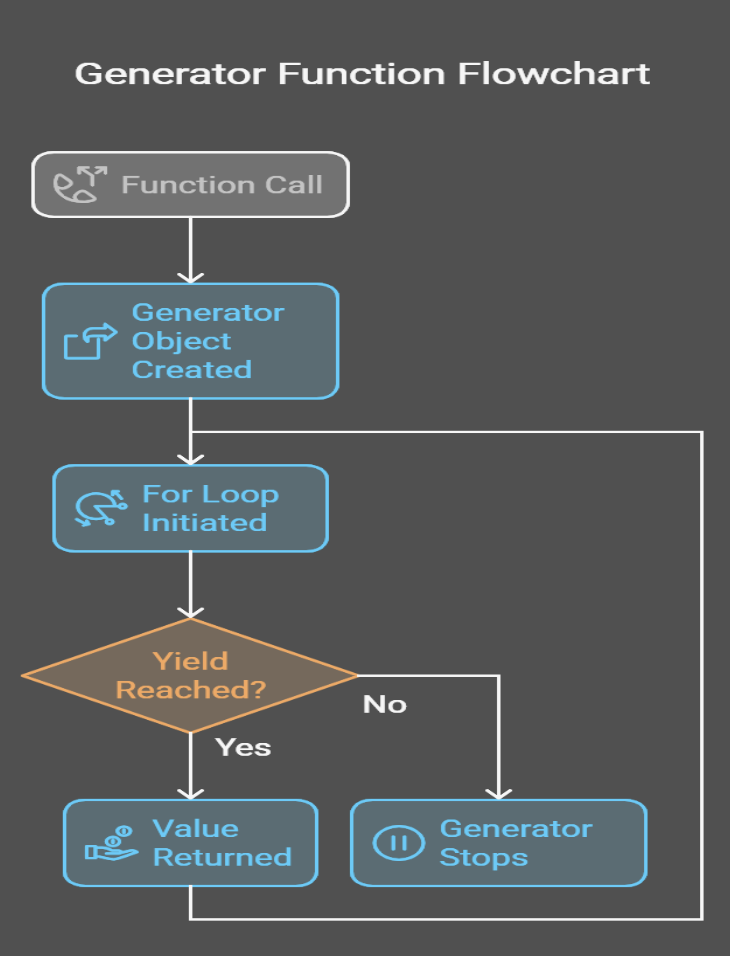
Generators can be implemented in multiple ways. That said, there are two primary ways: generator functions and generator expressions.
A generator function is defined like a regular function but uses the yield keyword instead of return. When called, it returns a generator object that can be iterated over.
def count_up_to(n):
count = 1
while count <= n:
yield count
count += 1
# Using the generator
counter = count_up_to(5)
for num in counter:
print(num)1
2
3
4
5From the above example, we can see that when the function count_up_to is called, it returns a generator object. Each time the for loop requests a value, the function runs until it hits yield, producing the current value of count and preserving its state between iterations so it can resume exactly where it left off.
Generator expressions are a compact way to create generators. They're similar to list comprehensions but with parentheses instead of square brackets.
# List comprehension (eager evaluation)
squares_list = [x**2 for x in range(5)] # [0, 1, 4, 9, 16]
# Generator expression (lazy evaluation)
squares_gen = (x**2 for x in range(5))
# Using the generator
for square in squares_gen:
print(square)0
1
4
9
16So, what’s the difference between a list comprehension and a generator expression? The list comprehension creates the entire list in memory, while the generator expression produces values one at a time, saving memory. If you are not familiar with list comprehensions, you can read about them in our Python List Comprehension Tutorial.
Traditional iterators in Python required classes with explicit __iter__() and __next__() methods, which involved a lot of boilerplate and manual state management, whereas generator functions simplify the process by automatically preserving state and eliminating the need for these methods—as demonstrated by a simple function that yields the square of each number up to n.
In explaining what are Python generators, I also conveyed some of the idea of why they are used. In this section, I want to go into a little more detail. Because generators aren't just a fancy Python feature but they really do actually solve real problems.
Unlike lists or arrays, which store all their elements in memory simultaneously, generators produce values on the fly, so they hold only one item in memory at a time.
For example, consider the difference between Python 2’s range() and xrange():
range() created a list in memory, which could be problematic for large ranges.
xrange() acted like a generator, producing values lazily.
Because the xrange() behavior was more useful, now, in Python 3, range() also behaves like a generator, so it avoids the memory overhead of storing all values simultaneously.
To show the idea, let’s compare memory usage when generating a sequence of 10 million numbers:
import sys
# Using a list
numbers_list = [x for x in range(10_000_000)]
print(f"Memory used by list: {sys.getsizeof(numbers_list) / 1_000_000:.2f} MB")
# Using a generator
numbers_gen = (x for x in range(10_000_000))
print(f"Memory used by generator: {sys.getsizeof(numbers_gen)} bytes")Memory used by list: 89.48 MB
Memory used by the generator: 112 bytesAs you can see, the generator uses almost no memory compared to the list, and this difference is significant.
Thanks to lazy evaluation, values are computed only when needed. This means you can start processing data immediately without waiting for the entire sequence to be generated.
For instance, imagine summing the squares of the first 1 million numbers:
# Using a list (eager evaluation)
sum_of_squares_list = sum([x**2 for x in range(1_000_000)])
# Using a generator (lazy evaluation)
sum_of_squares_gen = sum(x**2 for x in range(1_000_000))While both approaches give the same result, the generator version avoids creating a massive list, so we get the result faster.
Generators simplify the implementation of iterators by eliminating boilerplate code. Compare a class-based iterator with a generator function:
Here is the class-based iterator:
class SquaresIterator:
def __init__(self, n):
self.n = n
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current >= self.n:
raise StopIteration
result = self.current ** 2
self.current += 1
return result
# Usage
squares = SquaresIterator(5)
for square in squares:
print(square)Here is the generator function:
def squares_generator(n):
for i in range(n):
yield i ** 2
# Usage
squares = squares_generator(5)
for square in squares:
print(square)The generator version is shorter, easier to read, and requires no boilerplate code. It’s a perfect example of Python’s philosophy: simple is better.
Finally, I want to say that generators are uniquely suited for representing infinite sequences, something that’s simply impossible with lists. For example, consider the Fibonacci sequence:
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# Usage
fib = fibonacci()
for _ in range(10):
print(next(fib))0
1
1
2
3
5
8
13
21
34This generator can produce Fibonacci numbers indefinitely without running out of memory. Other examples include processing live data streams or working with time series data.
Now, let’s look at some more difficult ideas. In this section, we'll explore how to compose generators and use unique generator methods like .send(), .throw(), and .close().
Generators can be combined. You can transform, filter, and process data modularly by chaining generators together.
Let's say you have an infinite sequence of numbers and want to square each number and filter out odd results:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
def square_numbers(sequence):
for num in sequence:
yield num ** 2
def filter_evens(sequence):
for num in sequence:
if num % 2 == 0:
yield num
# Compose the generators
numbers = infinite_sequence()
squared = square_numbers(numbers)
evens = filter_evens(squared)
# Print the first 10 even squares
for _ in range(10):
print(next(evens))0
4
16
36
64
100
144
196
256
324The process involves the infinite_sequence function generating numbers indefinitely, while the square_numbers yields the square of each number, and then filter_evens filters out odd numbers to produce only even squares. Our Associate Python Developer career track goes into this kind of thing, so you can see how to build and debug complex pipelines using generators, as well as iterators and list comprehensions.
Generators come with advanced methods allowing two-way communication and controlled termination.
The .send() method allows you to pass values back into a generator, turning it into a coroutine. This is useful for creating interactive or stateful generators.
def accumulator():
total = 0
while True:
value = yield total
if value is not None:
total += value
# Using the generator
acc = accumulator()
next(acc) # Start the generator
print(acc.send(10)) # Output: 10
print(acc.send(5)) # Output: 15
print(acc.send(20)) # Output: 35Here’s how it works:
The generator starts with next(acc) to initialize it.
Each call to .send(value) passes a value into the generator, which is assigned to value in the yield statement.
The generator updates its state (total) and yields the new result.
The .throw() method allows you to raise an exception inside the generator, which can be helpful for error handling or signaling specific conditions.
def resilient_generator():
try:
for i in range(5):
yield i
except ValueError:
yield "Error occurred!"
# Using the generator
gen = resilient_generator()
print(next(gen)) # Output: 0
print(next(gen)) # Output: 1
print(gen.throw(ValueError)) # Output: "Error occurred!"Here’s how this one works:
The generator usually runs until .throw() is called.
The exception is raised inside the generator, which can handle it using a try-except block.
The .close() method stops a generator by raising a GeneratorExit exception. This is useful for cleaning up resources or stopping infinite generators.
def infinite_counter():
count = 0
try:
while True:
yield count
count += 1
except GeneratorExit:
print("Generator closed!")
# Using the generator
counter = infinite_counter()
print(next(counter)) # Output: 0
print(next(counter)) # Output: 1
counter.close() # Output: "Generator closed!"And here’s how it’s working:
The generator runs until .close() is called.
The GeneratorExit exception is raised, allowing the generator to clean up or log a message before terminating.
I hope you are coming to appreciate that generators are useful. In this section, I’m going to try to make the use cases stand out so you can picture how they actually work for you in your day-to-day.
One of the most common challenges in data science is working with datasets too large to fit into memory. Generators provide a way to process such data line by line.
Imagine you have a 10 GB CSV file containing sales data and need to filter records for a specific region. Here's how you can use a generator pipeline to achieve this:
import csv
def read_large_csv(file_path):
""" Generator to read a large CSV file line by line."""
with open(file_path, mode="r") as file:
reader = csv.DictReader(file)
for row in reader:
yield row
def filter_by_region(data, region):
""" Generator to filter rows by a specific region."""
for row in data:
if row["Region"] == region:
yield row
# Generator pipeline
file_path = "sales_data.csv"
region = "North America"
data = read_large_csv(file_path)
filtered_data = filter_by_region(data, region)
# Process the filtered data
for record in filtered_data:
print(record)Here is what is happening:
read_large_csv reads the file line by line, yielding each row as a dictionary.
filter_by_region filters rows based on the specified region.
The pipeline processes data incrementally, avoiding memory overload.
This approach benefits extract, transform, and load workflows, where data must be cleaned and transformed before analysis. You will see this sort of thing in our ETL and ELT in Python course.
Data sometimes arrives as a continuous stream. Think sensor data, live feeds, or social media.
Suppose you’re working with IoT devices that generate temperature readings every second. You want to calculate the average temperature over a sliding window of 10 readings:
def sensor_data_stream():
"""Simulate an infinite stream of sensor data."""
import random
while True:
yield random.uniform(0, 100) # Simulate sensor data
def sliding_window_average(stream, window_size):
""" Calculate the average over a sliding window of readings."""
window = []
for value in stream:
window.append(value)
if len(window) > window_size:
window.pop(0)
if len(window) == window_size:
yield sum(window) / window_size
# Generator pipeline
sensor_stream = sensor_data_stream()
averages = sliding_window_average(sensor_stream, window_size=10)
# Print the average every second
for avg in averages:
print(f"Average temperature: {avg:.2f}")Here is the explanation:
sensor_data_stream simulates an infinite stream of sensor readings.
sliding_window_average maintains a sliding window of the last 10 readings and yields their average.
The pipeline processes data in real-time, making it ideal for monitoring and analytics.
Generators are also used in situations where data size is unpredictable or when it just keeps coming/is infinite.
When scraping websites, you often don’t know how many pages or items you’ll need to process. Generators allow you to handle this unpredictability gracefully:
def scrape_website(url):
""" Generator to scrape a website page by page."""
while url:
# Simulate fetching and parsing a page
print(f"Scraping {url}")
data = f"Data from {url}"
yield data
url = get_next_page(url) # Hypothetical function to get the next page
# Usage
scraper = scrape_website("https://example.com/page1")
for data in scraper:
print(data)In simulations, such as Monte Carlo methods or game development, generators can represent infinite or dynamic sequences:
def monte_carlo_simulation():
""" Generator to simulate random events for Monte Carlo analysis."""
import random
while True:
yield random.random()
# Usage
simulation = monte_carlo_simulation()
for _ in range(10):
print(next(simulation))Because of how they work, generators excel in scenarios where memory efficiency is critical, but (you might be surprised to know) they may not always be the fastest option. Let’s compare generators with lists to understand their trade-offs.
Previously, we showed how generators were better than lists in terms of memory. This was the part where we compared memory usage when generating a sequence of 10 million numbers. Let’s now do a different thing, a speed comparison:
import time
# List comprehension
start_time = time.time()
sum([x**2 for x in range(1_000_000)])
print(f"List comprehension time: {time.time() - start_time:.4f} seconds")
# Generator expression
start_time = time.time()
sum(x**2 for x in range(1_000_000))
print(f"Generator expression time: {time.time() - start_time:.4f} seconds")List comprehension time: 0.1234 seconds
Generator expression time: 0.1456 secondsWhile a generator saves memory, in this case, it’s actually slower than the list. This is because, for this smaller dataset, there is the overhead of pausing and resuming execution.
The performance difference is negligible for small datasets, but for large datasets, the memory savings of generators often outweigh the slight speed penalty.
Finally, let's look at some common mistakes or issues:
Once a generator is exhausted, it cannot be reused. You'll need to recreate it if you want to iterate again.
gen = (x for x in range(5))
print(list(gen)) # Output: [0, 1, 2, 3, 4]
print(list(gen)) # Output: [] (the generator is exhausted)Since generators produce values on demand, errors or side effects may not appear until the generator is iterated.
For small datasets or simple tasks, the overhead of using a generator may not be worth the memory savings. Consider this example where I am materializing data for multiple iterations.
# Generator expression
gen = (x**2 for x in range(10))
# Materialize into a list
squares = list(gen)
# Reuse the list
print(sum(squares)) # Output: 285
print(max(squares)) # Output: 81To recap, I’ll provide some very general rules on when to use generators. Use for:
When to materialize data instead (convert to a list)
Throughout this article, we’ve explored how generators can help you tackle real-world challenges in data science, from processing large datasets to building real-time data pipelines. Keep practicing. The best way to master generators is to use them in your own work. As a start, try replacing a list comprehension with a generator expression or refactor a loop into a generator function.
Once you’ve mastered the basics, you can explore new and more advanced topics that build on the generator concept:
Coroutines: Use .send() and .throw() to create generators that can receive and process data, enabling two-way communication.
Asynchronous programming: Combine generators with Python’s asyncio library to build efficient, non-blocking applications.
Concurrency: Learn how generators can implement cooperative multitasking and lightweight concurrency.
Keep learning and become an expert. Take our Python Developer career track or our Python Programming skill track today. Click the link below to get started.
Learn Python with DataCamp
Course
Course
Course
blog
Javier Canales Luna
13 min
Tutorial
Kurtis Pykes
Tutorial
Arunn Thevapalan
Tutorial
Oluseye Jeremiah
Tutorial
Samuel Shaibu
Tutorial
Bex Tuychiev


