Curso
Google Sheets intermedio
4 h
57.2K
Aunque muchas organizaciones almacenan datos en bases de datos y opciones de almacenamiento como AWS, Azure y GCP, las hojas de cálculo de Microsoft Excel siguen siendo muy utilizadas para almacenar conjuntos de datos más pequeños.
La funcionalidad de ciencia de datos de Excel es más limitada que la de R, por lo que resulta útil poder importar datos de hojas de cálculo a R.
En este tutorial veremos cómo leer hojas de cálculo de Excel (así como filas y columnas específicas) en R utilizando el paquete readxl.
Para entenderlo, necesitarás conocimientos básicos de R.
Para una guía más general sobre la importación de diferentes tipos de archivos en R, lea How to Import Data Into R: Un tutorial.
El conjunto de datos que leeremos en R es uno pequeño con sólo dos hojas para demostrar cómo especificar qué hoja leer. Puede consultarse aquí.
La primera hoja es un conjunto de datos de marketing bancario con 45.211 filas y 17 columnas. La siguiente captura de pantalla es del archivo excel "sample.xlsx" y nombre de hoja "bank-full".
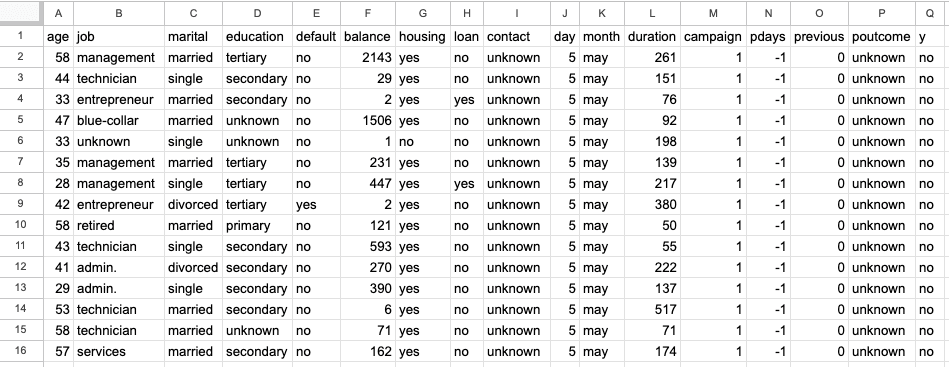
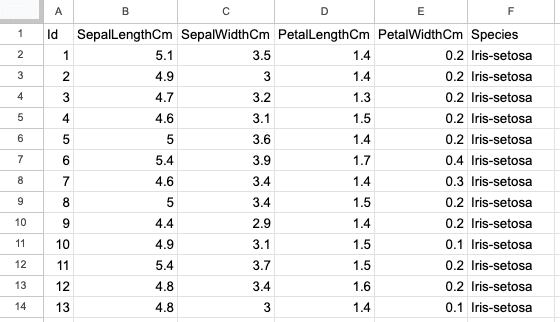
La segunda hoja es el conjunto de datos de Iris, con 150 filas y 6 columnas, y contiene información sobre los tipos de flor de Iris, como la longitud y anchura de sus sépalos y pétalos. La siguiente captura de pantalla es del mismo archivo excel, "sample.xlsx" y nombre de hoja "iris".
Este tutorial utiliza el paquete readxl. El paquete openxlsx es una alternativa decente que también incluye la capacidad de escribir en archivos XLSX, pero tiene una integración menos fuerte con paquetes tidyverse como dplyr y tidyr.
Para leer archivos Excel con el paquete readxl, primero tenemos que instalar el paquete y luego importarlo utilizando la función "library".
install.packages("readxl")Verá la siguiente salida en la consola, lo que indica que la instalación se ha realizado correctamente.
trying URL 'https://cran.rstudio.com/bin/macosx/big-sur-arm64/contrib/4.2/readxl_1.4.2.tgz'
Content type 'application/x-gzip' length 1545782 bytes (1.5 MB)
==================================================
downloaded 1.5 MB
The downloaded binary packages are in
/var/folders/mq/46mc_8tj06n0wh2xjkk08r140000gn/T//RtmpHIGYqM/downloaded_packagesPara utilizar los métodos "readxl", ejecute el siguiente comando en la consola R.
library(readxl)Tenga en cuenta que el paquete openxlsx es otra buena alternativa para escribir en archivos XLSX.
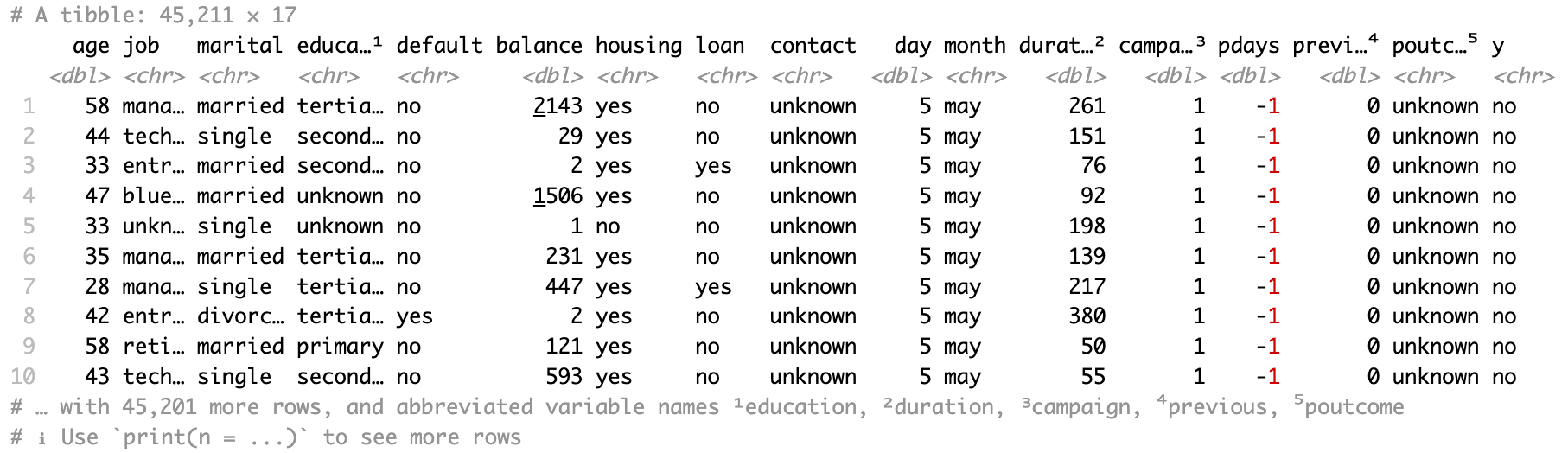
Leamos todos los datos de la primera hoja de cálculo, "banco-lleno", con read_xlsx() y sólo el argumento ruta.
bank_df <- read_xlsx(path = "sample.xlsx")El dato resultante es un tibble.
También puede utilizar read_excel() de la misma forma que read_xlsx(), y todos los argumentos que va a ver en las próximas secciones funcionan de forma similar con esta función. read_excel() intentará adivinar si tiene una hoja de cálculo XLSX, o el tipo de hoja de cálculo XLS más antiguo.
bank_df <- read_excel(path = "sample.xlsx")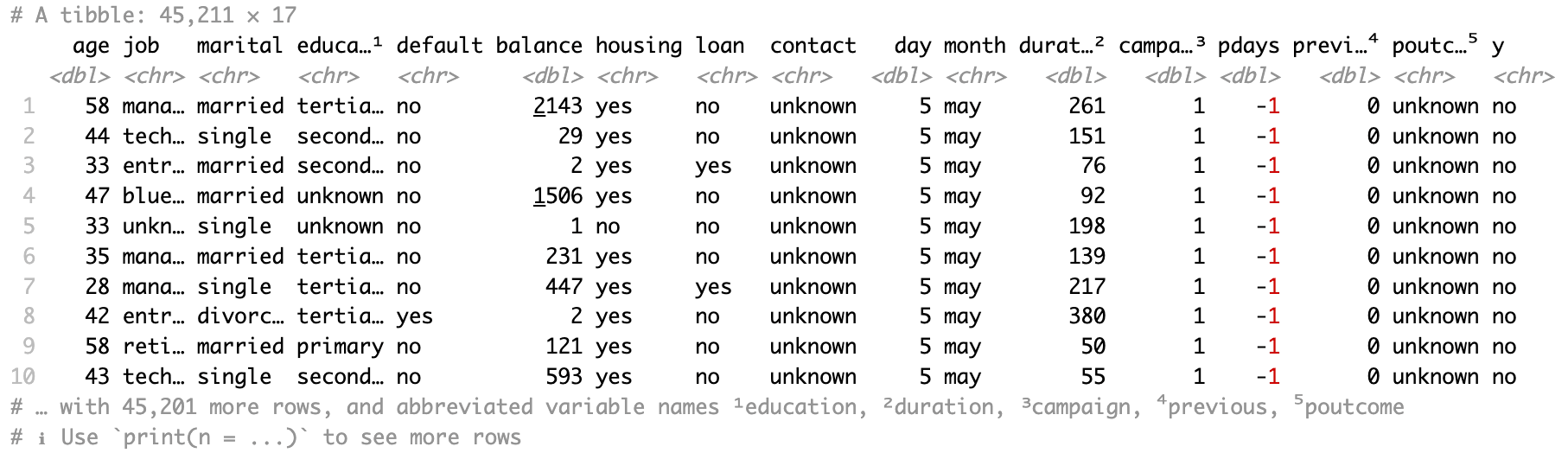
Ahora vamos a leer todos los datos del segundo libro de trabajo, es decir, "iris" con la función read_xlsx() y el argumento hoja.
iris <- read_xlsx("sample.xlsx", sheet = "iris")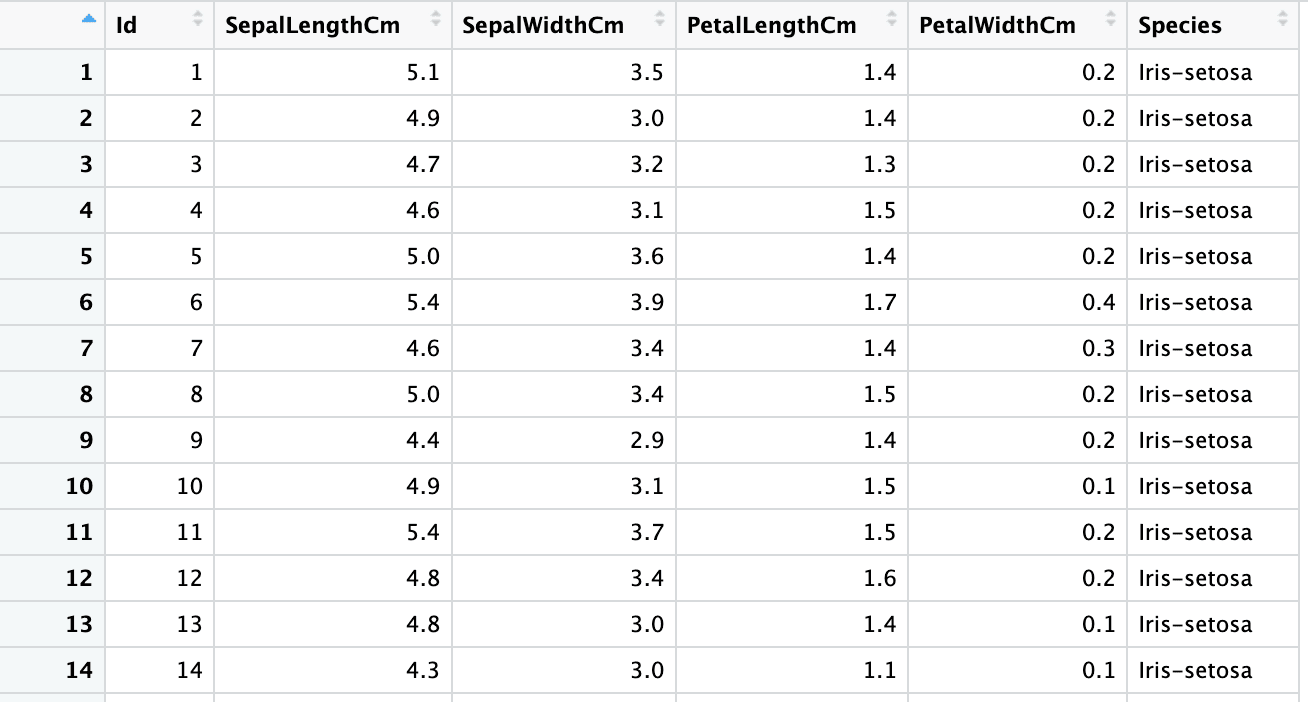
También puede especificar el número de hoja en el argumento hoja en lugar del nombre de la hoja.
iris2 <- read_xlsx("sample.xlsx", sheet = 1)
Vamos a leer filas específicas de un libro de trabajo estableciendo los argumentos skip y n_max. Para saltarse las primeras filas, puede utilizar el argumento skip con un valor igual al número de filas que desea saltarse.
bank_df_s2 <- read_excel("sample.xlsx", sheet = "bank-full", skip = 2)Tenga en cuenta que el código anterior omite también las cabeceras. En las secciones siguientes aprenderá a especificar cabeceras explícitamente en la función read_xlsx().
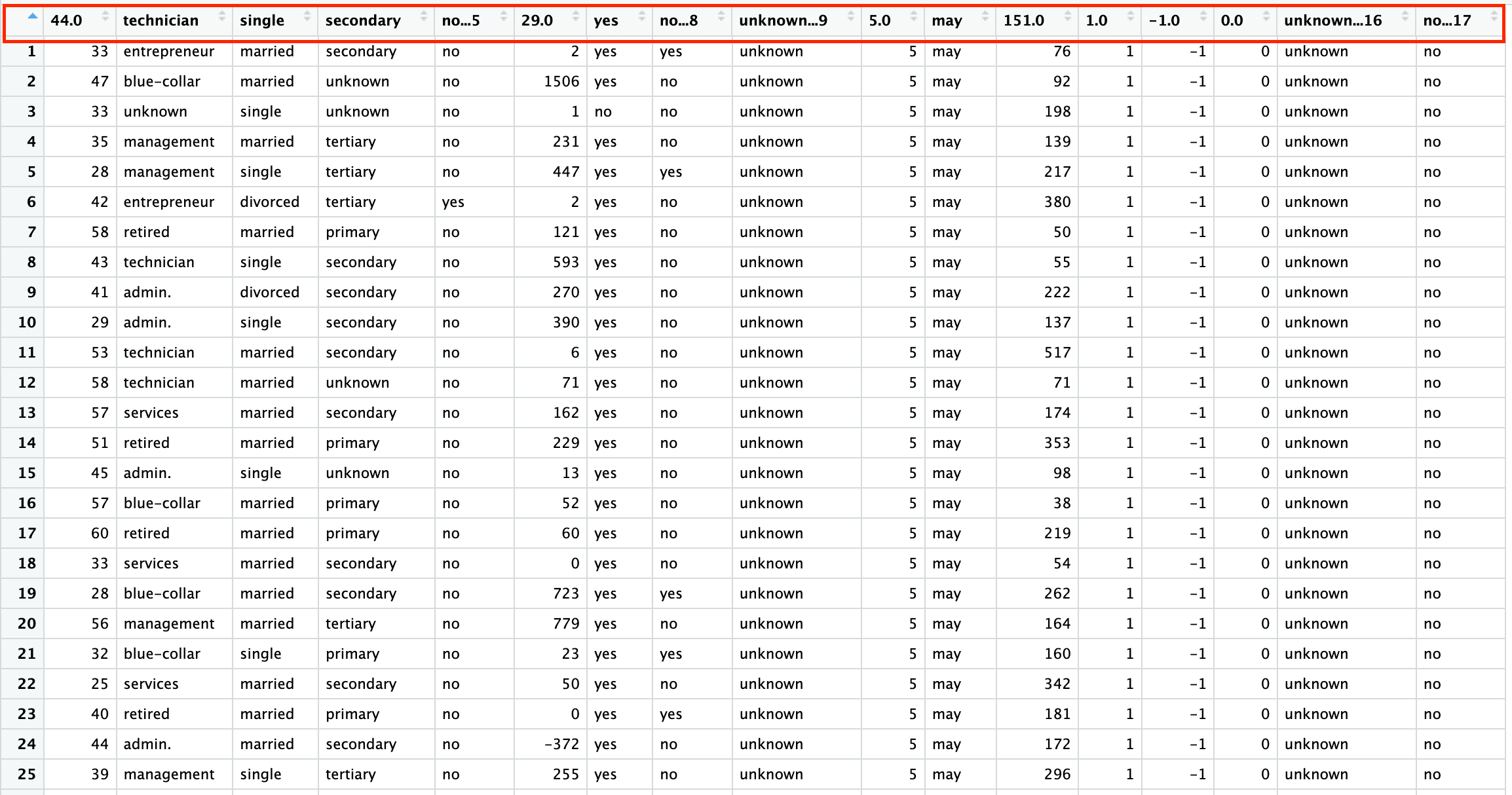
Del mismo modo, para leer las n primeras filas, especifique el argumento n_max en la función read_xlsx(). El código siguiente lee las 1000 primeras filas de la hoja "bank-full".
bank_df_n1k <- read_excel("sample.xlsx", sheet = "bank-full", n_max = 1000)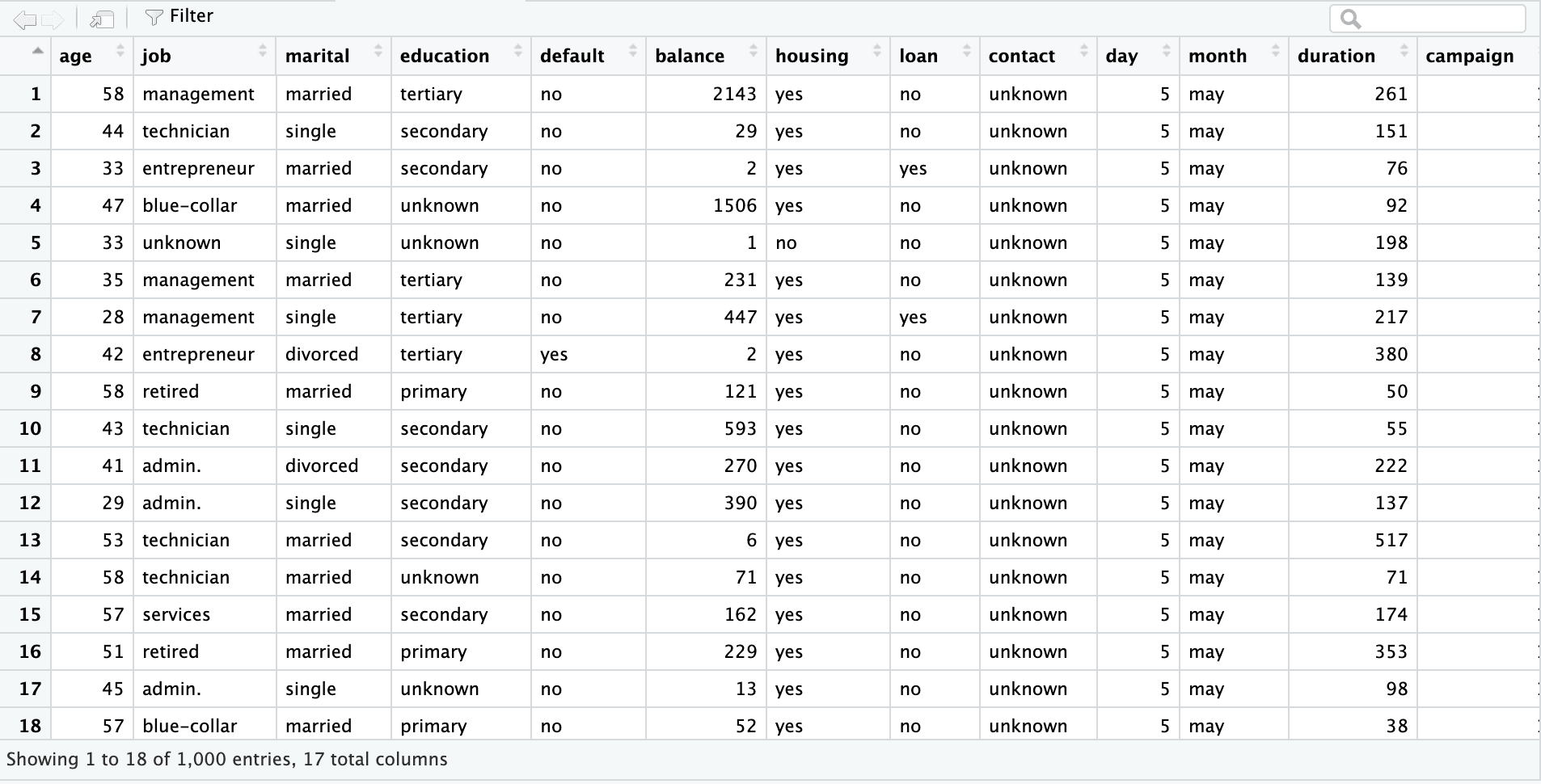
También puede combinar ambos argumentos para omitir algunas filas y leer un número específico de filas del conjunto de datos restante.
Mientras que los argumentos "skip" y "n_max" le permiten leer un subconjunto de las filas de los datos, puede leer celdas específicas de un libro de trabajo estableciendo el argumento rango.
Existen dos notaciones para especificar el subconjunto del conjunto de datos:
La idea es especificar las coordenadas del rectángulo que desea recortar del conjunto de datos.
Notación 1:
bank_df_range1 <- read_excel("sample.xlsx", sheet = "bank-full", range = "A3:E10")Notación 2:
bank_df_range2 <- read_excel("sample.xlsx", sheet = "bank-full",
range = "R3C1:R10C5")Range también le permite incluir el nombre de la hoja en el argumento (ejemplo: wbook!E4:G8).
bank_df_range3 <- read_excel("sample.xlsx", range = "bank-full!R3C1:R10C5")Vamos a leer datos que no tienen fila de cabecera estableciendo el argumento col_names en un vector de caracteres.
PS: Estamos utilizando el argumento skip primero para eliminar la fila de cabecera.
columns <- c("ID", "Sepal Length", "Sepal Width", "Petal Length", "Petal Width", "Species Name")
iris3 <- read_excel("sample.xlsx", sheet = 2, skip = 1, col_names = columns)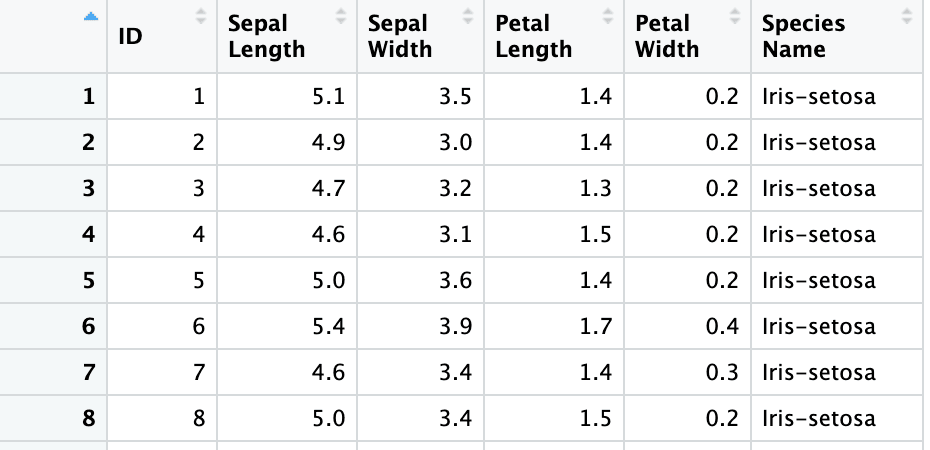
En la sección anterior, las cabeceras que especificamos estaban separadas por espacios. Puede convertir los nombres de cabecera en variables sintácticas de R con el argumento .name_repair = "universal".
iris4 <- read_excel("sample.xlsx", sheet = 2, skip = 1,
col_names = columns, .name_repair = "universal")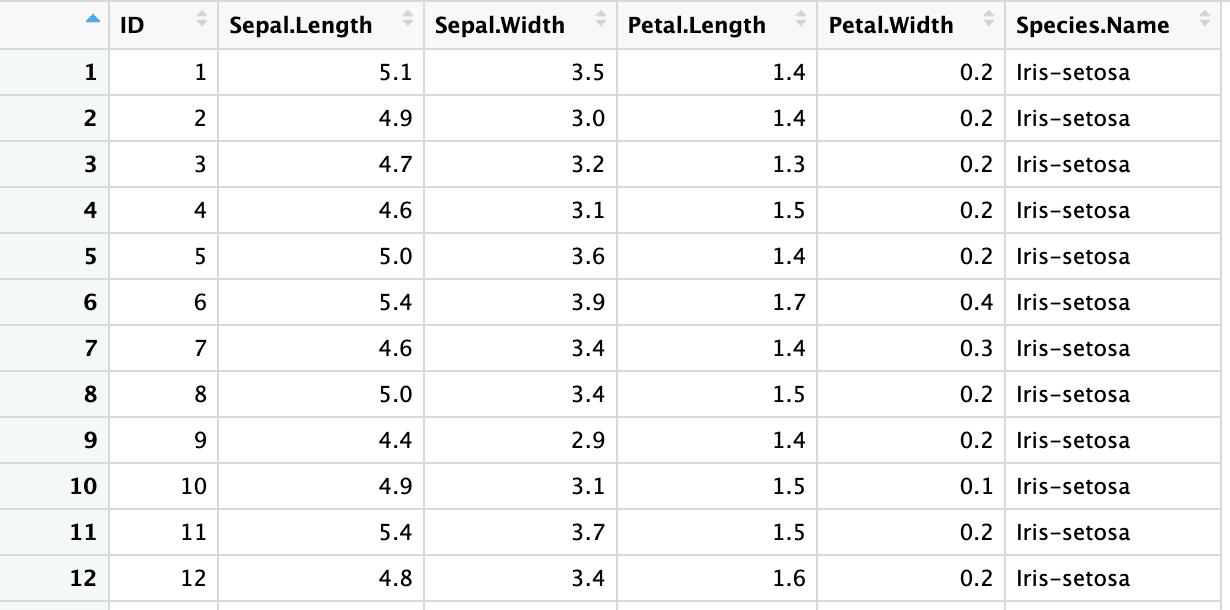
Por defecto, cuando se lee un fichero excel, R adivina el tipo de dato de cada variable. Observemos los tipos de columna del conjunto de datos del iris leídos utilizando los argumentos por defecto.
sapply(iris, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" Para anular las suposiciones de tipo de columna, puede utilizar el argumento col_types.
iris5 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris5, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 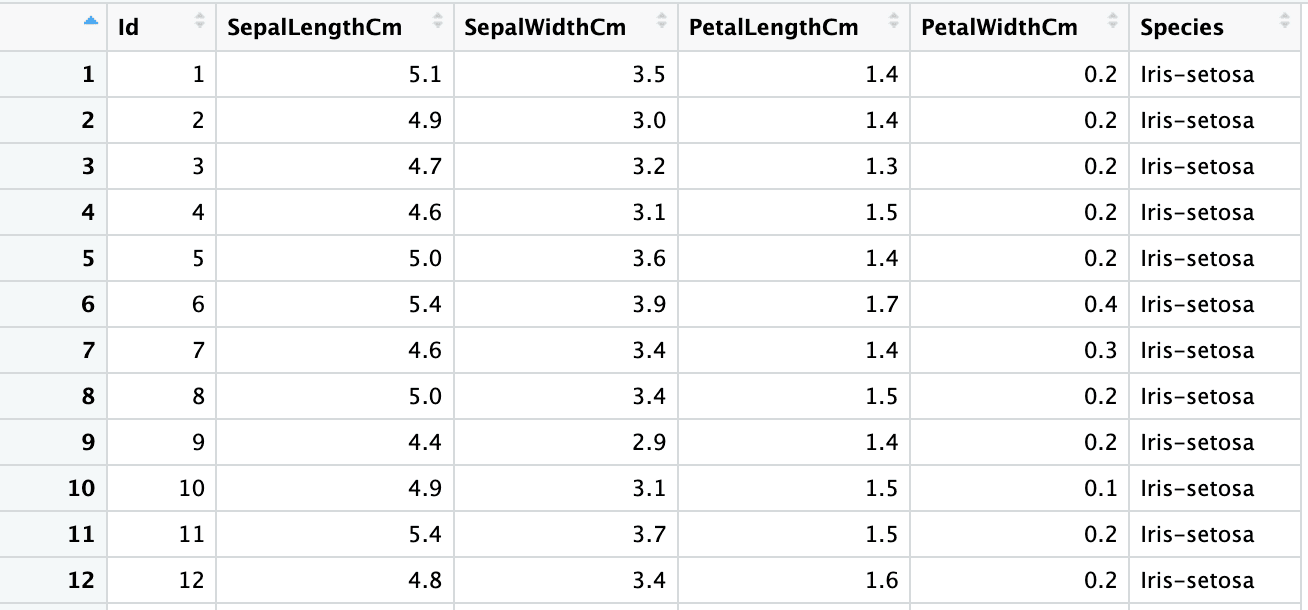
También puede dejar que R adivine los tipos de columna de las variables seleccionadas especificando el valor col_types como "guess" para una columna en particular.
iris6 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("guess", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris6, class)Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 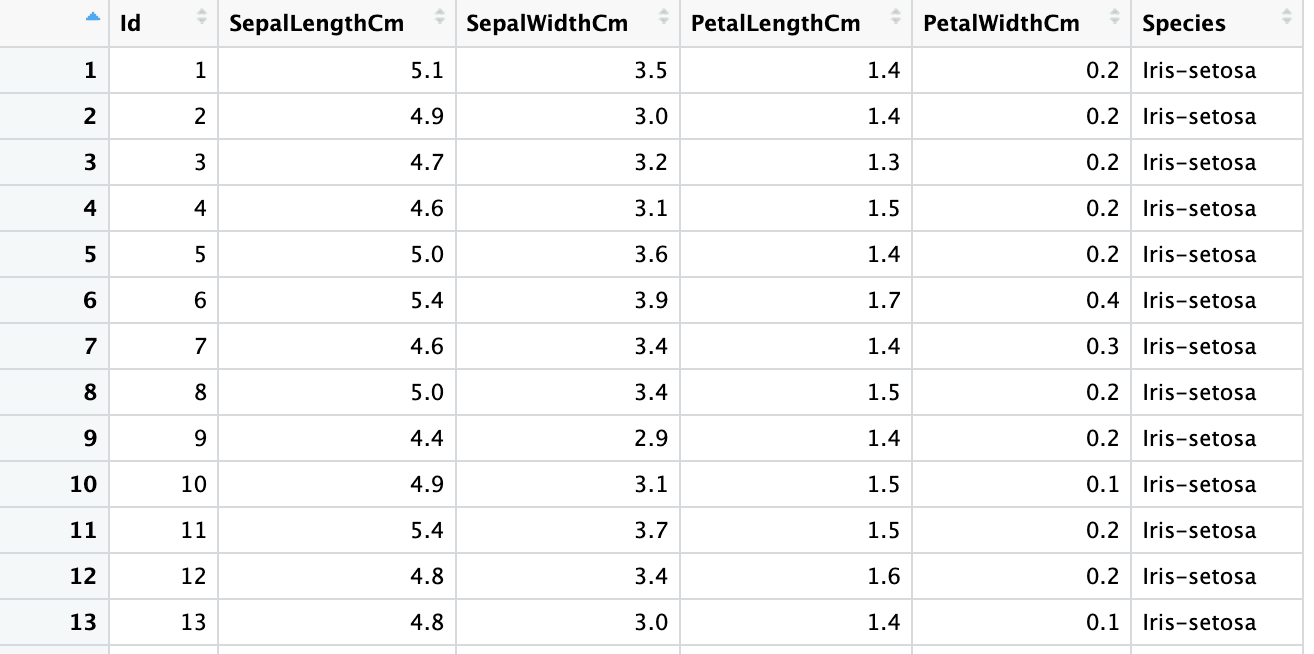
Aunque a menudo se oye decir que cuantos más datos, mejor. Pero en muchos casos de uso, se encuentra que algunas de las variables/columnas no contienen ninguna señal, que puede ser debido a cualquiera de las siguientes razones.
Puede omitir la lectura de algunas de las columnas configurando col_types como "skip", tal y como se muestra a continuación.
iris7 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "skip", "skip", "numeric", "numeric", "text"))
sapply(iris7, class) It To The Next Level
It To The Next LevelEn un mundo en el que los datos se generan a un ritmo vertiginoso y en formas muy variadas, su lenguaje de programación debe soportar la lectura de estos tipos de datos. R es uno de esos potentes lenguajes que apoyan este empeño. Inscríbase en el curso "Introducción a la importación de datos en R" para aprender cómo R ofrece paquetes para importar conjuntos de datos variados. Este curso ofrece tutoriales y cuestionarios para reforzar su comprensión de la importación de datos en R.
Más información sobre R y hojas de cálculo
Curso
Tutorial
Abid Ali Awan
Tutorial
Natassha Selvaraj
Tutorial
Francisco Javier Carrera Arias
Tutorial
Ryan Sheehy
Tutorial
Eladio Montero Porras