Machine Learning with Tree-Based Models in Python
BeginnerSkill Level
5 h
115.9K learners
Este tutorial explica cómo utilizar bosques aleatorios para la clasificación en Python. Trataremos:
Para aprovechar al máximo este artículo, debes tener conocimientos básicos de Python, pandas y scikit-learn. Es útil entender cómo se utilizan los árboles de decisión para la clasificación, así que plantéate leer primero el Tutorial de clasificación con árboles de decisión en Python. Si te estás iniciando en el uso de scikit-learn, consulta el Tutorial Kaggle: tu primer modelo de machine learning.
Aunque los bosques aleatorios pueden utilizarse tanto para la clasificación como para la regresión, este artículo se centrará en la construcción de un modelo de clasificación. Puedes encontrar el código de acompañamiento utilizado en este artículo en este DataCamp Workspace.
Practica la Clasificación de Bosques Aleatorios con Scikit-Learn en este ejercicio práctico.
Los bosques aleatorios son un popular algoritmo de machine learning supervisado.
Imagina que tienes que resolver un problema complejo y reúnes a un grupo de expertos de distintos campos para que aporten su opinión. Cada experto da su opinión basándose en sus conocimientos y experiencia. Después, los expertos votarían para llegar a una decisión final.
En una clasificación de bosque aleatorio, se crean múltiples árboles de decisión utilizando diferentes subconjuntos aleatorios de los datos y características. Cada árbol de decisión es como un experto, que da su opinión sobre cómo clasificar los datos. Las predicciones se hacen calculando la predicción de cada árbol de decisión, y luego tomando el resultado más popular. (Para la regresión, las predicciones utilizan en su lugar una técnica de promediado).
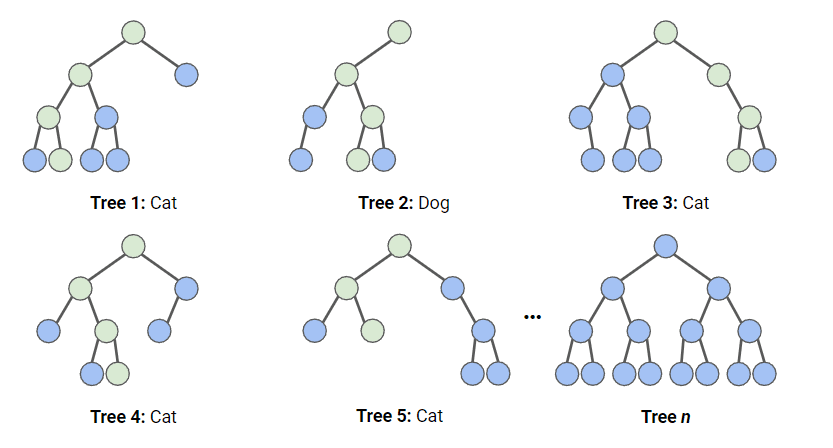
En el diagrama siguiente, tenemos un bosque aleatorio con n árboles de decisión, y hemos mostrado los 5 primeros, junto con sus predicciones (“Dog” o “Cat”, perro o gato). Cada árbol está expuesto a un número diferente de características y a una muestra diferente del conjunto de datos original, y como tal, cada árbol puede ser diferente. Cada árbol hace una predicción. Observando los 5 primeros árboles, podemos ver que 4/5 predijeron que la muestra era de un gato. Los círculos verdes indican un camino hipotético que siguió el árbol para llegar a su decisión. El bosque aleatorio contaría el número de predicciones de los árboles de decisión para “Cat” y para “Dog”, y elegiría la predicción más popular.
Este conjunto de datos consiste en campañas de marketing directo de una entidad bancaria portuguesa mediante llamadas telefónicas. Las campañas pretendían vender suscripciones a un depósito bancario a plazo fijo. Vamos a almacenar este conjunto de datos en una variable llamada bank_data.
Las columnas que utilizaremos son
age: edad de la persona que recibió la llamada telefónicadefault: si la persona tiene un crédito impagadocons.price.idx: puntuación del índice de precios al consumo en el momento de la convocatoriacons.conf.idx: puntuación del índice de confianza del consumidor en el momento de la llamaday: si la persona se suscribió (esto es lo que intentamos predecir)En este tutorial se utilizan los siguientes paquetes y funciones:
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizPara ajustar y entrenar este modelo, seguiremos la infografía El flujo de trabajo del machine learning; sin embargo, como nuestros datos están bastante limpios, no realizaremos todos los pasos. Haremos lo siguiente:
Los modelos basados en árboles son mucho más resistentes a los valores atípicos que los modelos lineales, y no necesitan que las variables estén normalizadas para funcionar. Por ello, necesitamos hacer muy poco preprocesamiento de nuestros datos.
no y yes, a 0s y 1s, respectivamente. Trataremos los valores unknown como no para este ejemplo.y, a 1s y 0s.bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Al entrenar cualquier modelo de aprendizaje supervisado, es importante dividir los datos en datos de entrenamiento y datos de prueba. Los datos de entrenamiento se utilizan para ajustar el modelo. El algoritmo utiliza los datos de entrenamiento para aprender la relación entre las características y el objetivo. Los datos de prueba se utilizan para evaluar el rendimiento del modelo.
El código siguiente divide los datos en variables separadas para las características y el objetivo, y luego los divide en datos de entrenamiento y de prueba.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Primero creamos una instancia del modelo Random Forest, con los parámetros por defecto. A continuación, lo ajustamos a nuestros datos de entrenamiento. Pasamos tanto las características como la variable objetivo, para que el modelo pueda aprender.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)Llegados a este punto, tenemos un modelo Random Forest entrenado, pero tenemos que averiguar si está haciendo predicciones precisas.
y_pred = rf.predict(X_test)La forma más sencilla de evaluar este modelo es mediante la precisión: comparamos las predicciones con los valores reales del conjunto de pruebas y contamos cuántas ha acertado el modelo.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Salida:
Accuracy: 0.888¡Es una puntuación bastante buena! Sin embargo, quizá podamos hacerlo mejor optimizando nuestros hiperparámetros.
Podemos utilizar el código siguiente para visualizar nuestros 3 primeros árboles.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)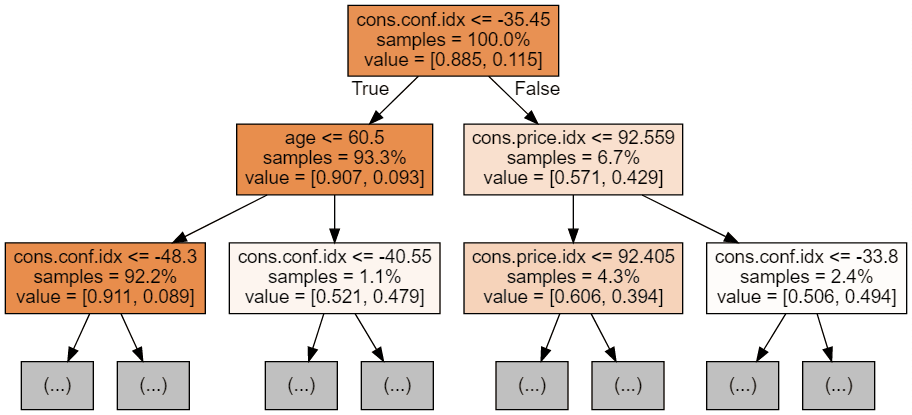
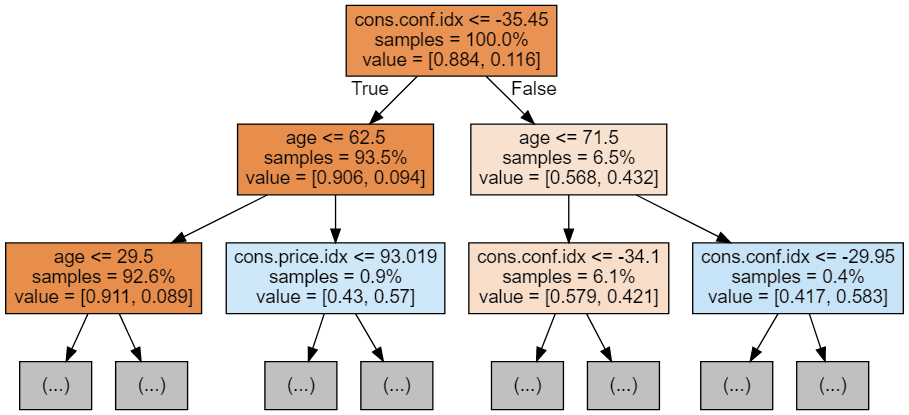
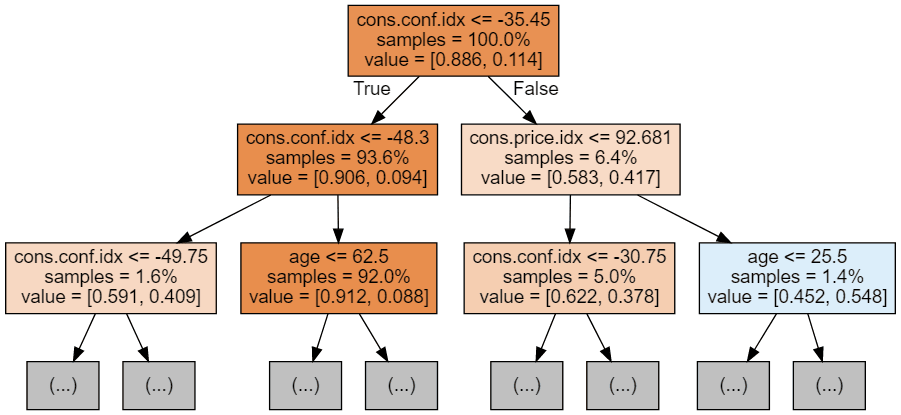
Cada imagen de árbol se limita a mostrar sólo los primeros nodos. Estos árboles pueden llegar a ser muy grandes y difíciles de visualizar. Los colores representan la clase mayoritaria de cada nodo (caja, con el rojo indicando mayoría 0 (sin suscripción) y el azul indicando mayoría 1 (suscripción). Los colores se oscurecen cuanto más se acerca el nodo a ser totalmente 0 ó 1. Cada nodo contiene también la siguiente información:
El código siguiente utiliza RandomizedSearchCV de Scikit-Learn, que buscará aleatoriamente parámetros dentro de un rango por hiperparámetro. Definimos los hiperparámetros a utilizar y sus rangos en el diccionario param_dist. En nuestro caso, estamos utilizando
param_dist = {'n_estimators': randint(50,500),
'max_depth': randint(1,20)}
# Create a random forest classifier
rf = RandomForestClassifier()
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(rf,
param_distributions = param_dist,
n_iter=5,
cv=5)
# Fit the random search object to the data
rand_search.fit(X_train, y_train)RandomizedSearchCV entrenará muchos modelos (definidos por n_iter_ y guardará cada uno de ellos como variables, el código siguiente crea una variable para el mejor modelo e imprime los hiperparámetros. En este caso, no hemos pasado un sistema de puntuación a la función, por lo que ésta utiliza por defecto la precisión. Esta función también utiliza la validación cruzada, lo que significa que divide los datos en cinco grupos de igual tamaño y utiliza 4 para entrenar y 1 para probar el resultado. Hará un bucle con cada grupo y dará una puntuación de precisión, que se promediará para encontrar el mejor modelo.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Salida:
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Veamos la matriz de confusión. Compara la predicción del modelo con la predicción correcta. Podemos utilizarla para comprender el equilibrio entre falsos positivos (arriba a la derecha) y falsos negativos (abajo a la izquierda). Podemos trazar la matriz de confusión utilizando este código:
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Salida:
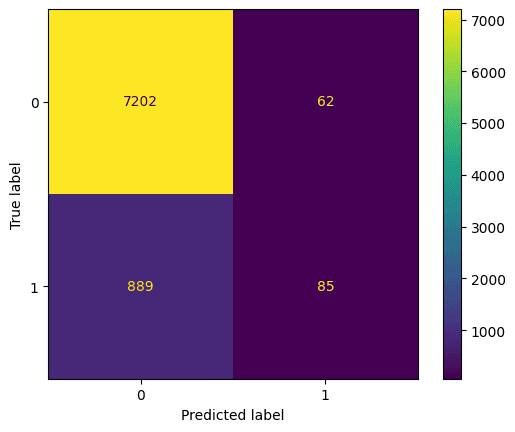
También debemos evaluar el mejor modelo con exactitud, precisión y recuerdo (ten en cuenta que tus resultados pueden diferir debido a la aleatorización)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Salida:
Accuracy: 0.885
Precision: 0.578
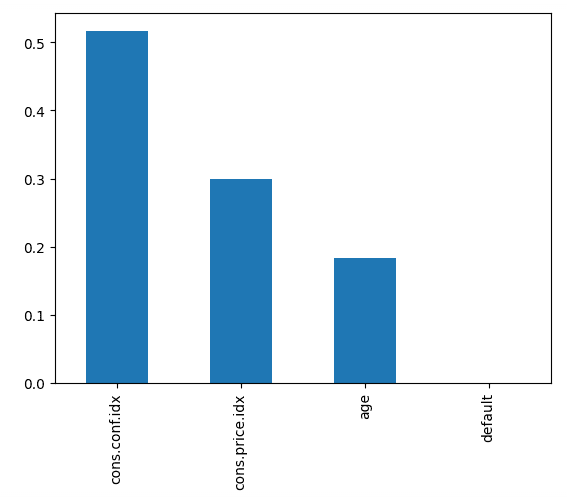
Recall: 0.0873El código siguiente traza la importancia de cada característica, utilizando la puntuación interna del modelo para encontrar la mejor forma de dividir los datos dentro de cada árbol de decisión.
# Create a series containing feature importances from the model and feature names from the training data
feature_importances = pd.Series(best_rf.feature_importances_, index=X_train.columns).sort_values(ascending=False)
# Plot a simple bar chart
feature_importances.plot.bar();Esto nos dice que el índice de confianza del consumidor, en el momento de la llamada, fue el mayor factor de predicción sobre si la persona se suscribió o no.
Cursos de Python
Curso
Curso
Curso
blog
Zoumana Keita
14 min
Tutorial
Avinash Navlani
Tutorial
Abid Ali Awan
Tutorial
Adam Shafi
Tutorial
Kevin Babitz
Tutorial
Avinash Navlani


