Curso
Aprendizaje no supervisado en Python
4 h
179.6K
SVM ofrece una exactitud muy alta en comparación con otros clasificadores, como la regresión logística y los árboles de decisión. Son conocidas por su truco del kernel para manejar espacios de entrada no lineales. Se utilizan en diversas aplicaciones, como la detección de caras, la detección de intrusos, la clasificación de correos electrónicos, artículos de noticias y páginas web, la clasificación de genes y el reconocimiento de escritura.
En este tutorial, utilizarás scikit-learn en Python. Si quieres saber más sobre este paquete de Python, te recomiendo que eches un vistazo a nuestro curso Aprendizaje supervisado con scikit-learn.
SVM es un algoritmo apasionante y los conceptos son relativamente sencillos. El clasificador separa los puntos de datos utilizando un hiperplano con el mayor margen. Por eso el clasificador SVM también se conoce como clasificador discriminativo. SVM encuentra un hiperplano óptimo que ayuda a clasificar nuevos puntos de datos.
En este tutorial, vas a tratar los siguientes temas:
Mira y aprende más sobre las máquinas de vectores de soporte con Scikit-learn en este vídeo de nuestro curso.
En general, las máquinas de vectores de soporte se consideran un enfoque de clasificación, pero pueden emplearse en problemas de clasificación y de regresión. Pueden manejar fácilmente varias variables continuas y categóricas. SVM crea un hiperplano en un espacio multidimensional para separar las distintas clases. SVM genera un hiperplano óptimo de forma iterativa, que se utiliza para minimizar un error. La idea central de SVM es hallar el hiperplano de máximo margen (MMH) que divida mejor el conjunto de datos en clases.
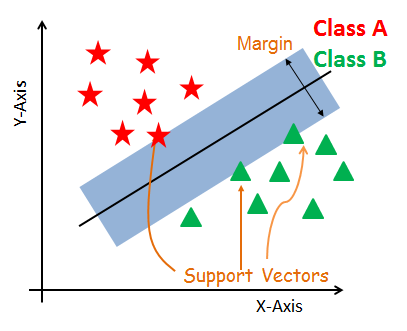
Los vectores de soporte son los puntos de datos más próximos al hiperplano. Estos puntos definirán mejor la línea de separación calculando los márgenes. Estos puntos son más relevantes para la creación del clasificador.
Un hiperplano es un plano de decisión que separa un conjunto de objetos que pertenecen a diferentes clases.
Un margen es un espacio entre las dos líneas de los puntos de clase más cercanos. Se calcula como la distancia perpendicular de la línea a los vectores de soporte o puntos más cercanos. Si el margen es mayor entre las clases, se considera un buen margen; un margen menor es un mal margen.
El objetivo principal es segregar el conjunto de datos dado de la mejor manera posible. La distancia entre los puntos más cercanos se conoce como margen. El objetivo es seleccionar un hiperplano con el máximo margen posible entre vectores de soporte en el conjunto de datos dado. SVM busca el hiperplano de máximo margen en los pasos siguientes:
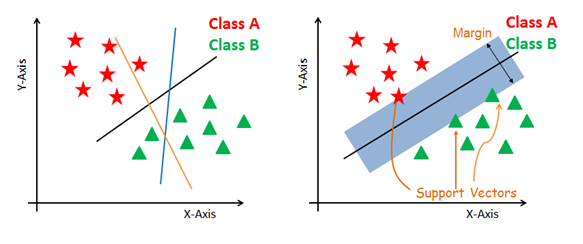
Generar hiperplanos que segreguen las clases de la mejor manera. La figura de la izquierda muestra tres hiperplanos: negro, azul y naranja. Aquí, el azul y el naranja tienen mayor error de clasificación, pero el negro separa correctamente las dos clases.
Selecciona el hiperplano con la máxima segregación de los puntos de datos más cercanos, como se muestra en la figura de la derecha.
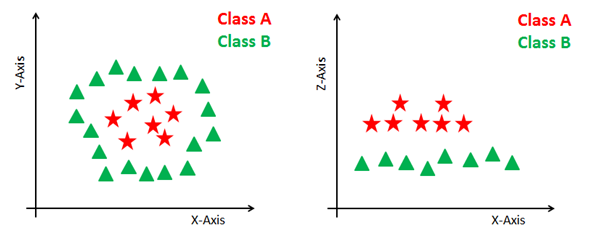
Algunos problemas no pueden resolverse utilizando el hiperplano lineal, como se muestra en la figura siguiente (lado izquierdo).
En tal situación, SVM utiliza un truco del kernel para transformar el espacio de entrada en un espacio de mayor dimensión, como se muestra a la derecha. Los puntos de datos se representan en el eje x y el eje z (Z es la suma al cuadrado de x e y: z = x^2 = y^2). Ahora puedes segregar fácilmente estos puntos utilizando la separación lineal.
El algoritmo SVM se implementa en la práctica utilizando un kernel. Un kernel transforma un espacio de datos de entrada en la forma requerida. SVM utiliza una técnica llamada truco del kernel. Aquí, el kernel toma un espacio de entrada de baja dimensión y lo transforma en un espacio de dimensión superior. En otras palabras, se puede decir que convierte el problema no separable en problemas separables añadiéndole más dimensión. Es útil sobre todo en problemas de separación no lineal. El truco del kernel te ayuda a crear un clasificador más exacto.
K(x, xi) = sum(x * xi)
K(x,xi) = 1 + sum(x * xi)^d
Donde d es el grado del polinomio. d = 1 es similar a la transformación lineal. El grado debe especificarse manualmente en el algoritmo de aprendizaje.
K(x,xi) = exp(-gamma * sum((x – xi^2))
Aquí gamma es un parámetro, que va de 0 a 1. Un valor más alto de gamma se ajustará perfectamente al conjunto de datos de entrenamiento, lo que provoca un sobreajuste. Gamma = 0,1 se considera un buen valor por defecto. El valor de gamma debe especificarse manualmente en el algoritmo de aprendizaje.
Hasta ahora, has conocido los fundamentos teóricos de SVM. Ahora conocerás su implementación en Python utilizando scikit-learn.
En la parte de creación del modelo, puedes utilizar el conjunto de datos sobre el cáncer, que es un problema de clasificación multiclase muy famoso. Este conjunto de datos se calcula a partir de una imagen digitalizada de una aspiración con aguja fina (FNA) de una masa mamaria. Describen las características de los núcleos celulares presentes en la imagen.
El conjunto de datos comprende 30 características (radio medio, textura media, perímetro medio, área media, suavidad media, compactibilidad media, concavidad media, puntos cóncavos medios, simetría media, dimensión fractal media, error de radio, error de textura, error de perímetro, error de área, error de suavidad, error de compactibilidad, error de concavidad, error de puntos cóncavos, error de simetría, error de dimensión fractal, peor radio, peor textura, peor perímetro, peor área, peor suavidad, peor compactibilidad, peor concavidad, peores puntos cóncavos, peor simetría y peor dimensión fractal) y un objetivo (tipo de cáncer).
Estos datos tienen dos tipos de clases de cáncer: maligno (dañino) y benigno (no dañino). Aquí puedes crear un modelo para clasificar el tipo de cáncer. El conjunto de datos está disponible en la biblioteca scikit-learn o puedes descargarlo de UCI Machine Learning Library.
Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoCursos de Scikit-learn
Curso
Curso
blog
Moez Ali
8 min
blog
Zoumana Keita
14 min
Tutorial
Kevin Babitz
Tutorial
Bekhruz Tuychiev
