Curso
Visualización de datos en Google Sheets
4 h
45.8K
Empecemos con los gráficos de datos más comunes que se utilizan ampliamente en muchos campos y que se pueden crear en la mayoría de las bibliotecas de visualización de datos de Python (excepto en algunas muy especializadas).
Un gráfico de barras es la visualización de datos más habitual para mostrar los valores numéricos de datos categóricos con el fin de comparar varias categorías entre sí. Las categorías se representan mediante barras rectangulares de la misma anchura y con alturas (para los gráficos de barras verticales) o longitudes (para los gráficos de barras horizontales) proporcionales a los valores numéricos a los que corresponden.
Para crear un gráfico de barras básico en matplotlib, utilizamos la función matplotlib.pyplot.bar(), como se indica a continuación:
# Data preparation
penguins_grouped = penguins[['species', 'bill_length_mm']].groupby('species').mean().reset_index()
# Creating a bar chart
plt.bar(penguins_grouped['species'], penguins_grouped['bill_length_mm'])
plt.title('Average penguin bill length by species')
plt.show()
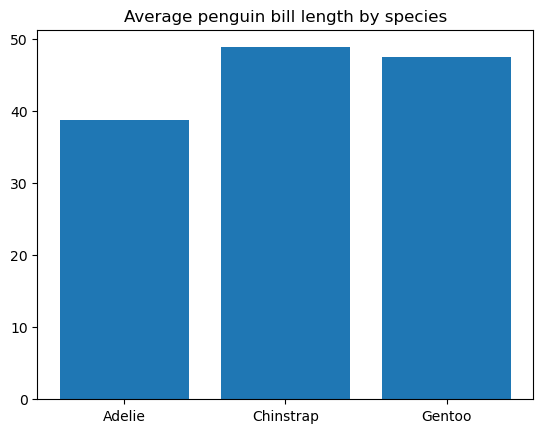
Podemos personalizar aún más el ancho y el color de las barras, el ancho y el color de los bordes de las barras, añadir etiquetas de tick a las barras, rellenar las barras con motivos, etc.
Para refrescar rápidamente los conocimientos sobre matplotlib, eche un vistazo a nuestra Matplotlib Cheat Sheet: Trazado en Python.
Un gráfico de líneas es un tipo de gráfico de datos que muestra una progresión de una variable de izquierda a derecha a lo largo del eje x mediante puntos de datos conectados por segmentos de líneas rectas. Lo más habitual es trazar el cambio de una variable a lo largo del tiempo. De hecho, los gráficos de líneas se utilizan a menudo para visualizar series temporales, como se explica en el tutorial sobre gráficos de líneas de series temporales de Matplotlib.
Podemos crear un gráfico lineal básico en matplotlib utilizando la función matplotlib.pyplot.plot(), de la siguiente manera:
# Data preparation
flights_grouped = flights[['year', 'passengers']].astype({'year': 'string'}).groupby('year').sum().reset_index()
# Creating a line plot
plt.plot(flights_grouped['year'], flights_grouped['passengers'])
plt.title('Total number of passengers by year')
plt.show()
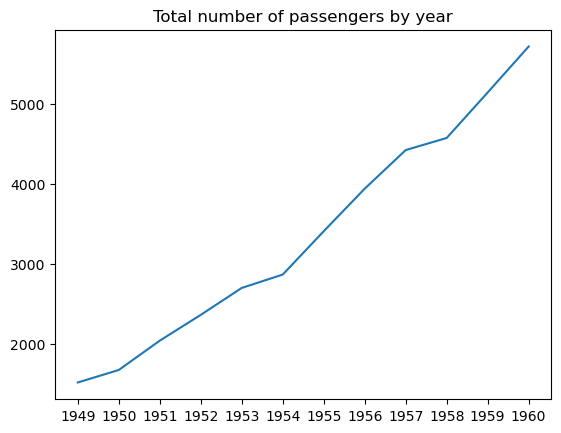
Es posible ajustar la anchura, el estilo, el color y la transparencia de las líneas, añadir y personalizar marcadores, etc.
El tutorial Line Plots in MatplotLib with Python proporciona más explicaciones y ejemplos sobre cómo crear y personalizar un gráfico de líneas en matplotlib. Para aprender a crear y personalizar un trazado de líneas en seaborn, lea Python Seaborn Line Plot Tutorial: Crear visualizaciones de datos.
Un gráfico de dispersión es un tipo de visualización de datos que muestra las relaciones entre dos variables trazadas como puntos de datos en el plano de coordenadas. Este tipo de gráfico de datos se utiliza para comprobar si las dos variables están correlacionadas entre sí, cuál es la intensidad de esta correlación y si existen conglomerados diferenciados en los datos.
El siguiente código ilustra cómo crear un gráfico de dispersión básico en matplotlib utilizando la función matplotlib.pyplot.scatter():
# Creating a scatter plot
plt.scatter(penguins['bill_length_mm'], penguins['bill_depth_mm'])
plt.title('Penguin bill length vs. bill depth')
plt.show()
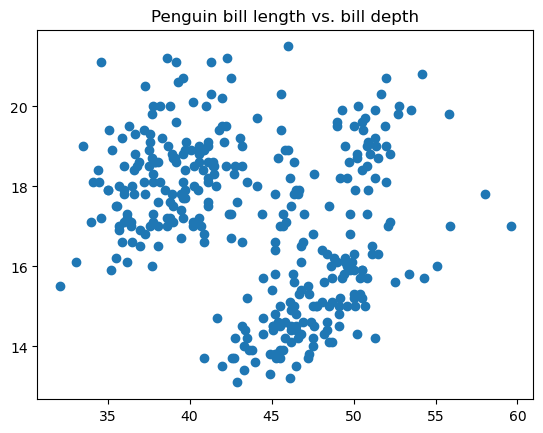
Podemos ajustar el tamaño del punto, el estilo, el color, la transparencia, el ancho del borde, el color del borde, etc.
Puedes leer más sobre gráficos de dispersión (¡y no sólo!) en este tutorial: Datos desmitificados: Visualizaciones de datos que captan las relaciones.
Un histograma es un tipo de gráfico de datos que representa la distribución de frecuencias de los valores de una variable numérica. Para ello, divide los datos en grupos de rangos de valores denominados bins, cuenta el número de puntos relacionados con cada bin y muestra cada bin como una barra vertical, con una altura proporcional al valor de recuento de ese bin. Un histograma puede considerarse como un tipo específico de gráfico de barras, sólo que sus barras adyacentes están unidas sin espacios, dada la naturaleza continua de los bins.
Podemos construir fácilmente un histograma básico en matplotlib utilizando la función matplotlib.pyplot.hist():
# Creating a histogram
plt.hist(penguins['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
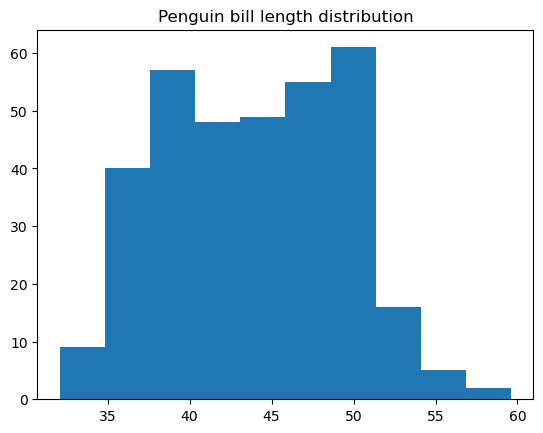
Es posible personalizar muchas cosas dentro de esta función, incluyendo el color y estilo del histograma, el número de bins, los bordes de los bins, el rango inferior y superior de los bins, si el histograma es regular o acumulativo, etc.
En el tutorial sobre Cómo crear un histograma con Plotly, puedes explorar otra forma de crear un histograma en Python.
Un gráfico de caja es un tipo de gráfico de datos que muestra un conjunto de cinco estadísticas descriptivas de los datos: los valores mínimo y máximo (excluyendo los valores atípicos), la mediana y el primer y tercer cuartil. Opcionalmente, también puede mostrar el valor medio. Un gráfico de cajas es la opción adecuada si sólo le interesan estas estadísticas, sin profundizar en la distribución real de los datos subyacentes.
En el tutorial sobre 11 técnicas de visualización de datos para cada caso de uso con ejemplos, encontrará, entre otras cosas, explicaciones más detalladas sobre qué tipo de información estadística puede obtener de un gráfico de caja.
Podemos crear un gráfico de caja básico en matplotlib utilizando la función matplotlib.pyplot.boxpot(), como se muestra a continuación:
# Data preparation
penguins_cleaned = penguins.dropna()
# Creating a box plot
plt.boxplot(penguins_cleaned['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
Hay mucho margen para personalizar un gráfico de caja: la anchura y orientación de la caja, la posición de la caja y los bigotes, la visibilidad y el estilo de varios elementos del gráfico de caja, etc.
Tenga en cuenta que para crear un gráfico de caja con esta función, primero tenemos que asegurarnos de que los datos no contienen valores perdidos. De hecho, en el ejemplo anterior, eliminamos los valores que faltaban de los datos antes de trazarlos. A modo de comparación, la biblioteca Seaborn no tiene esta limitación y gestiona los valores perdidos entre bastidores, como se indica a continuación:
# Creating a box plot
sns.boxplot(data=penguins, y='bill_length_mm')
plt.title('Penguin bill length distribution')
plt.show()
Un gráfico circular es un tipo de visualización de datos representado por un círculo dividido en sectores, donde cada sector corresponde a una determinada categoría de los datos categóricos, y el ángulo de cada sector refleja la proporción de esa categoría como parte del conjunto. A diferencia de los gráficos de barras, los gráficos circulares deben representar las categorías que constituyen el conjunto, por ejemplo, los pasajeros de un barco.
Los gráficos circulares tienen algunos inconvenientes:
Por lo tanto, los gráficos circulares deben utilizarse con moderación y precaución.
Para crear un gráfico circular básico en matplotlib, necesitamos aplicar la función matplotlib.pyplot.pie(), como sigue:
# Data preparation
titanic_grouped = titanic.groupby('class')['pclass'].count().reset_index()
# Creating a pie chart
plt.pie(titanic_grouped['pclass'], labels=titanic_grouped['class'])
plt.title('Number of passengers by class')
plt.show()
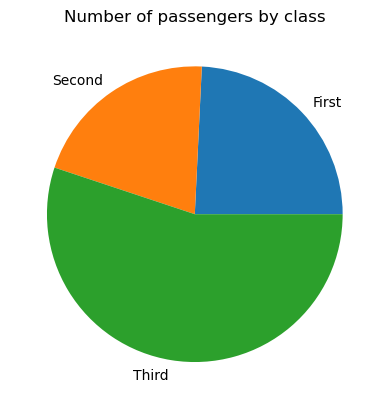
Si es necesario, podemos ajustar nuestro gráfico circular: cambiar los colores de sus cuñas, añadir un desplazamiento a algunas cuñas (normalmente las muy pequeñas), cambiar el radio del círculo, personalizar el formato de las etiquetas, rellenar algunas o todas las cuñas con patrones, etc.
En esta sección, vamos a explorar varios gráficos de datos avanzados. Algunos de ellos representan una variación elegante de los tipos comunes de visualizaciones de datos que hemos considerado en la sección anterior, otros son simplemente tipos independientes.
Mientras que un gráfico de barras común se utiliza para mostrar los valores numéricos de una variable categórica por categoría, un gráfico de barras agrupadas sirve para el mismo propósito pero a través de dos variables categóricas. Gráficamente, significa que tenemos varios grupos de barras, con cada grupo relacionado con una determinada categoría de una variable y cada barra de esos grupos relacionada con una determinada categoría de la segunda variable. Los gráficos de barras agrupadas funcionan mejor cuando la segunda variable no tiene más de tres categorías. En el caso contrario, se llenan demasiado y, por tanto, son menos útiles.
Al igual que un gráfico de barras común, podemos crear un gráfico de barras agrupadas con matplotlib. Sin embargo, la biblioteca Seaborn ofrece una funcionalidad más conveniente de su función seaborn.barplot() para crear este tipo de gráficos. Veamos un ejemplo de creación de un gráfico de barras agrupadas básico para la longitud del pico de los pingüinos a través de dos variables categóricas: especie y sexo.
# Creating a grouped bar chart
sns.barplot(data=penguins, x='species', y='bill_length_mm', hue='sex')
plt.title('Penguin bill length by species and sex')
plt.show()
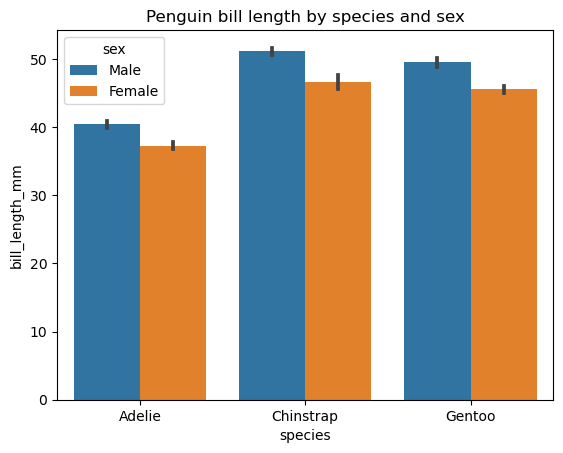
La segunda variable categórica se introduce a través del parámetro hue. Otros parámetros opcionales de esta función permiten cambiar la orientación, anchura y color de las barras, el orden de las categorías, el estimador estadístico, etc.
Para profundizar en el trazado con Seaborn, considere el siguiente curso: Visualización intermedia de datos con Seaborn.
Un gráfico de áreas apiladas es una extensión de un gráfico de áreas común (que es simplemente un gráfico de líneas con el área por debajo de la línea coloreada o rellena con un patrón) con múltiples áreas, cada una correspondiente a una variable concreta, apiladas unas sobre otras. Estos gráficos son útiles cuando necesitamos seguir tanto el progreso global de un conjunto de variables como la contribución individual de cada variable a este progreso. Al igual que los gráficos de líneas, los gráficos de áreas apiladas suelen reflejar el cambio de las variables a lo largo del tiempo.
Es importante tener en cuenta la principal limitación de los gráficos de áreas apiladas: ayudan sobre todo a captar la tendencia general, pero no los valores exactos de las áreas apiladas.
Para construir un gráfico básico de áreas apiladas en matplotlib, utilizamos la función matplotlib.pyplot.stackplot, como se muestra a continuación:
# Data preparation
flights_grouped = flights.groupby(['year', 'month']).mean().reset_index()
flights_49_50 = pd.DataFrame(list(zip(flights_grouped.loc[:11, 'month'].tolist(), flights_grouped.loc[:11, 'passengers'].tolist(), flights_grouped.loc[12:23, 'passengers'].tolist())), columns=['month', '1949', '1950'])
# Creating a stacked area chart
plt.stackplot(flights_49_50['month'], flights_49_50['1949'], flights_49_50['1950'], labels=['1949', '1950'])
plt.title('Number of passengers in 1949 and 1950 by month')
plt.legend()
plt.show()
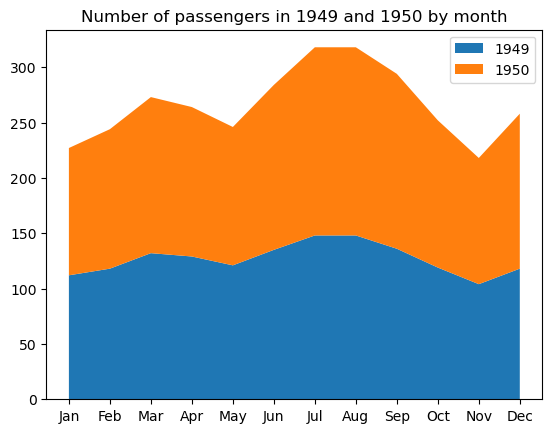
Algunas propiedades personalizables de este tipo de gráfico son los colores del área, la transparencia, los patrones de relleno, el ancho de línea, el estilo, el color, la transparencia, etc.
En la sección Tipos comunes de gráficos de datos, definimos un gráfico de caja como un tipo de visualización de datos que muestra un conjunto de cinco estadísticas descriptivas de los datos. A veces, es posible que queramos mostrar y comparar estos estadísticos por separado para cada categoría de una variable categórica. En tales casos, necesitamos trazar múltiples cajas en la misma área de trazado, lo que podemos hacer fácilmente con la función seaborn.boxplot(), como se indica a continuación:
# Creating multiple box plots
sns.boxplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
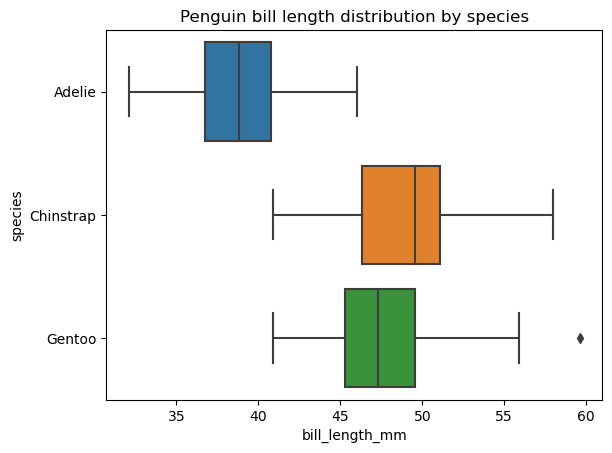
Es posible cambiar el orden de los gráficos de caja, su orientación, color, transparencia, anchura, las propiedades de sus distintos elementos, añadir otra variable categórica en el área del gráfico, etc.
Un gráfico de violín es similar a un gráfico de caja y muestra las mismas estadísticas generales de los datos, excepto que también muestra la forma de distribución de esos datos. Al igual que con los gráficos de caja, podemos crear un único gráfico de violín para los datos de interés o, más a menudo, varios gráficos de violín, cada uno para una categoría distinta de una variable categórica.
Seaborn proporciona más espacio para crear y personalizar gráficos de violín que matplotlib. Para construir un gráfico de violín básico en seaborn, necesitamos aplicar la función seaborn.violinplot(), como se indica a continuación:
Creating a violin plot
sns.violinplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
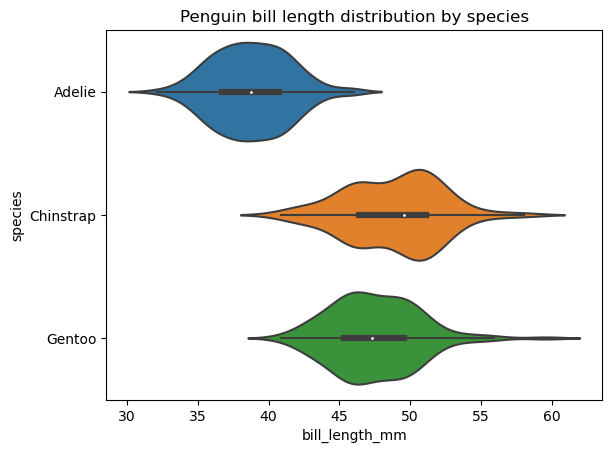
Podemos modificar el orden de los violines, su orientación, color, transparencia, anchura, las propiedades de sus distintos elementos, ampliar la distribución más allá de los puntos de datos extremos, añadir otra variable categórica en el área de trazado, seleccionar la forma en que se representan los puntos de datos en el interior del violín, etc.
Un mapa térmico es un tipo de visualización de datos tipo tabla en el que cada punto de datos numéricos se representa en función de una escala de colores seleccionada y de acuerdo con la magnitud del punto de datos dentro del conjunto de datos. La idea principal de estos gráficos es ilustrar los posibles puntos calientes y fríos de los datos que pueden requerir una atención especial.
En muchos casos, los datos necesitan cierto tratamiento previo antes de crear un mapa térmico para ellos. Esto suele implicar la limpieza y normalización de los datos.
El siguiente código muestra cómo crear un mapa de calor básico (tras el preprocesamiento de datos necesario) utilizando la función seaborn.heatmap():
# Data preparation
from sklearn import preprocessing
car_crashes_cleaned = car_crashes.drop(labels='abbrev', axis=1).iloc[0:10]
min_max_scaler = preprocessing.MinMaxScaler()
car_crashes_normalized = pd.DataFrame(min_max_scaler.fit_transform(car_crashes_cleaned.values), columns=car_crashes_cleaned.columns)
# Creating a heatmap
sns.heatmap(car_crashes_normalized, annot=True)
plt.title('Car crash heatmap for the first 10 car crashes')
plt.show()
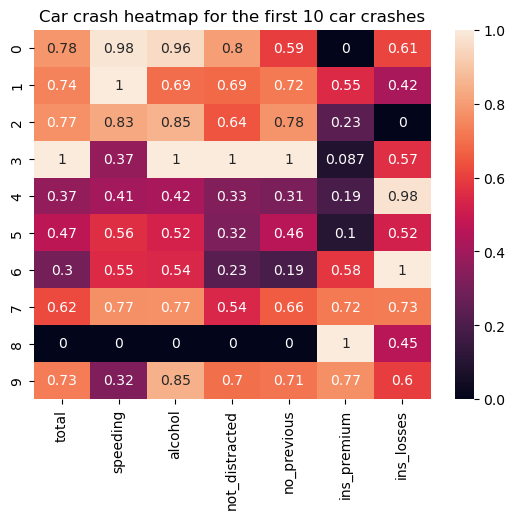
Algunos ajustes posibles pueden ser la selección de un mapa de colores, la definición de los valores de anclaje, el formato de las anotaciones, la personalización de las líneas de separación, la aplicación de una máscara, etc.
Por último, echemos un vistazo a algunos tipos de visualizaciones de datos poco utilizados o incluso menos conocidos. Muchos de ellos tienen al menos un análogo entre los tipos de gráficos más populares. Sin embargo, en algunos casos particulares, estas visualizaciones de datos poco convencionales pueden hacer un trabajo más eficaz que los gráficos de uso común.
Un gráfico de barras es prácticamente otra forma de representar un gráfico de barras, sólo que en lugar de barras sólidas, consiste en líneas finas con marcadores (opcionales) encima de cada una de ellas. Aunque un diagrama de tallo puede parecer una variación redundante de un gráfico de barras, en realidad es su mejor alternativa cuando se trata de visualizar muchas categorías. La ventaja de los gráficos de tallo frente a los de barras es que mejoran la relación datos/tinta y, por tanto, la legibilidad.
Para crear un gráfico de tallo básico en matplotlib, utilizamos la función matplotlib.pyplot.stem(), como se indica a continuación:
# Data preparation
fmri_grouped = fmri.groupby('subject')[['subject', 'signal']].max()
# Creating a stem plot
plt.stem(fmri_grouped['subject'], fmri_grouped['signal'])
plt.title('FMRI maximum signal by subject')
plt.show()
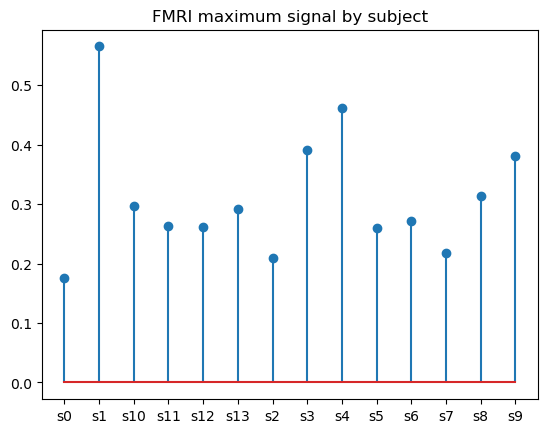
Podemos jugar con los parámetros opcionales de la función para cambiar la orientación del tallo y personalizar las propiedades del tallo, la línea de base y el marcador.
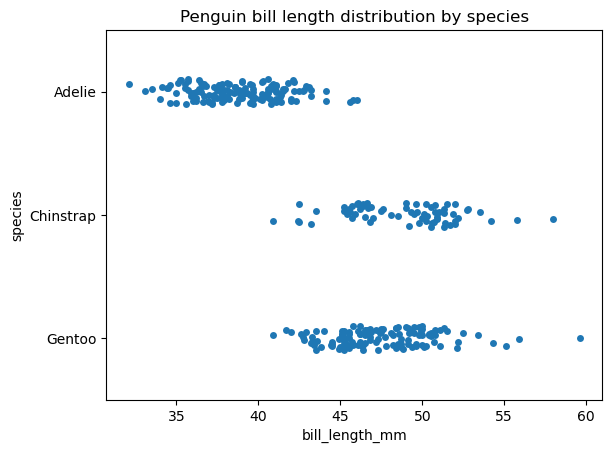
Estos dos tipos muy similares de visualizaciones de datos pueden considerarse como una implementación de un gráfico de dispersión para una variable categórica: tanto los gráficos de franjas como los de enjambres muestran el interior de la distribución de datos, incluyendo el tamaño de la muestra y la posición de los puntos de datos individuales, pero excluyendo los estadísticos descriptivos. La principal diferencia entre estos gráficos es que en un gráfico de franjas, los puntos de datos pueden solaparse, mientras que en un gráfico de enjambre, no. En cambio, en un gráfico de enjambre, los puntos de datos se alinean a lo largo del eje categórico.
Tenga en cuenta que tanto los gráficos de franjas como los de enjambre sólo pueden ser útiles para conjuntos de datos relativamente pequeños.
Así es como podemos crear un gráfico de bandas con la función seaborn.stripplot():
# Creating a strip plot
sns.stripplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
Ahora, creemos un gráfico de enjambre con la función seaborn.swarmplot() para los mismos datos y observemos la diferencia:
# Creating a swarm plot
sns.swarmplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
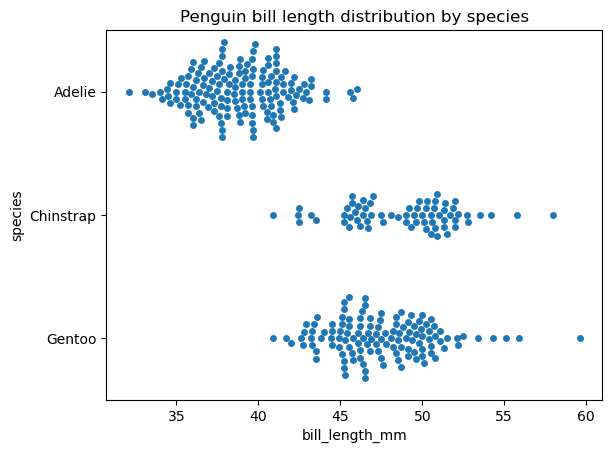
Las funciones seaborn.stripplot() y seaborn.swarmplot() tienen una sintaxis muy similar. Algunas propiedades personalizables en ambas funciones son el orden y la orientación del trazado y las propiedades del marcador, como el estilo, el tamaño, el color, la transparencia, etc. del marcador. Cabe mencionar que la regulación de la transparencia de los marcadores ayuda a solucionar parcialmente el problema de la superposición de puntos en un trazado de franjas.
Un mapa de árbol es un tipo de gráfico de datos utilizado para visualizar los valores numéricos de los datos categóricos por categoría como un conjunto de rectángulos situados dentro de un marco rectangular, con el área de cada rectángulo proporcional al valor de la categoría correspondiente. Por su finalidad, los diagramas de árbol son idénticos a los gráficos de barras y circulares. Al igual que los gráficos circulares, se supone que representan principalmente las categorías que constituyen el conjunto. Los mapas de árbol pueden resultar eficaces y convincentes cuando hay hasta diez categorías con una diferencia perceptible en sus valores numéricos.
Las desventajas de los mapas de árbol son muy similares a las de los gráficos circulares:
Debemos tener en cuenta estos puntos y utilizar los mapas de árbol con moderación y sólo cuando funcionen mejor.
Para construir un treemap en Python, primero necesitamos instalar e importar la librería squarify: pip install squarify y luego import squarify. El siguiente código crea un mapa de árbol básico:
import squarify
# Data preparation
diamonds_grouped = diamonds[['cut', 'price']].groupby('cut').mean().reset_index()
# Creating a treemap
squarify.plot(sizes=diamonds_grouped['price'], label=diamonds_grouped['cut'])
plt.title('Average diamond price by cut')
plt.show()
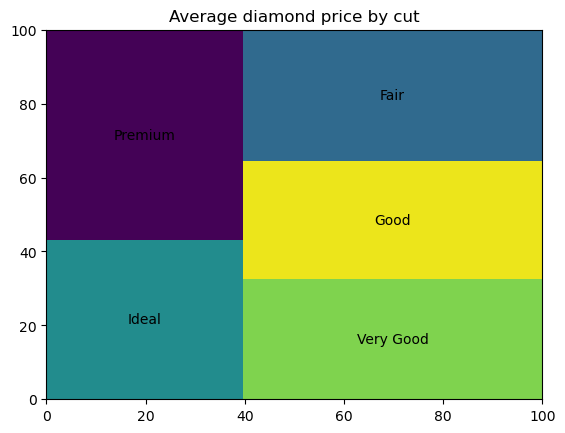
Podemos personalizar los colores y la transparencia de los rectángulos, rellenarlos con patrones, ajustar las propiedades de los bordes de los rectángulos, añadir un pequeño espacio entre los rectángulos y ajustar las propiedades del texto de la etiqueta.
Existe otro método para crear un mapa de árbol en Python, utilizando la biblioteca plotly. Puede obtener más información en el tutorial ¿Qué es la visualización de datos? Guía para científicos de datos.
Una nube de palabras es un tipo de visualización de datos de texto en el que el tamaño de fuente de cada palabra corresponde a la frecuencia de su aparición en un texto de entrada. El uso de nubes de palabras ayuda a encontrar las palabras más importantes de un texto.
Aunque las nubes de palabras son siempre llamativas e intuitivamente comprensibles para cualquier tipo de público objetivo, debemos ser conscientes de algunas limitaciones intrínsecas de este tipo de gráficos de datos:
Una aplicación interesante y menos conocida de las nubes de palabras es que podemos hacerlas basándonos no en la frecuencia de las palabras, sino en cualquier otro atributo asignado a cada palabra. Por ejemplo, podemos crear un diccionario de países, asignar a cada país el valor de su población y mostrar estos datos.
Para crear una nube de palabras en Python, necesitamos utilizar una biblioteca especializada en nubes de palabras. En primer lugar, tenemos que instalarlo (pip install wordcloud), luego importar la clase WordCloud y las palabras clave: from wordcloud import WordCloud, STOPWORDS. El siguiente código genera una nube de palabras básica:
from wordcloud import WordCloud, STOPWORDS
text = 'cat cat cat cat cat cat dog dog dog dog dog panda panda panda panda koala koala koala rabbit rabbit fox'
# Creating a word cloud
wordcloud = WordCloud().generate(text)
plt.imshow(wordcloud)
plt.title('Words by their frequency in the text')
plt.axis('off')
plt.show()

Es posible ajustar las dimensiones de una nube de palabras, cambiar su color de fondo, asignar un mapa de colores para la visualización de las palabras, establecer la preferencia de las palabras horizontales sobre las verticales, limitar el número máximo de palabras visualizadas, actualizar la lista de palabras vacías, limitar el tamaño de las fuentes, tener en cuenta las colocaciones de palabras, garantizar la reproducibilidad del gráfico, etc.
Si quieres aprender más sobre nubes de palabras en Python, aquí tienes una gran lectura: Tutorial de generación de nubes de palabras en Python. Además, puedes utilizar una plantilla gratuita para practicar la creación de este tipo de visualizaciones de datos: Plantilla: Crear una nube de palabras.
En este artículo, discutimos varios tipos de gráficos de datos, sus áreas de uso, sus limitaciones y cómo construirlos y personalizarlos en Python. Empezamos con las visualizaciones de datos más comunes, continuamos con otras más avanzadas y terminamos con algunos tipos de gráficos de datos poco convencionales pero a veces muy útiles.
A modo de breve resumen de cuándo utilizar cada uno de los gráficos de datos que hemos tratado, puedes encontrar nuestra útil Hoja de trucos de visualización de datos.
Aparte de Python, existen muchas otras herramientas para crear visualizaciones de datos perspicaces. A continuación encontrará una selección de cursos para principiantes, completos y exhaustivos que pueden resultarle útiles:
Comience hoy mismo su viaje a la visualización de datos
Curso
Curso
Curso
Tutorial
Kevin Babitz
Tutorial
Elena Kosourova
Tutorial
Arunn Thevapalan
Tutorial
Aditya Sharma
Tutorial
Elena Kosourova
Tutorial
Abid Ali Awan

