
programa
Ingeniero de Datos Asociado en SQL
30 h
En este artículo, expongo algunas técnicas que pueden ayudar a aprender dbt y agilizar la configuración del proyecto y el modelado de datos, haciendo que el proceso global sea más manejable.
Además, me adentraré en los patrones de diseño de proyectos dbt específicos en los que confío en mi trabajo diario. Estos métodos han demostrado ser inestimables en mis esfuerzos por construir plataformas de datos y almacenes de datos que sean precisos, intuitivos, fáciles de navegar y fáciles de usar.
La aplicación de estos enfoques facilita la creación de plataformas de datos que cumplan normas de alta calidad, al tiempo que minimiza los posibles problemas, lo que en última instancia conduce a proyectos basados en datos más exitosos.
dbt (Data Build Tool) es una potente solución de código abierto diseñada específicamente para el modelado de datos, que aprovecha las plantillas SQL y las funciones de ref() (referenciación) para establecer relaciones entre varias instancias de bases de datos, como tablas, vistas, esquemas, etc. Su flexibilidad es adecuada para quienes siguen el principio DRY (Do Not Repeat Yourself).
Con dbt, puedes crear una única plantilla SQL que puede reutilizarse y adaptarse fácilmente a distintos entornos de datos. Una vez escrita la plantilla, se puede "compilar" para generar las consultas SQL necesarias para su ejecución en cada entorno específico.
El enfoque que sigue dbt mejora la eficacia y garantiza la coherencia entre las distintas etapas de la canalización de datos, reduciendo la redundancia y los posibles errores, al tiempo que simplifica el proceso de mantenimiento y ampliación de la infraestructura de datos.
El modelado de datos desempeña un papel central en la ingeniería de datos, y dbt es una herramienta excelente. De hecho, ¡yo diría que dominar el dbt es absolutamente esencial para cualquiera que aspire a convertirse en un profesional de los datos de éxito!
Considera la plantilla dbt que aparece a continuación. Es una simple definición de tabla, pero lleva metadatos a bordo que indican al usuario qué base de datos y esquema debe utilizar:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Imaginemos que aguas abajo, en el canal de datos, tenemos una vista que sale de la tabla (table_a.sql) que hemos creado antes. Así, nuestro linaje de canalización de datos tendría este aspecto:

Ejemplo de linaje de canalización de datos. Imagen del autor.
Utilizaremos la función ref() para conectar dos etapas de nuestra tubería, y en nuestro caso, table_b.sql puede definirse así:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1La función ref() indica que el modelo table_b va después del table_a (aguas abajo). Ahora podemos ejecutar la tubería en su conjunto utilizando un solo comando dbt: dbt run --select tag:example.
Gracias a sus capacidades de código reutilizable, dbt ofrece funciones que lo convierten en una herramienta excelente para gestionar y optimizar los flujos de trabajo de datos en diversos entornos de datos (producción, desarrollo, pruebas, etc.).
Además, una de sus principales funciones es generar automáticamente documentación SQL completalo que mejora significativamente la transparencia y facilita la comprensión de los modelos de datos a los desarrolladores de datos y a las partes interesadas del negocio.
Uno de los retos a los que te enfrentas en el área del modelado de datos es la construcción de complejos conductos de transformación SQL que impliquen múltiples capas, al tiempo que haces que tu código sea reutilizable. Estos conductos requieren una cuidadosa reflexión y pruebas meticulosas para garantizar que funcionan eficazmente y mantener la transparencia organizativa, de modo que todos puedan comprender la lógica. la dbt también puede ayudar en este sentido.
Además, dbt admite pruebas de calidad de datos y pruebas unitarias para la lógica SQL, lo que te permite validar la precisión y fiabilidad de tus transformaciones de forma estructurada y automatizada(flujos de trabajo CI/CD).
Otra característica clave es su automatización flexible mediante macrosque permiten crear fragmentos de código personalizables y reutilizables, agilizando las tareas complejas y mejorando la productividad.
Estas funcionalidades combinadas hacen de dbt una solución ideal para gestionar cualquier tarea relacionada con SQL y entornos de datos, desde garantizar la integridad de los datos hasta automatizar procesos repetitivos, todo ello manteniendo la eficacia y la escalabilidad.
¡Pongámonos manos a la obra y ejecutemos algunos ejemplos con dbt y BigQuery como plataforma de datos!
Para este tutorial, utilizaremos Google Cloud BigQuery como solución de almacén de datos. Su nivel gratuito lo convierte en un candidato perfecto para aprender. Puedes activar BigQuery en tu cuenta de Google Cloud.
Instalaremos dbt localmente utilizando Python y el gestor pip, crearemos un entorno virtual y empezaremos a ejecutar modelos y pruebas de muestra.
Ejecuta los siguientes comandos en tu línea de comandos:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtNuestro requirements.txt debe contener las siguientes dependencias:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1A continuación, para el resto del tutorial, haremos lo siguiente:
Vamos a crear las credenciales de la cuenta de servicio para nuestra aplicación dbt:
Crear una cuenta de servicio para BigQuery en Google Cloud. Imagen del autor.
Guardar la clave privada de la cuenta de servicio en formato JSON. Imagen del autor.
dbt init en un terminal para inicializar finalmente nuestro proyecto dbt. Una vez finalizada la configuración, deberías recibir un mensaje como éste:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.Y la estructura de carpetas debería parecerse a esto:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtPodemos ver que profiles.yml se creó en la carpeta raíz de nuestra máquina local, pero lo ideal sería que estuviera en nuestra carpeta de aplicaciones, así que vamos a moverla.
cd my_dbt
touch profiles.ymlPor último, vamos a ajustar el contenido de profiles.yml para que refleje el nombre de nuestro proyecto e incluya las credenciales de la cuenta del servicio de Google:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comEso es. Estamos listos para compilar nuestro proyecto.
export DBT_PROFILES_DIR='.'
dbt compileEl resultado debería ser algo parecido a esto:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')La configuración inicial de nuestro proyecto ya está hecha.
Queremos diseñar nuestro proyecto dbt de forma cómoda y transparente para reflejar claramente la arquitectura del almacén de datos.
Recomiendo utilizar plantillas y macros en tu proyecto dbt e incorporar nombres de bases de datos personalizados para separar eficazmente tus entornos de datos en producción, desarrollo y pruebas.
Este enfoque mejora la organización y minimiza el riesgo de modificaciones accidentales en el entorno equivocado, mejorando la gestión general de los datos y la estabilidad del flujo de trabajo. De este modo, podemos gestionar y mantener fácilmente esos entornos, lo que contribuye a garantizar que los datos de producción permanezcan seguros y no se vean afectados por cambios experimentales o de prueba.
Las bases de datos de distintos entornos también pueden nombrarse de forma estructurada y coherente utilizando los sufijos correspondientes (_prod, _dev, _test), lo que facilita la diferenciación entre entornos y permite transiciones y despliegues más fluidos.

Las distintas capas del almacén de datos en un entorno de producción. Imagen del autor.
Por ejemplo, podemos trasladar las capas principales del modelo de datos a la convención de nomenclatura de la base de datos utilizando los prefijos raw_ y base_ en la nomenclatura de la base de datos:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsPara inyectar dinámicamente estos nombres de base de datos personalizados, sólo tienes que crear una macro dbt que se encargue de esta tarea automáticamente. Aprovechando este enfoque, puedes asegurarte de que se utilizan los nombres de base de datos correctos en el entorno de datos adecuado, sin tener que editar manualmente las configuraciones cada vez.
Veamos el fragmento de código siguiente, que contiene una macro para establecer diferentes esquemas en función del entorno en el que nos encontremos:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Ahora, cada vez que compilemos nuestros modelos, dbt aplicará automáticamente el nombre personalizado de la base de datos en función de la configuración especificada en la configuración de cada modelo. Esto significa que se inyectará el nombre correcto de la base de datos durante el proceso de compilación, garantizando que los modelos se ajusten al entorno adecuado: producción, desarrollo o pruebas.
Al incorporar esta función, eliminamos la necesidad de realizar cambios manuales en los nombres de las bases de datos, mejorando aún más la eficacia y precisión de nuestro flujo de trabajo.
Estas configuraciones necesarias pueden establecerse en properties.yml para nuestros modelos:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullComo puedes ver, podemos utilizar sentencias condicionales básicas para introducir lógica en los archivos de configuración, gracias a que dbt es compatible con Jinja.
No se pueden utilizar macros en este contexto, pero podemos utilizar condicionales sencillas utilizando expresiones Jinja dentro de los archivos .yml. Deben ir entre comillas. Esto garantiza que el lenguaje de plantillas se interprete correctamente durante la ejecución.
Ejecutemos un comando de compilación dbt y veamos qué ocurre:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt admite variables, que son una función de personalización muy potente. Las variables se pueden utilizar tanto en plantillas SQL como en macros y se pueden suministrar desde la línea de comandos del siguiente modo:
dbt run -m table_b -t dev --vars '{my_var: my_value}'Las variables deben declararse en el archivo principal del proyecto dbt_project.yml. Por ejemplo, el siguiente fragmento muestra cómo hacerlo:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Utilicemos variables para crear nombres de tabla personalizados (nombres de alias) en dbt.
Si no hay ningún alias, el nombre original del modelo (nombre de archivo) se utiliza como alias por defecto. Esta sencilla lógica garantiza que se haga referencia a los modelos por su alias configurado o por su nombre por defecto, dependiendo de la configuración. La implementación de esta funcionalidad tiene el siguiente aspecto, garantizando la flexibilidad en la forma de nombrar y referenciar los modelos en los distintos entornos:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Anulemos este comportamiento utilizando variables. Se trata de una configuración habitual para que los desarrolladores de datos mitiguen los riesgos de pisarse unos a otros mientras trabajan en la puesta en escena (desarrollo).
Queremos añadir el nombre del desarrollador a todas las instancias de la base de datos (tablas, vistas, etc.) creadas por ingenieros de desarrollo.
Hagamos una macro generate_alias_name.sql:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}No olvides añadir nuestra nueva variable a dbt_project.yml y ejecutar esto en tu línea de comandos:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Deberías ver una salida como ésta:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1Podemos ver que nuestra variable se ha añadido a una tabla de nombre: table_a_mike.
Esta sección trata de cómo diseñamos nuestro almacén de datos en términos de transformación de datos. Una estructura lógica simplificada de un proyecto en dbt puede parecerse a la que se muestra a continuación:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlPersonalmente, siempre intento centrarme en mantener la capa del modelo de datos fundacional (base) lo más limpia y directa posible, asegurándome de que las transformaciones de datos se apliquen sólo cuando sea necesario. Con este enfoque, pretendemos diseñar y aplicar una capa de modelo de datos base_ que implique una manipulación mínima de los datos a nivel de columna.
Sin embargo, hay casos en los que un cierto nivel de manipulación puede ser beneficioso, sobre todo cuando se trata de optimizar el rendimiento de las consultas. En estos casos, pequeños ajustes en la capa base pueden mejorar significativamente la eficacia, por lo que merece la pena equilibrar la simplicidad y el aumento de rendimiento. En este caso, estaría justificado añadir un filtro adicional de unión o partición.
Una práctica recomendada es aplicar las siguientes técnicas para mejorar tus modelos de datos y canalizaciones:
biz_ y mart_. Esto puede ayudar a mejorar el rendimiento y garantizar que la lógica empresarial se gestiona de forma eficiente.select * y considera la posibilidad de dividir los archivos SQL largos y complejos en modelos más pequeños con pruebas unitarias.Considera la siguiente consulta SQL. Explica cómo crear esa materialización personalizada:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Ahora, si añadimos un modelo adicional llamado table_c para demostrar esta función, podemos utilizar el SQL siguiente:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Ahora, si lo compilamos, debería parecerse a un script SQL:
$ dbt compile -m table_c -t devEl resultado:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;La ventaja de este enfoque es que ya no necesitamos depender del adaptador BigQuery. Si creamos otra tabla o vista que haga referencia a esta operación, podemos utilizar simplemente la función estándar ref().
Al hacerlo, table_c se reconocerá automáticamente como una dependencia en el linaje de datos. Esto facilita el seguimiento de cómo se relacionan las tablas y garantiza que las relaciones entre los distintos modelos estén debidamente documentadas en tu entorno de datos.
Este método ayuda a gestionar las dependencias y proporciona una visión clara de cómo fluyen los datos a través de las distintas etapas, incluidos los pasos complejos de procesamiento de datos que implican secuencias de comandos. Esto es especialmente útil para mantener canalizaciones de datos complejas.
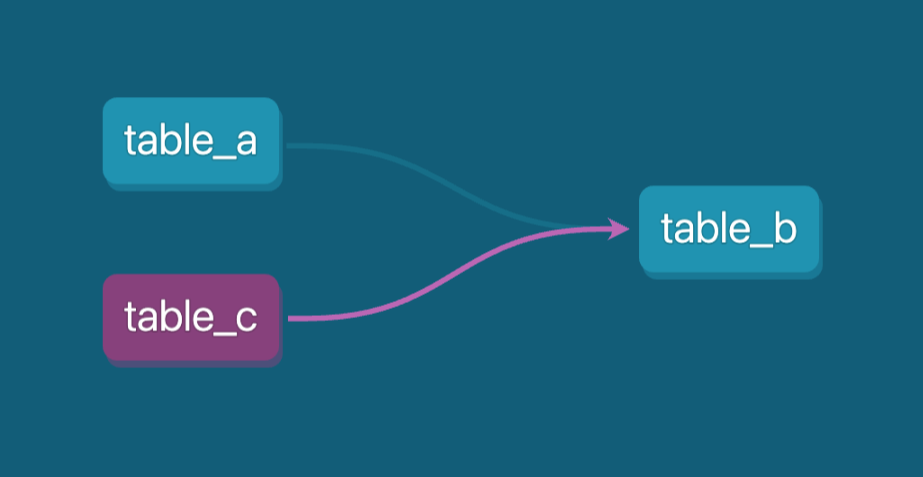
DAG (grafo acíclico dirigido) en dbt muestra las dependencias de table_b. Imagen del autor
Ahora, sólo tenemos que añadir table_c a nuestra canalización:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;¡La documentación se autogenerará si ejecutamos lo siguiente en nuestra línea de comandos!
dbt docs generate
dbt docs serveUn ejemplo más avanzado de un proyecto de almacenamiento de datos en dbt puede parecerse a la estructura siguiente. Contiene múltiples fuentes de datos y transformaciones a través de varias capas de modelos (stg, base, mrt, biz) para producir finalmente modelos de data mart.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlLas pruebas unitarias son un paso crucial en el proceso de canalización de datos, en el que podemos ejecutar pruebas para validar la lógica que subyace a nuestros modelos de datos. Del mismo modo que realizarías pruebas unitarias de tus funciones de Python para asegurarte de que se comportan según lo esperado, aplico un enfoque similar para probar los modelos de datos.
Al ejecutar estas pruebas, podemos detectar posibles problemas con antelación y asegurarnos de que las transformaciones y la lógica funcionan correctamente. Esta práctica ayuda a mantener la calidad de los datos y evita que los errores se propaguen a través de la canalización, lo que la convierte en un aspecto vital del proceso de ingeniería de datos.
Podemos añadir una prueba unitaria para un modelo simplemente modificando el archivo properties.yml:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Ahora, si ejecutamos el comando dbt test en nuestra línea de comandos, podremos ejecutar las pruebas unitarias:
% dbt test --select "table_b,test_type:unit"Este es el resultado:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Prueba a cambiar la fila id en expect a 3, y obtendremos un error para la misma prueba:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt también ofrece soporte para la comprobación de la calidad de los datos. Anteriormente escribí sobre ello en contratos de datos del blog. Podemos comprobar casi todo lo relacionado con la calidad de los datos, es decir, la frescura de los datos, las condiciones de las filas, la granularidad, etc.
Echemos un vistazo más de cerca a nuestro modelo table_b. Ya dispone de algunas comprobaciones de datos:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullAquí, bajo la definición tests, comprobamos nuestra condición materializada table_b.id para unique y not_null. Para ejecutar esta prueba específica, funcionará el siguiente comando:
dbt test -s table_bTambién podemos comprobar la integridad referencial de nuestros conjuntos de datos. Esto es esencial cuando se trabaja con modelos de datos con uniones, ya que garantiza que las relaciones entre entidades se mantienen con precisión. Estas pruebas ayudan a definir cómo se relacionan entre sí distintas entidades, como tablas o columnas.
Por ejemplo, considera el siguiente código dbt, que ilustra cómo cada refunds.refund_id está vinculado a un transactions.id válido. Esta asignación garantiza que todos los reembolsos estén vinculados a transacciones legítimas, manteniendo la integridad de tus datos y evitando registros huérfanos o relaciones incoherentes en tus modelos de datos:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idLos requisitos de datos suelen implicar el establecimiento de expectativas sobre cuándo deben estar disponibles los nuevos datos y la especificación del retraso máximo permitido para las actualizaciones. Estas comprobaciones son cruciales para garantizar que los datos siguen siendo relevantes para el análisis (actualizados).
En dbt, esto puede llevarse a cabo utilizando pruebas de frescura, que te permiten controlar si los nuevos datos llegan dentro del plazo previsto.
Por ejemplo, puedes configurar una prueba de frescura para verificar que el registro más reciente de una tabla cumple los criterios de frescura que hayas definido. Esto garantiza que tus canalizaciones de datos proporcionen actualizaciones con prontitud y coherencia, ayudando a mantener la fiabilidad y exactitud de tus datos a la vez que cumples los requisitos de plazos de entrega.
Considera el siguiente fragmento de código. Explica cómo configurar una prueba de frescura en dbt:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1¡Todas estas pruebas dbt son notables y muy útiles en el trabajo diario de los ingenieros de datos! Ayudan a mantener el almacén de datos en buen estado y los conductos de datos coherentes.
Construir una solución de almacén de datos es una tarea compleja que requiere una planificación y organización cuidadosas. dbt, como motor de plantillas, ayuda a hacerlo de forma coherente.
En este artículo, he descrito varias técnicas para organizar las carpetas de transformación de datos dbt con el fin de mejorar la claridad y la colaboración. Al almacenar los archivos SQL en una estructura lógica, creamos un entorno fácil de explorar, incluso para los nuevos en el proyecto.
DBT ofrece una amplia gama de funciones para agilizar aún más el proceso. Por ejemplo, podemos enriquecer nuestras plantillas SQL incorporando trozos de código reutilizables mediante macros, variables y constantes. En mi experiencia, cuando se combina con prácticas de infraestructura como código, esta funcionalidad ayuda a aplicar flujos de trabajo CI/CD adecuados, acelerando significativamente el desarrollo y la implantación.
Si quieres llevar tus conocimientos de dbt al siguiente nivel, considera la posibilidad de realizar el curso Introducción al dbt en DataCamp. Es un recurso excelente que, sin duda, te puede ayudar a empezar con éxito ¡con más práctica!
¡Aprende más sobre dbt e ingeniería de datos con estos cursos!
programa
programa
Curso
blog
Tim Lu
12 min
blog
Javier Canales Luna
15 min
blog
Joleen Bothma
11 min
Tutorial
Joleen Bothma
Tutorial
Joleen Bothma
Tutorial
Oluseye Jeremiah
