programa
Ingeniero de Datos Profesional en Python
40 h
Los contratos de datos son la columna vertebral de la calidad de los datos y la escalabilidad de las soluciones de datos distribuidos. Especifican el formato, el esquema y los protocolos que rigen el intercambio entre las entidades de la base de datos. Estos acuerdos formales eliminan las ambigüedades y las suposiciones no documentadas sobre los datos.
En este artículo, aclararé el concepto de contrato de datos ofreciendo técnicas básicas y avanzadas para facilitar su aplicación efectiva.
Un único contrato de datos delinea los parámetros precisos para el intercambio de datos entre dos modelos. Estos acuerdos formales garantizan que no haya ambigüedades sobre el formato y los esquemas de los datos.
Las definiciones y la validación de los contratos de datos son cruciales para una colaboración eficaz entre equipos.
En pocas palabras, un contrato de datos es un acuerdo formal entre el proceso que cambia el estado original de nuestros datos (productores) y los destinos (consumidores). Es muy parecido a cómo funcionan los contratos comerciales. Representan obligaciones entre proveedores y consumidores de un producto empresarial. Los contratos de datos hacen lo mismo con los productos de datos, es decir, tablas, vistas, modelos de datos, etc.
El objetivo es mitigar las interrupciones en el flujo descendente de datos y hacer que las transformaciones de datos sean estables y fiables.
Los principales componentes de un contrato de datos son el esquema (columnas y formatos), la parte de la capa semántica (medidas, cálculos y restricciones), los acuerdos de nivel de servicio (SLA) y la gobernanza de los datos.
Los beneficios de los contratos de datos incluyen:
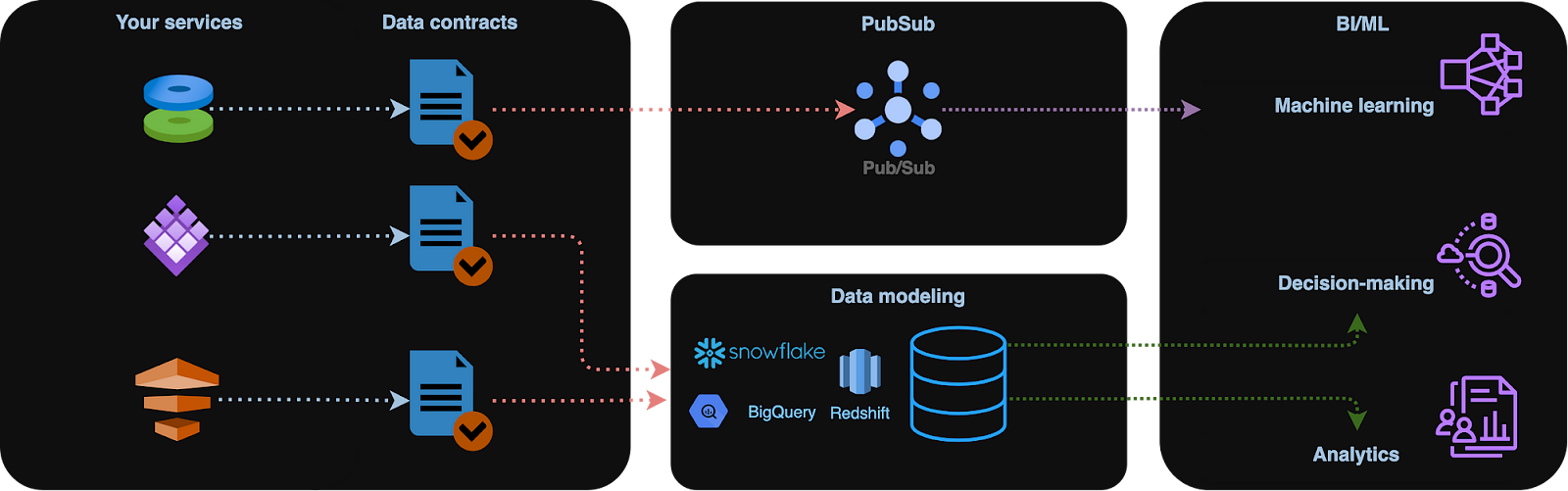
Contratos de datos. Imagen del autor.
En un contrato de datos, los esquemas definen los nombres de los atributos, los tipos de datos y si los atributos son obligatorios. También pueden especificar el formato, la longitud y los rangos de valores aceptables para las columnas.
Consideremos un esquema de modelo dbt definido como sigue en un archivo YAML. Nuestro esquema de tablas está definido en columns:
models:
- name: dim_orders
config:
materialized: table
contract:
enforced: true
columns:
- name: order_id
data_type: int
constraints:
- type: not_null
- name: order_type
data_type: stringAhora imaginemos que definimos así nuestro modelo dim_orders:
select
'abc123' as order_id,
'Some order type' as order_typeTener un contract como enforced: true en nuestra definición del modelo provocará el siguiente error si intentamos materializar dim_orders en una tabla de nuestra plataforma de datos:
20:53:45 Compilation Error in model dim_customers (models/dim_orders.sql)
20:53:45 This model has an enforced contract that failed.
20:53:45 Please ensure the name, data_type, and number of columns in your contract match the columns in your model's definition.
20:53:45
20:53:45 | column_name | definition_type | contract_type | mismatch_reason |
20:53:45 | ----------- | --------------- | ------------- | ------------------ |
20:53:45 | order_id | TEXT | INT | data type mismatch |
20:53:45
20:53:45
20:53:45 > in macro assert_columns_equivalent (macros/materializations/models/table/columns_spec_ddl.sql)Lo mismo habría ocurrido con las columnas adicionales, las comprobaciones de SLA y los metadatos que faltan, si hubiéramos decidido definirlos.
Un ejemplo dbt más avanzado contendría restricciones de modelo forzadas:
# models/schema.yaml
models:
- name: orders
# required
config:
contract:
enforced: true
# model-level constraints
constraints:
- type: primary_key
columns: [id]
- type: FOREIGN_KEY # multi_column
columns: [order_type, SECOND_COLUMN, ...]
expression: "OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_FIRST_COLUMN, OTHER_MODEL_SECOND_COLUMN, ...)"
- type: check
columns: [FIRST_COLUMN, SECOND_COLUMN, ...]
expression: "FIRST_COLUMN != SECOND_COLUMN"
name: HUMAN_FRIENDLY_NAME
- type: ...
columns:
- name: FIRST_COLUMN
data_type: DATA_TYPE
# column-level constraints
constraints:
- type: not_null
- type: unique
- type: foreign_key
expression: OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_COLUMN)
- type: …Proporcionar una definición de esquema como conjunto de reglas y restricciones aplicadas a las columnas de un conjunto de datos ofrece información muy importante para procesar y analizar los datos.
Los esquemas tienden a cambiar con el tiempo.
Se trata de una situación habitual. Imaginemos que nuestra tabla de origen añade una columna extra contraída:
select
'abc123' as order_id,
'Some order type' as order_type,
'USD' as currencyEs esencial tener en cuenta los cambios de esquema al realizar actualizaciones incrementales porque, de lo contrario, la salida del modelo incremental posterior invalidaría el contrato.
Esto puede solucionarse añadiendo on_schema_change: append a la estrategia incremental dbt.
Las validaciones de esquemas pueden ser explícitas o implícitas.
Algunos formatos de archivo de big data, como AVRO y Parquet, admiten por defecto definiciones de esquema incorporadas e implícitas, por lo que no es necesaria una validación externa adicional.
Por el contrario, los formatos de archivo de datos sin esquema, como JSON, requieren una validación externa del esquema. Algunas bibliotecas de Python, como pydantic o una simple @dataclass, pueden realizar esto:
from pydantic import BaseModel
class ConnectionDataRecord(BaseModel):
user: str
ts: int
record = ConnectionDataRecord(user="user1", ts=123456789)Si infringimos las normas y asignamos valores que no se ajustan a nuestros criterios, se lanzará una excepción. Por ejemplo, se producirá una excepción si intentamos llamar a ConnectionDataRecord('', 1).
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso