
Programa
Engenheiro de dados associado em SQL
30 h
Neste artigo, descrevo algumas técnicas que podem ajudar você a aprender dbt e a simplificar a configuração do projeto e a modelagem de dados, tornando o processo geral mais gerenciável.
Além disso, abordarei os padrões específicos de design de projetos dbt que utilizo em meu trabalho diário. Esses métodos se mostraram inestimáveis em meus esforços para criar plataformas de dados e data warehouses precisos, intuitivos, fáceis de navegar e amigáveis.
A aplicação dessas abordagens facilita a criação de plataformas de dados que atendem aos padrões de alta qualidade e minimiza os possíveis problemas, o que acaba resultando em projetos orientados por dados mais bem-sucedidos.
O dbt (Data Build Tool) é uma solução avançada de código aberto projetada especificamente para modelagem de dados, que utiliza modelos SQL e funções ref() (de referência) para estabelecer relações entre várias instâncias de banco de dados, como tabelas, exibições, esquemas e muito mais. Sua flexibilidade é adequada para quem segue o princípio DRY (Do Not Repeat Yourself, não se repita).
Com o dbt, você pode criar um único modelo SQL que pode ser reutilizado e facilmente adaptado a diferentes ambientes de dados. Depois que o modelo é escrito, ele pode ser "compilado" para gerar as consultas SQL necessárias para a execução em cada ambiente específico.
A abordagem seguida pela dbt aumenta a eficiência e garante a consistência em diferentes estágios do pipeline de dados, reduzindo a redundância e os possíveis erros e simplificando o processo de manutenção e dimensionamento da infraestrutura de dados.
A modelagem de dados desempenha um papel central na engenharia de dados, e o dbt é uma excelente ferramenta. Na verdade, eu diria que dominar o dbt é absolutamente essencial para qualquer pessoa que queira se tornar um profissional de dados bem-sucedido!
Considere o modelo de dbt abaixo. É uma definição de tabela simples, mas contém metadados que informam ao usuário qual banco de dados e esquema usar:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Vamos imaginar que no downstream, no pipeline de dados, temos uma visualização que sai da tabela (table_a.sql) que criamos acima. Portanto, nossa linhagem de pipeline de dados seria assim:

Exemplo de linhagem de pipeline de dados. Imagem do autor.
Usaremos a função ref() para conectar dois estágios do nosso pipeline e, no nosso caso, table_b.sql pode ser definido da seguinte forma:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1A função ref() informa que o modelo table_b vai atrás do table_a (downstream). Agora podemos executar o pipeline como um todo usando apenas um comando dbt: dbt run --select tag:example.
Devido aos seus recursos de código reutilizável, o dbt oferece recursos que o tornam uma excelente ferramenta para gerenciar e otimizar fluxos de trabalho de dados em vários ambientes de dados (produção, desenvolvimento, teste, etc.).
Além disso, um de seus principais recursos é gerar automaticamente uma documentação SQL abrangenteo que melhora significativamente a transparência e facilita a compreensão dos modelos de dados pelos desenvolvedores de dados e pelas partes interessadas nos negócios.
Um dos desafios enfrentados na área de modelagem de dados é a criação de pipelines de transformação SQL complexos que envolvem várias camadas e, ao mesmo tempo, tornam seu código reutilizável. Esses pipelines exigem uma reflexão cuidadosa e testes meticulosos para garantir que funcionem com eficiência e mantenham a transparência organizacional para que todos possam entender a lógica.
Além disso, o dbt oferece suporte a testes de qualidade de dados e testes unitários para lógica SQL, permitindo que você valide a precisão e a confiabilidade de suas transformações de forma estruturada e automatizada(fluxos de trabalho CI/CD).
Outro recurso importante é sua automação flexível usando macrosque permitem trechos de código personalizáveis e reutilizáveis, simplificando tarefas complexas e aumentando a produtividade.
Essas funcionalidades combinadas tornam o dbt a solução ideal para lidar com qualquer tarefa relacionada a SQL e ambientes de dados, desde a garantia da integridade dos dados até a automação de processos repetitivos, tudo isso mantendo a eficiência e o dimensionamento.
Vamos colocar a mão na massa e executar alguns exemplos com o dbt e o BigQuery como uma plataforma de dados!
Para este tutorial, usaremos o Google Cloud BigQuery como uma solução de data warehouse. Seu nível gratuito o torna um candidato perfeito para o aprendizado. Você pode ativar o BigQuery em sua conta do Google Cloud.
Instalaremos o dbt localmente usando o Python e o pip manager, criaremos um ambiente virtual e começaremos a executar modelos e testes de amostra.
Execute os seguintes comandos em sua linha de comando:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtNosso site requirements.txt deve conter as seguintes dependências:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Então, no restante do tutorial, faremos o seguinte:
Vamos criar credenciais de conta de serviço para nosso aplicativo dbt:
Criando uma conta de serviço para o BigQuery no Google Cloud. Imagem do autor.
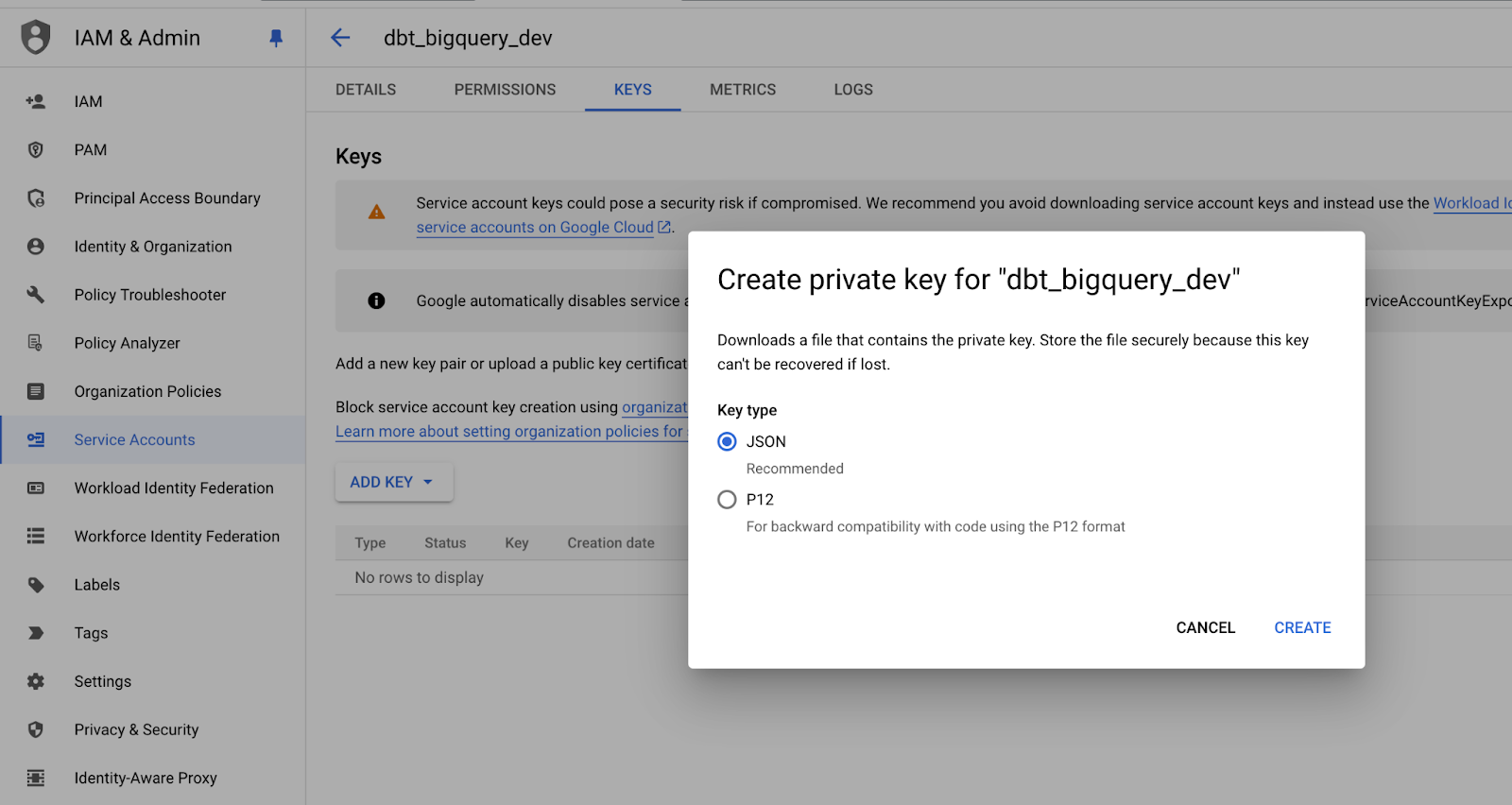
Salvando a chave privada da conta de serviço no formato JSON. Imagem do autor.
dbt init em um terminal para finalmente inicializar nosso projeto dbt. Após concluir a configuração, você deverá receber uma mensagem como esta:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.E a estrutura de pastas deve ser semelhante a esta:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtPodemos ver que o site profiles.yml foi criado na pasta raiz do computador local, mas, idealmente, gostaríamos que ele estivesse na pasta do aplicativo, portanto, vamos movê-lo.
cd my_dbt
touch profiles.ymlPor fim, vamos ajustar o conteúdo do site profiles.yml para refletir o nome do nosso projeto e incluir as credenciais da conta de serviço do Google:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comÉ isso aí! Estamos prontos para compilar nosso projeto.
export DBT_PROFILES_DIR='.'
dbt compileO resultado deve ser algo parecido com isto:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')Nossa configuração inicial do projeto está concluída.
Queremos projetar nosso projeto de dbt de forma conveniente e transparente para refletir claramente a arquitetura do data warehouse.
Recomendo que você use modelos e macros em seu projeto dbt e incorpore nomes de bancos de dados personalizados para separar efetivamente seus ambientes de dados em produção, desenvolvimento e teste.
Essa abordagem melhora a organização e minimiza o risco de modificações acidentais no ambiente errado, aprimorando o gerenciamento geral de dados e a estabilidade do fluxo de trabalho. Com isso, podemos gerenciar e manter facilmente esses ambientes, o que ajuda a garantir que os dados de produção permaneçam seguros e intocados por alterações experimentais ou de teste.
Os bancos de dados em diferentes ambientes também podem ser nomeados de forma estruturada e consistente usando sufixos relevantes (_prod, _dev, _test), facilitando a diferenciação entre ambientes e permitindo transições e implementações mais suaves.

As diferentes camadas do data warehouse em um ambiente de produção. Imagem do autor.
Por exemplo, podemos mover as principais camadas do modelo de dados para a convenção de nomenclatura do banco de dados usando os prefixos raw_ e base_ na nomenclatura do banco de dados:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsPara injetar esses nomes de bancos de dados personalizados dinamicamente, você só precisa criar uma macro dbt que lide com essa tarefa automaticamente. Ao aproveitar essa abordagem, você pode garantir que os nomes corretos de bancos de dados sejam usados no ambiente de dados apropriado sem editar manualmente as configurações todas as vezes.
Vejamos o trecho de código abaixo, que contém uma macro para definir esquemas diferentes, dependendo do ambiente em que você está:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Agora, sempre que compilarmos nossos modelos, o dbt aplicará automaticamente o nome do banco de dados personalizado com base na configuração especificada na configuração de cada modelo. Isso significa que o nome correto do banco de dados será injetado durante o processo de compilação, garantindo que os modelos estejam alinhados com o ambiente apropriado - produção, desenvolvimento ou teste.
Ao incorporar esse recurso, eliminamos a necessidade de alterações manuais nos nomes do banco de dados, aumentando ainda mais a eficiência e a precisão do nosso fluxo de trabalho.
Essas configurações necessárias podem ser definidas em properties.yml para nossos modelos:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullComo você pode ver, podemos usar instruções condicionais básicas para introduzir lógica nos arquivos de configuração, graças ao suporte do dbt ao Jinja.
Não é possível usar macros nesse contexto, mas você pode usar condicionais simples usando expressões Jinja nos arquivos .yml. Elas precisam ser colocadas entre aspas. Isso garante que a linguagem de modelo seja interpretada corretamente durante a execução.
Vamos executar um comando dbt compile e ver o que acontece:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1O dbt oferece suporte a variáveis, que são um recurso de personalização muito avançado. As variáveis podem ser usadas tanto em modelos SQL quanto em macros e podem ser fornecidas pela linha de comando da seguinte forma:
dbt run -m table_b -t dev --vars '{my_var: my_value}'As variáveis devem ser declaradas no arquivo principal do projeto dbt_project.yml. Por exemplo, o snippet abaixo demonstra como você pode fazer isso:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Vamos usar variáveis para criar nomes de tabela personalizados (nomes de alias) no dbt.
Se nenhum alias estiver presente, o nome original do modelo (nome do arquivo) será usado como alias por padrão. Essa lógica simples garante que os modelos sejam referenciados por seu alias configurado ou por seu nome padrão, dependendo da configuração. A implementação dessa funcionalidade é parecida com a seguinte, garantindo flexibilidade na forma como os modelos são nomeados e referenciados nos ambientes:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Vamos substituir esse comportamento usando variáveis. Essa é uma configuração comum para que os desenvolvedores de dados reduzam os riscos de pisar nos pés uns dos outros enquanto trabalham na preparação (desenvolvimento).
Queremos adicionar o nome do desenvolvedor a todas as instâncias do banco de dados (tabelas, exibições, etc.) criadas pelos engenheiros de desenvolvimento.
Vamos criar uma macro generate_alias_name.sql:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}Não se esqueça de adicionar nossa nova variável a dbt_project.yml e executar isso em sua linha de comando:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Você deverá ver um resultado como este:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1Podemos ver que nossa variável foi adicionada a um nome de tabela: table_a_mike.
Esta seção trata de como projetamos nosso data warehouse em termos de transformação de dados. Uma estrutura de projeto lógica simplificada no dbt pode ser parecida com esta abaixo:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlPessoalmente, sempre tento me concentrar em manter a camada do modelo de dados fundamental (base) o mais limpa e direta possível, garantindo que as transformações de dados sejam aplicadas somente quando necessário. Com essa abordagem, nosso objetivo é projetar e implementar uma camada de modelo de dados base_ que envolva manipulação mínima de dados no nível da coluna.
No entanto, há casos em que algum nível de manipulação pode ser benéfico, especialmente quando se trata de otimizar o desempenho da consulta. Nesses casos, pequenos ajustes na camada de base podem melhorar significativamente a eficiência, fazendo com que valha a pena equilibrar a simplicidade e os ganhos de desempenho. Nesse caso, seria justificável adicionar um filtro extra de junção ou particionamento.
Uma prática recomendada é implementar as seguintes técnicas para aprimorar seus modelos de dados e pipelines:
biz_ e mart_. Isso pode ajudar a melhorar o desempenho e garantir que a lógica comercial seja gerenciada com eficiência.select * e considere a possibilidade de dividir arquivos SQL longos e complexos em modelos menores com testes unitários.Considere a consulta SQL abaixo. Ele explica como você pode criar essa materialização personalizada:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Agora, se adicionarmos um modelo extra chamado table_c para demonstrar esse recurso, poderemos usar o SQL abaixo:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Agora, se o compilarmos, ele deverá se parecer com um script SQL:
$ dbt compile -m table_c -t devO resultado:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;A vantagem dessa abordagem é que não precisamos mais depender do adaptador BigQuery. Se criarmos outra tabela ou visualização que faça referência a essa operação, você poderá simplesmente usar a função padrão ref().
Ao fazer isso, o site table_c será automaticamente reconhecido como uma dependência na linhagem de dados. Isso facilita o rastreamento de como as tabelas estão relacionadas e garante que os relacionamentos entre diferentes modelos sejam documentados adequadamente em seu ambiente de dados.
Esse método ajuda a gerenciar dependências e oferece uma visão clara de como os dados fluem por vários estágios, incluindo etapas complexas de processamento de dados que envolvem scripts. Isso é especialmente útil para manter pipelines de dados complexos.
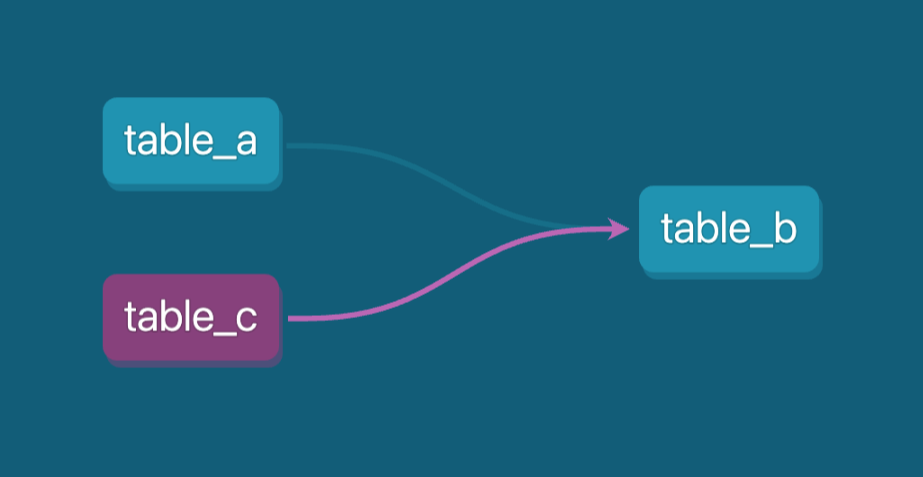
O DAG (gráfico acíclico direcionado) no dbt mostra as dependências para table_b. Imagem do autor
Agora, só precisamos adicionar table_c ao nosso pipeline:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;A documentação será gerada automaticamente se você executar o seguinte em nossa linha de comando!
dbt docs generate
dbt docs serveUm exemplo mais avançado de um projeto de armazenamento de dados em dbt pode se parecer com a estrutura abaixo. Ele contém várias fontes de dados e transformações por meio de várias camadas de modelos (stg, base, mrt, biz) para finalmente produzir modelos de data mart.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlO teste de unidade é uma etapa crucial no processo de pipeline de dados, em que podemos executar testes para validar a lógica por trás de nossos modelos de dados. Assim como você realizaria testes unitários para suas funções Python para garantir que elas se comportem conforme o esperado, aplico uma abordagem semelhante para testar modelos de dados.
Ao executar esses testes, podemos detectar possíveis problemas antecipadamente e garantir que as transformações e a lógica estejam funcionando corretamente. Essa prática ajuda a manter a qualidade dos dados e evita que os erros se propaguem pelo pipeline, tornando-a um aspecto vital do processo de engenharia de dados.
Você pode adicionar um teste de unidade para um modelo simplesmente modificando o arquivo properties.yml:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Agora, se executarmos o comando dbt test em nossa linha de comando, poderemos executar os testes de unidade:
% dbt test --select "table_b,test_type:unit"Este é o resultado:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Tente alterar a linha id em expect para 3, e você receberá um erro para o mesmo teste:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsO dbt também oferece suporte para verificações de qualidade de dados. Escrevi anteriormente sobre isso na seção contratos de dados do blog. Podemos verificar quase tudo o que é relevante para a qualidade dos dados, ou seja, o frescor dos dados, as condições das linhas, a granularidade etc.
Vamos dar uma olhada mais de perto em nosso modelo table_b. Você já tem algumas verificações de dados em vigor:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullAqui, na definição tests, testamos nosso table_b.id materializado para as condições unique e not_null. Para executar esse teste específico, o comando a seguir funcionará:
dbt test -s table_bTambém podemos testar a integridade referencial de nossos conjuntos de dados. Isso é essencial ao trabalhar com modelos de dados com uniões, pois garante que os relacionamentos entre as entidades sejam mantidos com precisão. Esses testes ajudam a definir como diferentes entidades, como tabelas ou colunas, se relacionam entre si.
Por exemplo, considere o código dbt abaixo, que ilustra como cada refunds.refund_id está vinculado a um transactions.id válido. Esse mapeamento garante que todos os reembolsos estejam vinculados a transações legítimas, mantendo a integridade dos seus dados e evitando registros órfãos ou relacionamentos inconsistentes nos seus modelos de dados:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idOs requisitos de dados geralmente envolvem a definição de expectativas sobre quando novos dados devem estar disponíveis e a especificação do atraso máximo permitido para atualizações. Essas verificações são essenciais para garantir que os dados permaneçam relevantes para a análise (atualizados).
No dbt, isso pode ser implementado com a utilização de testes de atualização, que permitem que você monitore se os novos dados chegam dentro do período de tempo esperado.
Por exemplo, você pode configurar um teste de atualização para verificar se o registro mais recente em uma tabela atende aos critérios definidos para atualização. Isso garante que seus pipelines de dados forneçam atualizações de forma rápida e consistente, ajudando a manter a confiabilidade e a precisão dos seus dados e, ao mesmo tempo, atendendo a requisitos urgentes.
Considere o trecho de código abaixo. Ele explica como você pode configurar um teste de atualização no dbt:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1Todos esses testes dbt são notáveis e muito úteis no trabalho diário dos engenheiros de dados! Eles ajudam a manter o data warehouse bem conservado e os pipelines de dados consistentes.
A criação de uma solução de data warehouse é uma tarefa complexa que exige planejamento e organização cuidadosos. O dbt, como mecanismo de modelagem, ajuda você a fazer isso de forma consistente.
Neste artigo, descrevi várias técnicas para organizar pastas de transformação de dados dbt para aumentar a clareza e a colaboração. Ao armazenar os arquivos SQL em uma estrutura lógica, criamos um ambiente que é fácil de explorar, mesmo para os novatos no projeto.
O DBT oferece uma ampla gama de recursos para agilizar ainda mais o processo. Por exemplo, podemos enriquecer nossos modelos SQL incorporando partes reutilizáveis de código por meio de macros, variáveis e constantes. Em minha experiência, quando combinada com práticas de infraestrutura como código, essa funcionalidade ajuda a aplicar fluxos de trabalho de CI/CD adequados, acelerando significativamente o desenvolvimento e a implementação.
Se você quiser levar seu conhecimento sobre dbt para o próximo nível, considere fazer o curso Introduction to dbt no DataCamp. É um excelente recurso que certamente pode fazer com que você comece a praticar com mais sucesso!
Saiba mais sobre dbt e engenharia de dados com estes cursos!
Programa
Programa
Curso
blog
Tim Lu
12 min
blog
Kurtis Pykes
11 min
blog
Joleen Bothma
11 min
blog
Javier Canales Luna
15 min
blog
Kurtis Pykes
7 min
Tutorial
Kurtis Pykes


