
Cursus
Ingénieur de données associé en SQL
30 h
Dans cet article, je présente quelques techniques qui peuvent aider à apprendre le dbt et à rationaliser la configuration du projet et la modélisation des données, rendant ainsi le processus global plus gérable.
En outre, j'aborderai les modèles de conception spécifiques au projet dbt sur lesquels je m'appuie dans mon travail quotidien. Ces méthodes se sont révélées inestimables dans mes efforts pour créer des plateformes et des entrepôts de données précis, intuitifs, faciles à naviguer et conviviaux.
L'application de ces approches facilite la création de plateformes de données répondant à des normes de haute qualité tout en minimisant les problèmes potentiels, ce qui se traduit en fin de compte par des projets axés sur les données plus fructueux.
dbt (Data Build Tool) est une puissante solution open-source conçue spécifiquement pour la modélisation des données, qui exploite les modèles SQL et les fonctions ref() (référencement) pour établir des relations entre diverses instances de base de données telles que les tableaux, les vues, les schémas, etc. Sa flexibilité convient à ceux qui suivent le principe DRY (Do Not Repeat Yourself).
Avec dbt, vous pouvez créer un modèle SQL unique qui peut être réutilisé et facilement adapté à différents environnements de données. Une fois le modèle écrit, il peut être "compilé" pour générer les requêtes SQL nécessaires à l'exécution dans chaque environnement spécifique.
L'approche suivie par dbt améliore l'efficacité et garantit la cohérence entre les différentes étapes du pipeline de données, réduisant ainsi la redondance et les erreurs potentielles tout en simplifiant le processus de maintenance et d'évolution de l'infrastructure de données.
La modélisation des données joue un rôle central dans l'ingénierie des données, et dbt est un excellent outil. En fait, je dirais que la maîtrise de dbt est absolument essentielle pour quiconque aspire à devenir un professionnel de l'information !
Examinez le modèle dbt ci-dessous. Il s'agit d'une simple définition de tableau, mais elle comporte des métadonnées indiquant à l'utilisateur la base de données et le schéma à utiliser :
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Imaginons qu'en aval, dans le pipeline de données, nous ayons une vue issue du tableau (table_a.sql) que nous avons créé ci-dessus. Ainsi, notre pipeline de données se présenterait comme suit :

Exemple de pipeline de données. Image par l'auteur.
Nous utiliserons la fonction ref() pour relier deux étapes de notre pipeline et, dans notre cas, table_b.sql peut être défini comme suit :
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1La fonction ref() indique que le modèle table_b suit le modèle table_a (en aval). Nous pouvons maintenant exécuter l'ensemble du pipeline en utilisant une seule commande dbt : dbt run --select tag:example.
Grâce à ses capacités de réutilisation du code, dbt offre des caractéristiques qui en font un excellent outil pour la gestion et l'optimisation des flux de données dans divers environnements de données (production, développement, tests, etc.). (production, développement, tests, etc.).
En outre, l'une de ses principales fonctionnalités consiste à la génération automatique d'une documentation SQL complètece qui améliore considérablement la transparence et facilite la compréhension des modèles de données pour les développeurs de données et les parties prenantes de l'entreprise.
L'un des défis rencontrés dans le domaine de la modélisation des données est la construction de pipelines de transformation SQL complexes qui impliquent plusieurs couches tout en rendant votre code réutilisable. Ces pipelines nécessitent une réflexion approfondie et des tests méticuleux pour garantir leur fonctionnement efficace et maintenir la transparence organisationnelle afin que tout le monde puisse comprendre la logique. dbt peut également vous aider à cet égard.
En outre, dbt prend en charge les tests de qualité des données et les tests unitaires pour la logique SQL, ce qui vous permet de valider l'exactitude et la fiabilité de vos transformations de manière structurée et automatisée(flux de travail CI/CD).
Une autre caractéristique clé est son l'automatisation flexible à l'aide de macrosqui permettent de personnaliser et de réutiliser des extraits de code, de rationaliser les tâches complexes et d'améliorer la productivité.
Ces fonctionnalités combinées font de dbt une solution idéale pour gérer toutes les tâches et environnements de données liés à SQL, qu'il s'agisse de garantir l'intégrité des données ou d'automatiser des processus répétitifs, tout en maintenant l'efficacité et l'évolutivité.
Mettons-nous au travail et exécutons quelques exemples avec dbt et BigQuery comme plateforme de données !
Pour ce tutoriel, nous utiliserons Google Cloud BigQuery comme solution d'entrepôt de données. Sa gratuité en fait un candidat idéal pour l'apprentissage. Vous pouvez activer BigQuery dans votre compte Google Cloud.
Nous installerons dbt localement à l'aide de Python et du gestionnaire pip, nous créerons un environnement virtuel et nous commencerons à exécuter des modèles et des tests types.
Exécutez les commandes suivantes dans votre ligne de commande :
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtNotre site requirements.txt doit contenir les dépendances suivantes :
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Ensuite, pour le reste du tutoriel, nous ferons ce qui suit :
Créons les informations d'identification du compte de service pour notre application dbt :
Création d'un compte de service pour BigQuery dans Google Cloud. Image par l'auteur.
Enregistrement de la clé privée du compte de service au format JSON. Image par l'auteur.
dbt init dans un terminal pour initialiser notre projet dbt. Une fois la configuration terminée, vous devriez obtenir un message comme celui-ci :
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.La structure du dossier doit ressembler à ceci :
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtNous pouvons voir que profiles.yml a été créé dans le dossier racine de notre machine locale, mais idéalement, nous voudrions qu'il soit dans notre dossier d'application, alors déplaçons-le.
cd my_dbt
touch profiles.ymlEnfin, ajustons le contenu du site profiles.yml pour refléter le nom de notre projet et inclure les informations d'identification du compte de service Google :
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comC'est tout ! Nous sommes prêts à compiler notre projet.
export DBT_PROFILES_DIR='.'
dbt compileLe résultat devrait ressembler à ceci :
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')La configuration initiale de notre projet est terminée.
Nous voulons concevoir notre projet dbt de manière pratique et transparente afin de refléter clairement l'architecture de l'entrepôt de données.
Je vous recommande d'utiliser des modèles et des macros dans votre projet dbt et d'incorporer des noms de base de données personnalisés pour séparer efficacement vos environnements de données en production, développement et test.
Cette approche améliore l'organisation et minimise le risque de modifications accidentelles dans le mauvais environnement, améliorant ainsi la gestion globale des données et la stabilité du flux de travail. Ainsi, nous pouvons facilement gérer et maintenir ces environnements, ce qui permet de garantir que les données de production restent sécurisées et ne sont pas affectées par des changements expérimentaux ou de test.
Les bases de données des différents environnements peuvent également être nommées de manière structurée et cohérente à l'aide de suffixes appropriés (_prod, _dev, _test), ce qui permet de différencier plus facilement les environnements tout en facilitant les transitions et les déploiements.

Les différentes couches de l'entrepôt de données dans un environnement de production. Image par l'auteur.
Par exemple, nous pouvons déplacer les principales couches du modèle de données vers la convention de dénomination de la base de données en utilisant les préfixes raw_ et base_ dans la dénomination de la base de données :
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsPour injecter dynamiquement ces noms de base de données personnalisés, il vous suffit de créer une macro dbt qui se charge automatiquement de cette tâche. Grâce à cette approche, vous pouvez vous assurer que les noms de base de données corrects sont utilisés dans l'environnement de données approprié sans avoir à modifier manuellement les configurations à chaque fois.
Voyons l'extrait de code ci-dessous, qui contient une macro permettant de définir des schémas différents en fonction de l'environnement dans lequel nous nous trouvons :
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Désormais, lorsque nous compilerons nos modèles, dbt appliquera automatiquement le nom de la base de données personnalisée en fonction de la configuration spécifiée dans l'installation de chaque modèle. Cela signifie que le nom correct de la base de données sera injecté au cours du processus de compilation, garantissant que les modèles sont alignés sur l'environnement approprié - production, développement ou test.
En intégrant cette fonctionnalité, nous éliminons la nécessité de modifier manuellement les noms de la base de données, ce qui améliore encore l'efficacité et la précision de notre flux de travail.
Ces configurations requises peuvent être définies dans properties.yml pour nos modèles :
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullComme vous pouvez le constater, nous pouvons utiliser des instructions conditionnelles de base pour introduire de la logique dans les fichiers de configuration, grâce à la prise en charge de Jinja par dbt.
Les macros ne peuvent pas être utilisées dans ce contexte, mais nous pouvons utiliser des conditionnelles simples à l'aide d'expressions Jinja dans les fichiers .yml. Ils doivent être mis entre guillemets. Cela permet de s'assurer que le langage de modélisation est correctement interprété lors de l'exécution.
Exécutons la commande dbt compile et voyons ce qui se passe :
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt prend en charge les variables, qui constituent une fonction de personnalisation très puissante. Les variables peuvent être utilisées à la fois dans les modèles SQL et les macros et peuvent être fournies à partir de la ligne de commande de la manière suivante :
dbt run -m table_b -t dev --vars '{my_var: my_value}'Les variables doivent être déclarées dans le fichier principal du projet dbt_project.yml. Par exemple, l'extrait ci-dessous montre comment procéder :
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Utilisons des variables pour créer des noms de tableaux personnalisés (noms d'alias) dans dbt.
Si aucun alias n'est présent, le nom original du modèle (nom de fichier) est utilisé par défaut comme alias. Cette logique simple garantit que les modèles sont référencés soit par leur alias configuré, soit par leur nom par défaut, en fonction de la configuration. La mise en œuvre de cette fonctionnalité ressemble à ce qui suit, garantissant la flexibilité dans la manière dont les modèles sont nommés et référencés dans les différents environnements :
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Remplaçons ce comportement par des variables. Il s'agit d'une configuration courante pour les développeurs de données afin d'atténuer les risques de se marcher sur les pieds pendant qu'ils travaillent sur la mise en scène (développement).
Nous voulons ajouter le nom du développeur à toutes les instances de base de données (tableaux, vues, etc.) créées par les ingénieurs de développement.
Réalisons une macro generate_alias_name.sql:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}N'oubliez pas d'ajouter notre nouvelle variable à dbt_project.yml et de l'exécuter dans votre ligne de commande :
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Vous devriez obtenir un résultat comme celui-ci :
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1Nous pouvons voir que notre variable a été ajoutée à un tableau nommé : table_a_mike.
Cette section traite de la manière dont nous concevons notre entrepôt de données en termes de transformation des données. Une structure de projet logique simplifiée en dbt peut ressembler à la structure ci-dessous :
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlPersonnellement, j'essaie toujours de me concentrer sur le maintien d'une couche de modèle de données (de base) aussi propre et directe que possible, en veillant à ce que les transformations de données ne soient appliquées que lorsque c'est nécessaire. En utilisant cette approche, nous visons à concevoir et à mettre en œuvre une couche de modèle de données base_ qui implique une manipulation minimale des données au niveau des colonnes.
Cependant, il existe des cas où un certain niveau de manipulation peut être bénéfique, en particulier lorsqu'il s'agit d'optimiser les performances des requêtes. Dans de tels cas, des ajustements mineurs au niveau de la couche de base peuvent améliorer de manière significative l'efficacité, d'où l'intérêt de trouver un équilibre entre la simplicité et les gains de performance. Dans ce cas, l'ajout d'une jointure supplémentaire ou d'un filtre de partitionnement serait justifié.
Il est recommandé de mettre en œuvre les techniques suivantes pour améliorer vos modèles de données et vos pipelines :
biz_ et mart_. Cela peut contribuer à améliorer les performances et à garantir une gestion efficace de la logique d'entreprise.select * et envisagez de diviser les fichiers SQL longs et complexes en modèles plus petits avec des tests unitaires.Considérez la requête SQL ci-dessous. Il explique comment créer une telle matérialisation personnalisée :
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Maintenant, si nous ajoutons un modèle supplémentaire appelé table_c pour démontrer cette fonctionnalité, nous pouvons utiliser le code SQL ci-dessous :
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Maintenant, si nous le compilons, il devrait ressembler à un script SQL :
$ dbt compile -m table_c -t devLe résultat :
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;L'avantage de cette approche est que nous n'avons plus besoin de nous appuyer sur l'adaptateur BigQuery. Si nous créons un autre tableau ou une autre vue qui fait référence à cette opération, nous pouvons simplement utiliser la fonction standard ref().
Ce faisant, table_c sera automatiquement reconnu comme une dépendance dans la lignée des données. Cela facilite le cursus des relations entre les tableaux et garantit que les relations entre les différents modèles sont correctement documentées dans votre environnement de données.
Cette méthode facilite la gestion des dépendances et offre une vision claire de la manière dont les données passent par les différentes étapes, y compris les étapes complexes de traitement des données impliquant des scripts. Ceci est particulièrement utile pour gérer des pipelines de données complexes.
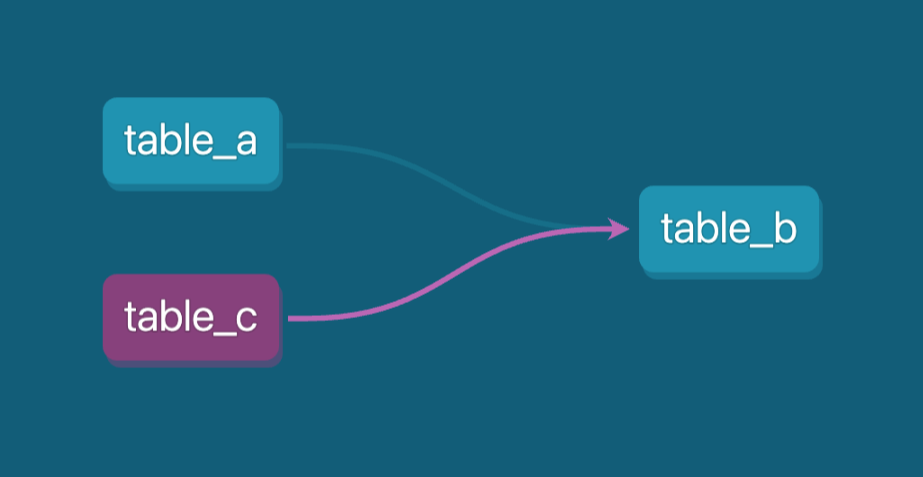
Le DAG (directed acyclic graph) dans dbt montre les dépendances pour table_b. Image par l'auteur
Il ne nous reste plus qu'à ajouter table_c à notre pipeline :
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;La documentation sera générée automatiquement si nous exécutons la commande suivante dans notre ligne de commande !
dbt docs generate
dbt docs serveUn exemple plus avancé de projet d'entreposage de données dans dbt peut ressembler à la structure ci-dessous. Il contient de multiples sources de données et des transformations à travers différentes couches de modèles (stg, base, mrt, biz) pour finalement produire des modèles de martingales de données.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlLes tests unitaires constituent une étape cruciale dans le processus d'élaboration du pipeline de données, où nous pouvons exécuter des tests pour valider la logique qui sous-tend nos modèles de données. De la même manière que vous effectueriez des tests unitaires pour vos fonctions Python afin de vous assurer qu'elles se comportent comme prévu, j'applique une approche similaire pour tester les modèles de données.
L'exécution de ces tests permet de détecter rapidement les problèmes potentiels et de s'assurer que les transformations et la logique fonctionnent correctement. Cette pratique permet de maintenir la qualité des données et d'empêcher les erreurs de se propager dans le pipeline, ce qui en fait un aspect essentiel du processus d'ingénierie des données.
Nous pouvons ajouter un test unitaire pour un modèle en modifiant simplement le fichier properties.yml:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Maintenant, si nous lançons la commande dbt test dans notre ligne de commande, nous pouvons exécuter les tests unitaires :
% dbt test --select "table_b,test_type:unit"Voici le résultat :
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Essayez de remplacer la ligne id dans expect par 3, et vous obtiendrez une erreur pour le même test :
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt offre également un soutien pour les contrôles de qualité des données. J'ai déjà écrit à ce sujet dans la rubrique contrats de données sur le blog. Nous pouvons vérifier presque tout ce qui concerne la qualité des données, c'est-à-dire la fraîcheur des données, l'état des lignes, la granularité, etc.
Examinons de plus près notre modèle table_b. Il y a déjà des contrôles de données en place :
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullIci, dans le cadre de la définition tests, nous testons notre site matérialisé table_b.id pour les conditions unique et not_null. Pour exécuter ce test spécifique, la commande suivante fonctionnera :
dbt test -s table_bNous pouvons également tester l'intégrité référentielle de nos ensembles de données. Ceci est essentiel lorsque vous travaillez avec des modèles de données comportant des jointures, car cela garantit que les relations entre les entités sont correctement maintenues. Ces tests permettent de définir comment différentes entités, telles que des tableaux ou des colonnes, sont liées les unes aux autres.
Par exemple, considérez le code dbt ci-dessous, qui illustre comment chaque refunds.refund_id est lié à un transactions.id valide. Ce mappage garantit que tous les remboursements sont liés à des transactions légitimes, préservant ainsi l'intégrité de vos données et évitant les enregistrements orphelins ou les relations incohérentes dans vos modèles de données :
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idLes exigences en matière de données impliquent souvent de fixer des attentes quant au moment où les nouvelles données doivent être disponibles et de spécifier le délai maximum autorisé pour les mises à jour. Ces contrôles sont essentiels pour garantir que les données restent pertinentes pour l'analyse (à jour).
Dans dbt, cela peut être mis en œuvre en utilisant des tests de fraîcheur, qui vous permettent de contrôler si les nouvelles données arrivent dans les délais prévus.
Par exemple, vous pouvez configurer un test de fraîcheur pour vérifier que l'enregistrement le plus récent d'un tableau répond aux critères de fraîcheur que vous avez définis. Cela garantit que vos pipelines de données fournissent des mises à jour rapides et cohérentes, contribuant ainsi à maintenir la fiabilité et l'exactitude de vos données tout en respectant les exigences en matière de délais.
Examinez l'extrait de code ci-dessous. Il explique comment mettre en place un test de fraîcheur dans dbt :
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1Tous ces tests dbt sont remarquables et très utiles dans le travail quotidien des ingénieurs de données ! Ils contribuent à la bonne maintenance de l'entrepôt de données et à la cohérence des pipelines de données.
Construire une solution d'entrepôt de données est une tâche complexe qui nécessite une planification et une organisation minutieuses. dbt, en tant que moteur de modélisation, vous aide à le faire de manière cohérente.
Dans cet article, j'ai présenté plusieurs techniques pour organiser les dossiers de transformation des données dbt afin d'améliorer la clarté et la collaboration. En stockant les fichiers SQL dans une structure logique, nous créons un environnement facile à explorer, même pour les nouveaux venus dans le projet.
DBT offre un large éventail de fonctionnalités permettant de rationaliser davantage le processus. Par exemple, nous pouvons enrichir nos modèles SQL en incorporant des éléments de code réutilisables par le biais de macros, de variables et de constantes. D'après mon expérience, lorsqu'elle est associée à des pratiques d'infrastructure en tant que code, cette fonctionnalité permet de mettre en œuvre des flux de travail CI/CD appropriés, ce qui accélère considérablement le développement et le déploiement.
Si vous souhaitez approfondir vos connaissances en matière de dbt, vous pouvez suivre le cours d'introduction à la dbt sur DataCamp. Il s'agit d'une excellente ressource qui peut certainement vous aider à démarrer avec succès avec plus de pratique !
Apprenez-en plus sur le dbt et l'ingénierie des données avec ces cours !
Cursus
Cursus
Cours
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Sejal Jaiswal
Tutoriel
Samuel Shaibu
Tutoriel
Satyabrata Pal
