
Track
Associate Data Engineer in SQL
30 hr
In this article, I outline some techniques that can help learn dbt and streamline the project setup and data modeling, making the overall process more manageable.
Additionally, I will get into the specific dbt project design patterns I rely on in my day-to-day work. These methods have proven invaluable in my efforts to build data platforms and data warehouses that are accurate, intuitive, easy to navigate, and user-friendly.
Applying these approaches makes creating data platforms that meet high-quality standards easier while minimizing potential issues, ultimately leading to more successful data-driven projects.
dbt (Data Build Tool) is a powerful open-source solution designed specifically for data modeling, leveraging SQL templates and ref() (referencing) functions to establish relationships between various database instances like tables, views, schemas, and more. Its flexibility suits those following the DRY (Do Not Repeat Yourself) principle.
With dbt, you can create a single SQL template that can be reused and easily adapted to different data environments. Once the template is written, it can be "compiled" to generate the SQL queries necessary for execution in each specific environment.
The approach dbt follows improves efficiency and ensures consistency across different data pipeline stages, reducing redundancy and potential errors while simplifying the process of maintaining and scaling the data infrastructure.
Data modeling plays a central role in data engineering, and dbt is an excellent tool. In fact, I would argue that mastering dbt is absolutely essential for anyone aspiring to become a successful data professional!
Consider the dbt template below. It is a simple table definition, but it carries metadata on board telling the user which database and schema to use:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Let's imagine that downstream, in the data pipeline, we have a view that comes out of the table (table_a.sql) we created above. So, our data pipeline lineage would look like this:

Example data pipeline lineage. Image by Author.
We will use the ref() function to connect two stages of our pipeline, and in our case, table_b.sql can be defined like so:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1The ref() function tells that table_b model goes after the table_a (downstream). Now we can run the pipeline as a whole using just one dbt command: dbt run --select tag:example.
Because of its reusable code capabilities, dbt provides features that make it an excellent tool for managing and optimizing data workflows in various data environments (production, development, testing, etc.).
Additionally, one of its core capabilities is automatically generating comprehensive SQL documentation, which significantly improves transparency and makes understanding data models easier for data developers and business stakeholders.
One of the challenges faced in the data modeling area is building complex SQL transformation pipelines that involve multiple layers while making your code reusable. These pipelines require careful thought and meticulous testing to ensure they function efficiently and maintain organizational transparency so everyone can understand the logic. dbt can also help in this regard.
Additionally, dbt supports data quality tests and unit tests for SQL logic, enabling you to validate the accuracy and reliability of your transformations in a structured and automated manner (CI/CD workflows).
Another key feature is its flexible automation using macros, which allow for customizable and reusable code snippets, streamlining complex tasks and enhancing productivity.
These combined functionalities make dbt an ideal solution for handling any SQL-related task and data environments, from ensuring data integrity to automating repetitive processes, all while maintaining efficiency and scalability.
Let’s get hands-on and execute some examples with dbt and BigQuery as a data platform!
For this tutorial, we will use Google Cloud BigQuery as a data warehouse solution. Its free tier makes it a perfect candidate for learning. You can activate BigQuery in your Google Cloud account.
We will install dbt locally using Python and pip manager, create a virtual environment, and start running sample models and tests.
Run the following commands in your command line:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtOur requirements.txt should contain the following dependencies:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Then, for the rest of the tutorial, we will do the following:
Let’s create service account credentials for our dbt application:
Creating a service account for BigQuery in Google Cloud. Image by Author.
Saving the service account private key in JSON format. Image by Author.
dbt init command in a terminal to finally initialize our dbt project. Once you finish the setup, you should get a message like this:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.And the folder structure should look similar to this:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtWe can see that profiles.yml was created in our local machine’s root folder, but ideally, we would want it to be in our application folder, so let’s move it.
cd my_dbt
touch profiles.ymlFinally, let’s adjust the contents of the profiles.yml to reflect our project name and include the Google service account credentials:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comThat’s it! We are ready to compile our project.
export DBT_PROFILES_DIR='.'
dbt compileThe output should be something like this:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')Our initial project setup is done.
We want to design our dbt project conveniently and transparently to reflect data warehouse architecture clearly.
I recommend using templates and macros in your dbt project and incorporating custom database names to effectively separate your data environments into production, development, and testing.
This approach improves organization and minimizes the risk of accidental modifications in the wrong environment, enhancing overall data management and workflow stability. By doing this, we can easily manage and maintain those environments, which helps ensure that the production data remains secure and untouched by experimental or test changes.
Databases in different environments can also be named in a structured and consistent manner using relevant suffixes (_prod, _dev, _test), making it easier to differentiate between environments while enabling smoother transitions and deployments.

The different data warehouse layers in a production environment. Image by Author.
For instance, we can move the main data model layers to the database naming convention using raw_ and base_ prefixes in database naming:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsTo inject these custom database names dynamically, you need only create a dbt macro that handles this task automatically. By leveraging this approach, you can ensure that the correct database names are used in the appropriate data environment without manually editing configurations every time.
Let's see the code snippet below, which contains a macro for setting different schemas depending on the environment we’re in:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Now, whenever we compile our models, dbt will automatically apply the custom database name based on the configuration specified within each model's setup. This means that the correct database name will be injected during the compilation process, ensuring that the models are aligned with the appropriate environment — production, development, or testing.
By incorporating this feature, we eliminate the need for manual changes to the database names, further enhancing the efficiency and accuracy of our workflow.
These required configurations can be set in properties.yml for our models:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullAs you can see, we can use basic conditional statements to introduce logic into the configuration files, thanks to dbt supporting Jinja.
Macros cannot be used in this context, but we can use simple conditionals using Jinja expressions within .yml files. They need to be enclosed in quotation marks. This ensures that the templating language is properly interpreted during execution.
Let’s run a dbt compile command and see what happens:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt supports variables, which are a very powerful customization feature. Variables can be used in both SQL templates and macros and can be supplied from the command line like so:
dbt run -m table_b -t dev --vars '{my_var: my_value}'Variables must be declared in the main project file dbt_project.yml. For example, the snippet below demonstrates how to do it:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Let's use variables to create custom table names (alias names) in dbt.
If no alias is present, the model's original name (file name) is used as the alias by default. This simple logic ensures that models are either referenced by their configured alias or their default name, depending on the setup. The implementation for this functionality looks like the following, ensuring flexibility in how models are named and referenced across environments:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Let's override this behavior using variables. This is a common setup for data developers to mitigate the risks of stepping on each other's toes while working on staging (development).
We want to add the developer name to all database instances (tables, views, etc.) created by development engineers.
Let's make a generate_alias_name.sql macro:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}Don’t forget to add our new variable to dbt_project.yml and run this in your command line:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'You should see an output like this:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1We can see that our variable was added to a table name: table_a_mike.
This section is all about how we design our data warehouse in terms of data transformation. A simplified logical project structure in dbt can look like this one below:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlPersonally, I always try to focus on keeping the foundational (base) data model layer as clean and straightforward as possible, ensuring that data transformations are applied only when necessary. Using this approach, we aim to design and implement a base_ data model layer that involves minimal data manipulation at the column level.
However, there are instances where some level of manipulation might be beneficial, particularly when it comes to optimizing query performance. In such cases, minor adjustments at the base layer can significantly improve efficiency, making it worthwhile to balance simplicity and performance gains. In this case, adding an extra join or partitioning filter would be justified.
A recommended practice is to implement the following techniques to enhance your data models and pipelines:
biz_ and mart_ layers. This can help improve performance and ensure that business logic is efficiently managed.select * and consider splitting long and complex SQL files into smaller models with unit tests.Consider the SQL query below. It explains how to create such custom materialization:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Now, if we add an extra model called table_c to demonstrate this feature, we can use the SQL below:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Now, if we compile it, it should look like a SQL script:
$ dbt compile -m table_c -t devThe output:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;The benefit of this approach is that we don't need to rely on the BigQuery adapter anymore. If we create another table or view that references this operation, we can simply use the standard ref() function.
By doing so, table_c will automatically be recognized as a dependency in the data lineage. This makes tracking how tables are related easy and ensures that the relationships between different models are properly documented within your data environment.
This method helps with managing dependencies and provides a clear view of how data flows through various stages, including complex data processing steps involving scripts. This is especially useful for maintaining complex data pipelines.
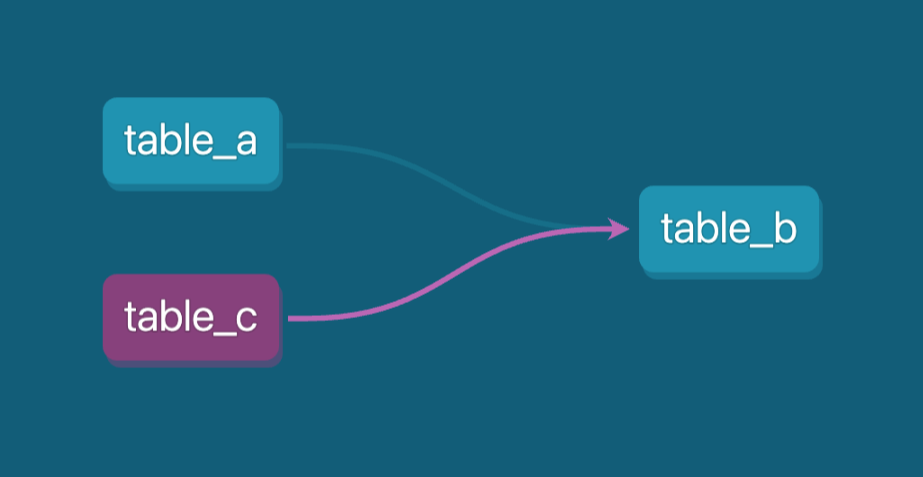
DAG (directed acyclic graph) in dbt shows the dependencies for table_b. Image by Author
Now, we just need to add table_c to our pipeline:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;Documentation will be auto-generated if we run the following in our command line!
dbt docs generate
dbt docs serveA more advanced example of a data warehousing project in dbt can look like the structure below. It contains multiple data sources and transformations through various model layers (stg, base, mrt, biz) to finally produce data mart models.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlUnit testing is a crucial step in the data pipeline process, where we can run tests to validate the logic behind our data models. As you would perform unit tests for your Python functions to ensure they behave as expected, I apply a similar approach to testing data models.
By running these tests, we can catch potential issues early and ensure that the transformations and logic are functioning correctly. This practice helps maintain data quality and prevents errors from propagating through the pipeline, making it a vital aspect of the data engineering process.
We can add a unit test for a model simply by modifying the properties.yml file:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Now, if we run the dbt test command in our command line, we can execute the unit tests:
% dbt test --select "table_b,test_type:unit"This is the output:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Try changing the row id in expect to 3, and we will get an error for the same test:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt offers support for data quality checks as well. I previously wrote about it in the data contracts blog post. We can check almost everything relevant to data quality, i.e., data freshness, row conditions, granularity, etc.
Let’s take a closer look at our table_b model. It has some data checks in place already:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullHere, under the tests definition, we test our materialized table_b.id for unique and not_null condition. To run this specific test, the following command will work:
dbt test -s table_bWe can also test our datasets for referential integrity. This is essential when working with data models with joins, as it ensures that relationships between entities are accurately maintained. These tests help define how different entities, such as tables or columns, relate to one another.
For example, consider the dbt code below, which illustrates how every refunds.refund_id is linked to a valid transactions.id. This mapping ensures that all refunds are tied to legitimate transactions, maintaining the integrity of your data and preventing orphaned records or inconsistent relationships in your data models:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idData requirements often involve setting expectations for when new data should be available and specifying the maximum allowable delay for updates. These checks are crucial to ensure that data remains relevant for analysis (up-to-date).
In dbt, this can be implemented by utilizing freshness tests, which allow you to monitor whether new data arrives within the expected time frame.
For example, you can configure a freshness test to verify that the most recent record in a table meets your defined criteria for freshness. This ensures that your data pipelines deliver updates promptly and consistently, helping maintain the reliability and accuracy of your data while adhering to time-sensitive requirements.
Consider the code snippet below. It explains how to set up a freshness test in dbt:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1All these dbt tests are remarkable and very useful in data engineers’ day-to-day work! They help to keep the data warehouse well-maintained and data pipelines consistent.
Building a data warehouse solution is a complex task that requires careful planning and organization. dbt, as a templating engine, helps to do it consistently.
In this article, I’ve outlined several techniques for organizing dbt data transformation folders to enhance clarity and collaboration. By storing SQL files in a logical structure, we create an environment that is easy to explore, even for those new to the project.
DBT offers a wide array of features to streamline the process further. For example, we can enrich our SQL templates by incorporating reusable pieces of code through macros, variables, and constants. In my experience, when paired with infrastructure-as-code practices, this functionality helps enforce proper CI/CD workflows, significantly speeding up development and deployment.
If you want to take your dbt knowledge to the next level, consider taking the Introduction to dbt course on DataCamp. It’s an excellent resource that can certainly get you started successfully with more hands-on practice!
Learn more about dbt and data engineering with these courses!
Track
Track
Course
blog
Austin Chia
11 min
blog
Laiba Siddiqui
15 min
Tutorial
Austin Chia
Tutorial
Bex Tuychiev
Tutorial
Austin Chia
Tutorial
Austin Chia
