
Lernpfad
Associate Data Engineer in SQL
30 Std.
In diesem Artikel beschreibe ich einige Techniken, die beim Erlernen von dbt helfen und das Projekt-Setup und die Datenmodellierung rationalisieren können, so dass der Gesamtprozess leichter zu bewältigen ist.
Außerdem werde ich auf die spezifischen dbt-Projektdesignmuster eingehen, die ich bei meiner täglichen Arbeit verwende. Diese Methoden haben sich bei meinen Bemühungen, Datenplattformen und Data Warehouses aufzubauen, die genau, intuitiv, einfach zu navigieren und benutzerfreundlich sind, als unschätzbar erwiesen.
Die Anwendung dieser Ansätze erleichtert die Erstellung von Datenplattformen, die hochwertige Standards erfüllen, und minimiert gleichzeitig potenzielle Probleme, was letztendlich zu erfolgreicheren datengesteuerten Projekten führt.
dbt (Data Build Tool) ist eine leistungsstarke Open-Source-Lösung, die speziell für die Datenmodellierungentwickelt wurde. Sie nutzt SQL-Vorlagen und ref() (Referenzierungs-)Funktionen, um Beziehungen zwischen verschiedenen Datenbankinstanzen wie Tabellen, Ansichten, Schemata und mehr herzustellen. Seine Flexibilität eignet sich für alle, die dem DRY-Prinzip (Do Not Repeat Yourself) folgen.
Mit dbt kannst du eine einzige SQL-Vorlage erstellen, die wiederverwendet und leicht an verschiedene Datenumgebungen angepasst werden kann. Sobald die Vorlage geschrieben ist, kann sie "kompiliert" werden, um die SQL-Abfragen zu erstellen, die für die Ausführung in der jeweiligen Umgebung erforderlich sind.
Der von dbt verfolgte Ansatz verbessert die Effizienz und sorgt für Konsistenz in den verschiedenen Phasen der Datenpipeline. Dadurch werden Redundanzen und potenzielle Fehler reduziert und die Wartung und Skalierung der Dateninfrastruktur vereinfacht.
Die Datenmodellierung spielt eine zentrale Rolle im Data Engineering, und dbt ist ein hervorragendes Werkzeug. Ich würde sogar behaupten, dass die Beherrschung von dbt für jeden, der ein erfolgreicher Datenprofi werden will, absolut unerlässlich ist!
Betrachte die folgende dbt-Vorlage. Es handelt sich um eine einfache Tabellendefinition, die jedoch Metadaten enthält, die dem Benutzer mitteilen, welche Datenbank und welches Schema er verwenden soll:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Stellen wir uns vor, dass wir in der Datenpipeline eine Ansicht haben, die aus der oben erstellten Tabelle (table_a.sql) stammt. Unsere Datenpipeline würde also wie folgt aussehen:

Beispiel für eine Daten-Pipeline-Linie. Bild vom Autor.
Wir werden die Funktion ref() verwenden, um zwei Stufen unserer Pipeline zu verbinden, und in unserem Fall kann table_b.sql wie folgt definiert werden:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1Die Funktion ref() sagt, dass das Modell table_b nach dem Modell table_a (Downstream) kommt. Jetzt können wir die gesamte Pipeline mit nur einem dbt-Befehl ausführen: dbt run --select tag:example.
Aufgrund seiner Fähigkeiten zur Wiederverwendung von Code bietet dbt Funktionen, die es zu einem hervorragenden Werkzeug machen für für die Verwaltung und Optimierung von Daten-Workflows in verschiedenen (Produktion, Entwicklung, Tests usw.).
Darüber hinaus ist eine der Kernfunktionen des Programms die automatische Erstellung einer umfassenden SQL-Dokumentationdie die Transparenz deutlich verbessert und das Verständnis von Datenmodellen für Datenentwickler und Unternehmensbeteiligte erleichtert.
Eine der Herausforderungen bei der Datenmodellierung besteht darin, komplexe SQL-Transformationspipelines zu erstellen, die mehrere Ebenen umfassen, und gleichzeitig den Code wiederverwendbar zu machen. Diese Pipelines müssen sorgfältig durchdacht und sorgfältig getestet werden, um sicherzustellen, dass sie effizient funktionieren und die organisatorische Transparenz aufrechterhalten wird, damit jeder die Logik verstehen kann. dbt kann auch in dieser Hinsicht helfen.
Darüber hinaus unterstützt dbt Datenqualitätstests und Unit-Tests für SQL-Logik, mit denen du die Genauigkeit und Zuverlässigkeit deiner Transformationen strukturiert und automatisiert überprüfen kannst(CI/CD-Workflows).
Eine weitere wichtige Funktion ist die flexible Automatisierung durch Makrosdie anpassbare und wiederverwendbare Codeschnipsel ermöglichen, die komplexe Aufgaben vereinfachen und die Produktivität steigern.
Diese kombinierten Funktionen machen dbt zu einer idealen Lösung für alle SQL-bezogenen Aufgaben und Datenumgebungen, von der Sicherstellung der Datenintegrität bis zur Automatisierung sich wiederholender Prozesse, und das alles bei gleichzeitiger Effizienz und Skalierbarkeit.
Lass uns praktisch werden und einige Beispiele mit dbt und BigQuery als Datenplattform ausführen!
In diesem Tutorial werden wir Google Cloud BigQuery als Data Warehouse-Lösung verwenden. Mit seinem kostenlosen Angebot ist es der perfekte Kandidat zum Lernen. Du kannst BigQuery in deinem Google Cloud-Konto aktivieren.
Wir installieren dbt lokal mit Python und dem pip manager, erstellen eine virtuelle Umgebung und beginnen mit der Ausführung von Beispielmodellen und Tests.
Führe die folgenden Befehle in deiner Befehlszeile aus:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtUnser requirements.txt sollte die folgenden Abhängigkeiten enthalten:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Für den Rest des Tutorials werden wir dann Folgendes tun:
Erstellen wir die Anmeldedaten für das Dienstkonto unserer dbt-Anwendung:
Erstellen eines Dienstkontos für BigQuery in Google Cloud. Bild vom Autor.
Speichern des privaten Schlüssels des Servicekontos im JSON-Format. Bild vom Autor.
dbt init in einem Terminal aus, um unser dbt-Projekt zu initialisieren. Sobald du die Einrichtung abgeschlossen hast, solltest du eine Meldung wie diese erhalten:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.Und die Ordnerstruktur sollte so ähnlich aussehen:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtWir sehen, dass profiles.yml im Stammordner unseres lokalen Rechners erstellt wurde, aber idealerweise wollen wir es in unserem Anwendungsordner haben, also verschieben wir es.
cd my_dbt
touch profiles.ymlZum Schluss passen wir den Inhalt von profiles.yml so an, dass er unseren Projektnamen wiedergibt und die Anmeldedaten für das Google-Servicekonto enthält:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comDas war's! Wir sind bereit, unser Projekt zu kompilieren.
export DBT_PROFILES_DIR='.'
dbt compileDie Ausgabe sollte in etwa so aussehen:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')Unsere anfängliche Projekteinrichtung ist abgeschlossen.
Wir wollen unser dbt-Projekt bequem und transparent gestalten, um die Data Warehouse-Architektur klar abzubilden.
Ich empfehle, Vorlagen und Makros in deinem dbt-Projekt zu verwenden und benutzerdefinierte Datenbanknamen einzubauen, um deine Datenumgebungen effektiv in Produktion, Entwicklung und Test zu trennen.
Dieser Ansatz verbessert die Organisation und minimiert das Risiko versehentlicher Änderungen in der falschen Umgebung, was das gesamte Datenmanagement und die Stabilität des Workflows verbessert. Auf diese Weise können wir diese Umgebungen leicht verwalten und pflegen, was dazu beiträgt, dass die Produktionsdaten sicher bleiben und nicht durch experimentelle oder Teständerungen beeinträchtigt werden.
Datenbanken in verschiedenen Umgebungen können auch strukturiert und einheitlich mit entsprechenden Suffixen benannt werden (_prod, _dev, _test), was die Unterscheidung zwischen den Umgebungen erleichtert und gleichzeitig reibungslosere Übergänge und Einsätze ermöglicht.

Die verschiedenen Data Warehouse-Schichten in einer Produktionsumgebung. Bild vom Autor.
Wir können zum Beispiel die Hauptdatenmodellebenen in die Datenbankbenennungskonvention verschieben, indem wir die Präfixe raw_ und base_ in der Datenbankbenennung verwenden:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsUm diese benutzerdefinierten Datenbanknamen dynamisch einzufügen, musst du nur ein dbt-Makro erstellen, das diese Aufgabe automatisch übernimmt. Mit diesem Ansatz kannst du sicherstellen, dass die richtigen Datenbanknamen in der entsprechenden Datenumgebung verwendet werden, ohne die Konfigurationen jedes Mal manuell zu bearbeiten.
Im folgenden Codeschnipsel findest du ein Makro, mit dem du je nach Umgebung unterschiedliche Schemata festlegen kannst:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Wenn wir nun unsere Modelle kompilieren, wendet dbt automatisch den benutzerdefinierten Datenbanknamen an, basierend auf der Konfiguration, die im Setup des jeweiligen Modells festgelegt wurde. Das bedeutet, dass der richtige Datenbankname während des Kompilierungsprozesses eingefügt wird, um sicherzustellen, dass die Modelle an die entsprechende Umgebung - Produktion, Entwicklung oder Test - angepasst sind.
Dank dieser Funktion müssen wir die Namen in den Datenbanken nicht mehr manuell ändern, was die Effizienz und Genauigkeit unserer Arbeitsabläufe weiter erhöht.
Diese erforderlichen Konfigurationen können unter properties.yml für unsere Modelle eingestellt werden:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullWie du siehst, können wir dank der Jinja-Unterstützung von dbt einfache bedingte Anweisungen verwenden, um Logik in die Konfigurationsdateien zu bringen.
Makros können in diesem Zusammenhang nicht verwendet werden, aber wir können einfache Bedingungen mit Jinja-Ausdrücken in .yml Dateien verwenden. Sie müssen in Anführungszeichen gesetzt werden. Dadurch wird sichergestellt, dass die Schablonensprache bei der Ausführung richtig interpretiert wird.
Lass uns den Befehl dbt compile ausführen und sehen, was passiert:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt unterstützt Variablen, die eine sehr mächtige Anpassungsfunktion sind. Variablen können sowohl in SQL-Vorlagen als auch in Makros verwendet werden und können wie folgt über die Befehlszeile übergeben werden:
dbt run -m table_b -t dev --vars '{my_var: my_value}'Variablen müssen in der Hauptprojektdatei dbt_project.yml deklariert werden. Der folgende Ausschnitt zeigt, wie es geht:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Verwenden wir Variablen, um eigene Tabellennamen (Aliasnamen) in dbt zu erstellen.
Wenn kein Alias vorhanden ist, wird standardmäßig der ursprüngliche Name des Modells (Dateiname) als Alias verwendet. Diese einfache Logik stellt sicher, dass die Modelle je nach Einstellung entweder mit ihrem konfigurierten Alias oder ihrem Standardnamen referenziert werden. Die Implementierung dieser Funktion sieht wie folgt aus, damit die Modelle in verschiedenen Umgebungen flexibel benannt und referenziert werden können:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Lass uns dieses Verhalten mit Hilfe von Variablen außer Kraft setzen. Dies ist eine übliche Vorgehensweise für Datenentwickler, um das Risiko zu minimieren, sich bei der Arbeit im Staging (Entwicklung) gegenseitig auf die Füße zu treten.
Wir möchten den Namen des Entwicklers zu allen Datenbankinstanzen (Tabellen, Ansichten usw.) hinzufügen, die von Entwicklungsingenieuren erstellt werden.
Lass uns ein generate_alias_name.sql Makro erstellen:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}Vergiss nicht, unsere neue Variable zu dbt_project.yml hinzuzufügen und sie in deiner Kommandozeile auszuführen:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Du solltest eine Ausgabe wie diese sehen:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1Wir können sehen, dass unsere Variable zu einer Tabelle hinzugefügt wurde: table_a_mike.
In diesem Abschnitt geht es darum, wie wir unser Data Warehouse im Hinblick auf die Datentransformation gestalten. Eine vereinfachte logische Projektstruktur in dbt kann wie die folgende aussehen:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlIch persönlich versuche immer, die grundlegende (Basis-)Datenmodellschicht so sauber und einfach wie möglich zu halten und sicherzustellen, dass die Daten nur bei Bedarf umgewandelt werden. Mit diesem Ansatz wollen wir eine base_ Datenmodellschicht entwerfen und implementieren, die nur minimale Datenmanipulationen auf Spaltenebene erfordert.
Es gibt jedoch Fälle, in denen ein gewisses Maß an Manipulation vorteilhaft sein kann, insbesondere wenn es darum geht, die Abfrageleistung zu optimieren. In solchen Fällen können kleine Anpassungen an der Basisschicht die Effizienz erheblich verbessern, sodass es sich lohnt, ein Gleichgewicht zwischen Einfachheit und Leistungssteigerung zu finden. In diesem Fall wäre das Hinzufügen eines zusätzlichen Join- oder Partitionierungsfilters gerechtfertigt.
Es empfiehlt sich, die folgenden Techniken anzuwenden, um deine Datenmodelle und Pipelines zu verbessern:
biz_ und mart_. Dies kann dazu beitragen, die Leistung zu verbessern und sicherzustellen, dass die Geschäftslogik effizient verwaltet wird.select * und erwäge, lange und komplexe SQL-Dateien in kleinere Modelle mit Unit-Tests aufzuteilen.Betrachte die folgende SQL-Abfrage. Hier wird erklärt, wie man eine solche benutzerdefinierte Materialisierung erstellt:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Wenn wir nun ein zusätzliches Modell namens table_c hinzufügen, um diese Funktion zu demonstrieren, können wir die folgende SQL verwenden:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Wenn wir es nun kompilieren, sollte es wie ein SQL-Skript aussehen:
$ dbt compile -m table_c -t devDas Ergebnis:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Der Vorteil dieses Ansatzes ist, dass wir uns nicht mehr auf den BigQuery-Adapter verlassen müssen. Wenn wir eine andere Tabelle oder Ansicht erstellen, die auf diese Operation verweist, können wir einfach die Standardfunktion ref() verwenden.
Auf diese Weise wird table_c automatisch als Abhängigkeit in der Datenabfolge erkannt. So kannst du leicht nachverfolgen, wie Tabellen miteinander verbunden sind, und sicherstellen, dass die Beziehungen zwischen verschiedenen Modellen in deiner Datenumgebung richtig dokumentiert sind.
Diese Methode hilft bei der Verwaltung von Abhängigkeiten und bietet einen klaren Überblick über den Datenfluss in den verschiedenen Phasen, einschließlich komplexer Datenverarbeitungsschritte, die Skripte beinhalten. Dies ist besonders nützlich für die Pflege komplexer Datenpipelines.
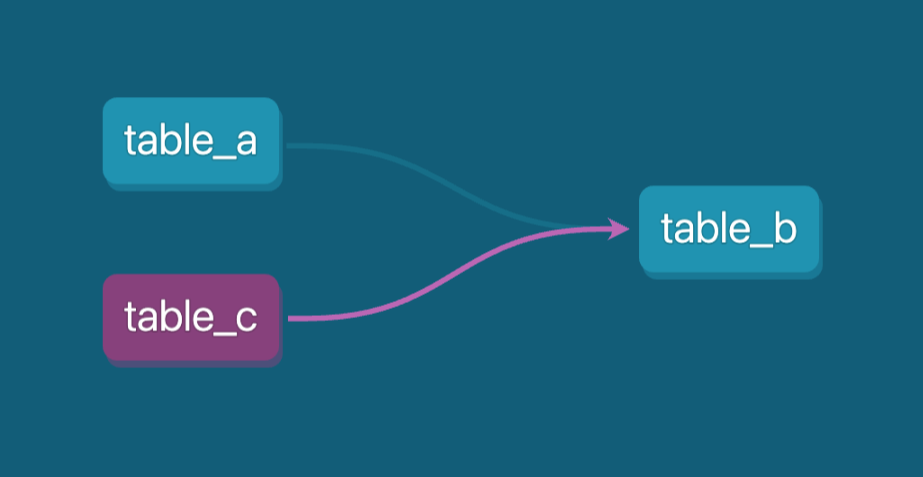
DAG (directed acyclic graph) in dbt zeigt die Abhängigkeiten für table_b. Bild vom Autor
Jetzt müssen wir nur noch table_c zu unserer Pipeline hinzufügen:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;Die Dokumentation wird automatisch generiert, wenn wir den folgenden Befehl in der Kommandozeile ausführen!
dbt docs generate
dbt docs serveEin fortgeschrittenes Beispiel für ein Data-Warehousing-Projekt in dbt kann wie die folgende Struktur aussehen. Es enthält mehrere Datenquellen und Transformationen durch verschiedene Modellebenen (stg, base, mrt, biz), um schließlich Data Mart Modelle zu erstellen.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlUnit-Tests sind ein wichtiger Schritt im Prozess der Datenpipeline, bei dem wir die Logik hinter unseren Datenmodellen durch Tests überprüfen können. So wie du Unit-Tests für deine Python-Funktionen durchführst, um sicherzustellen, dass sie sich wie erwartet verhalten, wende ich einen ähnlichen Ansatz beim Testen von Datenmodellen an.
Durch diese Tests können wir potenzielle Probleme frühzeitig erkennen und sicherstellen, dass die Transformationen und die Logik korrekt funktionieren. Diese Praxis trägt dazu bei, die Datenqualität zu erhalten und zu verhindern, dass sich Fehler in der Pipeline ausbreiten, was sie zu einem wichtigen Aspekt des Data Engineering-Prozesses macht.
Wir können einen Einheitstest für ein Modell hinzufügen, indem wir einfach die Datei properties.yml ändern:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Wenn wir nun den Befehl dbt test in unserer Kommandozeile ausführen, können wir die Unit-Tests ausführen:
% dbt test --select "table_b,test_type:unit"Das ist die Ausgabe:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Wenn du die Zeile id in expect auf 3 änderst, erhältst du einen Fehler für denselben Test:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt bietet auch Unterstützung für Datenqualitätsprüfungen. Ich habe schon einmal darüber geschrieben, und zwar im Datenverträge Blogbeitrag geschrieben. Wir können fast alles prüfen, was für die Datenqualität relevant ist, z. B. die Aktualität der Daten, die Bedingungen für die Zeilen, die Granularität usw.
Schauen wir uns unser table_b Modell genauer an. Es gibt bereits einige Datenkontrollen:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullHier, unter der tests Definition, testen wir unsere materialisierte table_b.id für unique und not_null Bedingung. Um diesen speziellen Test durchzuführen, funktioniert der folgende Befehl:
dbt test -s table_bWir können unsere Datensätze auch auf referenzielle Integrität prüfen. Das ist wichtig, wenn du mit Datenmodellen mit Joins arbeitest, da so sichergestellt wird, dass die Beziehungen zwischen den Entitäten genau eingehalten werden. Diese Tests helfen dabei, zu definieren, wie verschiedene Entitäten, wie Tabellen oder Spalten, miteinander in Beziehung stehen.
Betrachte zum Beispiel den folgenden dbt-Code, der veranschaulicht, wie jedes refunds.refund_id mit einem gültigen transactions.id verknüpft ist. Diese Zuordnung stellt sicher, dass alle Erstattungen mit rechtmäßigen Transaktionen verknüpft sind, wodurch die Integrität deiner Daten gewahrt bleibt und verwaiste Datensätze oder inkonsistente Beziehungen in deinen Datenmodellen verhindert werden:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idBei den Datenanforderungen geht es oft darum, Erwartungen zu formulieren, wann neue Daten verfügbar sein sollten, und die maximal zulässige Verzögerung für Aktualisierungen festzulegen. Diese Kontrollen sind wichtig, um sicherzustellen, dass die Daten für die Analyse relevant (aktuell) bleiben.
In dbt kann dies mit Hilfe von Freshness-Tests umgesetzt werden, mit denen du überwachen kannst, ob neue Daten innerhalb des erwarteten Zeitrahmens ankommen.
Du kannst zum Beispiel einen Freshness-Test konfigurieren, um zu überprüfen, ob der jüngste Datensatz in einer Tabelle die von dir festgelegten Freshness-Kriterien erfüllt. So wird sichergestellt, dass deine Datenpipelines Aktualisierungen zeitnah und konsistent liefern und die Zuverlässigkeit und Genauigkeit deiner Daten aufrechterhalten, während du gleichzeitig zeitkritische Anforderungen einhältst.
Sieh dir das folgende Codeschnipsel an. Hier wird erklärt, wie man einen Freshness-Test in dbt einrichtet:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1Alle diese dbt-Tests sind bemerkenswert und sehr nützlich für die tägliche Arbeit von Dateningenieuren! Sie tragen dazu bei, dass das Data Warehouse gut gewartet wird und die Datenpipelines konsistent bleiben.
Der Aufbau einer Data-Warehouse-Lösung ist eine komplexe Aufgabe, die eine sorgfältige Planung und Organisation erfordert. dbt als Template-Engine hilft dabei, dies konsequent zu tun.
In diesem Artikel habe ich verschiedene Techniken zur Organisation von dbt-Datentransformationsordnern vorgestellt, um die Übersichtlichkeit und Zusammenarbeit zu verbessern. Indem wir die SQL-Dateien in einer logischen Struktur speichern, schaffen wir eine Umgebung, die auch für Neueinsteiger leicht zu erkunden ist.
DBT bietet eine breite Palette von Funktionen, um den Prozess weiter zu optimieren. So können wir zum Beispiel unsere SQL-Vorlagen durch Makros, Variablen und Konstanten um wiederverwendbare Codeteile erweitern. Meiner Erfahrung nach hilft diese Funktion in Verbindung mit Infrastructure-as-Code-Praktiken dabei, ordnungsgemäße CI/CD-Workflows durchzusetzen und die Entwicklung und Bereitstellung erheblich zu beschleunigen.
Wenn du dein dbt-Wissen auf die nächste Stufe bringen willst, solltest du den Kurs Einführung in dbt auf DataCamp besuchen. Es ist ein hervorragendes Hilfsmittel, das dir sicherlich einen erfolgreichen Einstieg in die Praxis ermöglicht!
Lerne in diesen Kursen mehr über dbt und Data Engineering!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Zoumana Keita
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui

