programa
Manipulación de datos en Python
16 h
Con el aumento del volumen, la variedad y la velocidad de los datos, centrarse en crear conjuntos de datos de calidad y bien estructurados se ha vuelto más crítico que nunca, ya que influyen directamente en la precisión de los conocimientos y la eficacia de las decisiones en todos los sectores.
Los datos mal organizados o defectuosos pueden llevar a conclusiones erróneas, que cuestan tiempo, dinero y recursos. Aquí es donde interviene data wrangling como proceso esencial que garantiza que los datos brutos y no estructurados se transformen en un formato limpio y organizado, listo para el análisis .
El tratamiento de los datos implica una serie de pasos para garantizar que son precisos, fiables y adaptados a las necesidades específicas del análisis en cuestión. Al dominar la gestión de datos, puedes liberar todo el potencial de tus datos, convirtiéndolos en información procesable que impulse decisiones informadas y, en última instancia, conduzca al éxito.
La gestión de datos es el proceso de transformar los datos brutos en un formato más utilizable. Esto implica limpiar, estructurar y enriquecer los datos para que estén listos para el análisis.
Imagina que acabas de recibir un enorme conjunto de datos: está desordenado, con valores que faltan, incoherencias e información irrelevante. La gestión de datos es como un juego de herramientas que te ayuda a ordenar estos datos, asegurándote de que estén organizados y sean coherentes.
La gestión de datos es importante para garantizar que tus datos sean de alta calidad y estén bien estructurados, lo que es crucial para un análisis de datos preciso. Unos datos limpios y estructurados sirven de base para todos los pasos posteriores del flujo de trabajo de datos, ya estés construyendo un modelo de aprendizaje automático, generando visualizaciones o realizando análisis estadísticos.
Los datos de alta calidad reducen el riesgo de errores y sesgos en tu análisis, lo que conduce a perspectivas más fiables. Comprender la importancia de la gestión de datos es clave, ya que afecta directamente a la validez de las decisiones que se toman basándose en esos datos.
Unos datos mal manejados pueden llevar a conclusiones erróneas, que pueden tener consecuencias importantes en las aplicaciones del mundo real. Por lo tanto, dominar la gestión de datos es esencial para cualquiera que se tome en serio la toma de decisiones basadas en datos.
Hay 5 pasos principales en la gestión de datos:
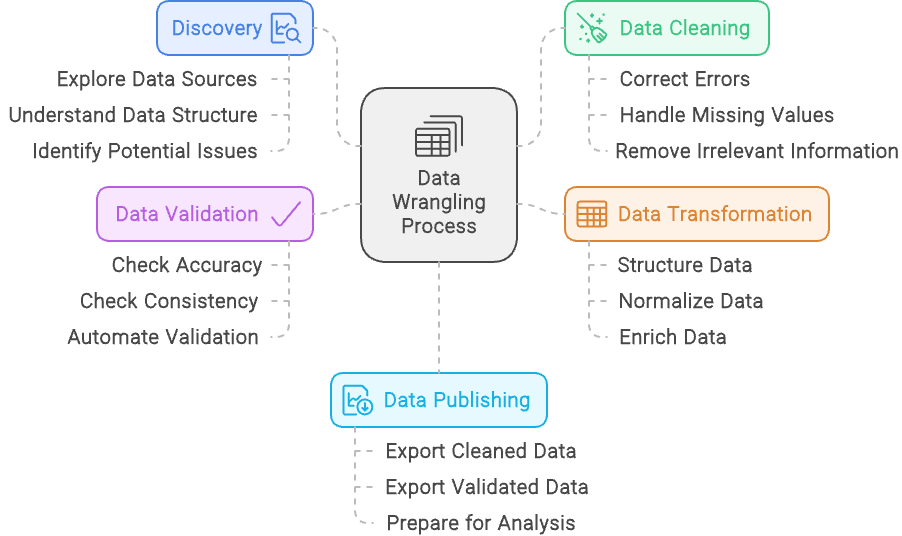
El proceso de tratamiento de datos - creado con Napkin.ai
Hemos esbozado los cinco pasos de la gestión de datos, pero veamos cada uno con más detalle:
La página descubrimiento en la gestión de datos es como echar un primer vistazo a un puzzle antes de empezar a encajar las piezas. Implica examinar el conjunto de datos para tener una idea clara de con qué estás trabajando, incluyendo la comprensión de los tipos de datos, sus fuentes y cómo están estructurados.
Del mismo modo que clasificas las piezas de un puzzle por colores o formas de los bordes, el descubrimiento te ayuda a categorizar y reconocer patrones en los datos, preparando el terreno para el trabajo que tienes por delante.
Pero descubrir también consiste en detectar problemas potenciales, como piezas que faltan o colores que no encajan en un puzzle.
Durante este paso, identificas cualquier problema en los datos, como incoherencias, valores que faltan o patrones inesperados. Si descubres estos problemas desde el principio, podrás planificar cómo abordarlos en los siguientes pasos de la gestión de datos, garantizando un camino más fácil hacia un conjunto de datos limpio y utilizable.
La limpieza de datos consiste en refinar tu conjunto de datos para garantizar su precisión y fiabilidad.
Este proceso incluye abordar cuestiones como la corrección de errores, el tratamiento de valores omitidos y la corrección de incoherencias. Por ejemplo, si tu conjunto de datos contiene entradas duplicadas para el mismo individuo o transacción, la limpieza de datos implicaría eliminar estos duplicados para evitar sesgar los resultados.
Además, si ves que algunas entradas están mal formateadas, como los números de teléfono con formatos distintos, las normalizarías a un formato coherente. El objetivo es mejorar la calidad general y la integridad de los datos, preparándolos para un análisis preciso y significativo.
La transformación de datos Es el proceso de modificar y mejorar tu conjunto de datos para que se ajuste mejor a los requisitos de tu análisis. Este paso implica la estructuración de los datos, como remodelarlos para adaptarlos al formato deseado o combinar varias fuentes en una estructura cohesionada.
Normalizar los datos es otro aspecto clave, que significa ajustar los valores a una escala o formato común, como convertir todos los valores monetarios a una sola moneda o normalizar las unidades de medida.
Además, la transformación de datos incluye enriquecer el conjunto de datos añadiendo nuevas variables o integrando fuentes de datos externas para proporcionar más contexto o perspectivas. Por ejemplo, puedes calcular nuevas métricas a partir de los datos existentes o añadir información adicional de otras bases de datos para obtener una imagen más completa.
El objetivo de la transformación de datos es prepararlos de forma que mejoren su utilidad y relevancia para un análisis en profundidad.
La validación de datos consiste en garantizar la exactitud y fiabilidad de tu conjunto de datos mediante comprobaciones sistemáticas y procesos automatizados. Este paso es fundamental para confirmar que los datos son correctos y coherentes.
Durante la validación de datos, realizas varias comprobaciones para identificar cualquier discrepancia, como comparar los datos con puntos de referencia conocidos o validarlos con reglas y restricciones predefinidas. Los procesos automatizados pueden incluir la ejecución de scripts que detecten anomalías o incoherencias, asegurándose de que los datos se ajustan a los formatos y rangos esperados.
El objetivo de la validación de datos es detectar cualquier problema antes de que los datos se utilicen para el análisis, evitando que los errores afecten a los resultados. Verificando rigurosamente la exactitud y fiabilidad de los datos, te aseguras de que las percepciones extraídas de los datos se basan en información fidedigna.
La publicación de datos es el paso final del proceso de tratamiento de datos, en el que los datos depurados y estructurados se ponen a disposición para el análisis y la toma de decisiones. Este paso implica preparar los datos para su difusión, a menudo mediante la creación de cuadros de mando, informes o visualizaciones interactivas que los hagan accesibles y comprensibles para las partes interesadas.
Durante la publicación de los datos, puedes establecer canalizaciones de datos o interfaces que permitan a los usuarios consultar los datos e interactuar con ellos, asegurándote de que se entregan en un formato que satisfaga sus necesidades.
El objetivo es proporcionar ideas claras y procesables a partir de los datos, permitiendo una toma de decisiones informada y facilitando la comunicación de los hallazgos en toda la organización. Al publicar eficazmente los datos, te aseguras de que el duro trabajo de elaboración de datos se traduzca en resultados significativos y prácticos.
Los términos manipulación de datos y limpieza de datos suelen utilizarse indistintamente, pero se refieren a aspectos diferentes del proceso de preparación de datos. Aunque ambos son esenciales para preparar los datos para el análisis, tienen finalidades distintas e implican tareas diferentes. Comprender la diferencia entre ellos ayuda a aclarar sus funciones y garantiza que cada aspecto de la preparación de datos se maneje con eficacia.
Tratamiento de datos es un proceso exhaustivo que consiste en transformar los datos brutos en un formato adecuado para el análisis. Abarca varias etapas, como la adquisición de los datos, su estructuración, su limpieza y su validación. El objetivo de la gestión de datos es preparar los datos de diversas fuentes para que puedan ser analizados y utilizados eficazmente para generar ideas. Este proceso garantiza que los datos estén organizados, sean precisos y estén listos para un análisis detallado.
Limpieza de datos, por otra parte, es un subconjunto específico de la depuración de datos. Se centra exclusivamente en mejorar la calidad de los datos abordando y corrigiendo los errores y las incoherencias. Esto incluye tareas como eliminar registros duplicados, corregir errores tipográficos, tratar los valores que faltan y normalizar los formatos de los datos. Aunque la limpieza de datos es una parte crucial de la gestión de datos, es sólo un paso en el proceso más amplio.
En pocas palabras, la gestión de datos es el marco general que prepara los datos para el análisis, incluyendo múltiples pasos para manejar diversos aspectos de la preparación de datos. La limpieza de datos es un componente integral de este marco, dedicado específicamente a mejorar la exactitud y coherencia de los datos.
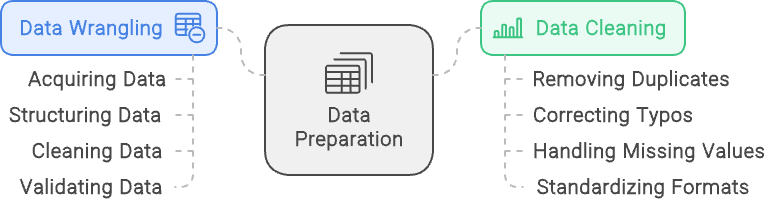
Manipulación de datos frente a limpieza de datos: La gestión de datos se centra en estructurar y validar los datos, mientras que la limpieza de datos se centra en garantizar que se dispone de datos limpios y de calidad. Imagen creada con napkin.ai
Hay muchas formas de manejar los datos, ya sea mediante el uso de herramientas fundamentales basadas en GUI, como Excel o Alteryx, o mediante la codificación con lenguajes como R y Python. Exploraremos aquí algunas opciones.
Para tareas sencillas de gestión de datos, las hojas de cálculo como Microsoft Excel y Google Sheets suelen ser las opciones más adecuadas. Estas herramientas son muy accesibles y ofrecen una interfaz familiar, lo que las hace ideales para tareas como la clasificación, el filtrado y la limpieza básica de datos. Las hojas de cálculo son especialmente útiles para los conjuntos de datos más pequeños o para quienes están empezando a aprender a manejar datos.
Con funciones y fórmulas incorporadas, permiten a los usuarios realizar cálculos y manipular datos rápidamente sin necesidad de grandes conocimientos técnicos.
Para la manipulación y automatización de datos más complejos, se utilizan ampliamente lenguajes de programación como Python y R. Python, con sus potentes bibliotecas como PandasNumPy y OpenRefine, es excelente para manejar grandes conjuntos de datos y realizar intrincadas transformaciones de datos.
Rcon paquetes como dplyr y tidyres otra buena opción, especialmente favorecida en las comunidades estadística y académica por sus sólidas capacidades de análisis de datos. Ambos lenguajes ofrecen un alto grado de flexibilidad, permitiendo a los usuarios programar flujos de trabajo personalizados y automatizar tareas repetitivas, lo que los hace ideales para los profesionales de los datos que trabajan con necesidades de manipulación de datos más sofisticadas.

Nuestro Hoja de trucos sobre el manejo de datos en Pandas puede ayudarte a dominar muchos de los aspectos básicos
Las herramientas de software especializadas están diseñadas específicamente para agilizar el proceso de gestión de datos, y ofrecen funciones avanzadas que simplifican las tareas complejas relacionadas con los datos. Estas herramientas son ideales para los usuarios que necesitan soluciones potentes, pero accesibles, para limpiar, estructurar y preparar los datos para el análisis sin necesidad de una codificación exhaustiva.
Alteryx es una herramienta líder en esta categoría, conocida por su intuitiva interfaz de arrastrar y soltar que permite a los usuarios limpiar, mezclar y transformar fácilmente datos de múltiples fuentes. Viene equipado con diversas herramientas integradas para la manipulación de datos, lo que facilita la realización de tareas como filtrar, unir y agregar datos.
Alteryx Designer Cloud, basado en la nube , mejora aún más estas capacidades al proporcionar una plataforma escalable y colaborativa para la gestión de datos. Esta solución permite a los equipos trabajar juntos en tiempo real, manejando con eficacia grandes conjuntos de datos y flujos de trabajo complejos en distintos entornos. Tanto si se utiliza en las instalaciones como en la nube, Alteryx garantiza que los datos se preparen con precisión y estén listos para un análisis profundo.
Para proyectos integrales de datos que requieren soluciones de extremo a extremo, plataformas integradas como KNIME, Apache NiFiy Microsoft Power BI. Estas plataformas no sólo admiten la gestión de datos, sino que también proporcionan herramientas para la integración, el análisis y la visualización de datos en un único entorno.
KNIME, por ejemplo, es conocido por su interfaz modular basada en nodos que permite a los usuarios construir flujos de trabajo complejos de forma visual. Apache NiFi destaca en la gestión y automatización de flujos de datos entre sistemas, mientras que Power BI combina la preparación de datos con potentes capacidades de visualización. Estas plataformas son ideales para proyectos en los que los datos deben prepararse, analizarse y compartirse a la perfección, ofreciendo un enfoque holístico de la toma de decisiones basada en datos.
Hay muchas opciones cuando se trata de manejar datos con Python. Los dos principales paquetes utilizados son Pandas y NumPy. Estos dos paquetes disponen de potentes herramientas que permiten a los usuarios realizar fácilmente técnicas clave de manipulación de datos en sus conjuntos de datos.
Gran parte del procesamiento de datos se realiza en Python, por lo que dominar estos paquetes será esencial para cualquier profesional de los datos. Aunque existen muchas técnicas, algunas cosas clave que hay que saber son cómo realizar una limpieza de datos de alto nivel (eliminar los nulos, por ejemplo), fusionar conjuntos de datos y tratar los valores perdidos.
Hay muchas ocasiones en las que hay que limpiarse en Python antes de utilizarlos. Esto podría implicar cosas como eliminar los espacios en blanco finales de las cadenas, eliminar los valores nulos o corregir los tipos de datos, por nombrar algunas.
Cada conjunto de datos es diferente y tendrá sus propias necesidades, así que explora tu conjunto de datos para saber si requiere una limpieza adicional. Practicar diversas técnicas y habilidades de codificación es una gran manera de aprender todas las formas diferentes en que podemos limpiar datos en Python.
Cuando se trata de limpiar cadenas, uno de los muchos problemas es el espacio en blanco de seguimiento/encabezamiento. Esto puede causar problemas al intentar analizar cadenas en función de su longitud, ubicación o coincidencia. La mejor forma de manejar algo así es utilizar el método str.strip() en una serie.
# Example utilizes a pandas series
# If working with a dataframe, call the series using df[col] syntax
s = pd.Series(['1. Ant. ', '2. Bee!\n', '3. Cat?\t', np.nan, 10, True])
# It is important to include the .str or else the method will not work
s.str.strip()Eliminar valores nulos en Pandas es fácil. Hablaremos de cómo rellenar los valores nulos más adelante en este artículo. Puedes utilizar simplemente el método dropna(). Hay parámetros opcionales en este método que te permiten elegir las condiciones exactas que eliminarán una fila/columna, pero el comportamiento por defecto es eliminar cualquier fila con cualquier valor nulo
# For any dataframe
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]}
df.dropna()El método .astype() permite cambiar el tipo de datos de una serie, pero corregir los tipos de datos es un poco más complicado, ya que tienes que asegurarte de que cada valor de tu serie Pandas coincide con ese tipo de datos.
Por ejemplo, convertir una serie que es un objeto en un número entero significa que sabes que cada valor es un número entero. Si hay un único valor que no es un entero, provocará un error en el método. Puedes optar por coaccionarla haciendo nulos los valores no válidos, pero puede que merezca más la pena investigar mientras no se conviertan determinados valores.
Fusionar DataFrames en Pandas es similar a unir en SQL. El comportamiento por defecto de un Pandas merge() es realizar una unión interna. Sin embargo, se unirá a los nulos, así que ten cuidado. Realizar una fusión requiere que utilices una clave determinada. Puedes unir varias columnas o incluso el índice.
# Create two dataframes
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
# merge the df1 DataFrame to the df2 DataFrame using the columns key and rkey as keys
df1.merge(df2, left_on='lkey', right_on='rkey')El código anterior fusionará los dos DataFrames basándose en las claves coincidentes de sus respectivas columnas lkey y rkey. Los valores no coincidentes se descartarán y sólo te quedarán los valores coincidentes. Sin embargo, puedes cambiar el comportamiento de la fusión y elegir también una fusión izquierda/derecha/exterior. Se trata de una potente herramienta que permite a los científicos de datos reunir diferentes conjuntos de datos procedentes de diversas fuentes de datos.
Cuando se trata de valores perdidos, la metodología exacta puede variar en función del caso empresarial. Cuando hablamos de valores perdidos, debemos considerar por qué falta el valor. Si el valor falta debido a errores técnicos, quizá deberíamos centrarnos en solucionar el error técnico antes de analizar nuestros datos y ver si podemos recuperar los datos históricos.
A veces, podemos utilizar el resto de los datos y simplemente ignorar el valor que falta. Si los datos históricos son importantes e irrecuperables, debemos completar los datos que faltan. Hablemos de cómo completar la información que falta.
El método principal para rellenar los datos es utilizar el método fillna() de Pandas. Para los valores de cadena, este método puede utilizarse para rellenar esos nulos, por ejemplo: df.fillna(value=’missing’) ¡que puede ser suficiente! Lo bueno de este método es que podemos ser creativos. Combinando el método fillna() de Pandas con diversos métodos de NumPy, como mean(), median(), y funciones lambda, podemos rellenar matemáticamente nuestros valores perdidos.
Como alternativa, incluso existen métodos Pandas como interpolate() que pueden rellenar los huecos algorítmicamente si tus datos están ordenados (por ejemplo, en función del tiempo). El objetivo es rellenar los datos con la mayor precisión posible para que reflejen los datos reales.
Realizar la gestión de datos en SQL puede ser una forma eficaz de procesar tus datos, especialmente si tu base de datos SQL está en la nube. Esto limita la cantidad de datos procesados por tu máquina local y la cantidad de salida/salida de datos a través de las redes.
El objetivo principal de la gestión de datos en SQL es limitar el alcance de los datos que fluyen a través de nuestros conductos mediante la extracción, transformación y carga adecuadas de los datos. Algunas formas de gestionarlo son filtrar datos, unirlos a tablas de referencia y realizar agregaciones.
La principal forma de filtrar tablas en SQL es mediante la cláusula WHERE. Es bastante sencillo de utilizar, pero puede ser extraordinariamente potente. Las condiciones pueden ser simples declaraciones de igualdad, buscar cadenas similares o incluso utilizar otras subconsultas. También puedes combinar varias cláusulas where utilizando las declaraciones AND y OR.
El filtrado basado en casos sencillos, como la búsqueda de un valor concreto de una columna, puede tener un aspecto similar al siguiente:
SELECT *
FROM sample_table
WHERE sample_col = 23Utilizar sentencias más complejas como LIKE o IN puede aportar flexibilidad a tus cláusulas WHERE. Por ejemplo, la siguiente consulta busca personas cuyo nombre empiece por J gracias al comodín % y también cuyo apellido sea IN la lista proporcionada.
SELECT *
FROM sample_table
WHERE name LIKE ‘J%’ /* looks for people whose name starts with J */
AND last_name IN (‘Smith’, ‘Rockefeller’, ‘Williams’) /* Looks for people whose last name is in this list */Por último, algo como utilizar otras subconsultas puede aportar flexibilidad a tu filtrado. Puede basarse en los resultados de otra tabla. Un ejemplo habitual es buscar una lista de ID de clientes después de una fecha concreta.
SELECT *
FROM sample_table
WHERE customer_id IN (SELECT id FROM reference_table WHERE date >= ‘2024-01-01’)Utilizar una combinación de estas técnicas garantiza que tus entradas de datos son exactamente lo que buscas y que se puede minimizar el tamaño de los conjuntos de datos. Un uso muy potente de los filtros es eliminar los duplicados de tu conjunto de datos y limpiarlo así. Algunas técnicas más avanzadas a implementar son los filtros HAVING para agregaciones y las sentencias QUALIFY con funciones de ventana.
Realizar uniones de tablas nos permite reunir información adicional que podríamos necesitar para nuestros conjuntos de datos. SQL tiene una variedad de uniones como INNER, OUTER, LEFT, y RIGHT. Con las uniones INNER y OUTER, determinamos qué datos se conservan. Las uniones INNER conservan los datos sólo si hay una coincidencia en ambos lados, mientras que OUTER conserva los datos que tampoco coinciden dependiendo del lado desde el que nos unamos (izquierda o derecha).
La unión LEFT mantiene los datos en el lado izquierdo de la unión y la unión RIGHT mantiene los datos en el lado derecho de la unión. Combinas las uniones LEFT y RIGHT con las uniones INNER y OUTER, así como con la especial FULL OUTER JOIN, que simplemente une todos los datos de ambas tablas.
Un ejemplo de unión podría ser:
SELECT *
FROM a
LEFT OUTER JOIN
b
WHERE a.id = b.idLa afirmación anterior tiene la tabla a a la izquierda, ya que es la primera, y la tabla b a la derecha, ya que es la segunda. El LEFT OUTER JOIN dice, une los datos de la tabla a y la tabla b donde a.id = b.id, pero si no hay coincidencia conserva todos los datos de la tabla a. Las uniones son herramientas potentes para aportar datos adicionales que pueden ser necesarios para tu entrada de datos.
Una última herramienta que podemos utilizar en SQL para manejar datos es la cláusula GROUP BY para realizar agregaciones. Esto simplifica los datos y nos permite preprocesarlos un poco antes de enviarlos más adelante. La agregación es una potente herramienta para calcular estadísticas de síntesis. He aquí un ejemplo en el que estamos viendo las ventas totales por ID de cliente.:
SELECT
Customer_ID,
SUM(sales)
FROM sample_table
GROUP BY Customer_IDExisten numerosas funciones de agregación, como SUM, MEAN, MAX y MIN, que nos permiten conocer rápida y fácilmente nuestros datos. Aprovechar las agregaciones simplifica la entrada de datos en las canalizaciones.
Esta sección tratará algunos ejemplos prácticos y casos de uso de las técnicas de manipulación de datos. Los principales objetivos en los que nos centraremos son: la normalización de datos, la fusión de fuentes de datos y el tratamiento de textos.
Es importante normalizar los datos en las mismas unidades. Si trabajas con datos que miden lo mismo en unidades diferentes o con diferencias monetarias, esto podría causar problemas en el análisis.
Vamos a ver un ejemplo sencillo de conversión de distintas monedas a USD en SQL. En primer lugar, supongamos que tenemos dos tablas. La Tabla 1 es una tabla sales que contiene las ventas de productos de varias regiones y la Tabla 2 es una tabla currency_exchange que contiene el tipo de cambio de varias regiones para varios días. Un ejemplo de esta conversión puede ser
SELECT
a.sale_id,
a.region,
CASE WHEN region <> ‘US’
THEN a.sale_price * b.exchange_rate
ELSE a.sale_price
END AS sale_price
FROM sales AS a
LEFT OUTER JOIN
currency_exchange AS b
WHERE a.region = b.regionEsto toma los datos sale_id y region de la tabla sales y se une a la tabla de referencia currency_exchange de la región para que podamos obtener el tipo de cambio. A menudo, puede haber una fecha implicada para que podamos obtener el tipo de cambio del día.
Una parte importante de la gestión de datos consiste en procesarlos para nuestros modelos de aprendizaje automático. Recientemente, muchos modelos se han centrado en el procesamiento del lenguaje natural y un precursor de ello es el análisis de sentimientos a través de datos de texto.
Un paso fundamental para ello es la preparación del texto mediante la normalización y la eliminación de la puntuación. Como la puntuación y las mayúsculas pueden no proporcionar un contexto importante a un modelo de aprendizaje automático, a menudo es mejor normalizar.
Para ello, utilizaremos paquetes básicos de Python y el paquete re. Más abajo encontrarás un ejemplo de eliminación de signos de puntuación, normalización del texto para eliminar las mayúsculas y recorte de espacios vacíos.
# import regex
import re
# input string
test_string = " Python 3.0, released in 2008, was a major revision of the language that is not completely backward compatible and much Python 2 code does not run unmodified on Python 3. With Python 2's end-of-life, only Python 3.6.x[30] and later are supported, with older versions still supporting e.g. Windows 7 (and old installers not restricted to 64-bit Windows)."
# remove whitespaces
no_space_string = test_string.strip()
# convert to lower case
lower_string = no_space_string .lower()
# remove numbers
no_number_string = re.sub(r'\d+','',lower_string)
print(no_number_string)El fragmento de código anterior proporciona una gran base para eliminar espacios en blanco, convertir caracteres a minúsculas y eliminar números/datos no alfabéticos.
La gestión de datos es un componente esencial de la preparación de nuestros datos para los modelos y análisis de aprendizaje automático. Existen multitud de herramientas en Python, como los paquetes pandas y numpy, junto con diversos métodos SQL, como las cláusulas WHERE y GROUP BY, que nos permiten preparar nuestros datos.
El dominio de estas técnicas es fundamental para que cualquier aspirante a profesional de los datos tenga éxito en la profesión. Si quieres profundizar en los temas de la gestión de datos, considera los siguientes recursos:
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Matt Crabtree
10 min
blog
Matt Crabtree
15 min
blog
Javier Canales Luna
12 min
blog
Matt Crabtree
9 min



