
programa
Procesamiento del lenguaje natural en Python
20 h
En el cambiante mundo tecnológico actual, la Inteligencia Artificial destaca como un campo crucial y siempre presente, que se abre paso sin esfuerzo en nuestras experiencias cotidianas. En el centro de esta ola de IA está el Procesamiento del Lenguaje Natural, un área sofisticada que impulsa herramientas conversacionales populares como ChatGPT y Bard.
¿Y si la mayoría de los modelos que hacen posibles estas herramientas estuvieran abiertos a todo el mundo y todos en un único lugar?
Entra: Hugging Face, un cambio de juego en el aprendizaje automático y el procesamiento del lenguaje natural y un agente clave en la democratización de la IA. Gracias al aprendizaje por transferencia, está desempeñando un papel crucial a la hora de hacer más accesible la IA.
A día de hoy, es la biblioteca de PNL en Python más popular, con más de 115.000 estrellas en GitHub, y se ha convertido en una de las plataformas fundamentales para que los entusiastas y profesionales de la IA experimenten, desplieguen y amplíen sus propios modelos.
Tanto si eres un profesional de los datos como un principiante curioso, Hugging Face tiene las herramientas y los recursos para dar vida a tus proyectos de IA, ampliando los límites de lo que es posible con el aprendizaje automático.
Así que, ¡descubramos lo que Hugging Face puede ofrecerte!
También puedes aprender más sobre el uso de modelos de IA de código abierto con Cara Abrazada con nuestro code-along.
Para la mayoría de la gente, Cara de abrazo podría ser simplemente otro emoji disponible en el teclado de su teléfono (🤗)
Sin embargo, en la escena tecnológica, es el GitHub del mundo ML: una plataforma colaborativa rebosante de herramientas que permiten a cualquiera crear, entrenar y desplegar modelos NLP y ML utilizando código de fuente abierta.
¿El giro revolucionario?
Estos modelos ya vienen preentrenados, lo que simplifica aún más el proceso de trituración en PNL. En pocas palabras, los desarrolladores ya no tienen que empezar desde cero; ahora sólo tienen que cargar un modelo preentrenado desde el hub Cara Abrazada, ajustarlo a sus tareas específicas y empezar desde ahí.
Esta facilidad de uso simplifica enormemente el proceso de desarrollo.
Así, Hugging Face es un centro donde convergen científicos de datos, investigadores e ingenieros de ML para intercambiar ideas, buscar apoyo y contribuir a iniciativas de código abierto.
Se describen a sí mismos como:
"La comunidad de IA para construir el futuro".
Esta visión es precisamente uno de los ingredientes secretos del éxito de Hugging Face: tener un enfoque impulsado por la comunidad.
Otra razón de su fuerte crecimiento es la intuitividad de la plataforma. Con una interfaz sencilla, es fácil empezar, tanto para principiantes como para profesionales.
Con el objetivo de albergar la mayor colección de recursos de PNL y ML, Hugging Face se compromete a democratizar la IA y hacerla accesible a una comunidad global.
Fundada en 2016, Hugging Face era una empresa franco-estadounidense que pretendía desarrollar un chatbot interactivo de IA dirigido a los adolescentes. Sin embargo, tras hacer público el modelo que impulsa este chatbot, rápidamente pasó a tener una visión más amplia: dotar a la industria de la IA de herramientas potentes y accesibles.
Imagen del autor.
El lanzamiento en 2018 de su biblioteca transformadora Transformers supuso una de sus mayores y más conocidas contribuciones a la comunidad de la IA, ofreciendo modelos preentrenados como BERT y GPT que se han convertido en básicos en las tareas de PNL.
Hoy, HuggingFace ha transformado totalmente el ecosistema del ML. Su compromiso con la colaboración de código abierto ha catalizado la innovación en PNL, permitiendo el crecimiento y desarrollo comunitario de la tecnología.
La plataforma se ha convertido en un nexo para compartir modelos y conjuntos de datos, impulsando la investigación y las aplicaciones prácticas en IA.
¿Su mantra?
"Democratizar el buen Aprendizaje Automático, un compromiso cada vez".
A través de asociaciones estratégicas y de su dedicación a hacer que las herramientas avanzadas de PNL estén ampliamente disponibles, Hugging Face se ha convertido en parte integrante de la comunidad, ampliando continuamente los límites de la IA y democratizando el acceso a la tecnología de vanguardia.
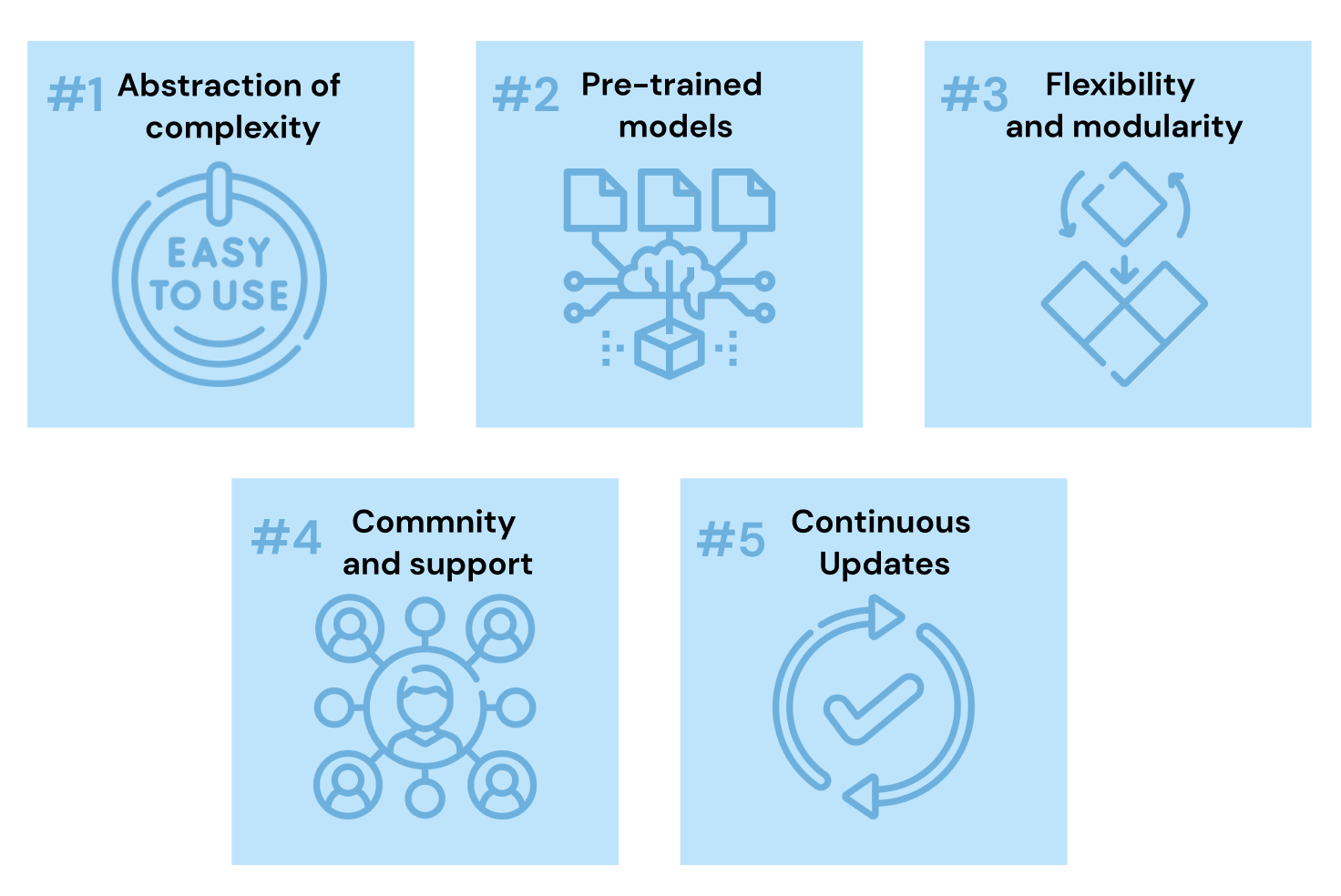
Hugging Face se ha convertido en una piedra angular de la PNL moderna gracias a su conjunto de componentes básicos y funciones que satisfacen una amplia gama de necesidades de procesamiento del lenguaje.
Así que vamos a desglosar cada una de ellas.
La biblioteca Transformers es un conjunto completo de modelos de aprendizaje automático de última generación especialmente diseñados para la PNL. Consiste en una amplia colección de modelos preentrenados optimizados para tareas como clasificación de textos, generación de idiomas, traducción y resumen, entre otras
Hugging Face ha abstraído las tareas habituales de la PNL en un método sencillo de usar, `pipeline()`, una API fácil de usar para realizar una gran variedad de tareas. Estos conductos permiten a los usuarios aplicar fácilmente modelos complejos a problemas del mundo real. Si quieres saber más sobre lo que hay detrás de esta biblioteca, te recomiendo encarecidamente que leas el artículo Una introducción al uso de Transformadores y Cara de Abrazo.
Estos modelos son fácilmente accesibles y personalizables, lo que ha sido revolucionario para desarrolladores e investigadores y ha desempeñado un papel clave en hacer más accesibles los modelos sofisticados de PNL.
Su importancia radica en su capacidad para abstraer las complejidades que entraña el entrenamiento y despliegue de modelos de PNL, facilitando a los profesionales la implementación de funciones avanzadas de PNL con un código mínimo.
La biblioteca permite aprovechar modelos preentrenados sin profundizar en los algoritmos subyacentes.
La biblioteca Transformadores simplifica la aplicación de los modelos de PNL de varias formas fundamentales:
Si quieres comprobar de primera mano todo el trabajo que nos evita la biblioteca de transformadores, aprende a desplegar un modelo de PNL con Construir un transformador con PyTorch.
El Model Hub es la cara de la comunidad, una plataforma en la que miles de modelos y conjuntos de datos están a tu alcance. Es una función innovadora que permite a los usuarios compartir y descubrir modelos aportados por la comunidad, promoviendo un enfoque colaborativo del desarrollo de la PNL.
Puedes ir a comprobarlo en su sitio web oficial. Allí puedes seleccionar fácilmente el Centro de Modelos haciendo clic en los botones Modelos del navegador, y debería aparecerte una vista como la siguiente:
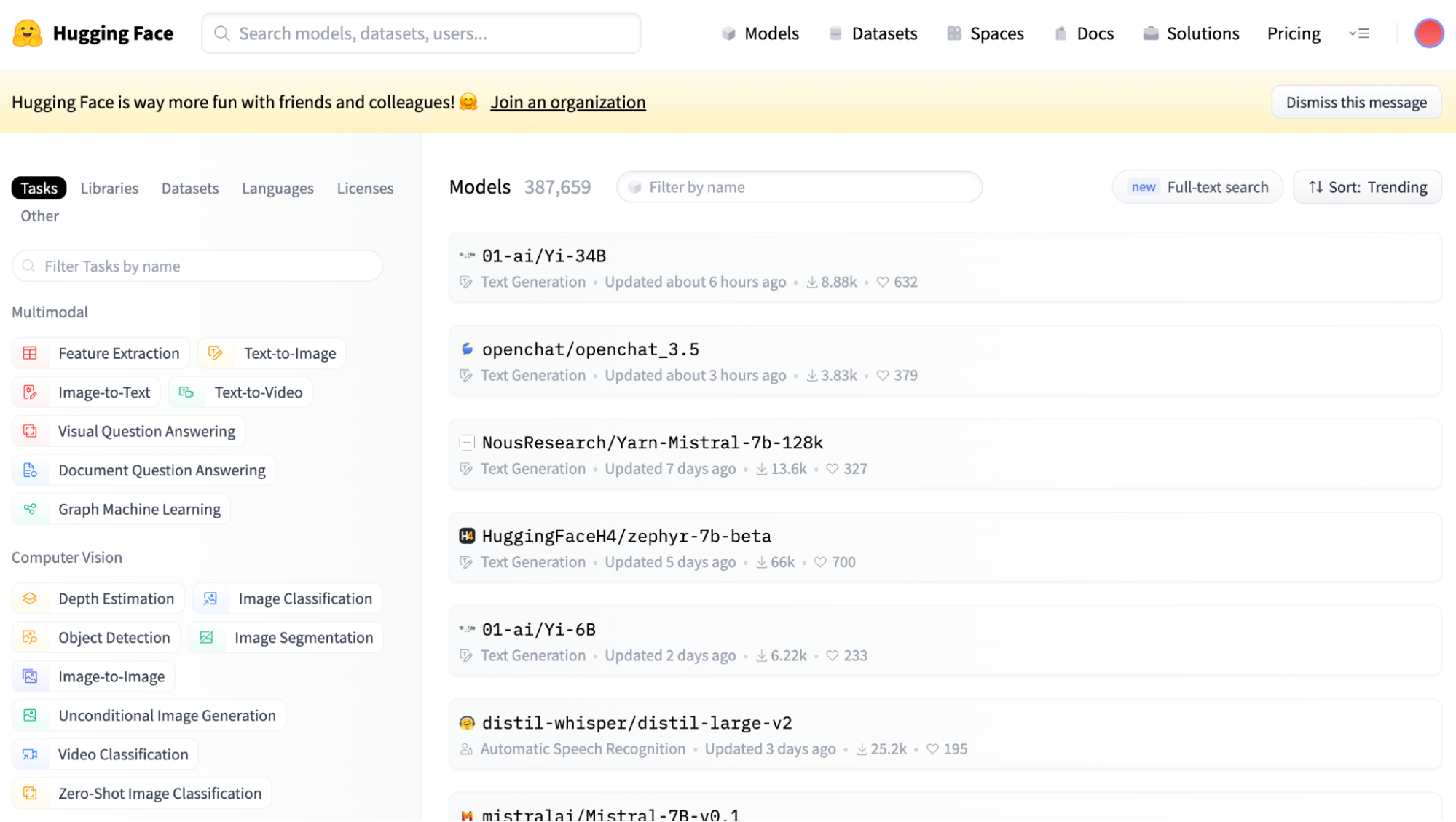
Captura de pantalla de la vista principal de Hugging Face Model Hub.
Como puedes ver, en la barra lateral izquierda, hay múltiples filtros relativos a la tarea principal a realizar.
Contribuir al Model Hub es muy sencillo gracias a las herramientas de Hugging Face, que guían a los usuarios en el proceso de subir sus modelos. Una vez aportados, estos modelos están disponibles para que los utilice toda la comunidad, ya sea directamente a través del hub o mediante la integración con la biblioteca de Transformers de Cara Abrazada.
Esta facilidad de acceso y contribución fomenta un ecosistema dinámico en el que los modelos más avanzados se perfeccionan y amplían constantemente, proporcionando una base rica y colaborativa para el avance de la PNL.
Los tokenizadores son cruciales en la PNL, ya que se encargan de convertir el texto en un formato que los modelos de aprendizaje automático puedan entender, lo cual es esencial para procesar diferentes idiomas y estructuras de texto.
Se encargan de descomponer el texto en tokens -unidades básicas como palabras, subpalabras o caracteres-, preparando así los datos para que los procesen los modelos de aprendizaje automático. Estos tokens son los bloques de construcción que permiten a los modelos comprender y generar el lenguaje humano.
También facilitan la transformación de los tokens en representaciones vectoriales para la entrada del modelo y manejan el relleno y el truncamiento para longitudes de secuencia uniformes.
Hugging Face proporciona una gama de tokenizadores fáciles de usar, optimizados para su biblioteca Transformers, que son clave para el preprocesamiento sin fisuras del texto. Puedes leer más sobre la Tokenización en otro artículo.
Otro componente clave es la biblioteca de Conjuntos de Datos de Caras Abrazadas, un vasto repositorio de conjuntos de datos de PLN que sirven de apoyo al entrenamiento y la evaluación comparativa de los modelos de ML.
Esta biblioteca es una herramienta crucial para los desarrolladores en este campo, ya que ofrece una variada colección de conjuntos de datos que pueden utilizarse para entrenar, probar y comparar cualquier modelo de PLN en una amplia variedad de tareas.
Una de las principales ventajas que presenta es su interfaz sencilla y fácil de usar. Aunque puedes examinar y explorar todos los conjuntos de datos en el Hugging Face Hub, para utilizarlos en tu código, han adaptado la biblioteca de conjuntos de datos que te permite descargar cualquier conjunto de datos sin esfuerzo.
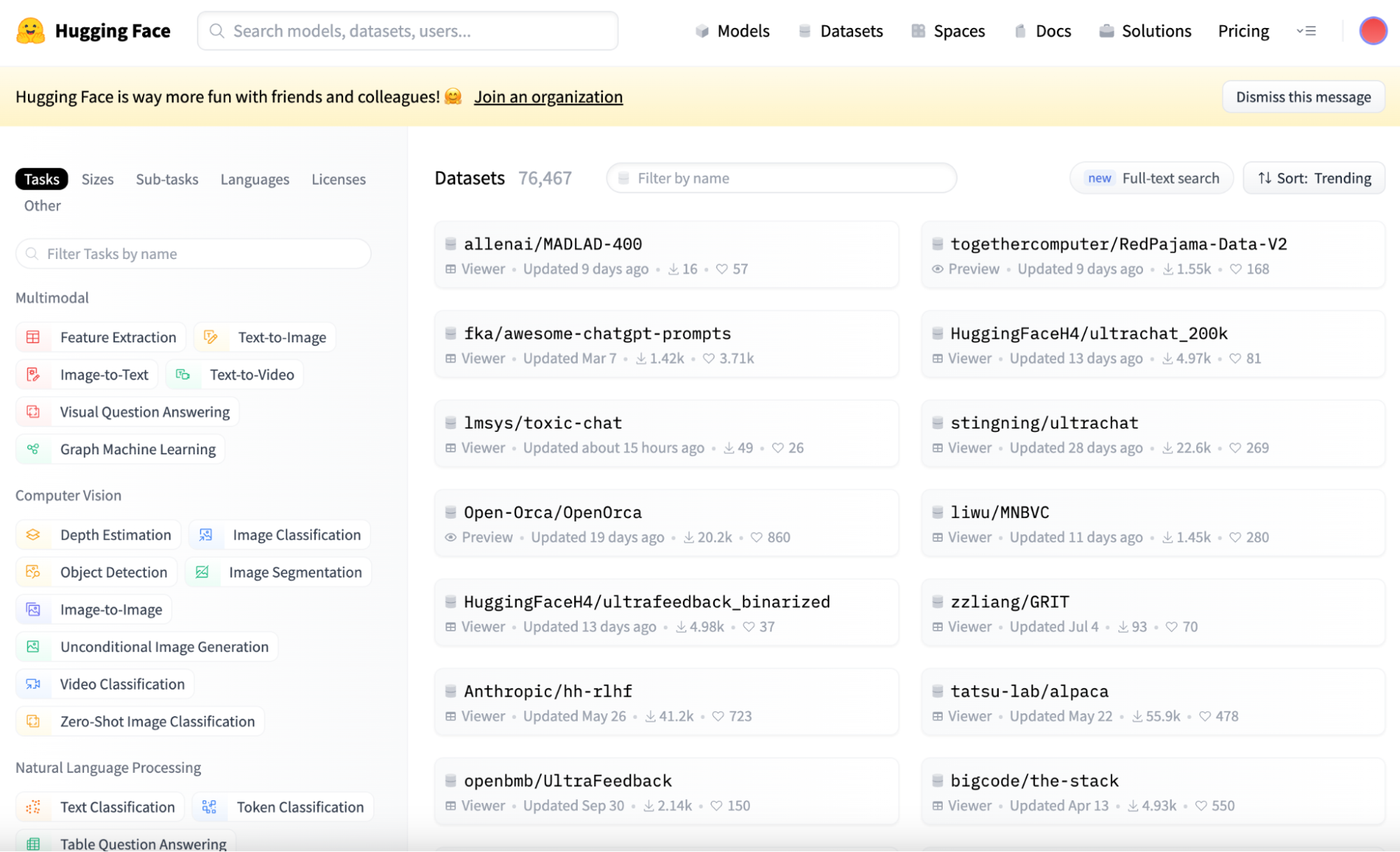
Captura de pantalla de la vista principal de los Conjuntos de Datos de Caras Abrazadas.
Incluye conjuntos de datos para tareas comunes como la clasificación de textos, la traducción y la respuesta a preguntas, así como conjuntos de datos más especializados para retos únicos en este campo.
Así que, ahora que todos estamos de acuerdo y entendemos los conceptos básicos de Abrazar a la Cara, vamos a intentar averiguar cómo utilizar esta pequeña joya tecnológica.
Esta guía te guiará brevemente a través de los aspectos básicos para empezar a utilizar Abrazar a la Cara, incluyendo la instalación, el uso de modelos preentrenados, el ajuste fino y la compartición de tus modelos con la comunidad.
En primer lugar, debes combinar la biblioteca transformers con tu biblioteca de aprendizaje profundo favorita, ya sea TensorFlow o PyTorch.
La biblioteca de transformadores puede instalarse fácilmente utilizando pip, el instalador de paquetes de Python.
pip install transformers
Para disponer de toda la capacidad, debes instalar también la biblioteca datasets y la biblioteca tokenizers.
pip install tokenizers, datasets
El centro de modelos de Hugging Face ofrece una enorme colección de modelos preentrenados que puedes utilizar para una amplia gama de tareas de PNL. Descubramos cómo utilizar nuestro primer modelo preentrenado.
1. Selecciona un Modelo Preentrenado: En primer lugar, tienes que seleccionar un modelo preentrenado. Para ello, vamos al Centro de Modelos.
Imagina que queremos deducir el sentimiento correspondiente a una cadena de texto. Así que podemos examinar fácilmente sólo los modelos que realizan tareas de "Clasificación de textos" seleccionando el botón Clasificación de textos de la barra lateral izquierda.
Los modelos de Cara de Abrazo siempre aparecían ordenados por Trending. Normalmente, los resultados más altos son los más utilizados. Por tanto, seleccionamos el segundo resultado, que es el modelo de análisis de sentimientos más utilizado.
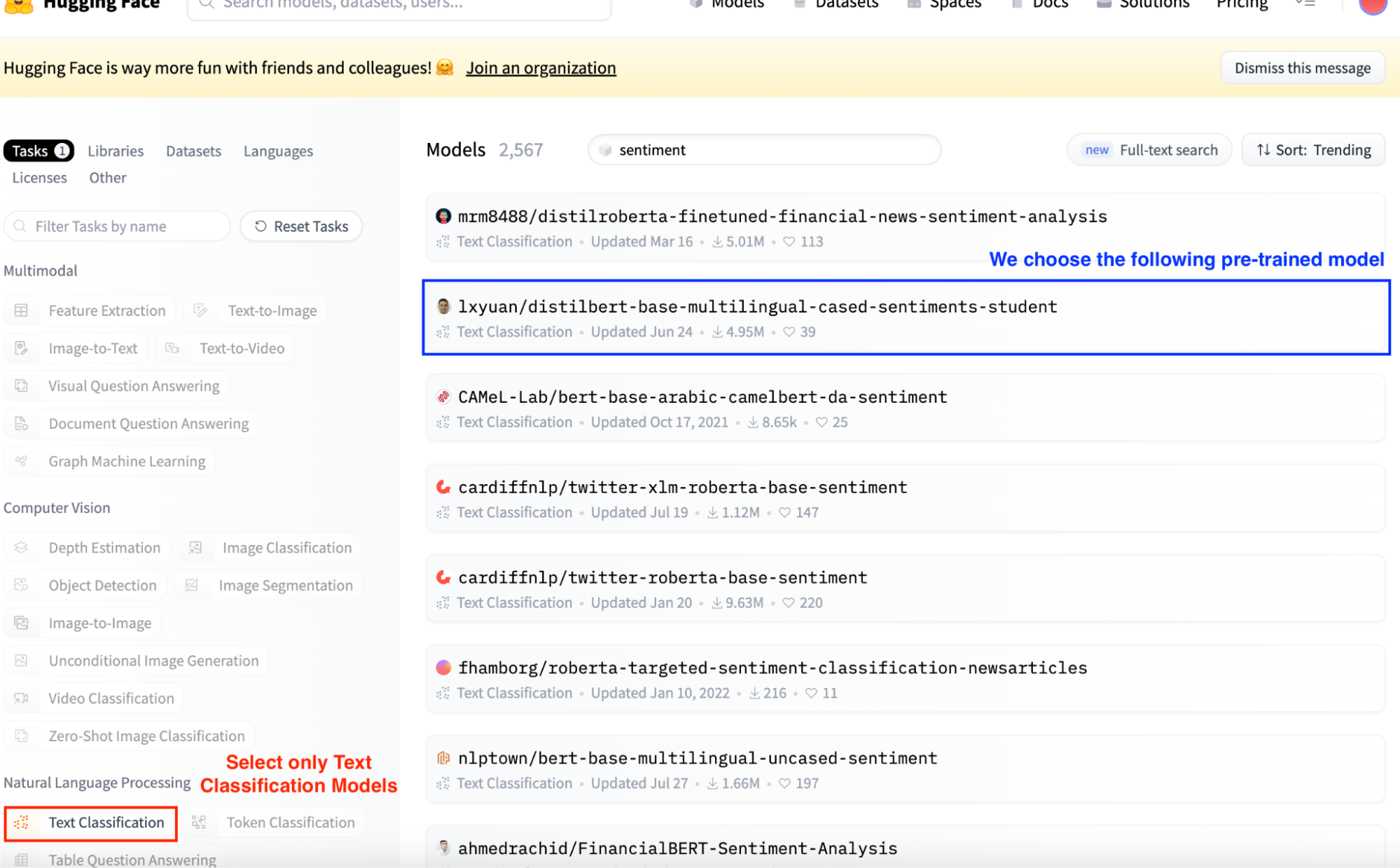
Captura de pantalla de la vista principal de Hugging Face Model Hub. Selección de modelos de clasificación de textos.
Para utilizarlo, tenemos que copiar el nombre correspondiente del modelo. Se encuentra en la parte superior de su vista específica.
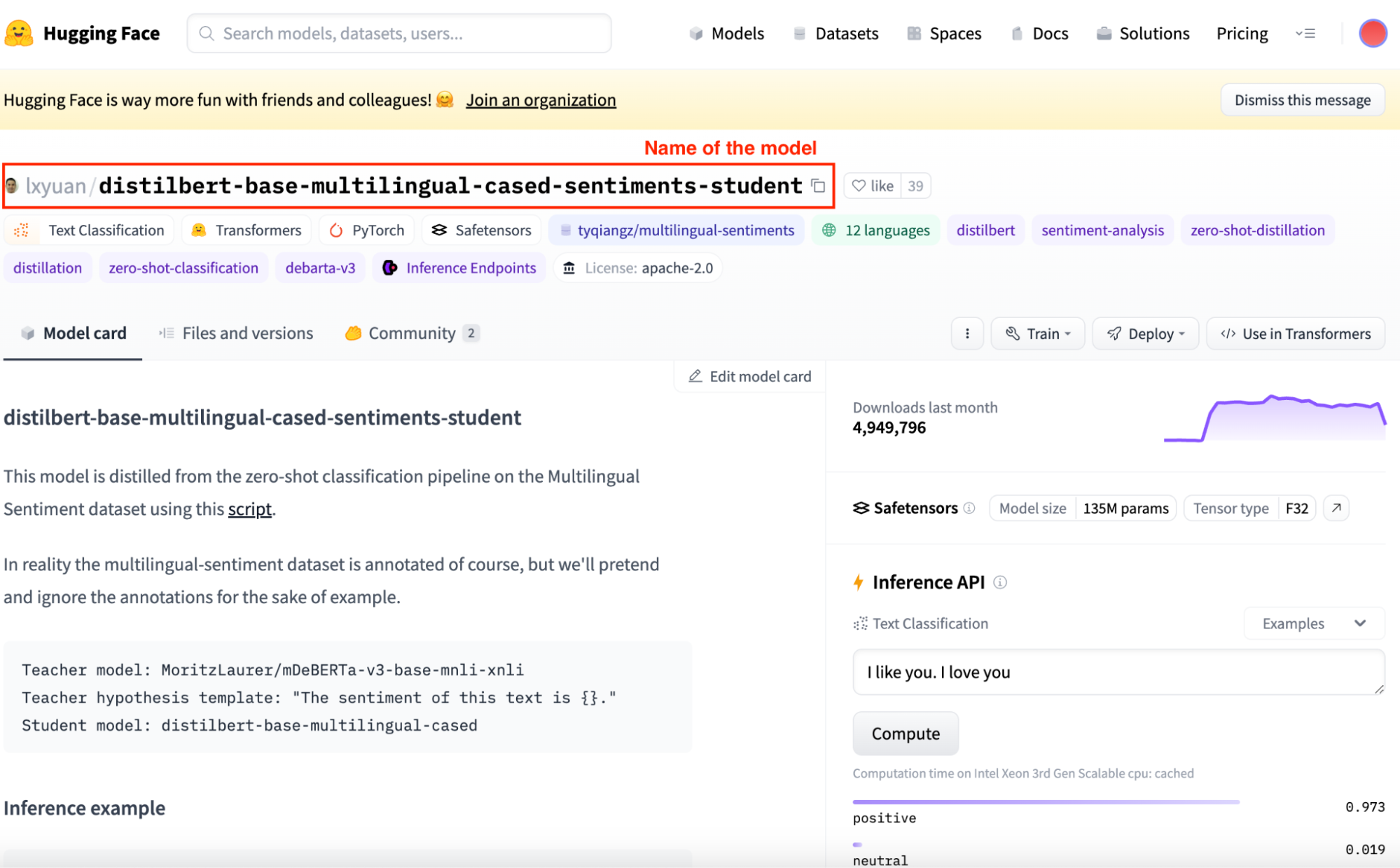
Captura de pantalla de la vista del modelo específico del Hub de Cara Abrazada.
1. Carga un modelo preentrenado: Ahora que ya sabemos qué modelo utilizar, vamos a utilizarlo en Python. Primero tenemos que importar las clases AutoTokenizer y AutoModelForSequenceClassification de transformers.
El uso de estas clases AutoModel deducirá automáticamente la arquitectura del modelo a partir del nombre del modelo.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "lxyuan/distilbert-base-multilingual-cased-sentiments-student"
# We call define a model object
model = AutoModelForSequenceClassification.from_pretrained(model_name)
2. Prepara tu aportación: Cargar un tokenizador para nuestro modelo, en este caso, la biblioteca de transformadores facilita el proceso ya que infiere el tokenizador a utilizar a partir del nombre del modelo que hemos elegido.
#We call the tokenizer class
tokenizer = AutoTokenizer.from_pretrained(model_name)
3. Ejecuta el modelo: Genera un objeto pipeline con el modelo elegido, el tokenizador y la tarea a realizar. En nuestro caso, un análisis de sentimientos. Si inicializas el objeto clasificador con la tarea, la clase pipeline lo rellenará con los valores por defecto, aunque no sea recomendable en producción.
# Initializing a classifier with a model and a tokenizer
classifier = pipeline("sentiment-analysis", model = model, tokenizer = tokenizer)
# When passing only the task, the pipeline command inferes both the model and tokenizer.
classifier = pipeline("sentiment-analysis")
Podemos ejecutar este modelo introduciendo algunos datos de entrada.
output = classifier("I've been waiting for this tutorial all my life!")
4. Interpreta los resultados: El modelo devolverá un objeto que contiene varios elementos según la clase del modelo. Por ejemplo, para este ejemplo de análisis de sentimientos, obtendremos:
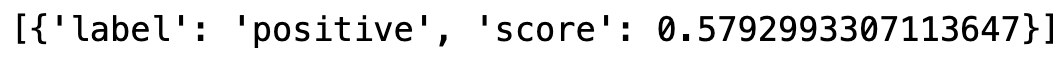
Salida obtenida.
El ajuste fino es el proceso de tomar un modelo preentrenado y actualizar sus parámetros entrenándolo en un conjunto de datos específico para tu tarea. Esto te permite aprovechar las representaciones aprendidas del modelo y adaptarlas a tu caso de uso.
Imagina que necesitamos utilizar un modelo clasificador de texto para inferir sentimientos a partir de una lista de tweets. Una pregunta natural que me viene a la mente es ¿Funcionará correctamente este modelo preentrenado?
Para asegurarnos de que lo hace, podemos aprovechar el ajuste fino entrenando un modelo de Cara de Abrazo previamente entrenado con un conjunto de datos que contenga tuits y sus sentimientos correspondientes, de modo que mejore el rendimiento.
He aquí un ejemplo básico de puesta a punto de un modelo de clasificación de secuencias:
1. Elige un modelo preentrenado y un conjunto de datos: Selecciona un modelo de arquitectura adecuado a tu tarea. En este caso, queremos seguir utilizando el mismo modelo de análisis de sentimientos. Sin embargo, ahora necesitamos algunos datos para entrenar nuestro modelo.
Y aquí es precisamente donde entra en juego la biblioteca datasets. Podemos comprobar todos los conjuntos de datos en el Centro de Modelos y encontrar el que mejor se adapte a nosotros.
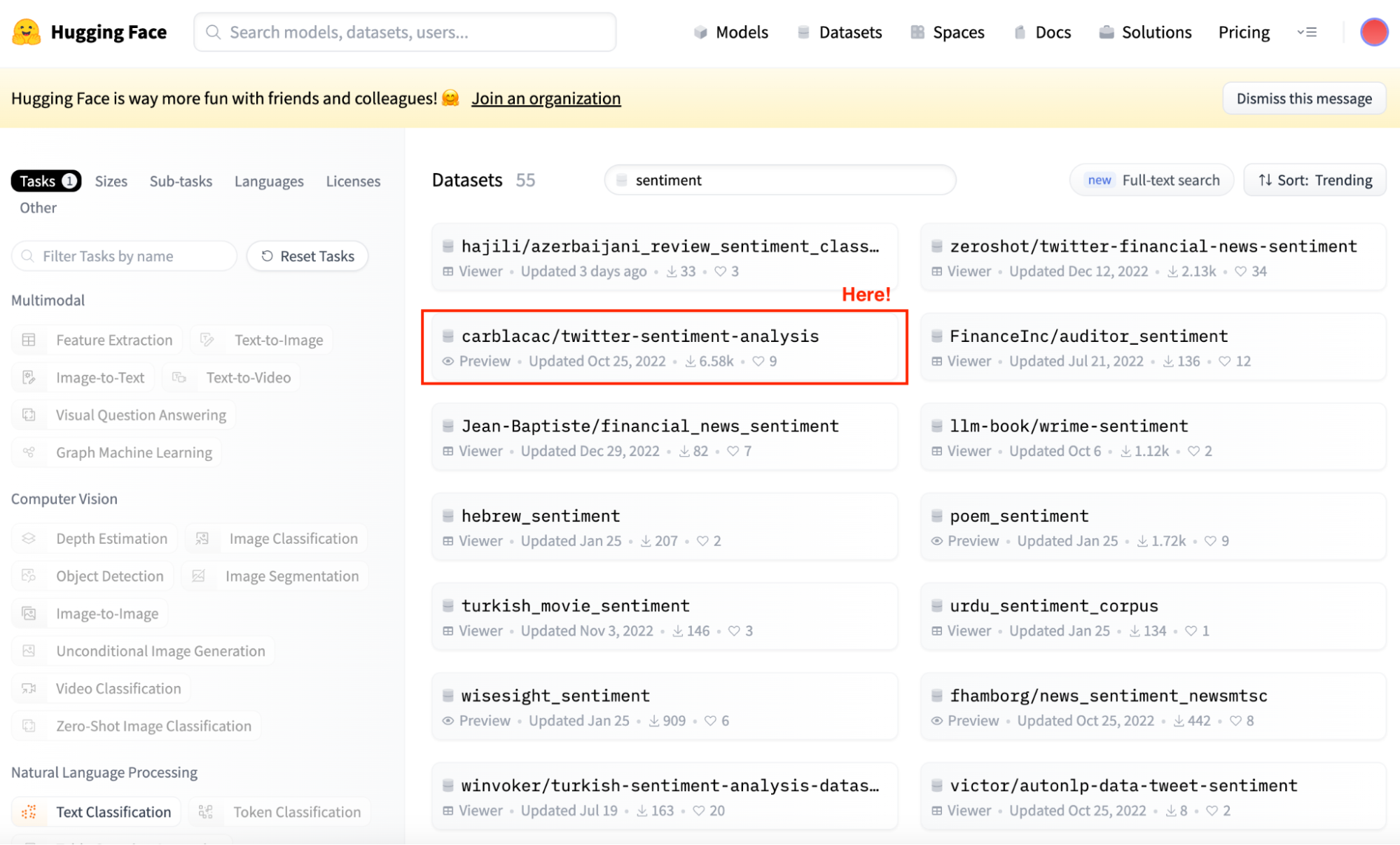
Captura de pantalla de la vista principal de Hugging Face Datasets Hub. Selección de conjuntos de datos de Análisis de Sentimiento.
Ahora que ya sé qué conjunto de datos elegir, podemos inicializar simplemente tanto el modelo como el conjunto de datos.
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
Si comprobamos el conjunto de datos que acabamos de descargar, es un diccionario que contiene un subconjunto para entrenamiento y otro para pruebas. Si convertimos el subconjunto de entrenamiento en un marco de datos, tiene el siguiente aspecto:
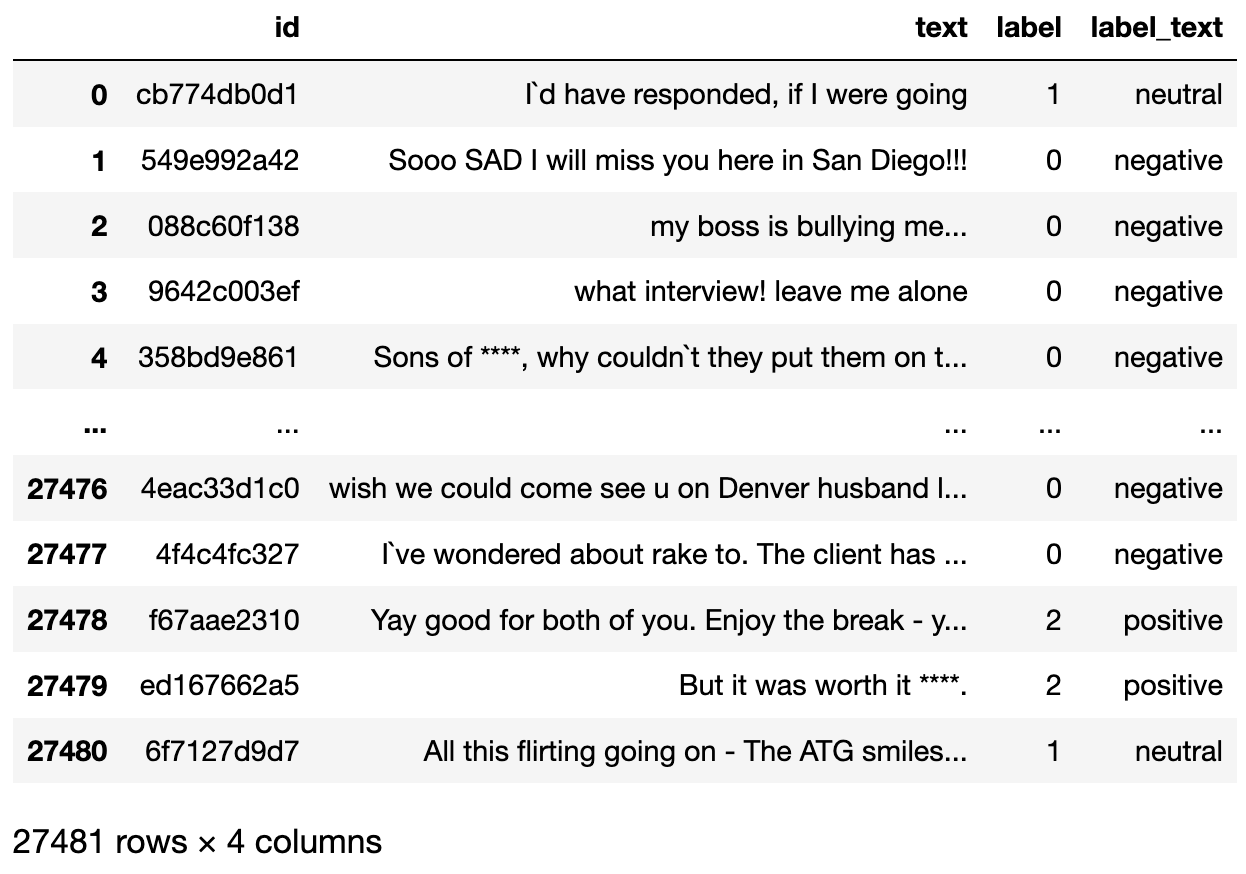
El conjunto de datos que se va a utilizar.
2. Prepara tu conjunto de datos: Ahora que ya tenemos nuestro conjunto de datos, necesitamos un tokenizador que lo prepare para ser analizado por nuestro modelo. La variable texto de nuestro conjunto de datos debe tokenizarse para que podamos utilizarla para afinar nuestro modelo.
Por eso, el segundo paso consiste en cargar un Tokenizer preentrenado y tokenizar nuestro conjunto de datos para poder utilizarlo en el ajuste fino.
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
3. Construye un conjunto de datos PyTorch con codificaciones: El tercer paso consiste en generar un conjunto de datos de entrenamiento y de prueba. El conjunto de entrenamiento se utilizará para afinar nuestro modelo, mientras que el conjunto de pruebas se utilizará para evaluarlo.
Normalmente, el proceso de ajuste requiere mucho tiempo. Para facilitar el tutorial, tomamos muestras aleatorias de ambos conjuntos de datos para reducir el tiempo de cálculo.
from datasets import load_dataset
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
4. Afina el modelo: Nuestro último paso es configurar los argumentos de entrenamiento e iniciar el proceso de entrenamiento. La biblioteca de transformadores contiene la clase trainer(), que se encarga de todo.
Primero definimos los argumentos de entrenamiento junto con la estrategia de evaluación. Una vez definido todo, podemos entrenar fácilmente el modelo con el comando train().
from transformers import Trainer, TrainingArguments
import numpy as np
training_args = TrainingArguments(output_dir="trainer_output", evaluation_strategy="epoch")
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
5. Evalúa el modelo: Tras el entrenamiento, evalúa el rendimiento del modelo en un conjunto de validación o prueba. De nuevo, la clase Entrenador ya contiene un método Evaluar que se encarga de esto.
import evaluate
trainer.evaluate()
Nuestro modelo afinado presenta una precisión del 70%.
Ahora que ya hemos mejorado nuestro modelo, ¿cómo podemos compartirlo con la comunidad? Esto nos lleva a nuestro último paso.
Una vez que hayamos afinado tu modelo, tal vez quieras compartirlo con la comunidad.
Abrazar la Cara hace que este proceso sea sencillo. En primer lugar, tienes que instalar la biblioteca huggingface_hub.
Un requisito para este último paso es tener un token activo para poder conectarte a tu cuenta de Hugging Face. Puedes conseguirlo fácilmente siguiendo esta pauta. Al trabajar en un Jupyter Notebook, podemos importar fácilmente la biblioteca notebook_login.
from huggingface_hub import notebook_login
notebook_login()
Esto generará un inicio de sesión dentro de nuestro Jupyter Notebook. Sólo tenemos que enviar nuestro token, y nuestro cuaderno se conectará a nuestra cuenta de cara abrazadora.
Ahora sólo tenemos que subir nuestro modelo utilizando el comando push_to_hub.
finetuned_model.push_to_hub("my-awesome-model")
Y, después de esto, el modelo estará disponible para todos en nuestro perfil Cara Abrazada.
Si queremos estandarizar cualquier proceso de PNL, con Cara de Abrazo suele implicar tres sencillos pasos que ocupan menos de cinco líneas de código:
1. Define un objeto modelo con la clase de canalización (y el modelo y el tokenizador correspondientes).
2. Define el texto de entrada o pregunta.
3. Ejecuta el modelo preentrenado con nuestra entrada y observa la salida.
La clasificación de textos es una tarea fundamental en PNL. Consiste en asignar a cada texto de entrada una o varias categorías. Puede utilizarse para diversas aplicaciones, como la detección de spam, el análisis de sentimientos, el etiquetado de temas, etc.
Puedes observar en el siguiente código de ejemplo cómo, con sólo los tres sencillos pasos indicados en el apartado anterior, podemos implementar un modelo de clasificación de texto.
# We import the pipeline module from the transformers library
from transformers import pipeline
# We load the pre-trained text classification model.
classifier = pipeline("text-classification",model='lxyuan/distilbert-base-multilingual-cased-sentiments-student')
# Input to be classified
input_ = "I absolutely love the transformers library!"
# Perform classification
output_ = classifier(input_)
# Observer the result
print(output_)
Fácil, ¿verdad?
Así que pasemos al segundo caso de uso y uno de los más abusados de todos los tiempos.
La mayoría de vosotros ya estaréis familiarizados con ChatGPT o Google Bard, que son herramientas que generan texto a partir de una solicitud de entrada. Este proceso se denomina "Generación de Texto", y es un aspecto fascinante de la PNL, en el que un modelo produce texto similar al humano a partir de una entrada inicial.
Tiene una amplia gama de aplicaciones, desde crear respuestas de chatbot hasta generar escritura creativa.
La idea central es entrenar un modelo en un gran corpus de texto, permitiéndole aprender patrones, estilos y estructuras del lenguaje. Como puedes imaginar, la parte más cara es precisamente el entrenamiento del modelo.
Sin embargo, Cara de Abrazo nos permite implementar un modelo de este tipo en sólo cinco líneas de código, igual que en el caso anterior.
Mira el ejemplo siguiente:
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
prompt = "In a world dominated by AI,"
generated_text = generator(prompt, max_length=50)[0]['generated_text']
print(generated_text)
La respuesta a preguntas, comúnmente conocida como QA, es un campo de la PNL centrado en la construcción de sistemas que respondan automáticamente a preguntas formuladas por humanos en lenguaje natural.
Los sistemas de control de calidad se utilizan ampliamente en diversas aplicaciones, como asistentes virtuales, atención al cliente y sistemas de recuperación de información.
Los sistemas de garantía de calidad pueden clasificarse en dos tipos:
Estos sistemas suelen utilizar una combinación de comprensión del lenguaje natural para interpretar la pregunta y recuperación de información para encontrar respuestas relevantes.
De nuevo, implantar uno de estos modelos utilizando Cara de Abrazo es rápido y fácil.
from transformers import pipeline
qa_pipeline = pipeline('question-answering', model='distilbert-base-uncased-distilled-squad')
context = """Paris is the capital and most populous city of France. The city has an area of 105 square kilometers and a population of 2,140,526 residents."""
question = "What is the population of Paris?"
answer = qa_pipeline(question=question, context=context)
print(answer)
El último caso de uso es la traducción. La traducción automática es un subcampo de la lingüística computacional que se centra en la traducción de texto o voz de una lengua a otra mediante software. Con la llegada del aprendizaje profundo, la traducción automática ha avanzado mucho, sobre todo con modelos como la Traducción Automática Neuronal (NMT), que utilizan grandes redes neuronales.
Los sistemas NMT modernos, a diferencia de los modelos de traducción tradicionales basados en reglas o estadísticos, aprenden a traducir entrenándose con grandes conjuntos de datos de texto bilingüe. Utilizan arquitecturas secuencia a secuencia, en las que una parte de la red codifica el texto de origen y otra lo descodifica en la lengua de destino, a menudo con una fluidez y precisión impresionantes.
Un ejemplo sencillo utilizando Cara de Abrazo sería:
from transformers import pipeline
# Load the translation pipeline for English to Spanish
translator = pipeline('translation_en_to_de')
# Text to translate from English to Spanish
text_to_translate = "This is a great day for science!"
# Perform the translation
translation = translator(text_to_translate, max_length=40)
# Print the translated text
print(translation[0]['translation_text'])
La Cara de Abrazo ha surgido como una fuerza transformadora en el campo de la inteligencia artificial y el procesamiento del lenguaje natural. Su completo conjunto de herramientas, que incluye la revolucionaria biblioteca Transformers, el centro colaborativo Model Hub y la extensa biblioteca Datasets, ha democratizado el acceso a las capacidades avanzadas de PNL.
Al fomentar un entorno en el que la innovación se comparte y se construye colectivamente, Hugging Face no sólo está contribuyendo al avance de la IA, sino que también está dando forma a un futuro en el que la tecnología es más accesible, inclusiva y poderosa.
Mientras seguimos presenciando y participando en la revolución de la IA, Cara Abrazada nos recuerda que los avances tecnológicos más profundos son los que se abren, se comparten y se construyen juntos.
No se trata sólo de crear máquinas más inteligentes, sino de fomentar una comunidad más inteligente y conectada de desarrolladores, investigadores y entusiastas deseosos de superar los límites de lo posible.
¡Comienza hoy tu viaje a la IA y la PNL!
programa
programa
Curso