Course
Text Mining with Bag-of-Words in R
4 hr
44.3K
Text classification is a common NLP task used to solve business problems in various fields. The goal of text classification is to categorize or predict a class of unseen text documents, often with the help of supervised machine learning.
Similar to a classification algorithm that has been trained on a tabular dataset to predict a class, text classification also uses supervised machine learning. The fact that text is involved in text classification is the main distinction between the two.
You can also perform text classification without using supervised machine learning. Instead of algorithms, a manual rule-based system can be designed to perform the task of text classification. We’ll compare and review the pros and cons of rule-based and machine-learning-based text classification systems in the next section.
If you want to learn more about supervised machine learning, check out our separate article.
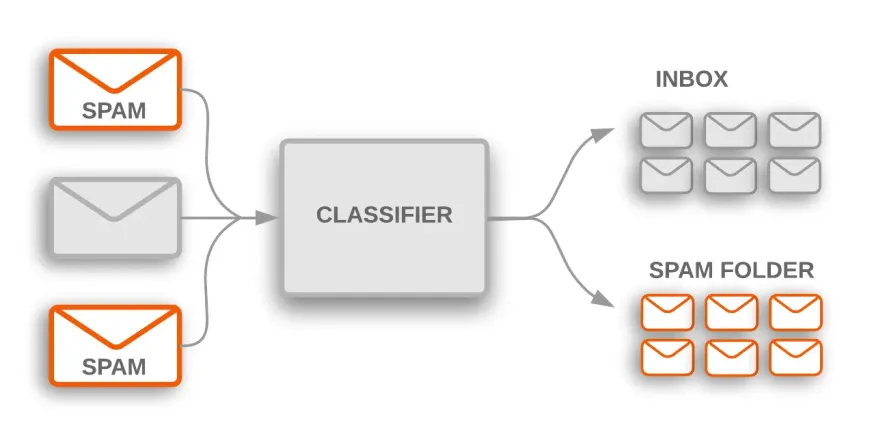
There are many practical use cases for text classification across many industries. For example, a spam filter is a common application that uses text classification to sort emails into spam and non-spam categories.
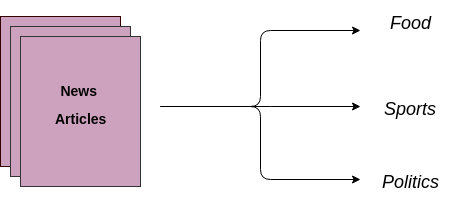
Another use case is to automatically assign text documents into predetermined categories. A supervised machine learning model is trained on labeled data, which includes both the raw text and the target. Once a model is trained, it is then used in production to obtain a category (label) on the new and unseen data (articles/blogs written in the future).
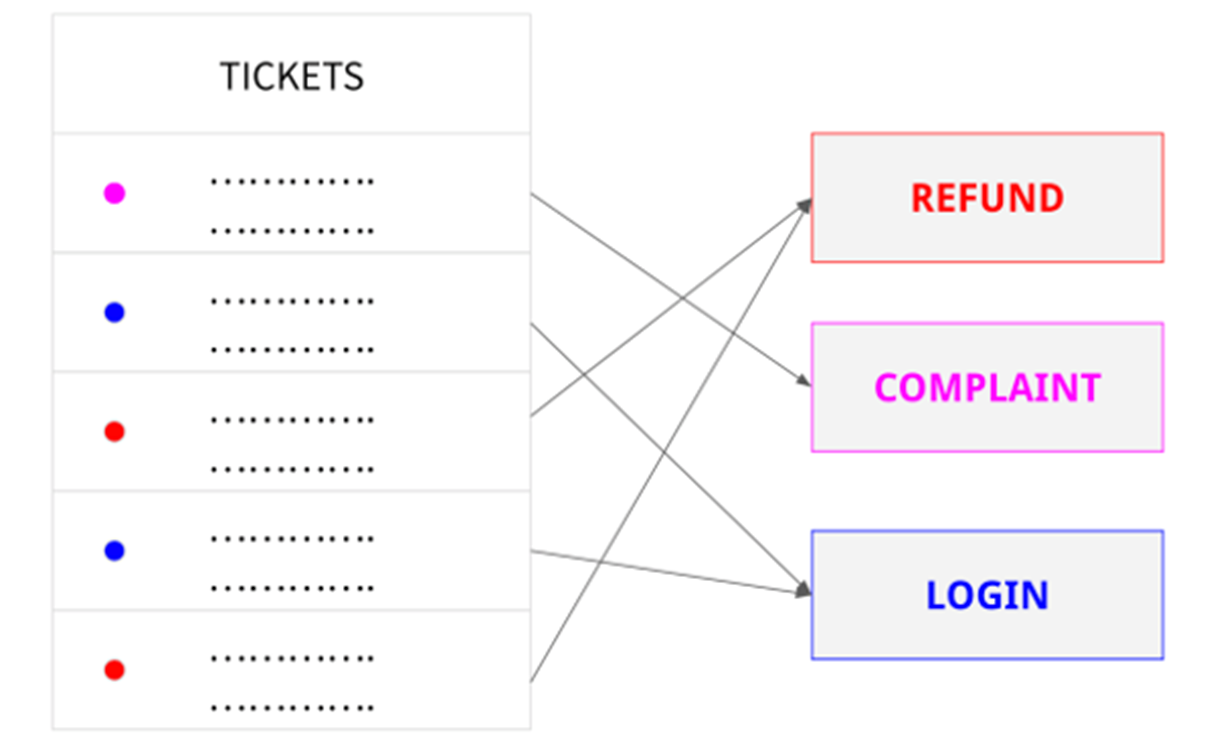
A company might use text classification to automatically categorize customer support requests by topic or to prioritize and route requests to the appropriate department.
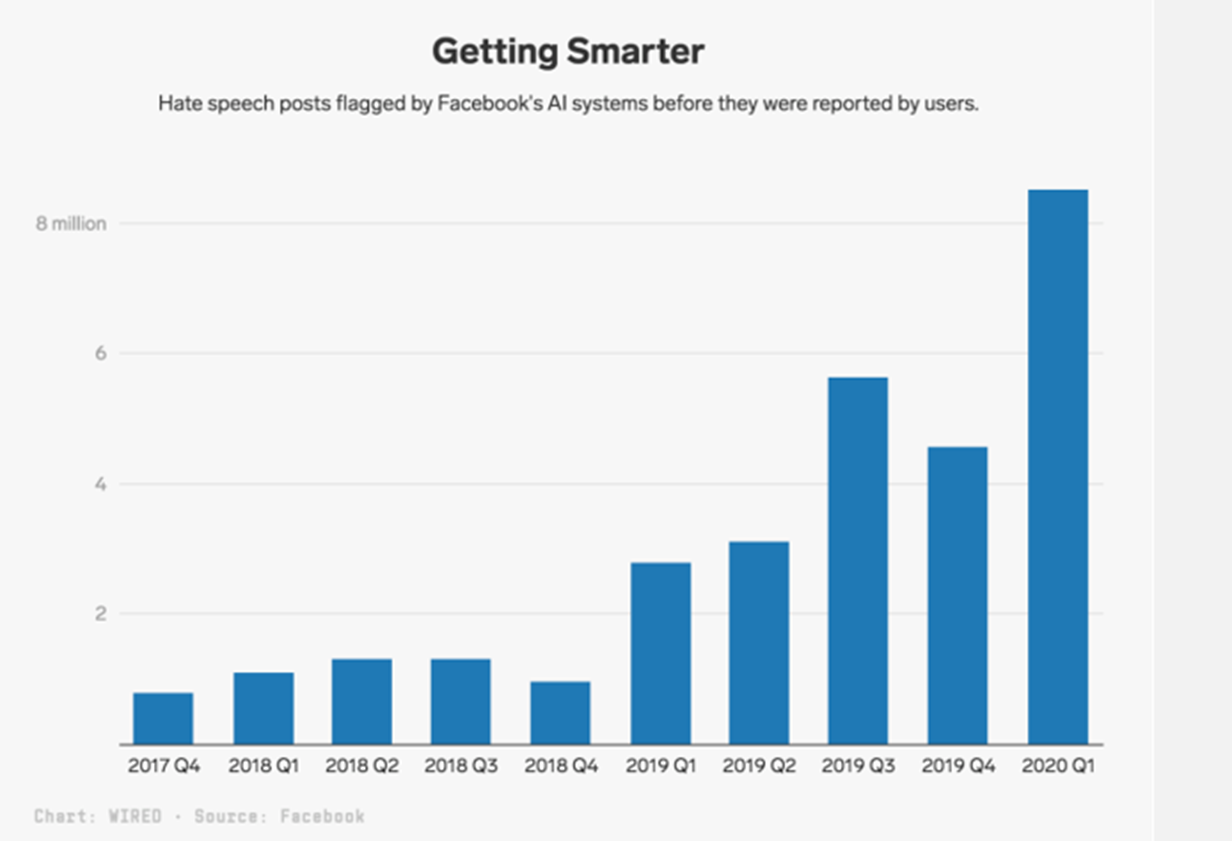
With over 1.7 billion daily active users, Facebook inevitably has content created on the site that is against the rules. Hate speech is included in this undesirable content.
Facebook tackles this issue by requesting a manual review of postings that an AI text classifier has identified as hate speech. Postings that were flagged by AI are examined in the same manner as posts that users have reported. In fact, in just the first three months of 2020, the platform removed 9.6 million items of content that had been classified as hate speech.
There are mainly two types of text classification systems; rule-based and machine learning-based text classification.
Rule-based techniques use a set of manually constructed language rules to categorize text into categories or groups. These rules tell the system to classify text into a particular category based on the content of a text by using semantically relevant textual elements. An antecedent or pattern and a projected category make up each rule.
For example, imagine you have tons of new articles, and your goal is to assign them to relevant categories such as Sports, Politics, Economy, etc.
With a rule-based classification system, you will do a human review of a couple of documents to come up with linguistic rules like this one:
Rule-based systems can be refined over time and are understandable to humans. However, there are certain drawbacks to this strategy.
These systems, to begin with, demand in-depth expertise in the field. They take a lot of time since creating rules for a complicated system can be difficult and frequently necessitates extensive study and testing.
Given that adding new rules can alter the outcomes of the pre-existing rules, rule-based systems are also challenging to maintain and do not scale effectively.
Machine learning-based text classification is a supervised machine learning problem. It learns the mapping of input data (raw text) with the labels (also known as target variables). This is similar to non-text classification problems where we train a supervised classification algorithm on a tabular dataset to predict a class, with the exception that in text classification, the input data is raw text instead of numeric features.
Like any other supervised machine learning, text classification machine learning has two phases; training and prediction.
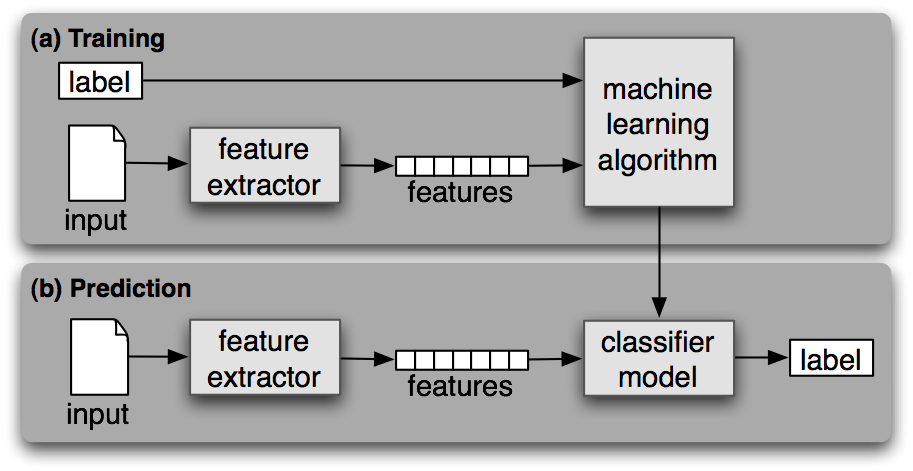
A supervised machine learning algorithm is trained on the input-labeled dataset during the training phase. At the end of this process, we get a trained model that we can use to obtain predictions (labels) on new and unseen data.
Once a machine learning model is trained, it can be used to predict labels on new and unseen data. This is usually done by deploying the best model from an earlier phase as an API on the server.
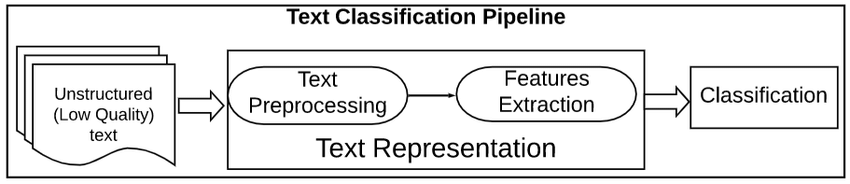
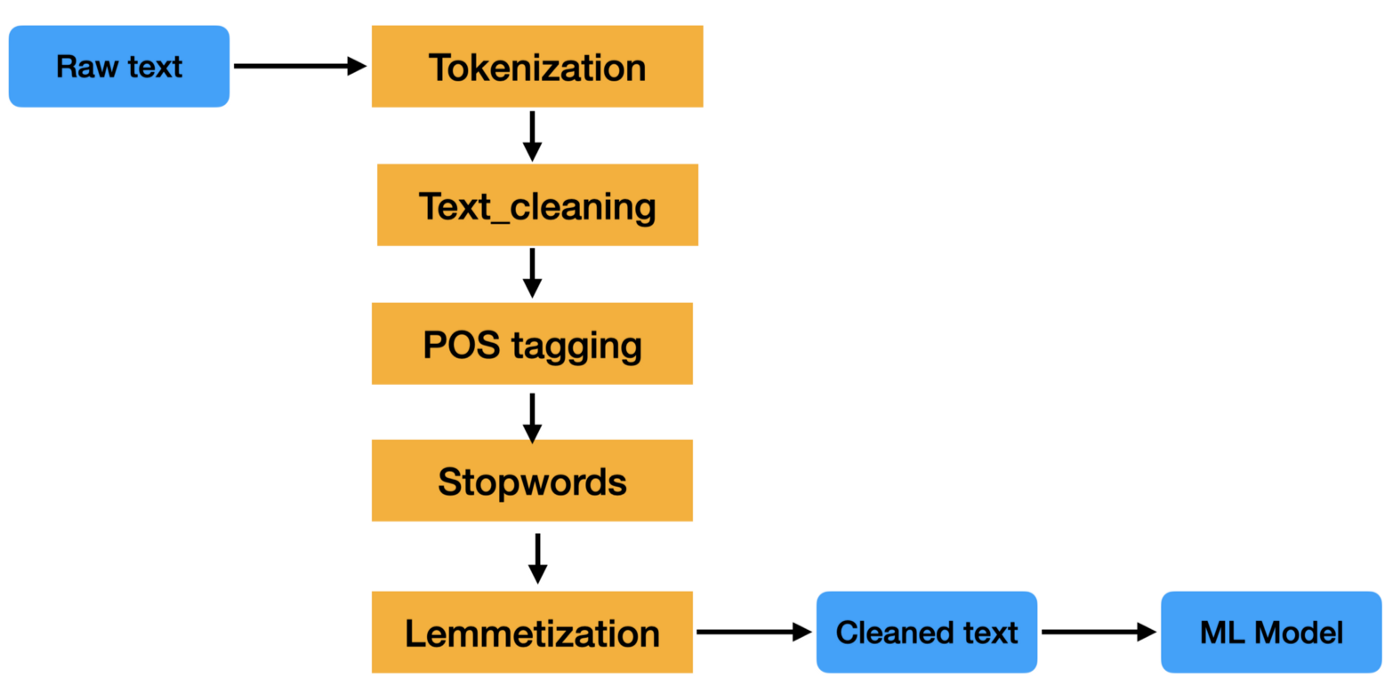
Preprocessing text data is an important step in any natural language processing task. It helps in cleaning and preparing the text data for further processing or analysis.
A text preprocessing pipeline is a series of processing steps that are applied to raw text data in order to prepare it for use in natural language processing tasks.
The steps in a text preprocessing pipeline can vary, but they typically include tasks such as tokenization, stop word removal, stemming, and lemmatization. These steps help reduce the size of the text data and also improve the accuracy of NLP tasks such as text classification and information extraction.
Text data is difficult to process because it is unstructured and often contains a lot of noise. This noise can be in the form of misspellings, grammatical errors, and non-standard formatting. A text preprocessing pipeline aims to clean up this noise so that the text data can be more easily analyzed.
Want to learn more about it? Check out our Text Mining with R track.
The two most common methods for extracting feature from text or in other words converting text data (strings) into numeric features so machine learning model can be trained are: Bag of Words (a.k.a CountVectorizer) and Tf-IDF.
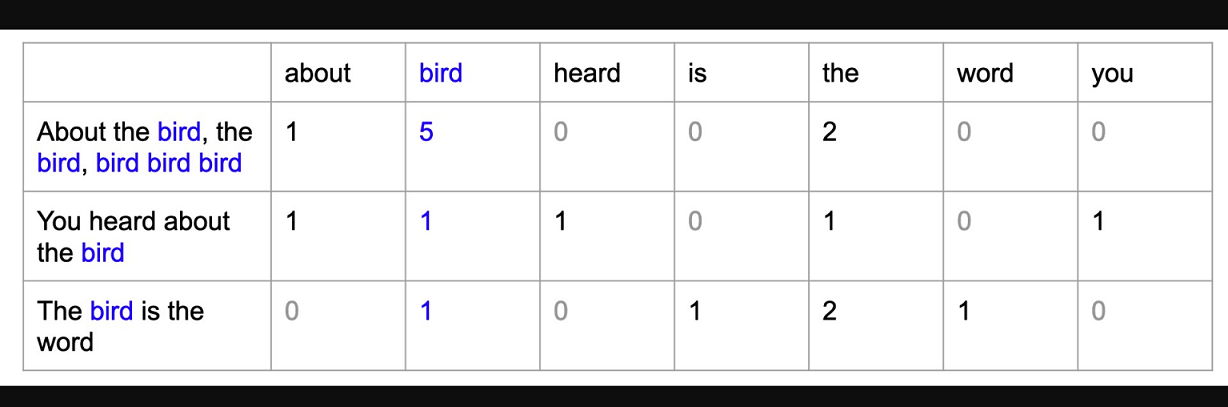
A bag of words (BoW) model is a simple way of representing text data as numeric features. It involves creating a vocabulary of known words in the corpus and then creating a vector for each document that contains counts of how often each word appears.
TF-IDF stands for term frequency-inverse document frequency, and it is another way of representing text as numeric features. There are some shortcomings of the Bag of Words (BoW) model that Tf-IDF overcomes. We won’t go into detail about that in this article, but if you would like to explore this concept further, check out our Introduction to Natural Language Processing in Python course.
The TF-IDF model is different from the bag of words model in that it takes into account the frequency of the words in the document, as well as the inverse document frequency. This means that the TF-IDF model is more likely to identify the important words in a document than the bag of words model.
First, start by importing the dataset directly from this GitHub link. The SMS Spam Collection is a dataset containing 5,574 SMS messages in English along with the label Spam or Ham (not spam). Our goal is to train a machine learning model that will learn from the text of SMS and the label and be able to predict the class of SMS messages.
# reading data
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv', encoding='latin-1')
data.head()
After reading the dataset, notice that there are a few extra columns that we don’t need. We only need the first two columns. Let’s go ahead and drop the remaining columns and also rename the first two columns.
# drop unnecessary columns and rename cols
data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
data.columns = ['label', 'text']
data.head()
Let’s do some basic EDA to see if there are missing values in the dataset and what’s the target balance.
# check missing values
data.isna().sum()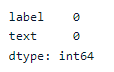
# check data shape
data.shape>>> (5572, 2)# check target balance
data['label'].value_counts(normalize = True).plot.bar()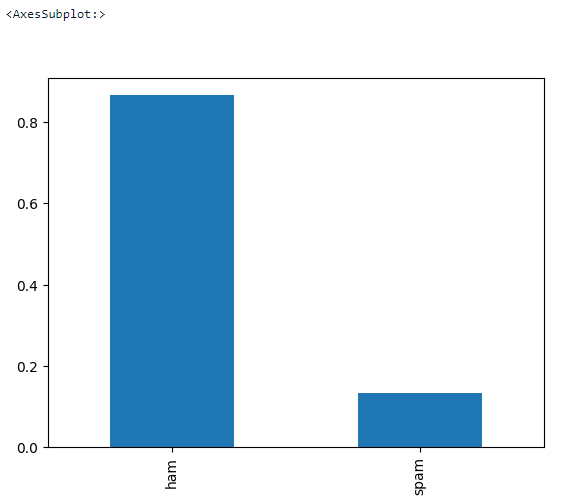
This is where all text cleaning takes place. It’s a loop that iterates through all 5,572 documents and does the following:
# text preprocessing
# download nltk
import nltk
nltk.download('all')
# create a list text
text = list(data['text'])
# preprocessing loop
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
corpus = []
for i in range(len(text)):
r = re.sub('[^a-zA-Z]', ' ', text[i])
r = r.lower()
r = r.split()
r = [word for word in r if word not in stopwords.words('english')]
r = [lemmatizer.lemmatize(word) for word in r]
r = ' '.join(r)
corpus.append(r)
#assign corpus to data['text']
data['text'] = corpus
data.head()
Let’s split the dataset into train and test before feature extraction.
# Create Feature and Label sets
X = data['text']
y = data['label']
# train test split (66% train - 33% test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
print('Training Data :', X_train.shape)
print('Testing Data : ', X_test.shape)>>> Training Data : (3733,)
>>> Testing Data : (1839,)Here, we use the Bag of Words model (CountVectorizer) to convert the cleaned text into numeric features. This is needed for training the machine learning model.
# Train Bag of Words model
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X_train_cv = cv.fit_transform(X_train)
X_train_cv.shape>>> (3733, 7020)In this part, we are training a Logistic Regression model and evaluating the confusion matrix of the trained model.
# Training Logistic Regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train_cv, y_train)
# transform X_test using CV
X_test_cv = cv.transform(X_test)
# generate predictions
predictions = lr.predict(X_test_cv)
predictions>>> array(['ham', 'spam', 'ham', ..., 'ham', 'ham', 'spam'], dtype=object)# confusion matrix
import pandas as pd
from sklearn import metrics
df = pd.DataFrame(metrics.confusion_matrix(y_test,predictions), index=['ham','spam'], columns=['ham','spam'])
df
Check out the full DataLab workbook for more details.
NLP is still an active area of research and development, with many universities and companies working on developing new algorithms and applications. NLP is an interdisciplinary field, with researchers coming from a variety of backgrounds, including computer science, linguistics, psychology, and cognitive science.
Text classification is a powerful and widely used task in NLP that can be used to automatically categorize or predict a class of unseen text documents, often with the help of supervised machine learning.
It is not always accurate, but when used correctly, it can add a lot of value to your analytics. There are many different ways and algorithms to go about setting up a text classifier, and no single approach is best. It is important to experiment and find what works best for your data and your purposes.
Top Courses
Course
Course
Course
blog
Zoumana Keita
14 min
blog
Kurtis Pykes
10 min
cheat-sheet
Richie Cotton
Tutorial
Sayak Paul
Tutorial
Mustafa El-Dalil
Tutorial
Abid Ali Awan


