Course
Intermediate Python
4 hr
1.4M
The extensive contribution of researchers in NLP, short for Natural Language Processing, during the last decades has been generating innovative results in different domains. Below are some of the examples of Natural Language Processing in practice:
This conceptual blog aims to cover Transformers, one of the most powerful models ever created in Natural Language Processing. After explaining their benefits compared to recurrent neural networks, we will build your understanding of Transformers. Then, we will walk you through some real-world case scenarios using Huggingface transformers.
You can also learn more about Building NLP Applications with Hugging Face with our code-along.
Before diving into the core concept of transformers, let’s briefly understand what recurrent models are and their limitations.
Recurrent networks employ the encoder-decoder architecture, and we mainly use them when dealing with tasks where both the input and outputs are sequences in some defined ordering. Some of the greatest applications of recurrent networks are machine translation and time series data modeling.
Let’s consider translating the following French sentence into English. The input transmitted to the encoder is the original French sentence, and the translated output is generated by the decoder.
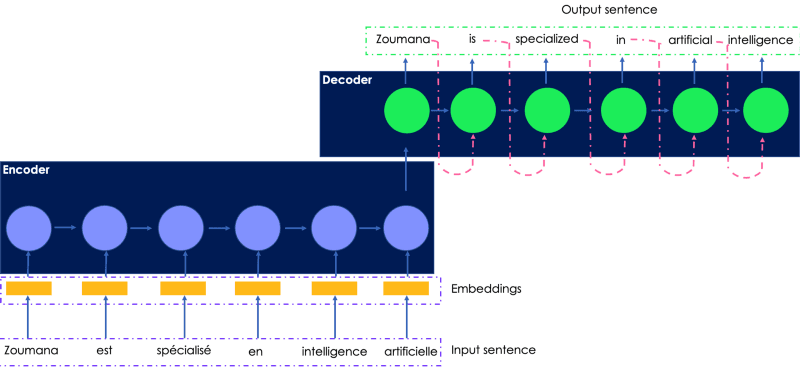
A simple illustration of the recurrent network for language translation
Wouldn't it be great to have a model that combines the benefits of recurrent networks and make parallel computation possible?
Here is where transformers come in handy.
Transformers is the new simple yet powerful neural network architecture introduced by Google Brain in 2017 with their famous research paper “Attention is all you need.” It is based on the attention mechanism instead of the sequential computation as we might observe in recurrent networks.
Similar to recurrent networks, transformers also have two main blocs: encoder and decoder, each one having a self-attention mechanism. The first version of transformers had RNN and LSTM encoder-decoder architecture, which have been changed later into self-attention and feed-forward networks.
The following section provides a general overview of the main components of each block of transformers.
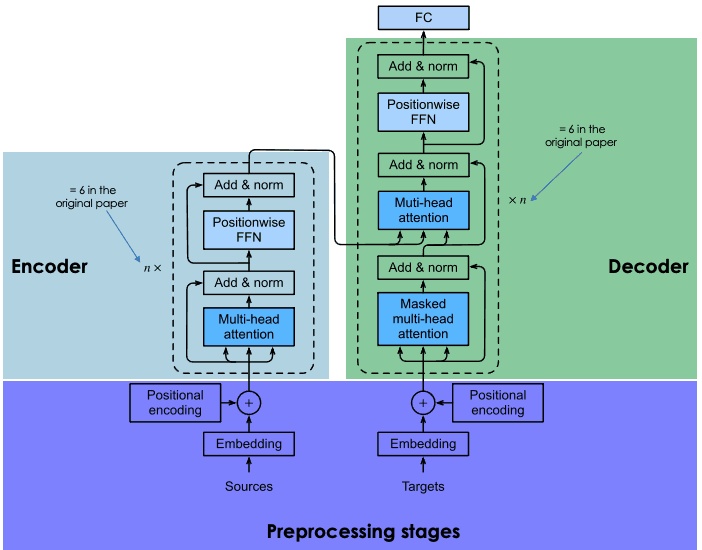
General Architecture of transformers (adapted by Author)
This section contains two main steps: (1) the generation of the embeddings of the input sentence, and (2) the computation of the positional vector of each word in the input sentence. All the computations are performed the same way for both the source sentence (before the encoder block) and the target sentence (before the decoder block).
Before generating the embeddings of the input data, we start by performing the tokenization, then create the embedding of each individual word without paying attention to their relationship in the sentence.
The tokenization task discards any notion of relations that existed in the input sentence. The positional encoding tries to create the original cyclic nature by generating a context vector for each word.
At the end of the previous step, we get for each word two vectors: (1) the embedding and (2) its context vector. These vectors are added to create a single vector for each word, which is then transmitted to the encoder.
As mentioned previously, we lost all notion of a relationship. The goal of the attention layer is to capture the contextual relationships existing between different words in the input sentence. This step ends up generating an attention vector for each word.
At this stage, a feed-forward neural network is applied to every attention vector to transform them into a format that is expected by the next multi-head attention layer in the decoder.
The decoder block consists of three main layers: masked multi-head attention, multi-head attention, and a position-wise feed-forward network. We already understand the last two layers, which are the same in the encoder.
The decoder comes into the equation during the training of the network, and it receives two main inputs: (1) the attention vectors of the input sentence we want to translate and (2) the translated target sentences in English.
During the generation of the next English word, the network is allowed to use all the words from the French word. However, when dealing with a given word in the target sequence (English translation), the network only has to access the previous words because making the next ones available will lead the network to “cheat” and not make any effort to learn properly. Here is where the masked multi-head attention layer has all its benefits. It masks those next words by transforming them into zeros so that they can’t be used by the attention network.
The result of the masked multi-head attention layer passes through the rest of the layers in order to predict the next word by generating a probability score.
This architecture was successful because of the following reasons:
Training deep neural networks such as transformers from scratch is not an easy task, and might present the following challenges:
Using transfer learning can have many benefits, such as reducing the training time, speeding up the training process of new models, and decreasing project delivery time.
Imagine building a model from scratch to translate Mandingo language into Wolof, which are both low resources languages. Gathering data related to those languages is costly. Instead of going through all these challenges, one can re-use pre-trained deep-neural networks as the starting point for training the new model.
Such models have been trained on a huge corpus of data, made available by someone else (moral person, organization, etc.), and evaluated to work very well on language translation tasks such as French to English.
If you are new to NLP, this Introduction to Natural Language Processing in Python course can provide you with the fundamental skills to perform and solve real-world problems.
But what do you mean by re-use of deep-neural networks?
The re-use of the model involves choosing the pre-trained model that is similar to your use case, refining the input-output pair data of your target task, and retraining the head of the pre-trained model by using your data.
The introduction of Transformers has led to the development of state-of-the-art transfer learning models such as:
Hugging Face is an AI community and Machine Learning platform created in 2016 by Julien Chaumond, Clément Delangue, and Thomas Wolf. It aims to democratize NLP by providing Data Scientists, AI practitioners, and Engineers immediate access to over 20,000 pre-trained models based on the state-of-the-art transformer architecture. These models can be applied to:
Hugging Face Transformers also provides almost 2000 data sets and layered APIs, allowing programmers to easily interact with those models using almost 31 libraries. Most of them are deep learning, such as Pytorch, Tensorflow, Jax, ONNX, Fastai, Stable-Baseline 3, etc.
These courses are a great introduction to using Pytorch and Tensorflow for respectively building deep convolutional neural networks. Other components of the Hugging Face Transformers are the Pipelines.
The pipeline() method has the following structure:
from transformers import pipeline
# To use a default model & tokenizer for a given task(e.g. question-answering)
pipeline("<task-name>")
# To use an existing model
pipeline("<task-name>", model="<model_name>")
# To use a custom model/tokenizer
pipeline('<task-name>', model='<model name>',tokenizer='<tokenizer_name>')Now that you have a better understanding of Transformers, and the Hugging Face platform, we will walk you through the following real-world scenarios: language translation, sequence classification with zero-shot classification, sentiment analysis, and question answering.
This dataset is available on Datacamp’s Dataset is enriched by Facebook and was created to predict the popularity of an article before its publication. The analysis will be based on the description column. To illustrate our examples, we will be using only three examples from the data.
Below is a brief description of the data. It has 14 columns and 1428 rows.
import pandas as pd
# Load the data from the path
data_path = "datacamp_workspace_export_2022-08-08 07_56_40.csv"
news_data = pd.read_csv(data_path, error_bad_lines=False)
# Show data information
news_data.info()
MariamMT is an efficient Machine Translation framework. It uses the MarianNMT engine under the hood, which is purely developed in C++ by Microsoft and many academic institutions such as the University of Edinburgh, and Adam Mickiewicz University in Poznań. The same engine is currently behind the Microsoft Translator service.
The NLP group from the University of Helsinki open-sourced multiple translation models on Hugging Face Transformers and they are all in the following format Helsinki-NLP/opus-mt-{src}-{tgt}where {src} and {tgt}correspond respectively to the source and target languages.
So, in our case, the source language is English (en) and the target language is French (fr)
MarianMT is one of those models previously trained using Marian on parallel data collected at Opus.
pip install transformers sentencepiece
from transformers import MarianTokenizer, MarianMTModel# Get the name of the model
model_name = 'Helsinki-NLP/opus-mt-en-fr'
# Get the tokenizer
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Instantiate the model
model = MarianMTModel.from_pretrained(model_name)def format_batch_texts(language_code, batch_texts):
formated_bach = [">>{}<< {}".format(language_code, text) for text in
batch_texts]
return formated_bachdef perform_translation(batch_texts, model, tokenizer, language="fr"):
# Prepare the text data into appropriate format for the model
formated_batch_texts = format_batch_texts(language, batch_texts)
# Generate translation using model
translated = model.generate(**tokenizer(formated_batch_texts,
return_tensors="pt", padding=True))
# Convert the generated tokens indices back into text
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
return translated_texts# Check the model translation from the original language (English) to French
translated_texts = perform_translation(english_texts, trans_model, trans_model_tkn)
# Create wrapper to properly format the text
from textwrap import TextWrapper
# Wrap text to 80 characters.
wrapper = TextWrapper(width=80)
for text in translated_texts:
print("Original text: \n", text)
print("Translation : \n", text)
print(print(wrapper.fill(text)))
print("")
Most of the time, training a Machine Learning model requires all the candidate labels/targets to be known beforehand, meaning that if your training labels are science, politics, or education, you will not be able to predict the healthcare label unless you retrain your model, taking into consideration that label and the corresponding input data.
This powerful approach makes it possible to predict the target of a text in about 15 languages without having seen any of the candidate labels. We can use this model by simply loading it from the hub.
The goal here is to try to classify the category of each of the previous descriptions, whether it is tech, politics, security, or finance.
from transformers import pipelinecandidate_labels = ["tech", "politics", "business", "finance"]my_classifier = pipeline("zero-shot-classification",
model='joeddav/xlm-roberta-large-xnli')#For the first description
prediction = my_classifier(english_texts[0], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)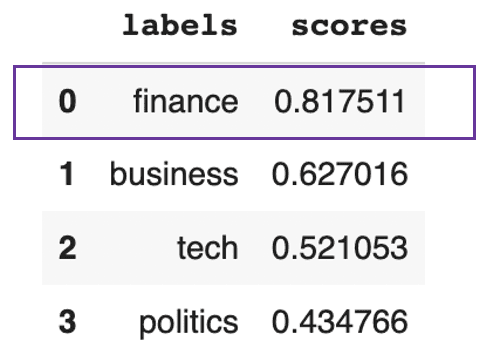
Text predicted to be mainly about finance
This previous result shows that the text is overall about finance at 81%.
For the last description, we get the following result:
#For the last description
prediction = my_classifier(english_texts[-1], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)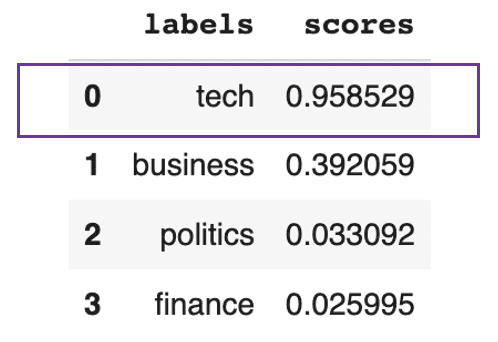
Text predicted to be mainly about tech
This previous result shows that the text is overall about tech at 95%.
Most models performing sentiment classification require proper training. The hugging Face pipeline module makes it easy to run sentiment analysis predictions by using a specific model available on the hub by specifying its name.
model_checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
distil_bert_model = pipeline(task="sentiment-analysis", model=model_checkpoint)# Run the predictions
distil_bert_model(english_texts[1:])
The model predicted the first text to have a negative sentiment with 96% confidence, and the second one predicted with positive sentiment at 52% confidence.
If you want to explore more on sentiment analysis tasks, this Python Sentiment Analysis course will help you get the skills to build your own sentiment analysis classifier using Python and understand the basics of NLP.
Imagine dealing with a report much longer than the one about Apple. And, all you are interested in is the date of the event being mentioned. Instead of reading the whole report to find the key information, we can use a question-answering model from Hugging Face that will provide the answer we are interested in.
This can be done by providing the model with proper context (Apple’s report)and the question we are interested in finding the answer to.
from transformers import AutoModelForQuestionAnswering, AutoTokenizermodel_checkpoint = "deepset/roberta-base-squad2"
task = 'question-answering'
QA_model = pipeline(task, model=model_checkpoint, tokenizer=model_checkpoint)QA_input = {
'question': 'when is Apple hosting an event?',
'context': english_texts[-1]
}model_response = QA_model(QA_input)
pd.DataFrame([model_response])
The model answered that Apple’s event is on September 10th with high confidence of 97%.
In this article, we’ve covered the evolution of natural language technology from recurrent networks to transformers and how Hugging Face has democratized the use of NLP through its platform.
If you are still hesitant about using transformers, we believe it is time to give them a try and add value to your business cases.
Courses for Python
Course
Course
Course
Tutorial
Arjun Sarkar
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
code-along
Jacob Marquez
code-along
Priyanka Asnani
code-along
Alara Dirik




