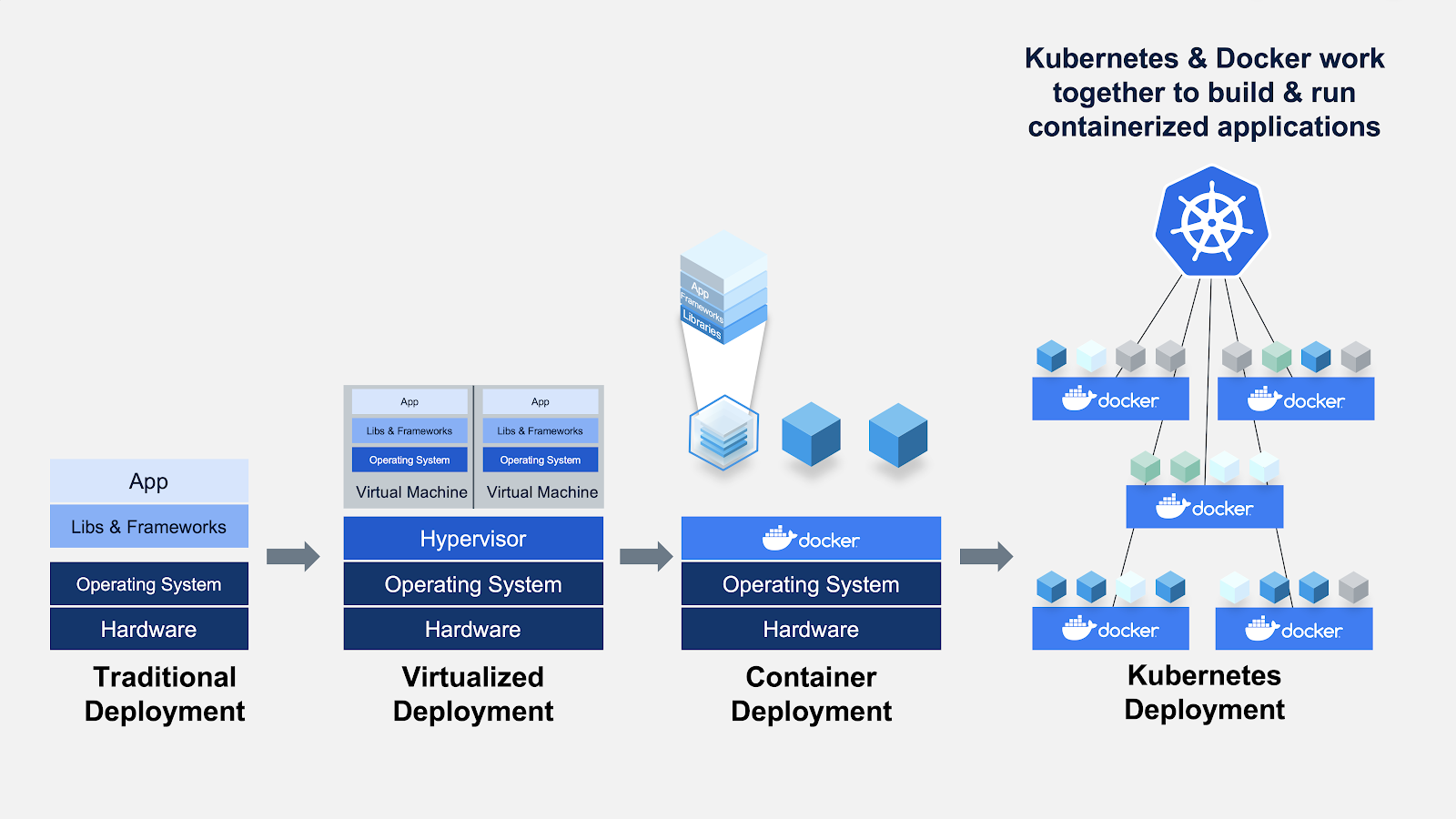
In the vast realm of technology, where innovation is the cornerstone of progress, containerization has emerged as a game-changer. With its ability to encapsulate applications and their dependencies into portable and lightweight units, containerization has revolutionized software development and machine learning.
Two titans of this containerization revolution, Docker and Kubernetes, have risen to prominence, reshaping how we build and scale applications. In the world of machine learning, where complexity and scalability are paramount, containerization offers an invaluable solution.
In this article, we will embark on a journey to explore the world of containerization, uncovering the wonders of Docker and Kubernetes and unraveling their profound importance and advantages in the context of machine learning.
What is a Container?
A container serves as a standardized software unit that encompasses code and its dependencies, facilitating efficient and reliable execution across different computing environments. It consists of a lightweight, independent package known as a container image, which contains all the necessary components for running an application, such as code, runtime, system tools, libraries, and configurations.
Containers possess built-in isolation, ensuring each container operates independently and includes its own software, libraries, and configuration files. They can communicate with one another through well-defined channels while being executed by a single operating system kernel. This approach optimizes resource utilization compared to virtual machines, as it allows multiple isolated user-space instances, referred to as containers, to run on a single control host.
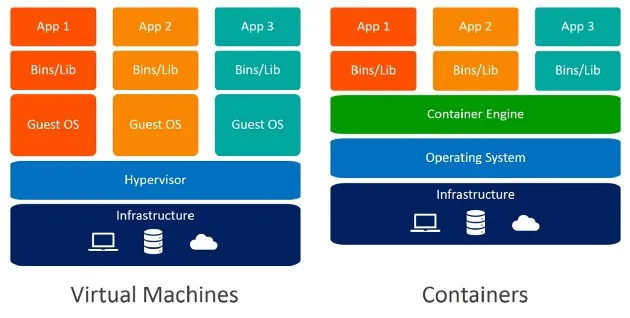
Why Do Containers Matter for Modern Applications?
Containerization is highly important in the field of machine learning due to its numerous advantages. Here are some key benefits:
1. Reproducibility and portability
Containers encapsulate the entire software stack, ensuring consistent deployment and easy portability of ML models across different environments.
2. Isolation and dependency management
Dependencies are isolated within containers, preventing conflicts and simplifying dependency management, making it easier to work with different library versions.
3. Scalability and resource management
Container orchestration platforms like Kubernetes enable efficient resource utilization and scaling of ML workloads, improving performance and reducing costs.
Why Use Docker?
Check out DataCamp’s Docker cheat sheet.
Docker, often hailed as the pioneer of containerization, has transformed the landscape of software development and deployment. At its core, Docker provides a platform for creating and managing lightweight, isolated containers that encapsulate applications and their dependencies.
Docker achieves this by utilizing container images, which are self-contained packages that include everything needed to run an application, from the code to the system libraries and dependencies. Docker images can be easily created, shared, and deployed, allowing developers to focus on building applications rather than dealing with complex configuration and deployment processes.
Creating a Dockerfile in your project
Containerizing an application refers to the process of encapsulating the application and its dependencies into a Docker container. The initial step involves generating a Dockerfile within the project directory. A Dockerfile is a text file that contains a series of instructions for building a Docker image. It serves as a blueprint for creating a container that includes the application code, dependencies, and configuration settings. Let’s see an example Dockerfile:
# Use the official Python base image with version 3.9
FROM python:3.9
# Set the working directory within the container
WORKDIR /app
# Copy the requirements file to the container
COPY requirements.txt .
# Install the dependencies
RUN pip install -r requirements.txt
# Copy the application code to the container
COPY . .
# Set the command to run the application
CMD ["python", "app.py"]If you want to learn more about common Docker commands and industry-wide best practices, then check out our blog, Docker for Data Science: An Introduction and enrol in our Introduction to Docker course.
This Dockerfile follows a simple structure. It begins by specifying the base image as the official Python 3.9 version. The working directory inside the container is set to "/app". The file "requirements.txt" is copied into the container to install the necessary dependencies using the "RUN" instruction. The application code is then copied into the container. Lastly, the "CMD" instruction defines the command that will be executed when a container based on this image is run, typically starting the application with the command python app.py.
Building Docker Image from Dockerfile
Once you have a Dockerfile, you can build the image from this file by running the following command in the terminal. For this, you must have Docker installed on your computer. Follow these instructions to install Docker if you already haven’t done so.
docker build -t image-name:tag
Running this command may take a long time. As the image is being built you will see the logs printed on the terminal. The docker build command constructs an image, while the -t flag assigns a name and tag to the image. The name represents the desired identifier for the image, and the tag signifies a version or label. The . denotes the current directory where the Dockerfile is located, indicating to Docker that it should use the Dockerfile in the present directory as the blueprint for image construction.
Once the image is built, you can run docker images command on terminal to confirm:
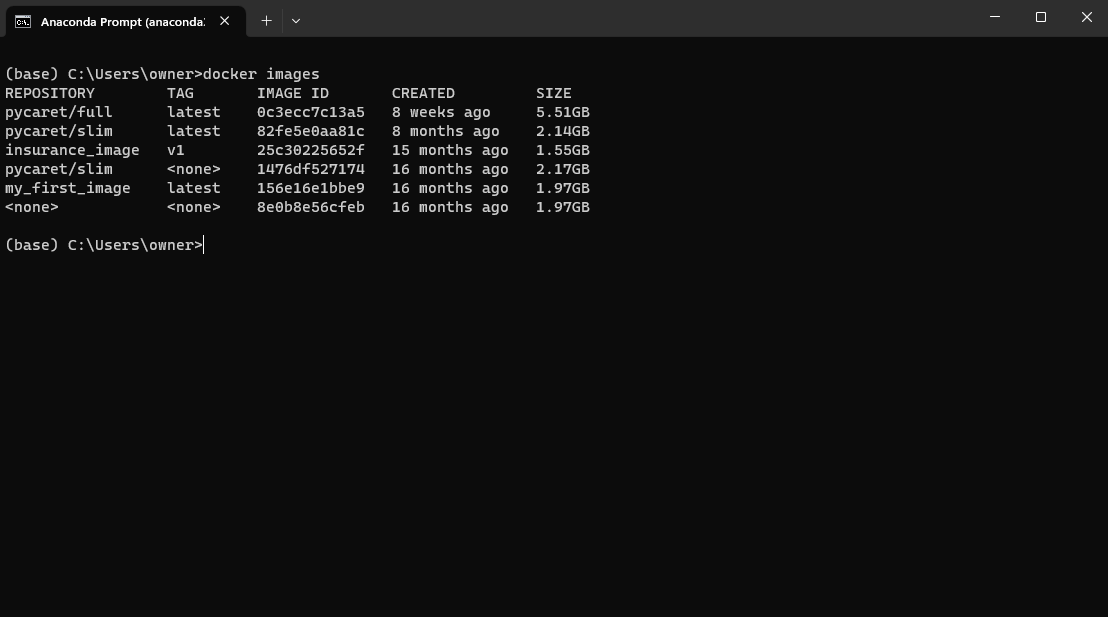
Example by author
Take the next step in your journey to mastering Docker with DataCamp's Introduction to Docker course. In this comprehensive course, you'll learn the fundamentals of containerization, explore the power of Docker, and gain hands-on experience with real-world examples.
Why Use Kubernetes?
While Docker revolutionized containerization, Kubernetes emerged as the orchestrator enabling the seamless management and scaling of containerized applications. Kubernetes, often referred to as K8s, automates the deployment, scaling, and management of containers across a cluster of nodes.
At its core, Kubernetes provides a robust set of features for container orchestration. It allows developers to define and declare the desired state of their applications using YAML manifests. Kubernetes then ensures that the desired state is maintained, automatically handling tasks such as scheduling containers, scaling applications based on demand, and managing container health and availability.
With Kubernetes, developers can seamlessly scale their applications to handle increased traffic and workload without worrying about the underlying infrastructure. It provides a declarative approach to infrastructure management, empowering developers to focus on building and improving their applications rather than managing the intricacies of container deployments.
Understanding Kubernetes components for machine learning: Pods, Services, Deployments
Kubernetes provides several key components that are vital for deploying and managing machine learning applications efficiently. These components include Pods, Services, and Deployments.
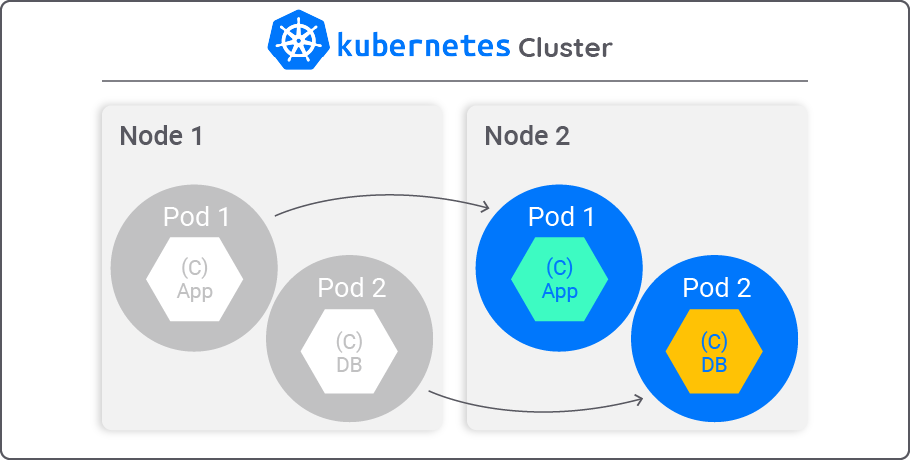
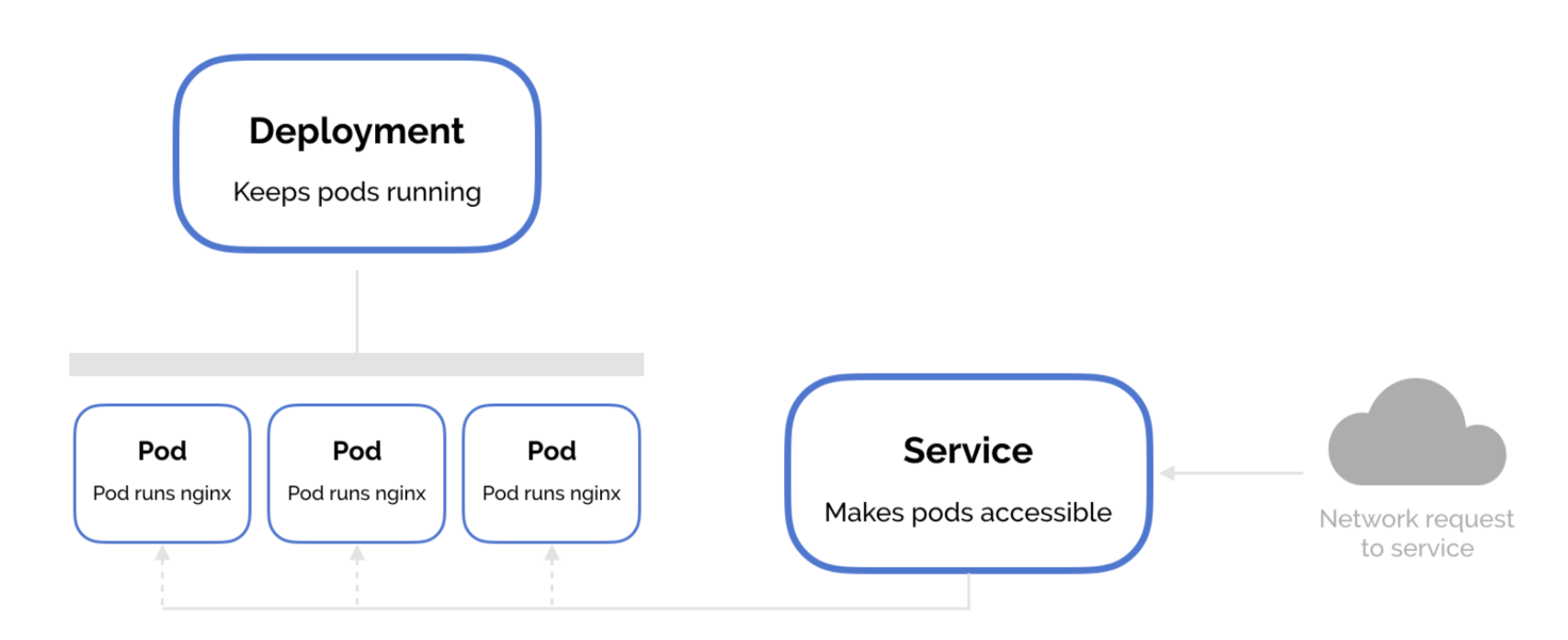
1. Pods
In Kubernetes, a Pod is the smallest unit of deployment. It represents a single instance of a running process within the cluster. In the context of machine learning, a Pod typically encapsulates a containerized ML model or a specific component of the ML workflow. Pods can consist of one or more containers that work together and share the same network and storage resources.
2. Services
Services enable communication and networking between different Pods. A Service defines a stable network endpoint to access one or more Pods. In machine learning scenarios, Services can be used to expose ML models or components as endpoints for data input or model inference. They provide load balancing and discovery mechanisms, making it easier for other applications or services to interact with the ML components.
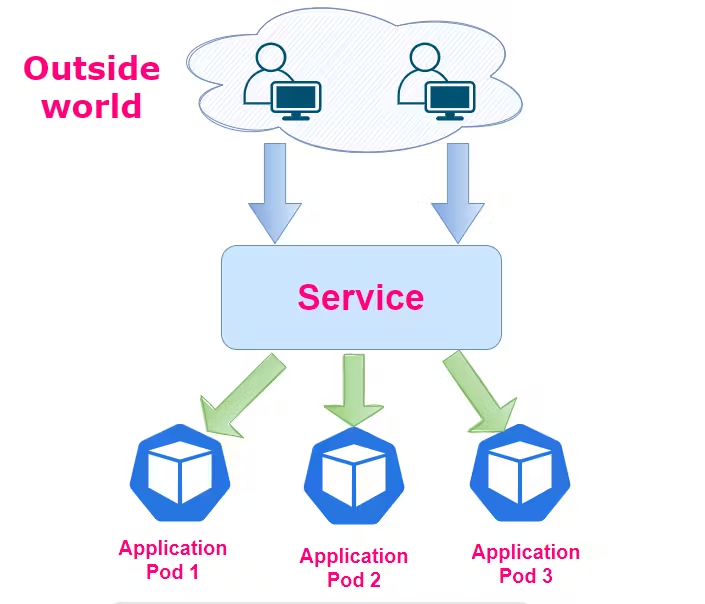
3. Deployments
Deployments provide a declarative way to manage the creation and scaling of Pods. A Deployment ensures that a specified number of replicas of a Pod are running at all times. It allows for easy scaling, rolling updates, and rollbacks of applications. Deployments are particularly useful for managing ML workloads that require dynamic scaling based on demand or when updates need to be applied without downtime.
Writing a Kubernetes Configuration File for an ML project
To deploy an ML project in Kubernetes, a Kubernetes configuration file, typically written in YAML format, is used. This file specifies the desired state of the application, including information about the Pods, Services, Deployments, and other Kubernetes resources.
The configuration file describes the containers, environment variables, resource requirements, and networking aspects required for running the ML application. It defines the desired number of replicas, port bindings, volume mounts, and any specific configurations unique to the ML project.
Example Configuration yaml file for Kubernetes setup
apiVersion: v1
kind: Pod
metadata:
name: ml-model-pod
spec:
containers:
- name: ml-model-container
image: your-image-name:tag
ports:
- containerPort: 8080
env:
- name: ENV_VAR_1
value: value1
- name: ENV_VAR_2
value: value2In this example, various elements are used to configure a Pod in Kubernetes. These include specifying the Kubernetes API version, defining the resource type as a Pod, providing metadata like the Pod's name, and outlining the Pod's specifications in the spec section.
Kubernetes for machine learning
Once the Kubernetes configuration file is defined, deploying an ML model is a straightforward process. Using the kubectl command-line tool, the configuration file can be applied to the Kubernetes cluster to create the specified Pods, Services, and Deployments.
Kubernetes will ensure that the desired state is achieved, automatically creating and managing the required resources. This includes scheduling Pods on appropriate nodes, managing networking, and providing load balancing for Services.
Kubernetes excels at scaling and managing ML workloads. With horizontal scaling, more replicas of Pods can be easily created to handle increased demand or to parallelize ML computations. Kubernetes automatically manages the load distribution across Pods and ensures efficient resource utilization.
Conclusion
Containerization, powered by Docker and Kubernetes, has revolutionized the field of machine learning by offering numerous advantages and capabilities. Docker provides a platform for creating and managing lightweight, isolated containers that encapsulate applications and their dependencies. It simplifies the deployment process, allowing developers to focus on building applications rather than dealing with complex configurations.
Kubernetes, on the other hand, acts as the orchestrator that automates the deployment, scaling, and management of containerized applications. It ensures the desired state of the application is maintained, handles tasks such as scheduling containers, scaling applications based on demand, and manages container health and availability. Kubernetes enables efficient resource utilization and allows seamless scaling of machine learning workloads, providing a declarative approach to infrastructure management.
The combination of Docker and Kubernetes offers a powerful solution for managing machine learning applications. Docker provides reproducibility, portability, and easy dependency management, while Kubernetes enables efficient scaling, resource management, and orchestration of containers. Together, they allow organizations to unlock the full potential of machine learning in a scalable and reliable manner.
Ready to dive into the world of MLOps and revolutionize your machine learning workflows? Check out our Getting Started with MLOps guide and Machine Learning, Pipelines, Deployment, and MLOps Tutorial to take your MLOps skills to the next level. You can also get Docker certified to showcase your Docker skills.