Cours
Introduction à R
4 h
3M
Avec les facettes, vous pouvez créer des graphiques à plusieurs panneaux et contrôler la façon dont les échelles d'un panneau sont liées aux échelles d'un autre panneau.
Si vous êtes un tant soit peu familier avec ggplot2, vous connaissez la structure de base d'un appel à la fonction ggplot(). Pour une introduction à ggplot2, vous pouvez consulter notre cours sur ggplot2. Lorsque vous appelez ggplot, vous fournissez une source de données, généralement un cadre de données, puis vous demandez à ggplot de faire correspondre différentes variables de notre source de données à différents aspects esthétiques, comme la position des axes x ou y ou la couleur de nos points ou de nos barres. Avec les facettes, vous disposez d'un moyen supplémentaire de cartographier les variables. Pour le démontrer, vous utiliserez l'ensemble de données suivant, qui comprend un certain nombre d'indicateurs économiques pour une sélection de pays. La plupart d'entre elles sont des variantes du PIB, le produit intérieur brut de chaque pays.
print(econdata)## Country GDP_nom GDP_PPP GDP_nom_per_capita GDP_PPP_per_capita
## 1 USA 19390600 19390600 59501 59495
## 2 Canada 1652412 1769270 45077 48141
## 3 China 12014610 23159107 8643 16807
## 4 Japan 4872135 5428813 38440 42659
## 5 France 2583560 2835746 39869 43550
## 6 Germany 3684816 4170790 44550 50206
## 7 Sweden 3684816 520937 53218 51264
## 8 Ireland 333994 343682 70638 72632
## GNI_per_capita Region
## 1 58270 North America
## 2 42870 North America
## 3 8690 Asia
## 4 38550 Asia
## 5 37970 Europe
## 6 43490 Europe
## 7 52590 Europe
## 8 55290 EuropeLes variables suivantes sont présentes :
Pays : Cela se passe de commentaires !
PIB_nom : Produit intérieur brut en valeur nominale en USD
GDP_PPP: Produit intérieur brut contrôlé en fonction des différences de pouvoir d'achat
PIB_nom_par_capita : Produit intérieur brut en valeur nominale en USD par habitant
PIB_PPP_par_habitant : Produit intérieur brut contrôlé pour tenir compte des différences de pouvoir d'achat par habitant.
RNB par habitant : Revenu national brut de chaque pays par habitant.
Région : région du monde où se trouve le pays.
Pour commencer, traçons un simple diagramme à barres du PIB nominal de chaque pays.
ggplot(econdata, aes(x=Country, y=GDP_nom))+
geom_bar(stat='identity', fill="forest green")+
ylab("GDP (nominal)")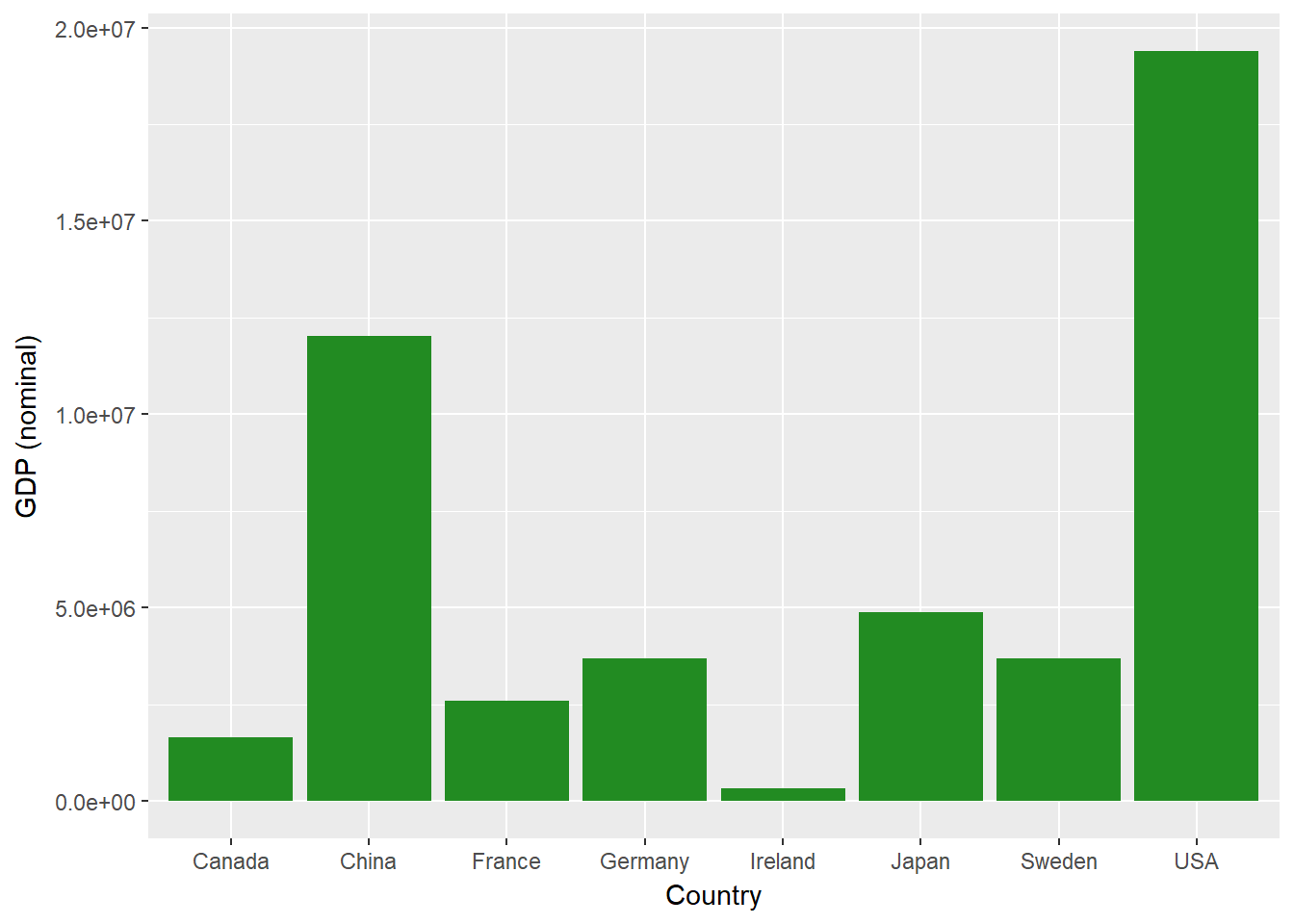
Vous pouvez également tracer une autre variable, le PIB corrigé des PPA.
ggplot(econdata, aes(x=Country, y=GDP_PPP))+
geom_bar(stat='identity', fill="forest green")+
ylab("GDP (PPP)")
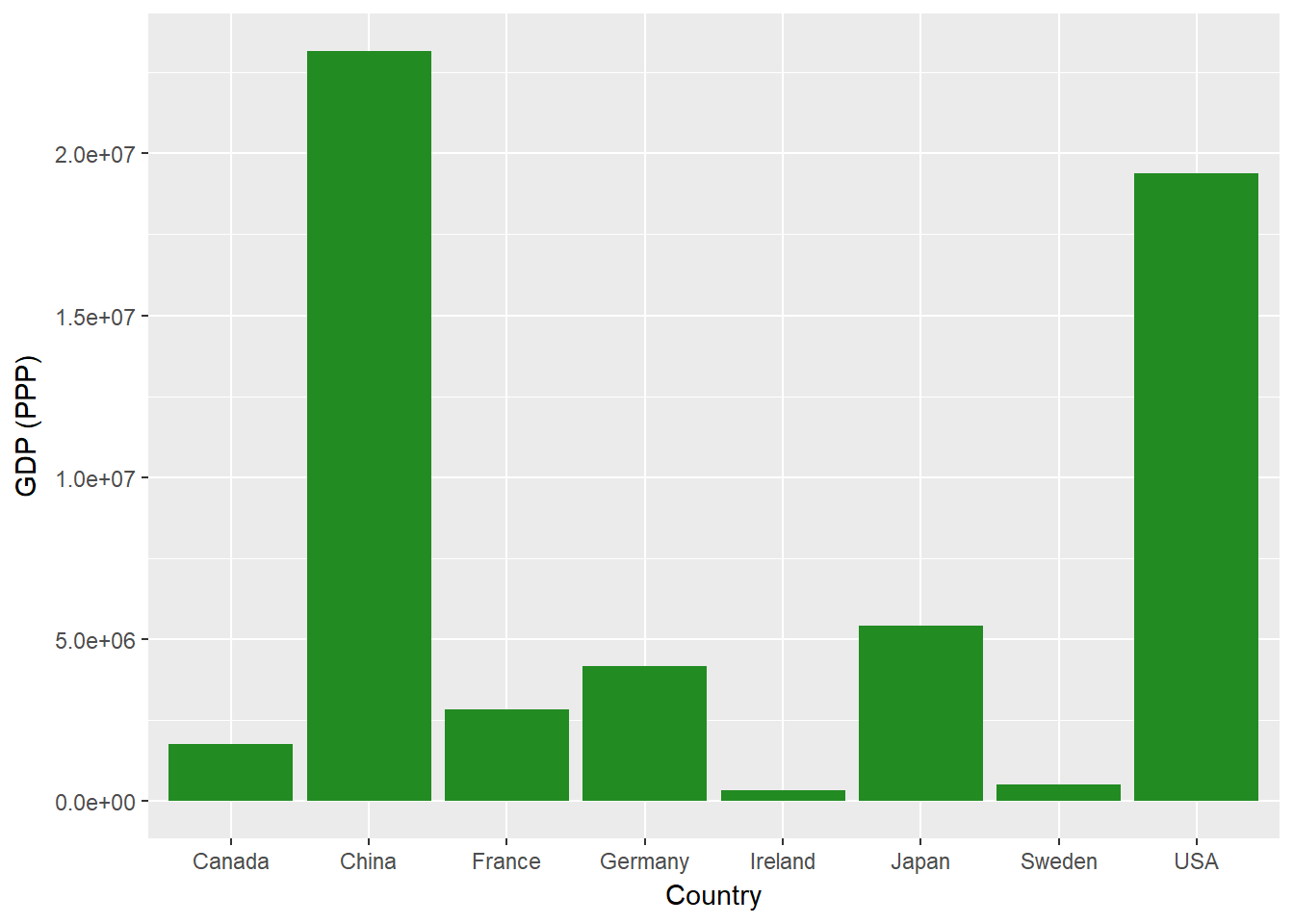
Vous obtenez ainsi un deuxième graphique distinct, similaire au précédent mais utilisant une variable différente. Supposons que vous souhaitiez représenter le PIB (nominal) et le PIB (PPA) ensemble. Pour ce faire, vous utiliserez la technique de la facette. Tout d'abord, vous devrez reformater vos données, en passant d'un format "large" avec chaque variable dans sa propre colonne à un format "long", dans lequel vous utilisez une colonne pour vos mesures et une autre pour une variable clé nous indiquant quelle mesure nous utilisons dans chaque ligne.
econdatalong <- gather(econdata, key="measure", value="value", c("GDP_nom", "GDP_PPP"))
Une fois que vous avez les données dans un tel format, vous pouvez utiliser notre variable clé pour tracer des facettes. Construisons un graphique simple, montrant à la fois le PIB nominal (à partir de notre premier graphique) et le PIB (PPA) (à partir de notre deuxième graphique). Pour ce faire, il vous suffit de modifier votre code pour ajouter +facet_wrap() et spécifier que ~measure, notre variable clé, doit être utilisée pour les facettes.
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure)
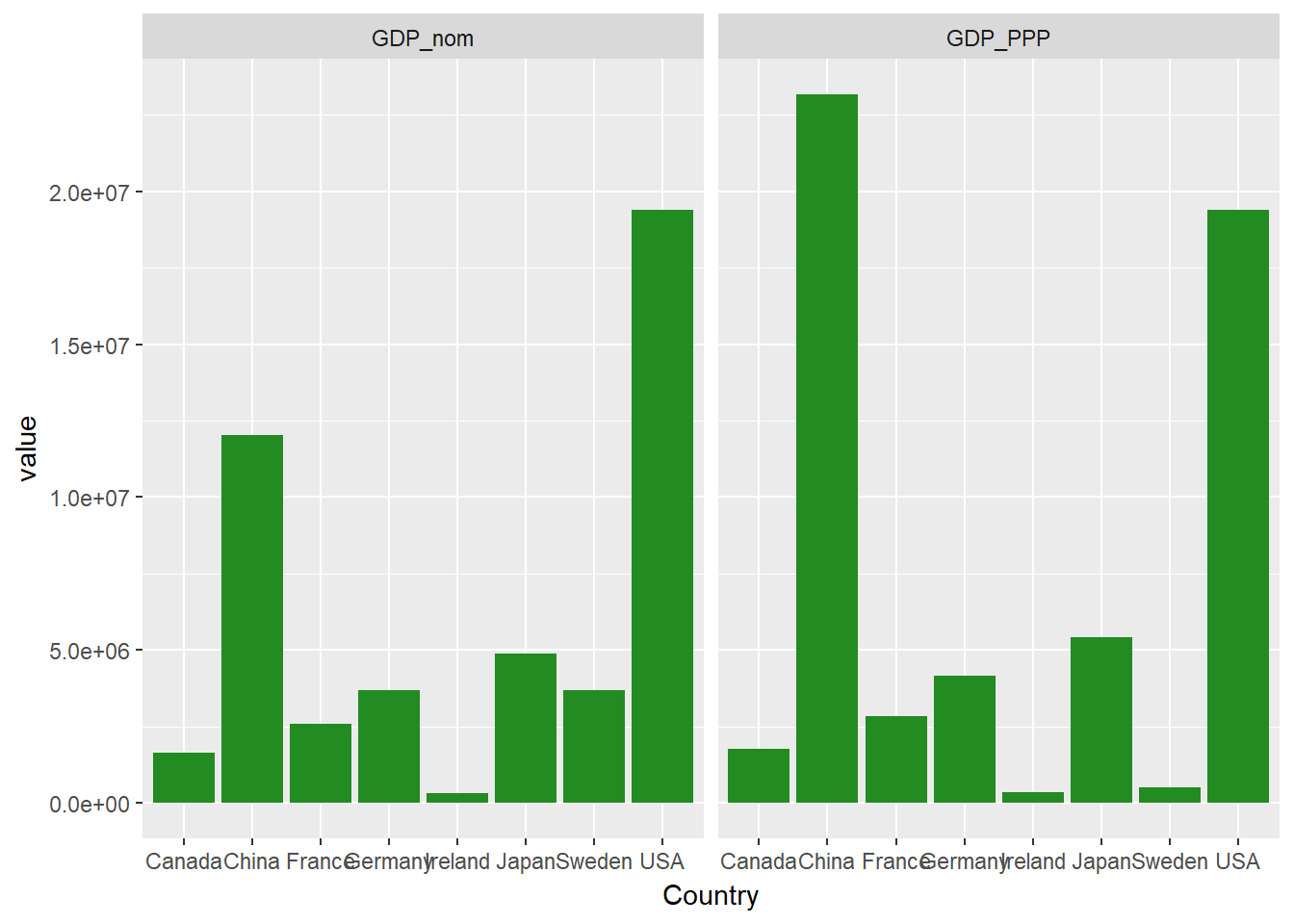
Cela fonctionne, mais vous remarquerez à quel point les noms de pays sont écrasés. Réorganisons nos panneaux.
La commande facet_wrap() choisira automatiquement le nombre de colonnes à utiliser. Vous pouvez le spécifier directement en utilisant ncol=, comme suit :
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1)
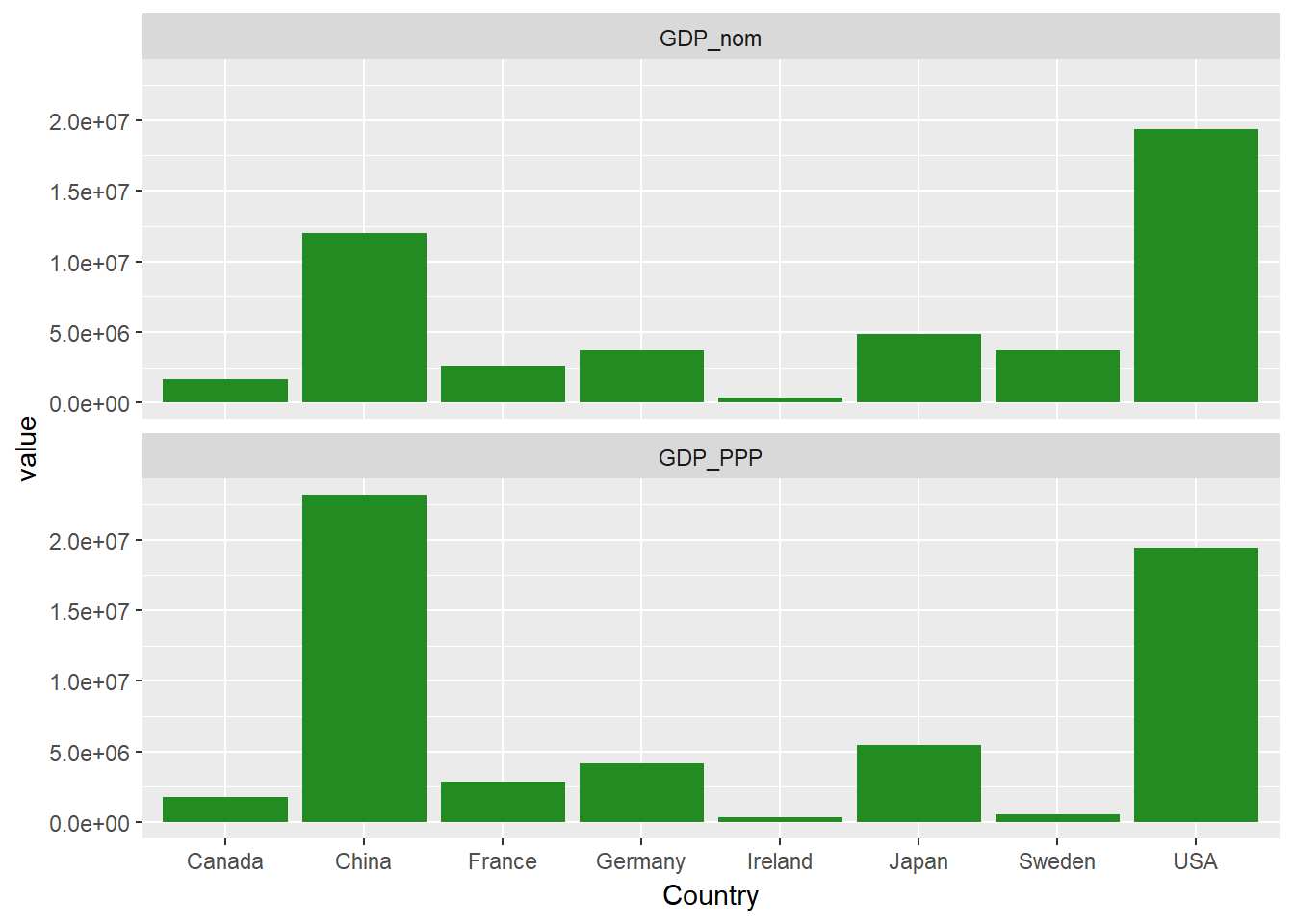
Vous avez probablement remarqué que les pays, sur l'axe des x ci-dessus, sont classés par ordre alphabétique. Si vous souhaitez modifier cette situation, le moyen le plus simple est de définir les niveaux du facteur Country. Effectuons cette réorganisation en classant les pays par ordre de PIB nominal total.
econdata$Country <- factor(econdata$Country, levels= econdata$Country[order(econdata$GDP_nom)])
econdatalong <- gather(econdata, key="measure", value="value", c("GDP_nom", "GDP_PPP"))
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1)
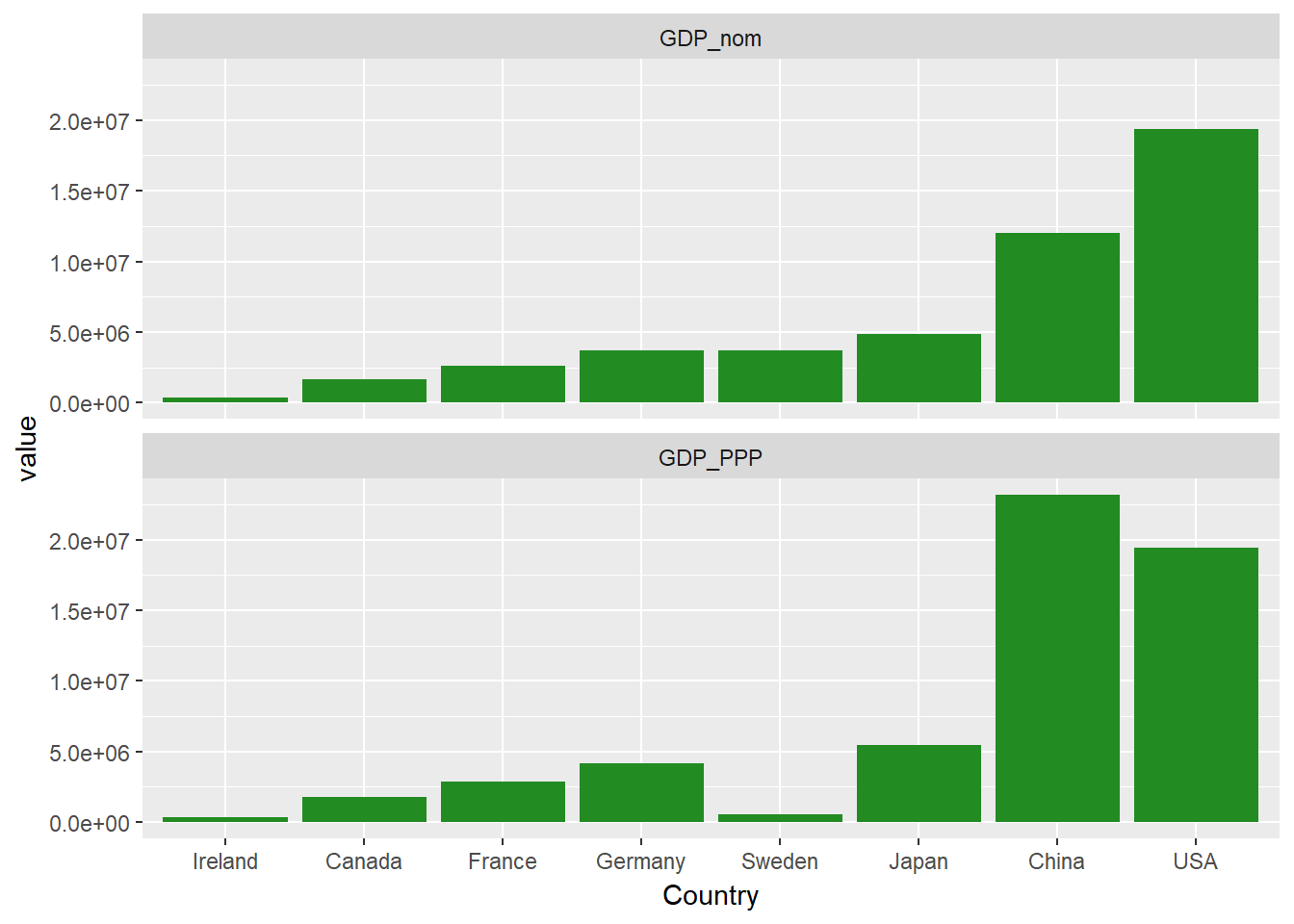
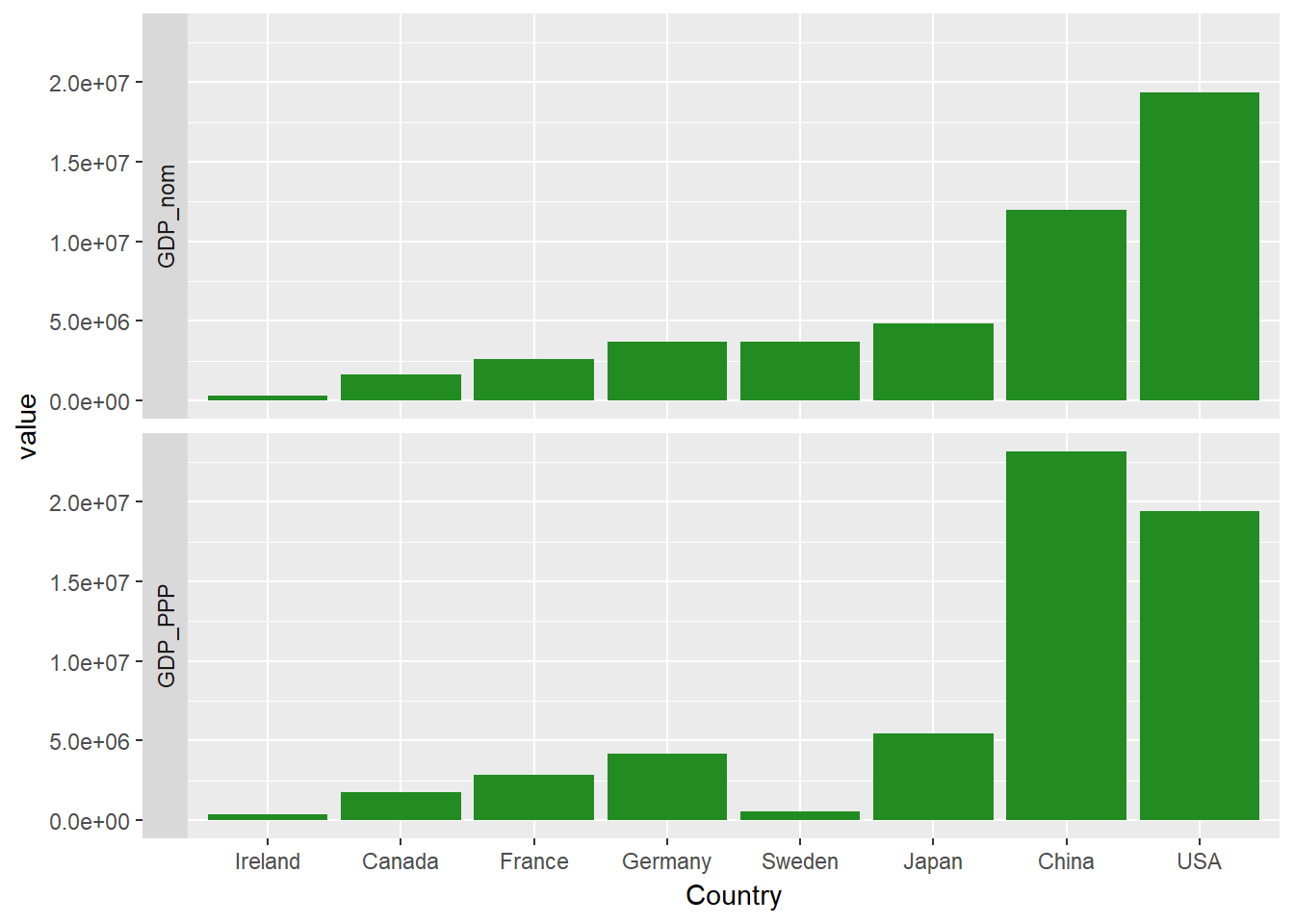
Vous pouvez également effectuer quelques personnalisations supplémentaires, comme déplacer les étiquettes des facettes vers le côté gauche avec l'argument strip.position.
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1, strip.position = "left")
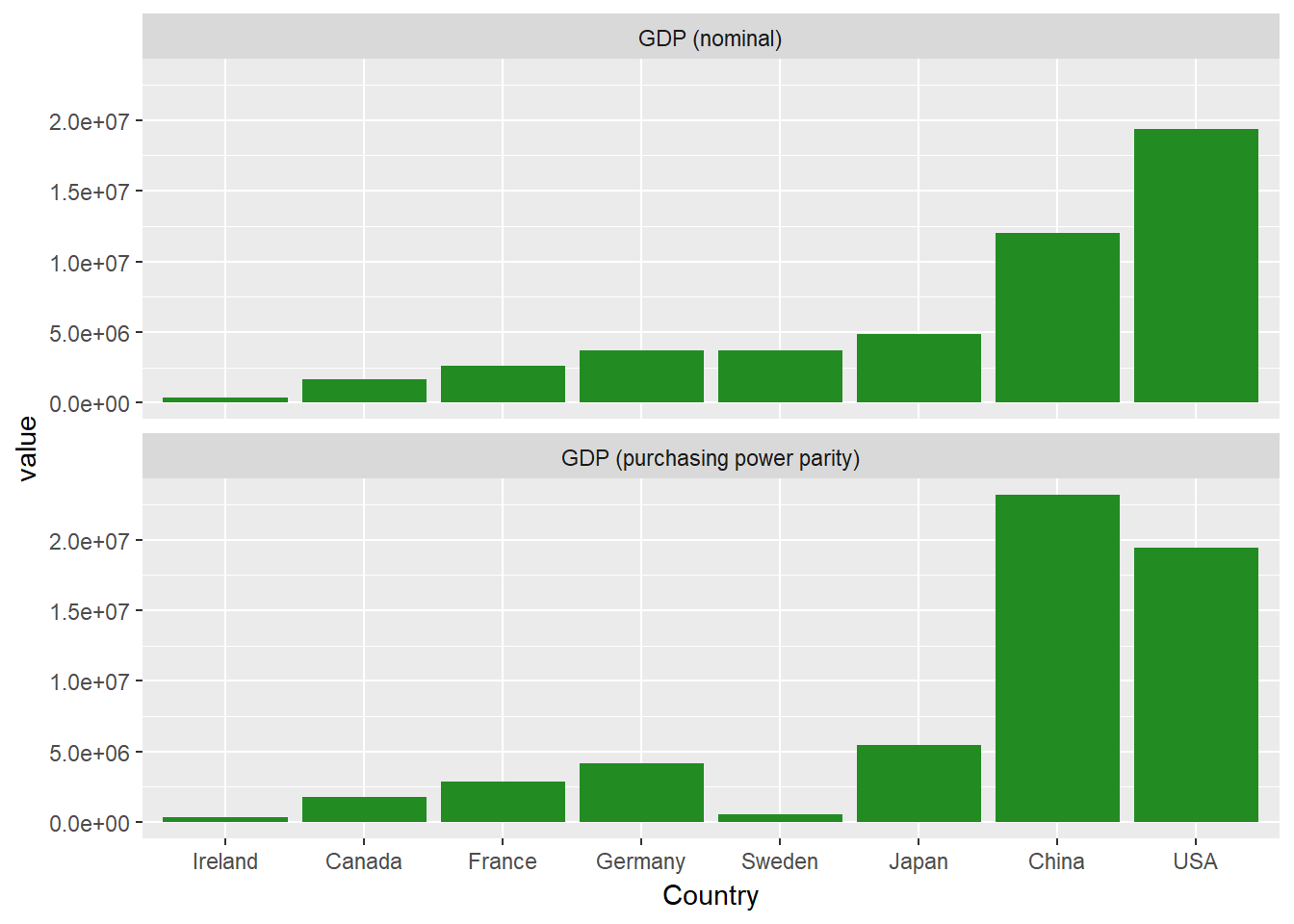
Vous avez peut-être remarqué que les facettes ont des titres simples et courts, tirés des niveaux du facteur measure. Mettons de l'ordre dans tout cela et donnons à nos facettes des étiquettes plus agréables. Pour ce faire, vous créerez une fonction d'étiquetage simple, variable_labeller, qui renverra le nom approprié lorsqu'on lui demandera l'une des valeurs de variable_names. Ensuite, vous transmettez cette fonction à l'argument labeller de facet_wrap.
variable_names <- list(
"GDP_nom" = "GDP (nominal)" ,
"GDP_PPP" = "GDP (purchasing power parity)"
)
variable_labeller <- function(variable,value){
return(variable_names[value])
}
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1, labeller=variable_labeller)
Construisons un graphique à facettes plus large, en utilisant chacune des mesures économiques.
econdatalong <- gather(econdata, key="measure", value="value", c( "GDP_nom" , "GDP_PPP" ,"GDP_nom_per_capita", "GDP_PPP_per_capita" ,"GNI_per_capita"))
variable_names <- list(
"GDP_nom" = "GDP (nominal)" ,
"GDP_PPP" = "GDP (purchasing power parity)",
"GDP_nom_per_capita" = "GDP (nominal) per capita",
"GDP_PPP_per_capita" = "GDP (purchasing power parity) per capita",
"GNI_per_capita" = "GNI per capita"
)
variable_labeller <- function(variable,value){
return(variable_names[value])
}
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1, labeller= variable_labeller)+
scale_y_continuous(breaks = pretty(econdatalong$value, n = 10))
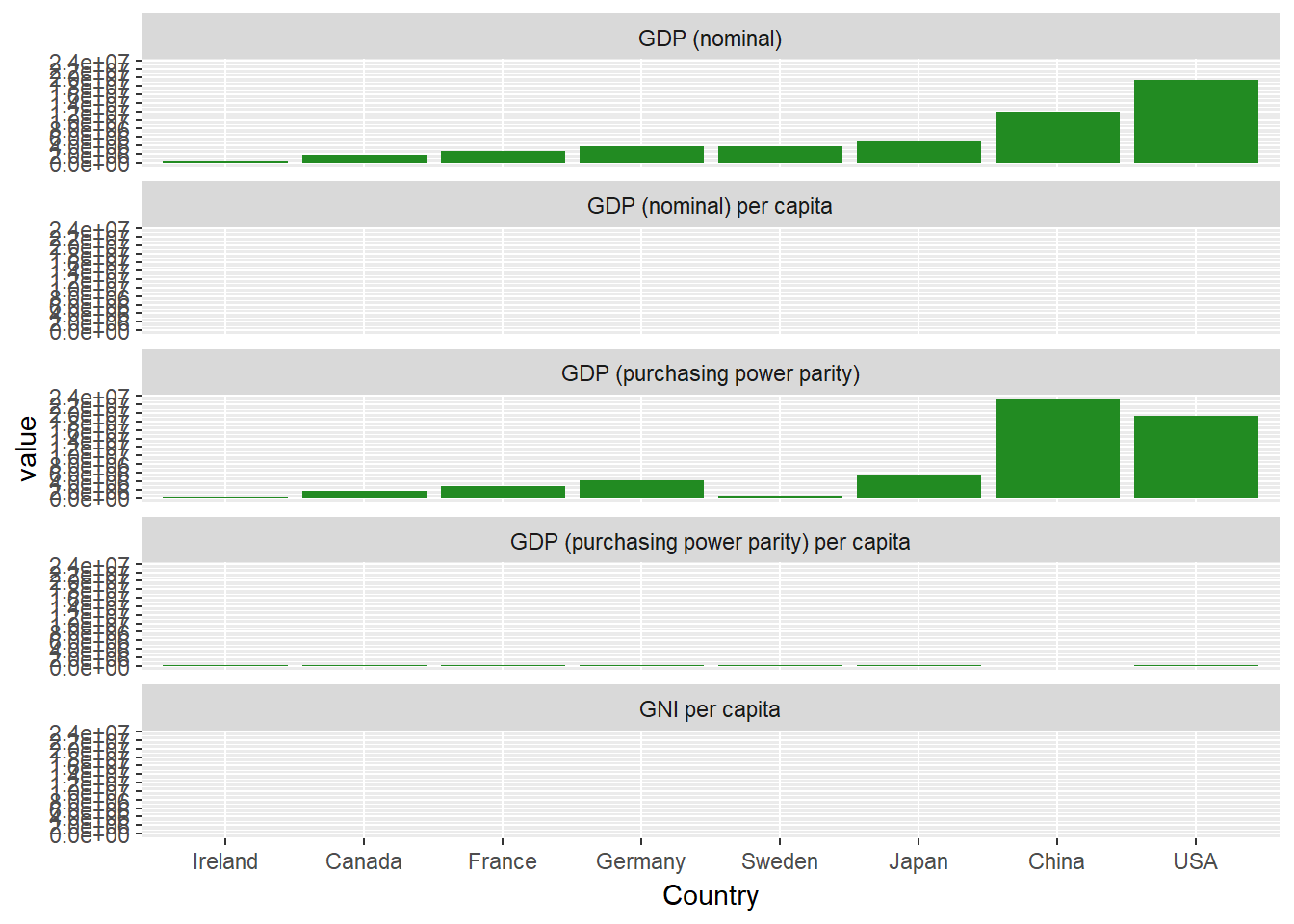
Ce n'est pas bon du tout ! Vous ne pouvez pas voir les valeurs de trois des panneaux. Comment cela se fait-il ? Jetons un coup d'œil aux données primaires pour comprendre pourquoi.
summary(econdata)## Country GDP_nom GDP_PPP GDP_nom_per_capita
## Ireland:1 Min. : 333994 Min. : 343682 Min. : 8643
## Canada :1 1st Qu.: 2350773 1st Qu.: 1457187 1st Qu.:39512
## France :1 Median : 3684816 Median : 3503268 Median :44814
## Germany:1 Mean : 6027118 Mean : 7202368 Mean :44992
## Sweden :1 3rd Qu.: 6657754 3rd Qu.: 8919260 3rd Qu.:54789
## Japan :1 Max. :19390600 Max. :23159107 Max. :70638
## (Other):2
## GDP_PPP_per_capita GNI_per_capita Region
## Min. :16807 Min. : 8690 Asia :2
## 1st Qu.:43327 1st Qu.:38405 Europe :4
## Median :49174 Median :43180 North America:2
## Mean :48094 Mean :42215
## 3rd Qu.:53322 3rd Qu.:53265
## Max. :72632 Max. :58270
##Si vous examinez chaque colonne, vous constaterez que les valeurs de chaque colonne s'échelonnent sur quelques ordres de grandeur. Par défaut, les facettes utilisent les mêmes limites et plages pour les axes X et Y. Pour modifier cela, vous pouvez ajouter cet extrait au code de votre facette : scales="free_y" afin que chaque facette utilise sa propre échelle indépendante.
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, scales="free_y", ncol=1, labeller= variable_labeller)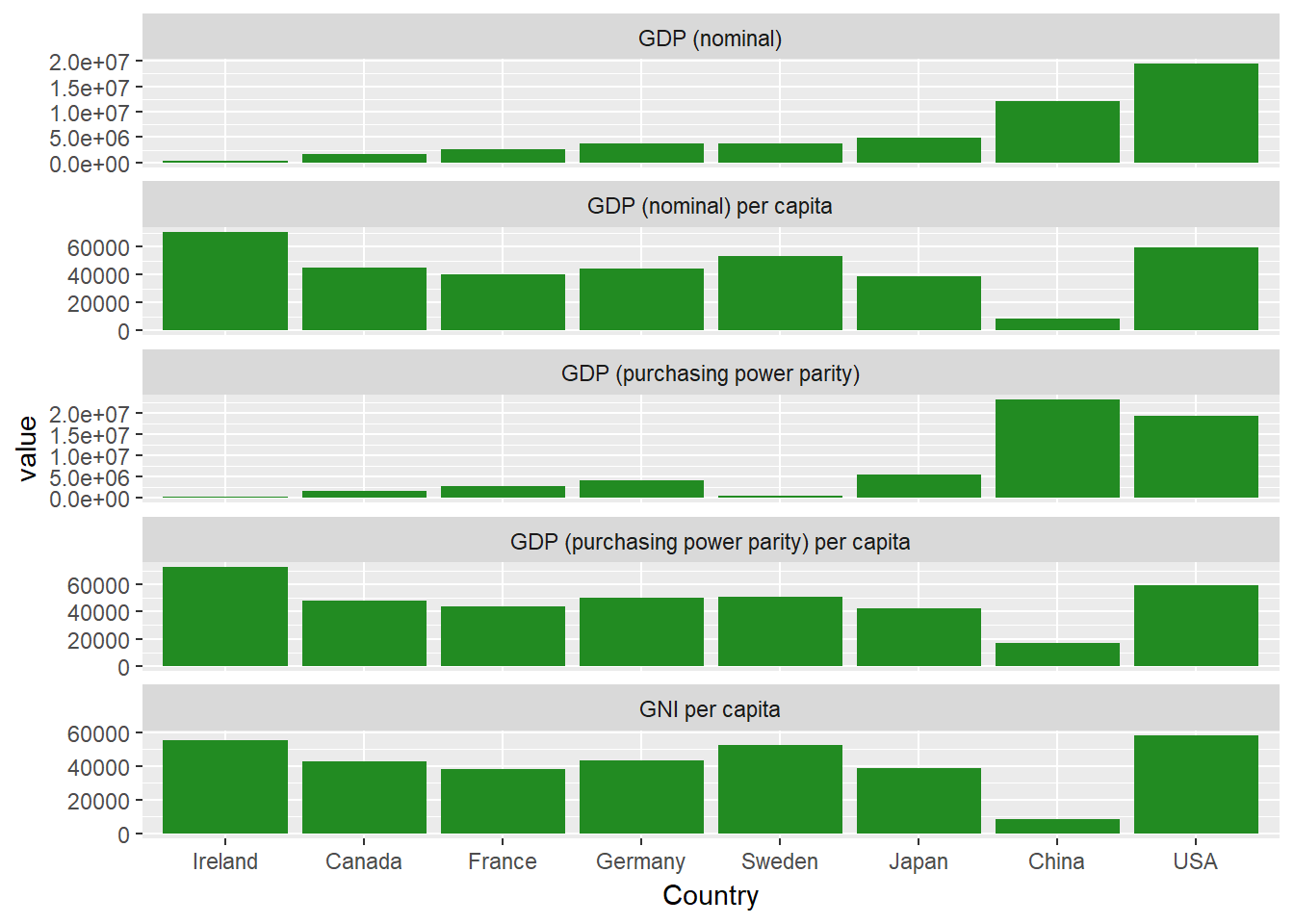
C'est beaucoup mieux. Chaque facette dispose désormais d'un axe des ordonnées indépendant.
Vous avez peut-être remarqué que notre ensemble de données comprend également la variable Region, qui indique la région dans laquelle se trouve le pays en question. Vous pouvez utiliser cette variable pour colorer nos barres en fonction de la région, comme suit :
ggplot(econdatalong, aes(x=Country, y=value, fill=Region))+
geom_bar(stat='identity')+
facet_wrap(~measure, scales="free_y", ncol=1, labeller= variable_labeller)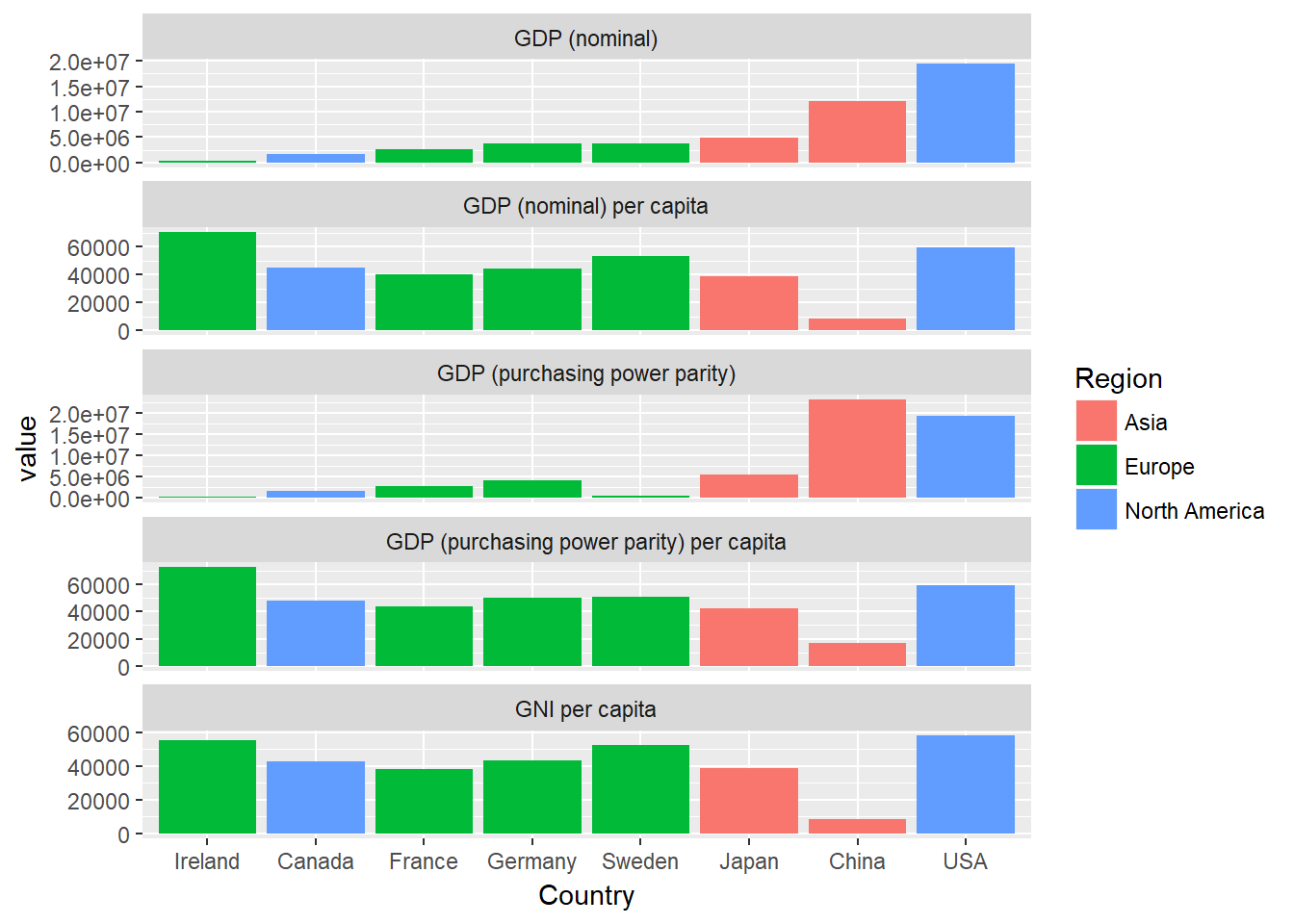
Cependant, cela est un peu désordonné, ne serait-il pas préférable de placer chacune des différentes régions dans leur propre sous-panneau ? Eh bien, avec le facettage, c'est possible ! Ici, vous allez utiliser facet_grid au lieu de facet_wrap, car cela facilitera la mise en correspondance de nos facettes avec deux variables, Region et measure, où toutes ces deux variables sont réparties sur les lignes et les colonnes d'une grille de parcelles. Notez que vous définissez également scales="free" et space="free", ce qui permet à nos différents panneaux d'occuper des espaces différents. Vous devrez également créer une nouvelle fonction d'étiquetage, qui produira des noms pour les lignes et les étiquettes.
variable_names <- list(
"GDP_nom" = "GDP \n(nominal)" ,
"GDP_PPP" = "GDP \n(PPP)",
"GDP_nom_per_capita" = "GDP (nominal)\n per capita",
"GDP_PPP_per_capita" = "GDP (PPP)\n per capita",
"GNI_per_capita" = "GNI \nper capita"
)
region_names <- levels(econdata$Region)
variable_labeller2 <- function(variable,value){
if (variable=='measure') {
return(variable_names[value])
} else {
return(region_names)
}
}
ggplot(econdatalong, aes(x=Country, y=value, fill=Region))+
geom_bar(stat='identity')+
facet_grid(measure~Region, scales="free", space="free_x", labeller= variable_labeller2)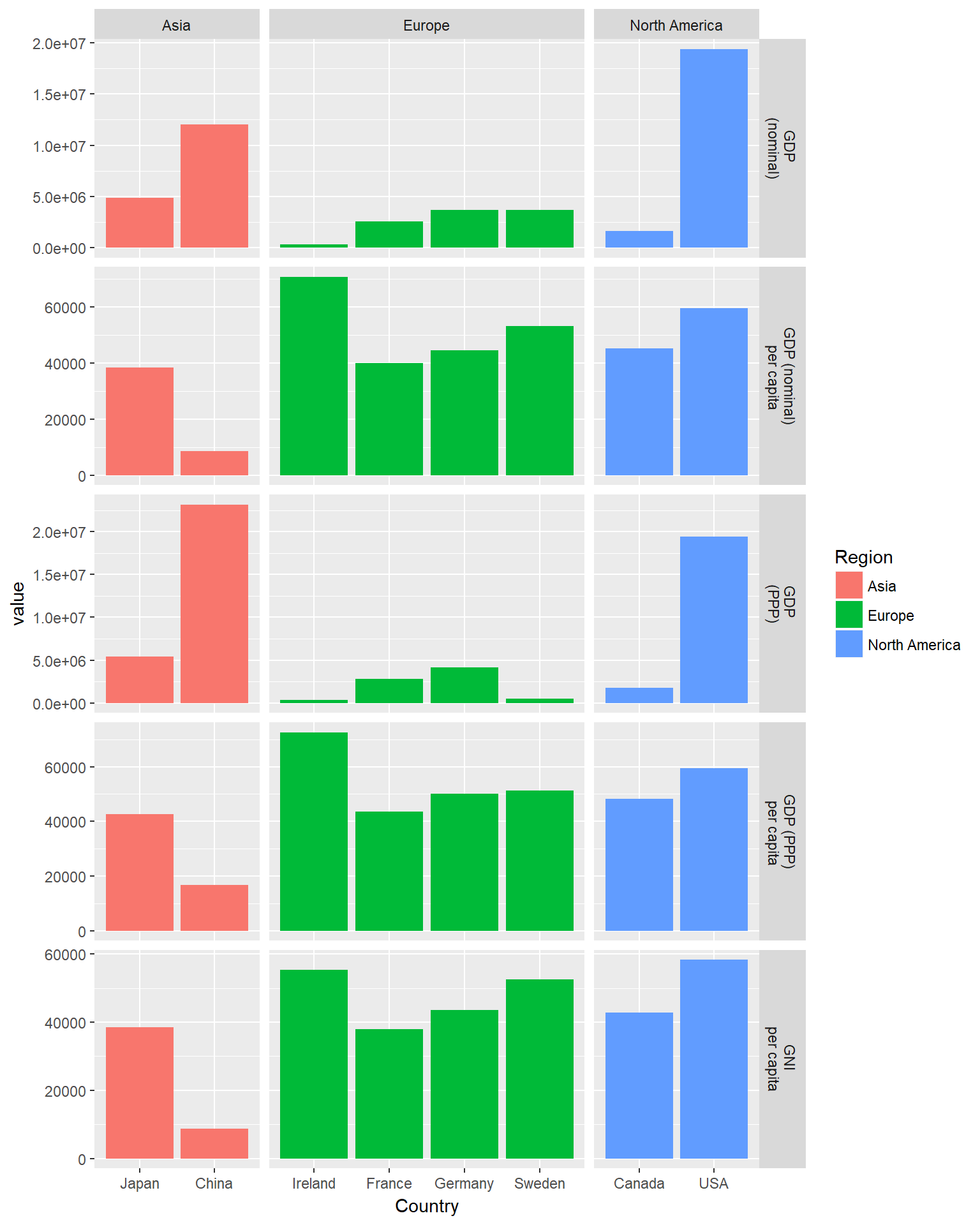
C'est maintenant beaucoup plus clair ! Chaque région a sa propre colonne de panneaux et chaque indicateur a sa propre ligne de barres.
C'est à peu près tout ce qu'il faut savoir pour ce tutoriel. J'espère que vous avez apprécié d'apprendre ce que sont les facettes.
Si vous souhaitez en savoir plus sur les facettes, suivez le cours de DataCamp sur la visualisation des Big Data avec Trelliscope.
Consultez notre site Getting Started with the Tidyverse : Tutoriel.
R Cours
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach