Kurs
Einführung in R
4 Std.
3M
Mit der Facettierung kannst du Diagramme mit mehreren Feldern erstellen und steuern, wie sich die Skalen eines Feldes zu den Skalen eines anderen verhalten.
Wenn du mit ggplot2 vertraut bist, kennst du die grundlegende Struktur eines Aufrufs der Funktion ggplot(). Eine Einführung in ggplot2 findest du in unserem ggplot2-Kurs. Wenn du ggplot aufrufst, gibst du eine Datenquelle an, in der Regel einen Datenrahmen, und bittest dann ggplot, verschiedene Variablen in unserer Datenquelle auf verschiedene Ästhetiken abzubilden, z. B. die Position der x- oder y-Achsen oder die Farbe unserer Punkte oder Balken. Mit Facetten hast du eine zusätzliche Möglichkeit, die Variablen abzubilden. Um dies zu demonstrieren, verwendest du den folgenden Datensatz, der eine Reihe von Wirtschaftsindikatoren für eine Auswahl von Ländern enthält. Die meisten davon sind Varianten des BIP, des Bruttoinlandsprodukts des jeweiligen Landes.
print(econdata)## Country GDP_nom GDP_PPP GDP_nom_per_capita GDP_PPP_per_capita
## 1 USA 19390600 19390600 59501 59495
## 2 Canada 1652412 1769270 45077 48141
## 3 China 12014610 23159107 8643 16807
## 4 Japan 4872135 5428813 38440 42659
## 5 France 2583560 2835746 39869 43550
## 6 Germany 3684816 4170790 44550 50206
## 7 Sweden 3684816 520937 53218 51264
## 8 Ireland 333994 343682 70638 72632
## GNI_per_capita Region
## 1 58270 North America
## 2 42870 North America
## 3 8690 Asia
## 4 38550 Asia
## 5 37970 Europe
## 6 43490 Europe
## 7 52590 Europe
## 8 55290 EuropeDie folgenden Variablen sind vorhanden:
Land: Selbsterklärend!
GDP_nom: Bruttoinlandsprodukt als Nominalwert in USD
GDP_PPP: Bruttoinlandsprodukt unter Berücksichtigung der Kaufkraftunterschiede
GDP_nom_per_capita: Bruttoinlandsprodukt als Nominalwert in USD auf Pro-Kopf-Basis
GDP_PPP_per_capita: Bruttoinlandsprodukt unter Berücksichtigung der unterschiedlichen Kaufkraft pro Kopf
GNI_per_capita: Bruttonationaleinkommen für jedes Land auf Pro-Kopf-Basis.
Region: Region der Welt, in der sich das Land befindet.
Machen wir zunächst ein einfaches Balkendiagramm des nominalen BIP der einzelnen Länder.
ggplot(econdata, aes(x=Country, y=GDP_nom))+
geom_bar(stat='identity', fill="forest green")+
ylab("GDP (nominal)")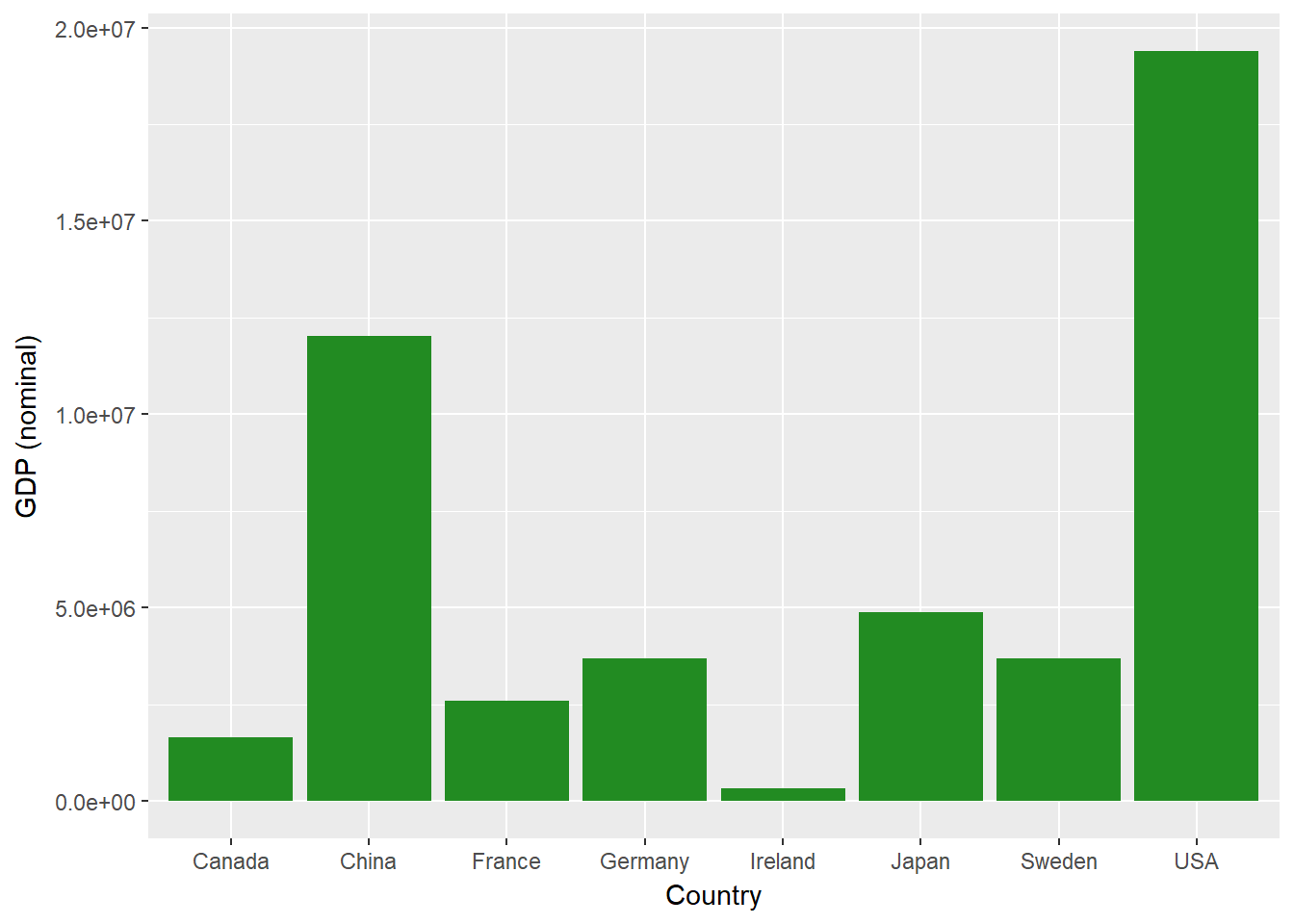
Du kannst auch eine andere Variable aufzeichnen, das KKP-bereinigte BIP.
ggplot(econdata, aes(x=Country, y=GDP_PPP))+
geom_bar(stat='identity', fill="forest green")+
ylab("GDP (PPP)")
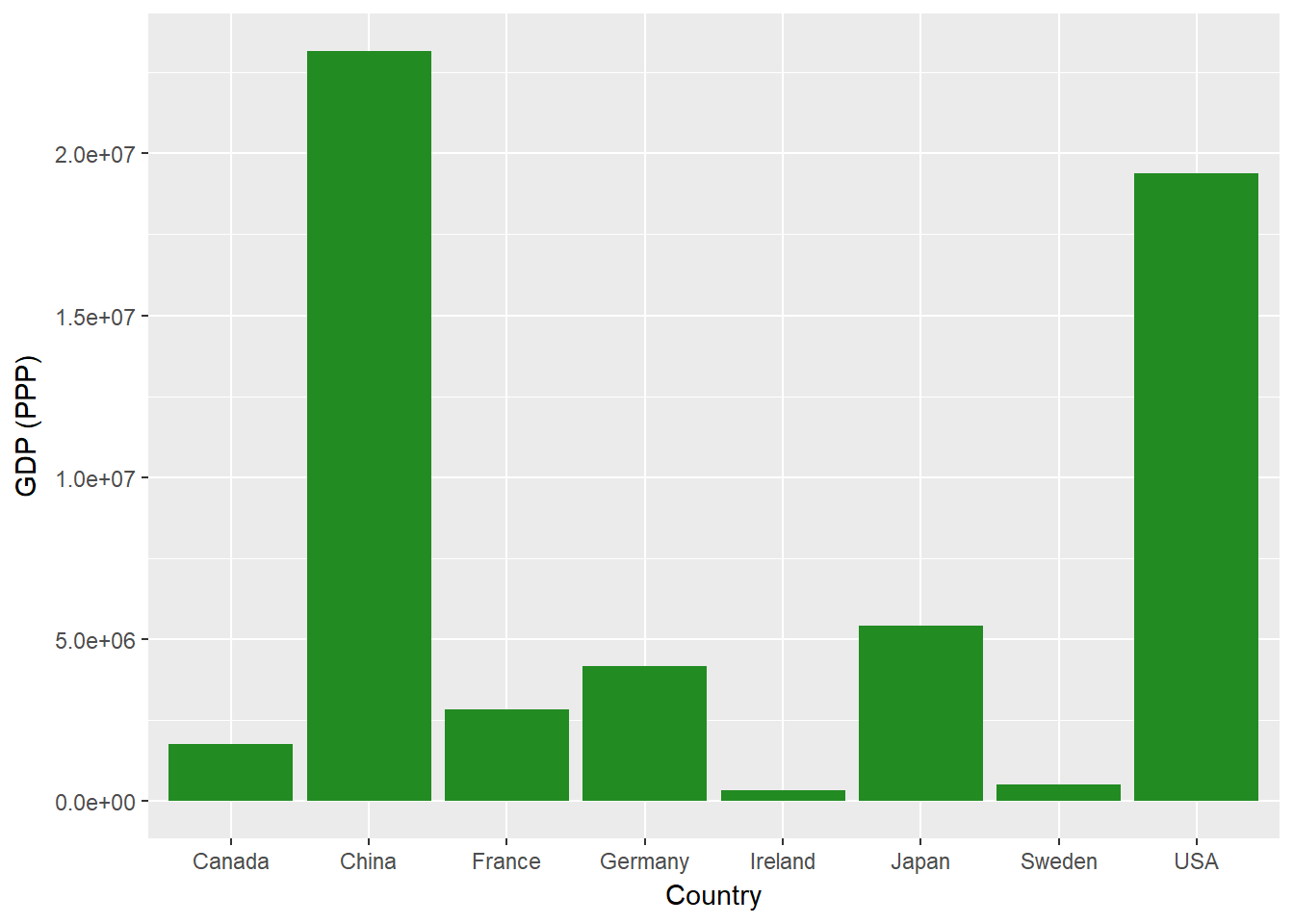
So erhältst du ein zweites separates Diagramm, das dem letzten ähnelt, aber eine andere Variable verwendet. Angenommen, du willst das nominale und das KKP-BIP zusammen darstellen. Dazu verwendest du die Facettierung. Zuerst musst du deine Daten neu formatieren, indem du sie von einem "breiten" Format mit jeder Variable in einer eigenen Spalte in ein "langes" Format umwandelst, in dem du eine Spalte für deine Messwerte und eine weitere für eine Schlüsselvariable verwendest, die uns sagt, welchen Messwert wir in jeder Zeile verwenden.
econdatalong <- gather(econdata, key="measure", value="value", c("GDP_nom", "GDP_PPP"))
Sobald du die Daten in einem solchen Format hast, kannst du unsere Schlüsselvariable verwenden, um mit Facetten zu zeichnen. Erstellen wir eine einfache Grafik, die sowohl das nominale BIP (aus unserer ersten Grafik) als auch das BIP (KKP) (aus unserer zweiten Grafik) zeigt. Dazu änderst du einfach deinen Code, fügst +facet_wrap() hinzu und gibst an, dass ~measure, unsere Schlüsselvariable, für die Facettierung verwendet werden soll.
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure)
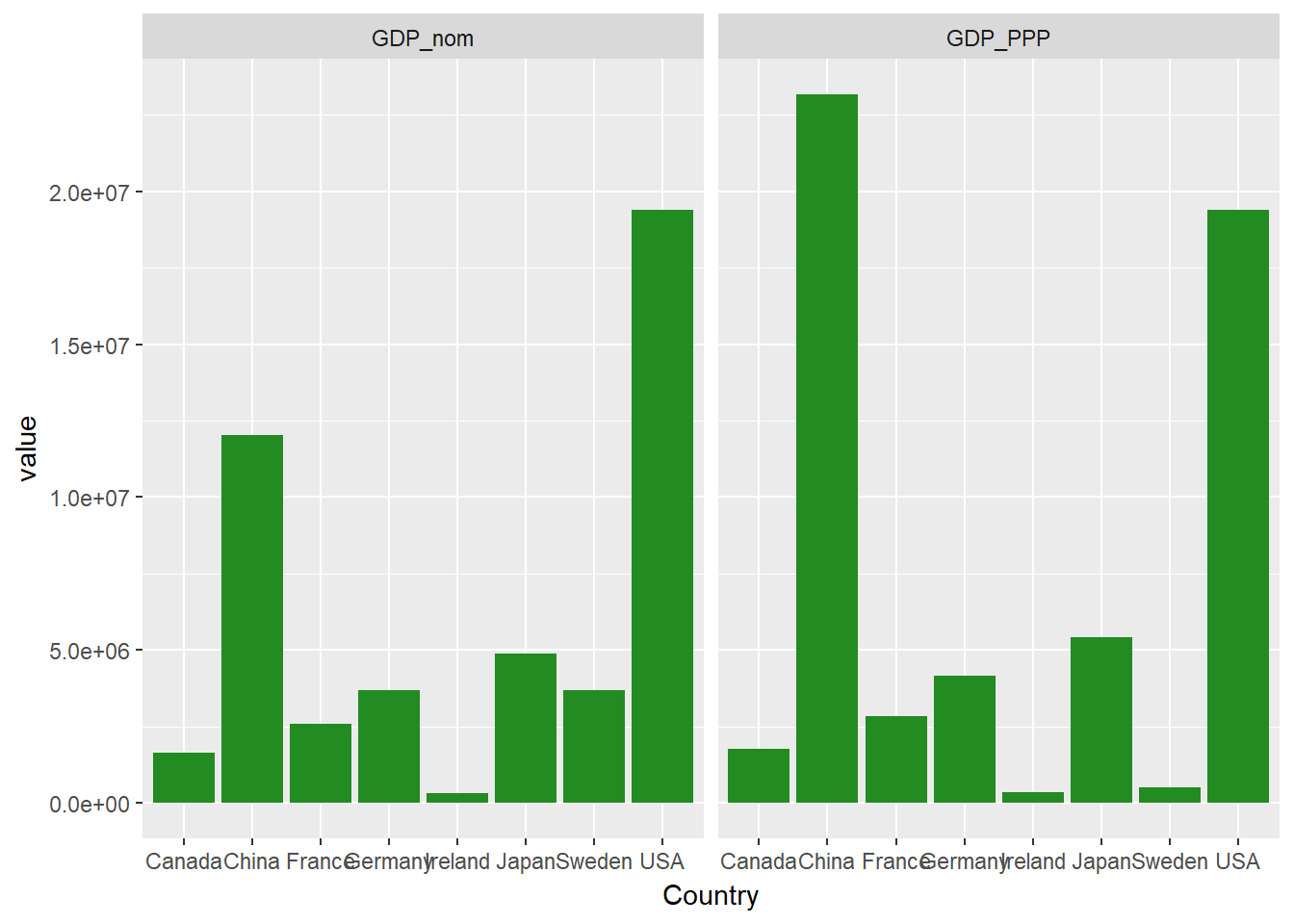
Das funktioniert, aber du wirst feststellen, wie zerquetscht die Ländernamen sind. Lass uns unsere Tafeln neu anordnen.
Der Befehl facet_wrap() wählt automatisch aus, wie viele Spalten verwendet werden sollen. Du kannst dies direkt mit ncol= angeben, etwa so:
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1)
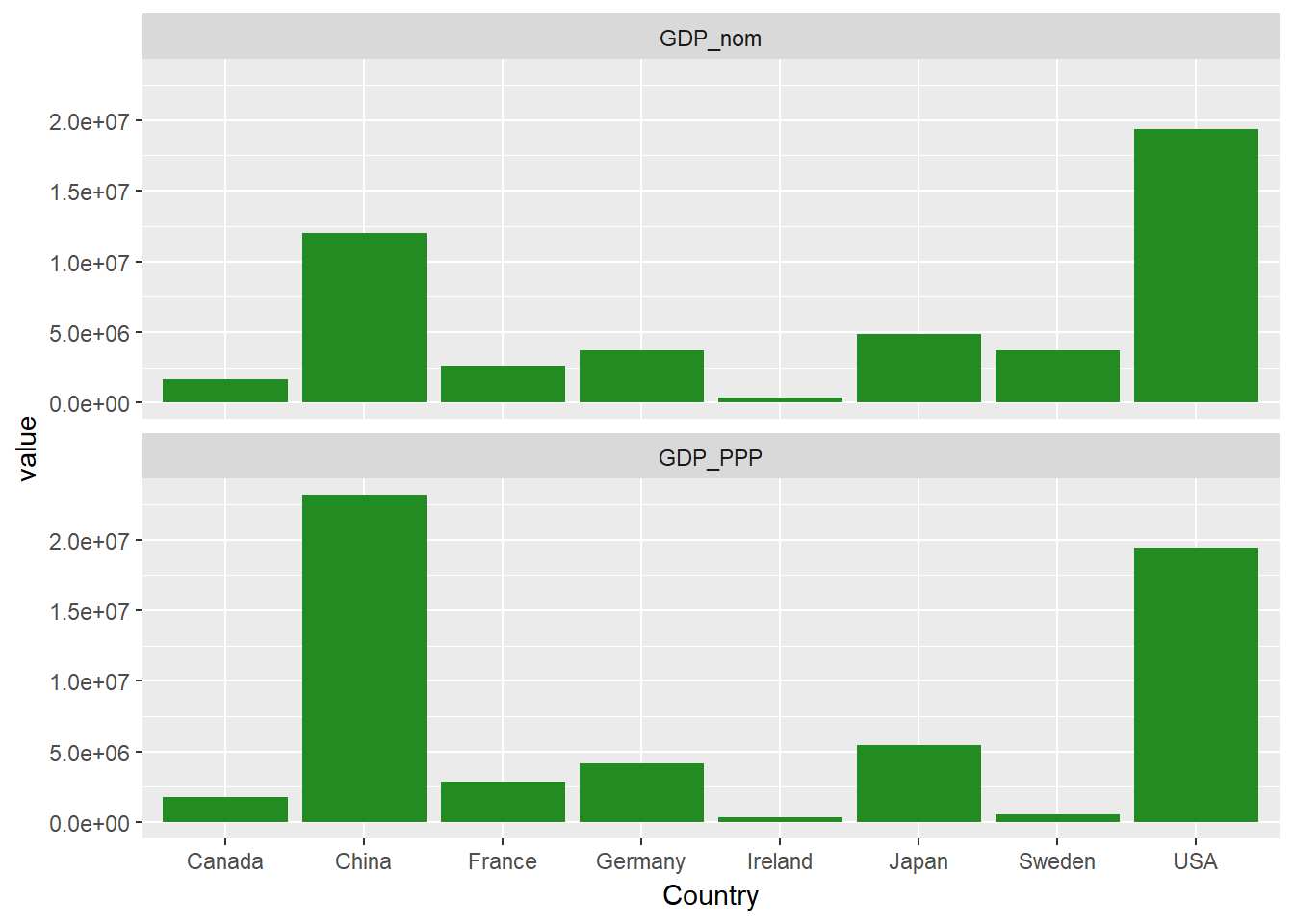
Du hast wahrscheinlich bemerkt, dass die Länder auf der x-Achse oben in alphabetischer Reihenfolge angeordnet sind. Wenn du das ändern möchtest, ist es am einfachsten, die Stufen des Country Faktors einzustellen. Ordnen wir die Länder in der Reihenfolge des gesamten nominalen BIPs neu an.
econdata$Country <- factor(econdata$Country, levels= econdata$Country[order(econdata$GDP_nom)])
econdatalong <- gather(econdata, key="measure", value="value", c("GDP_nom", "GDP_PPP"))
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1)
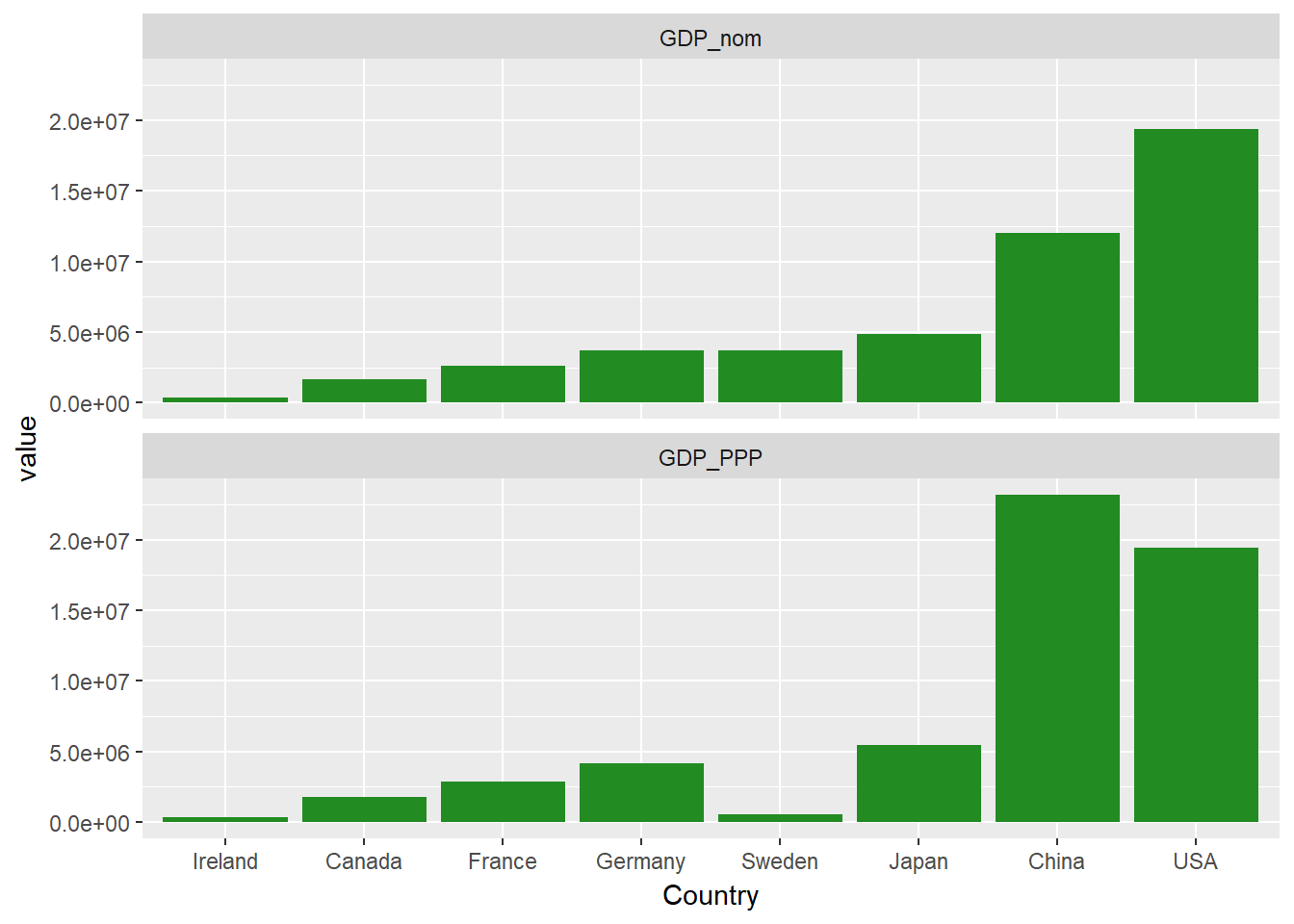
Du kannst auch einige zusätzliche Anpassungen vornehmen, z. B. die Facettenbeschriftungen mit dem Argument strip.position auf die linke Seite verschieben.
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1, strip.position = "left")
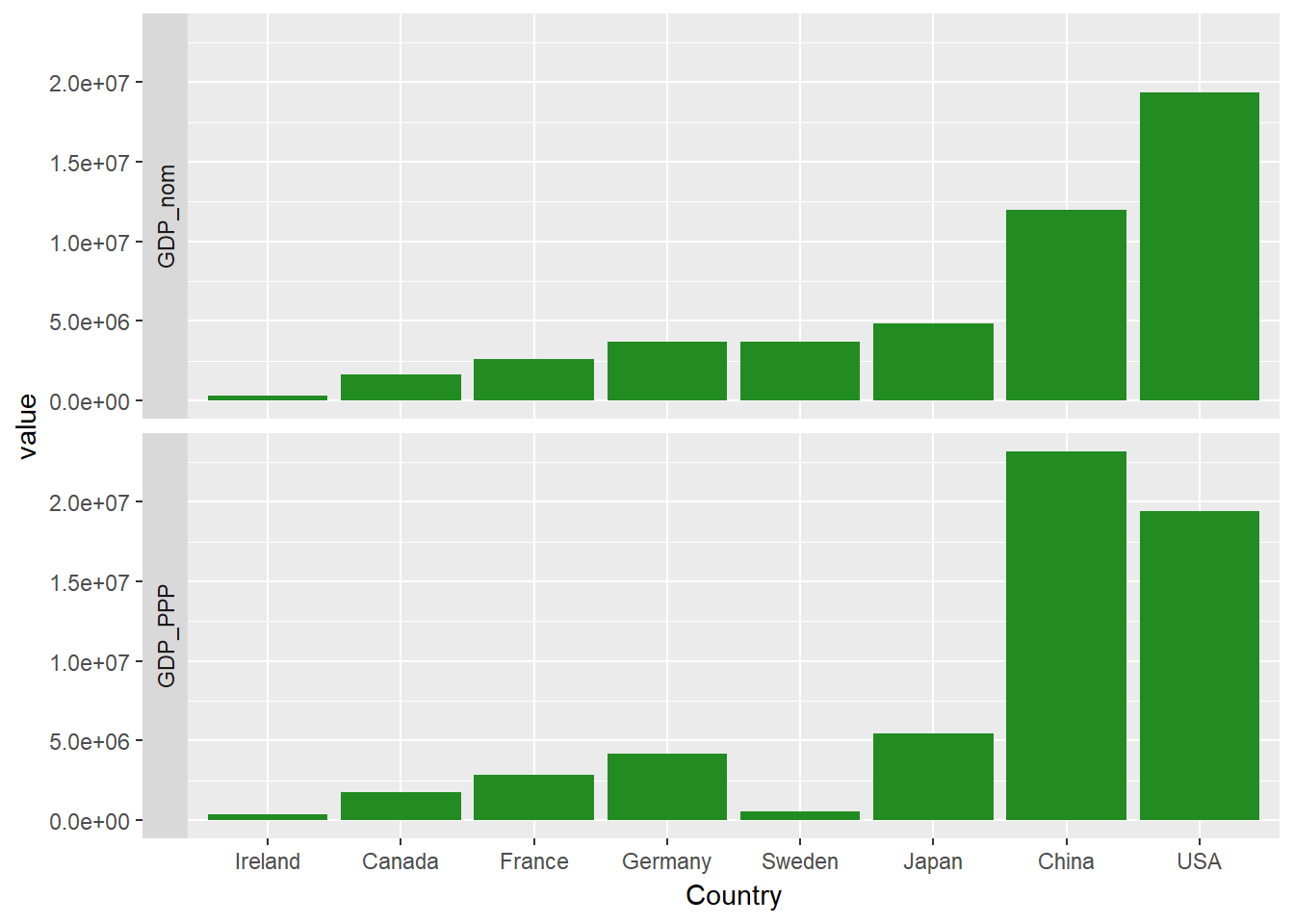
Du hast vielleicht bemerkt, dass die Facetten einfache kurze Überschriften haben, die von den Ebenen des Faktors measure stammen. Bringen wir etwas Ordnung in die Sache und geben wir unseren Facetten ein paar hübsche Namen. Zu diesem Zweck erstellst du eine einfache Labeller-Funktion, variable_labeller, die den entsprechenden Namen zurückgibt, wenn du nach einem der Werte von variable_names gefragt wirst. Dann übergibst du diese Funktion an das labeller Argument von facet_wrap.
variable_names <- list(
"GDP_nom" = "GDP (nominal)" ,
"GDP_PPP" = "GDP (purchasing power parity)"
)
variable_labeller <- function(variable,value){
return(variable_names[value])
}
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1, labeller=variable_labeller)
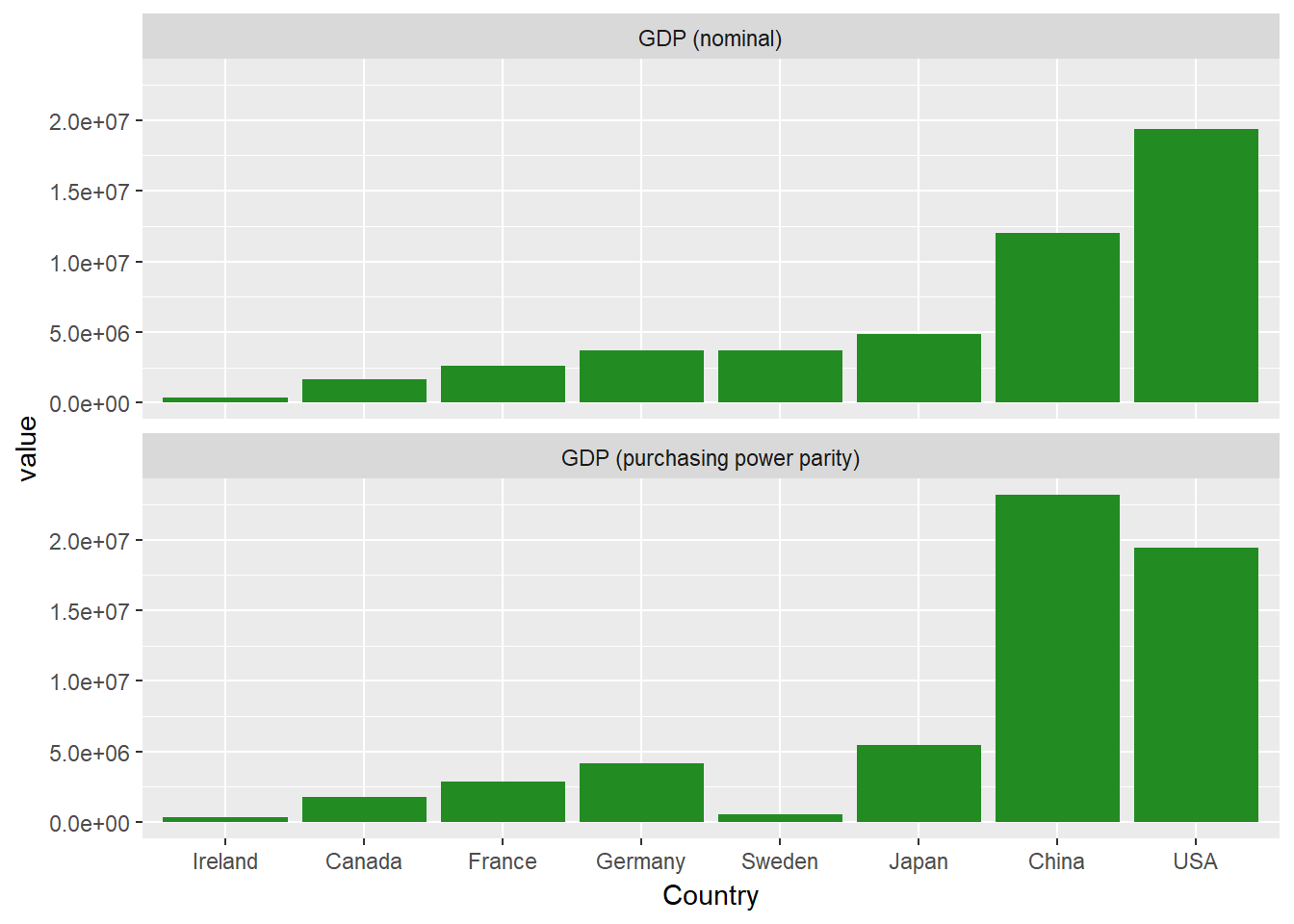
Lass uns eine größere Facettengrafik erstellen, indem wir jede der wirtschaftlichen Maßnahmen verwenden.
econdatalong <- gather(econdata, key="measure", value="value", c( "GDP_nom" , "GDP_PPP" ,"GDP_nom_per_capita", "GDP_PPP_per_capita" ,"GNI_per_capita"))
variable_names <- list(
"GDP_nom" = "GDP (nominal)" ,
"GDP_PPP" = "GDP (purchasing power parity)",
"GDP_nom_per_capita" = "GDP (nominal) per capita",
"GDP_PPP_per_capita" = "GDP (purchasing power parity) per capita",
"GNI_per_capita" = "GNI per capita"
)
variable_labeller <- function(variable,value){
return(variable_names[value])
}
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, ncol=1, labeller= variable_labeller)+
scale_y_continuous(breaks = pretty(econdatalong$value, n = 10))
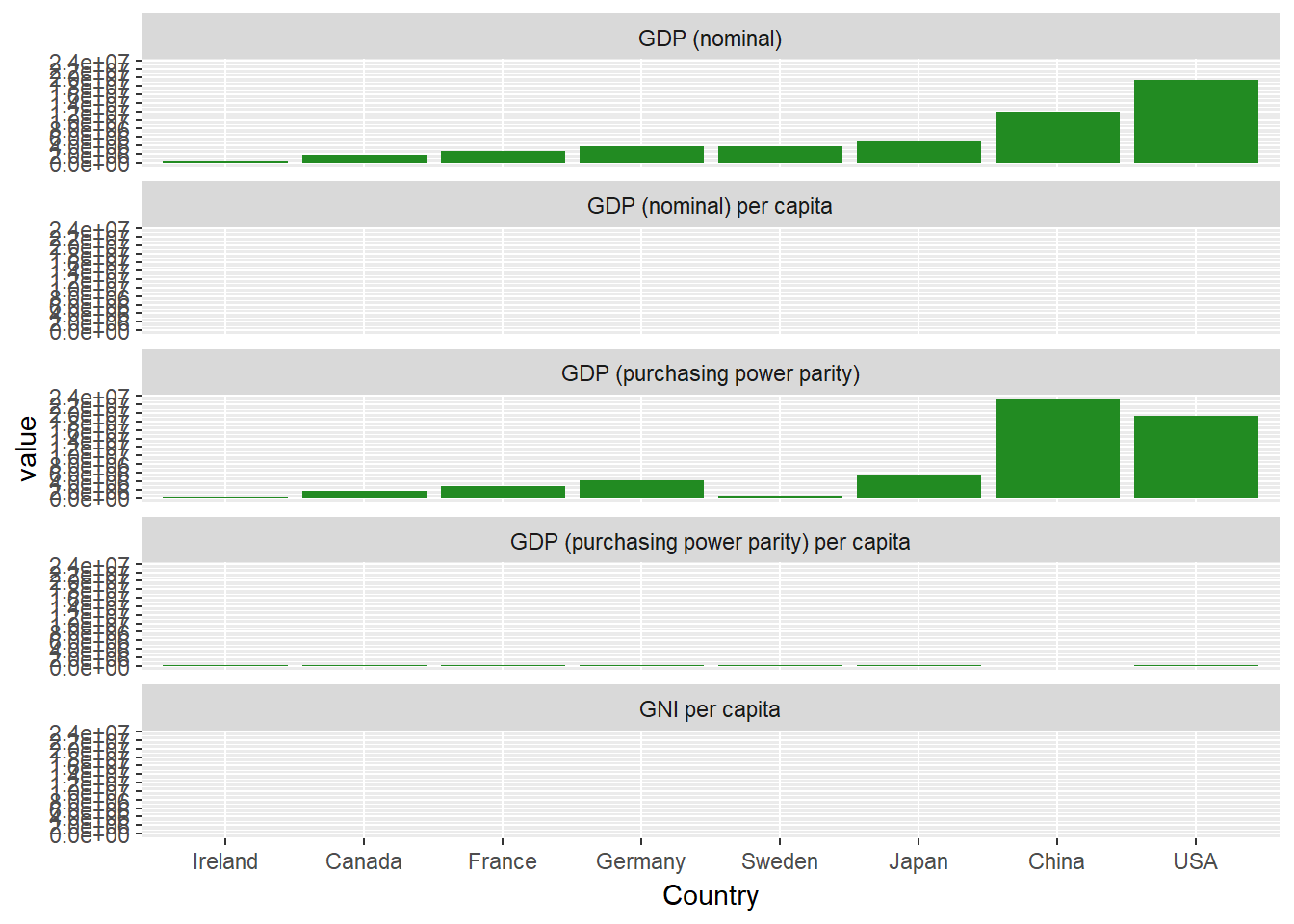
Das ist überhaupt nicht gut! Du kannst die Werte für drei der Tafeln nicht sehen. Warum ist das so? Werfen wir einen Blick auf die Primärdaten, um zu sehen, warum.
summary(econdata)## Country GDP_nom GDP_PPP GDP_nom_per_capita
## Ireland:1 Min. : 333994 Min. : 343682 Min. : 8643
## Canada :1 1st Qu.: 2350773 1st Qu.: 1457187 1st Qu.:39512
## France :1 Median : 3684816 Median : 3503268 Median :44814
## Germany:1 Mean : 6027118 Mean : 7202368 Mean :44992
## Sweden :1 3rd Qu.: 6657754 3rd Qu.: 8919260 3rd Qu.:54789
## Japan :1 Max. :19390600 Max. :23159107 Max. :70638
## (Other):2
## GDP_PPP_per_capita GNI_per_capita Region
## Min. :16807 Min. : 8690 Asia :2
## 1st Qu.:43327 1st Qu.:38405 Europe :4
## Median :49174 Median :43180 North America:2
## Mean :48094 Mean :42215
## 3rd Qu.:53322 3rd Qu.:53265
## Max. :72632 Max. :58270
##Wenn du dir die einzelnen Spalten ansiehst, siehst du, dass die Werte in jeder Spalte um einige Größenordnungen variieren. Standardmäßig verwendet die Facettierung dieselben Grenzen und Bereiche für die X- und Y-Achse. Um das zu ändern, kannst du diesen Code-Schnipsel in deinen Facettencode einfügen: scales="free_y", damit jede Facette ihren eigenen, unabhängigen Maßstab verwendet.
ggplot(econdatalong, aes(x=Country, y=value))+
geom_bar(stat='identity', fill="forest green")+
facet_wrap(~measure, scales="free_y", ncol=1, labeller= variable_labeller)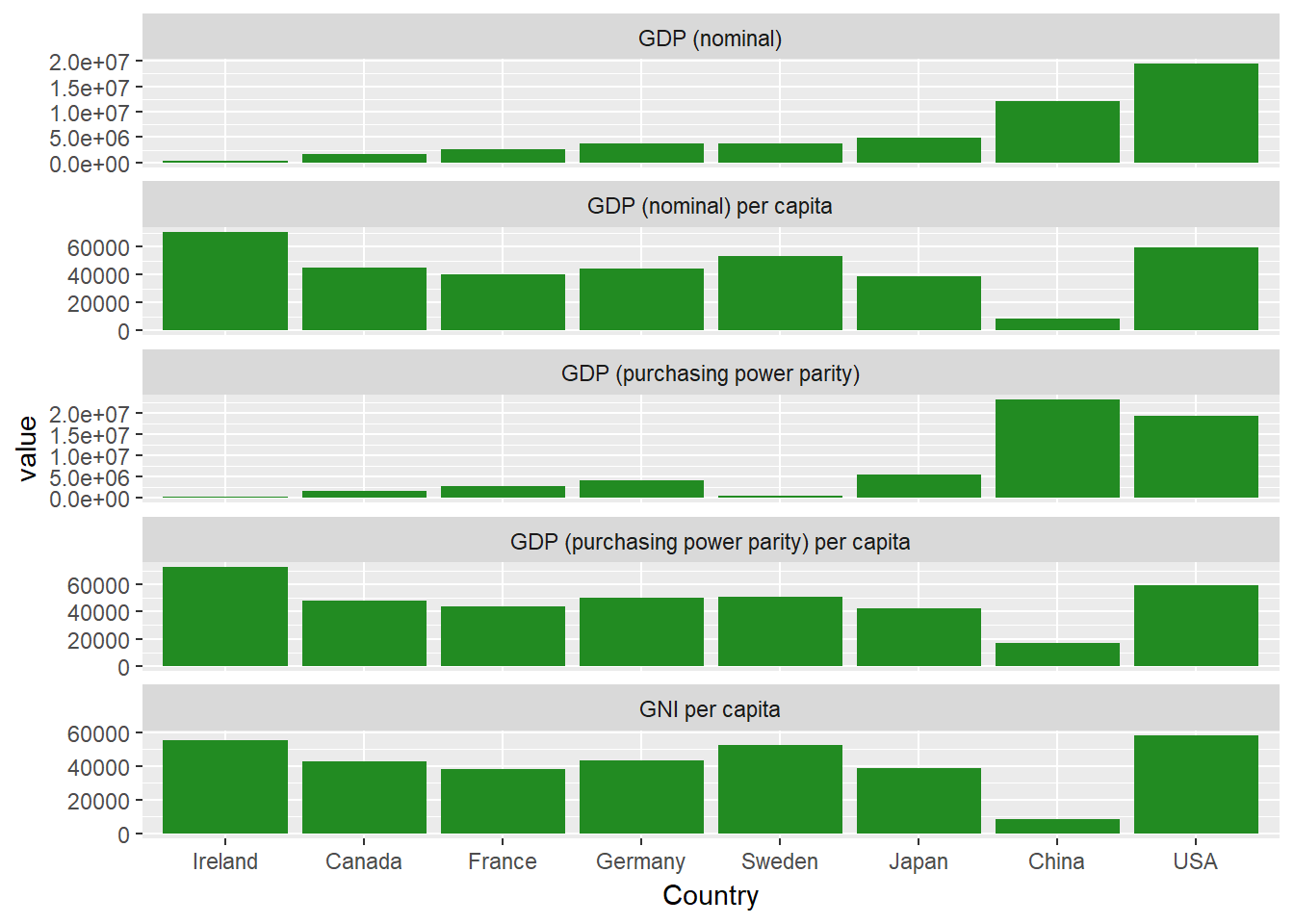
Das ist viel besser. Jede Facette hat jetzt ihre eigene unabhängige y-Achse.
Du hast vielleicht bemerkt, dass unser Datensatz auch die Variable Region enthält, die angibt, in welcher Region sich das betreffende Land befindet. Du kannst diese Variable verwenden, um unsere Balken je nach Region wie folgt einzufärben:
ggplot(econdatalong, aes(x=Country, y=value, fill=Region))+
geom_bar(stat='identity')+
facet_wrap(~measure, scales="free_y", ncol=1, labeller= variable_labeller)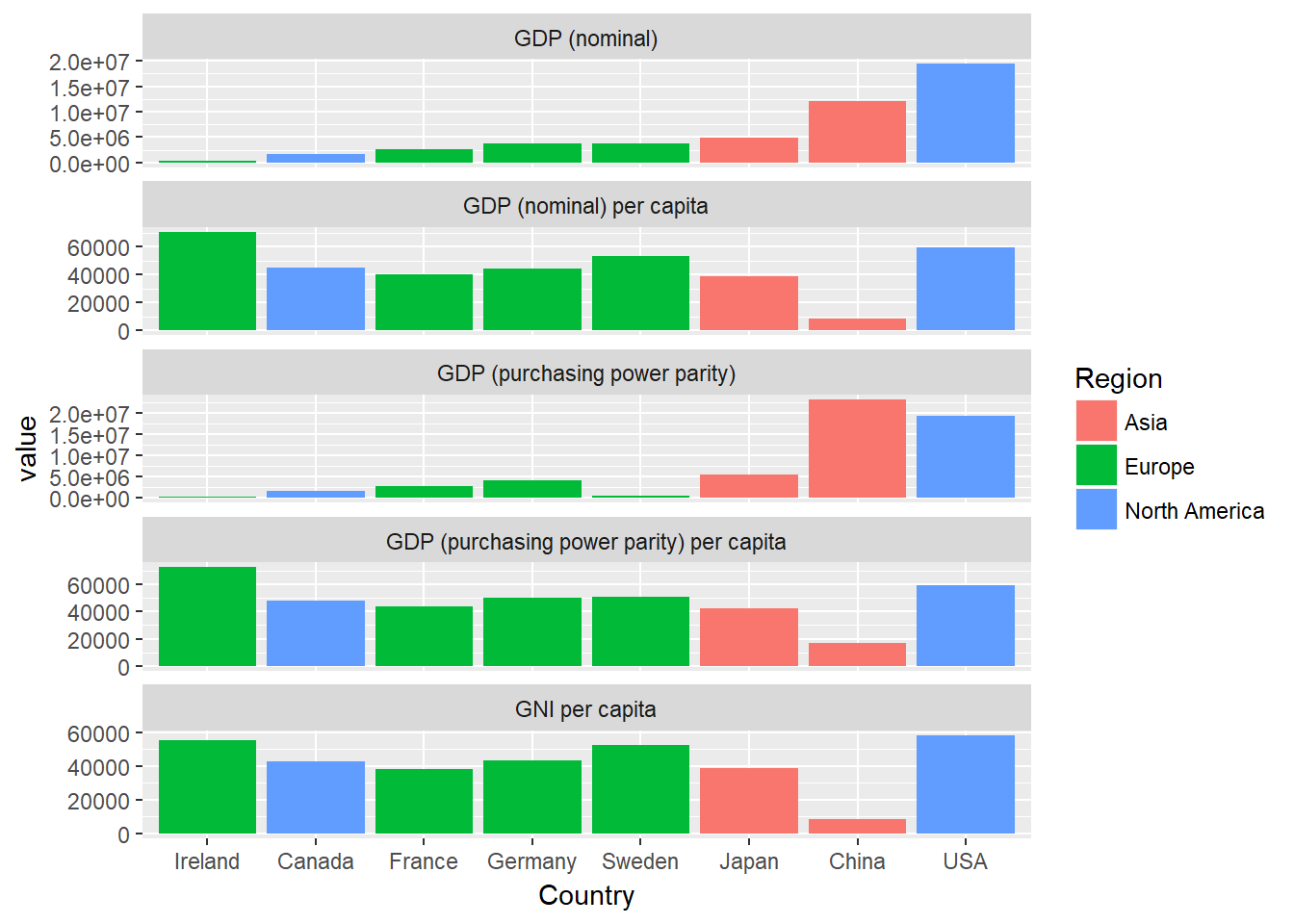
Das ist allerdings etwas unübersichtlich. Wäre es nicht schön, wenn du jede der verschiedenen Regionen in ein eigenes Unter-Panel packen könntest? Nun, mit Facettenschliff kannst du das! Hier verwendest du facet_grid anstelle von facet_wrap, da dies die Zuordnung unserer Facetten zu zwei Variablen, Region und measure, vereinfacht, wobei diese beiden Variablen über die Zeilen und Spalten eines Rasters von Plots verteilt sind. Beachte, dass du auch scales="free" und space="free" einstellst, damit unsere verschiedenen Tafeln unterschiedlich viel Platz einnehmen können. Du musst auch eine neue Beschriftungsfunktion erstellen, die Namen für Zeilen und Beschriftungen erzeugt.
variable_names <- list(
"GDP_nom" = "GDP \n(nominal)" ,
"GDP_PPP" = "GDP \n(PPP)",
"GDP_nom_per_capita" = "GDP (nominal)\n per capita",
"GDP_PPP_per_capita" = "GDP (PPP)\n per capita",
"GNI_per_capita" = "GNI \nper capita"
)
region_names <- levels(econdata$Region)
variable_labeller2 <- function(variable,value){
if (variable=='measure') {
return(variable_names[value])
} else {
return(region_names)
}
}
ggplot(econdatalong, aes(x=Country, y=value, fill=Region))+
geom_bar(stat='identity')+
facet_grid(measure~Region, scales="free", space="free_x", labeller= variable_labeller2)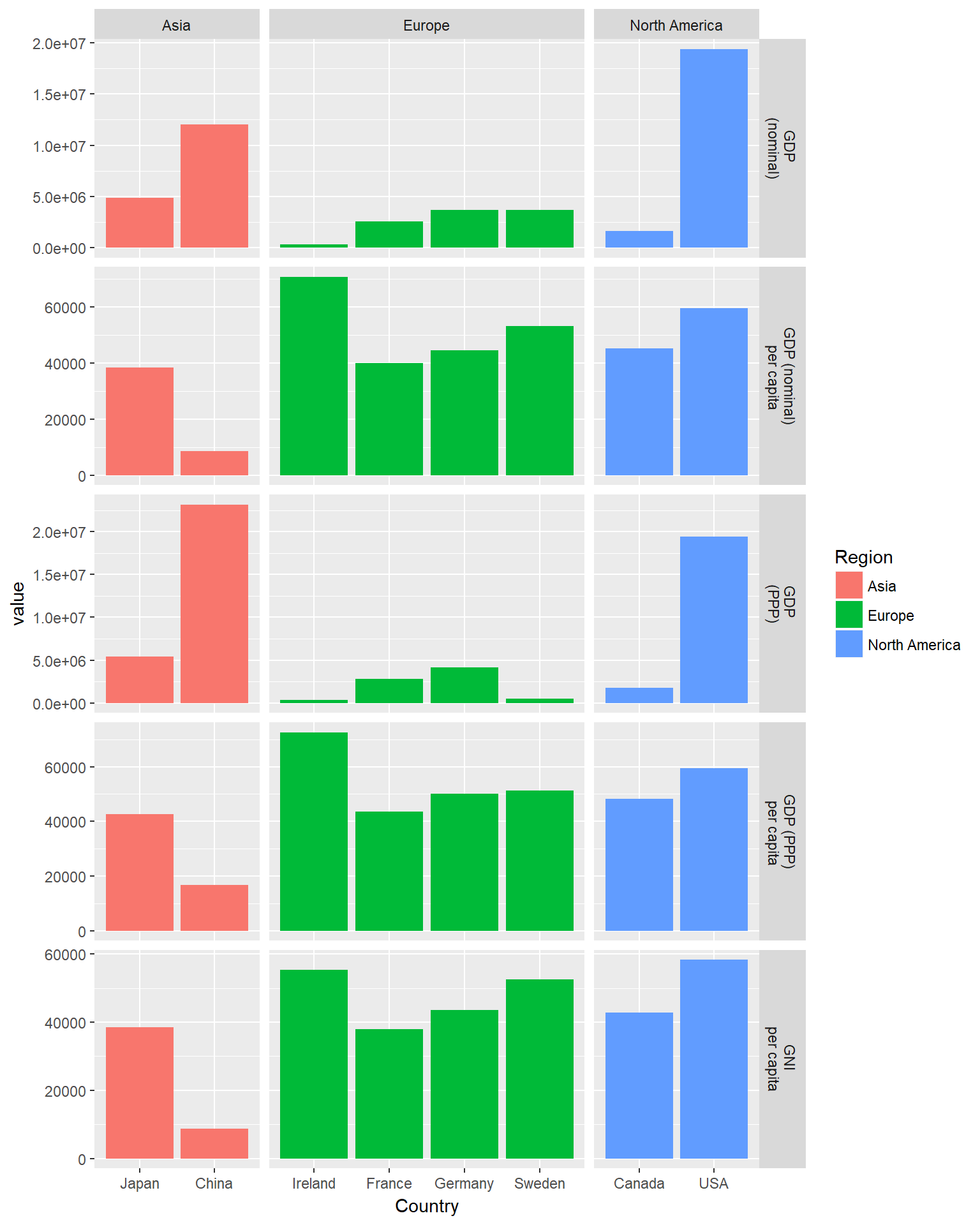
Jetzt ist es viel klarer! Jede Region hat eine eigene Spalte mit Tafeln und jede Kennzahl eine eigene Reihe mit Balken.
Das war's dann auch schon für dieses Tutorial. Ich hoffe, es hat dir gefallen, etwas über Facetten zu lernen.
Wenn du mehr über Facetten erfahren möchtest, besuche den DataCamp-Kurs Visualisierung von Big Data mit Trelliscope.
Schau dir unser Getting Started with the Tidyverse an: Tutorial.
R Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
