
Cursus
Fondamentaux d’OpenAI
15 h
Avec le lancement de GPT-5, OpenAI a élargi l'appel d'outils/fonctions dans l'API pour inclure des appels d'outils en format libre (texte brut, sans JSON), des contraintes grammaticales via Lark/CFG, des listes d'outils autorisés et un raisonnement amélioré sur l'utilisation des outils. Ensemble, ces éléments font de GPT-5 un modèle véritablement agentique ; vous pouvez connecter des API, des bases de données et des outils personnalisés à l'API Responses et générer des réponses fondées, voire automatiser des flux de travail.
Dans ce tutoriel, je vais aborder les outils fonctionnels. outils de fonctionet les outils personnalisés, les les contraintes grammaticales, listes d'autorisation d'outilset préambules, avec des exemples de code et des explications claires sur leur fonctionnement et leur utilisation.
L'appel de fonction dans GPT-5 vous permet d'améliorer le modèle grâce aux données et aux actions de votre application. Le modèle peut déterminer quand faire appel à un outil, tandis que vous gérez la logique et renvoyez les résultats pour obtenir une réponse finale et fondée.
Types d'appels de fonction :
GPT-5 prend en charge à la fois les outils fonctionnels structurés (utilisant JSON Schema) et les outils personnalisés qui acceptent des charges utiles de texte en format libre (telles que SQL, scripts ou configurations) pour une intégration transparente avec des environnements d'exécution externes.
Les outils fonctionnels sont définis par JSON Schema, ce qui garantit que le modèle comprend exactement quels arguments transmettre et permet une validation stricte des entrées. Pour en savoir plus, veuillez consulter notre tutoriel sur les appels de fonction OpenAI.
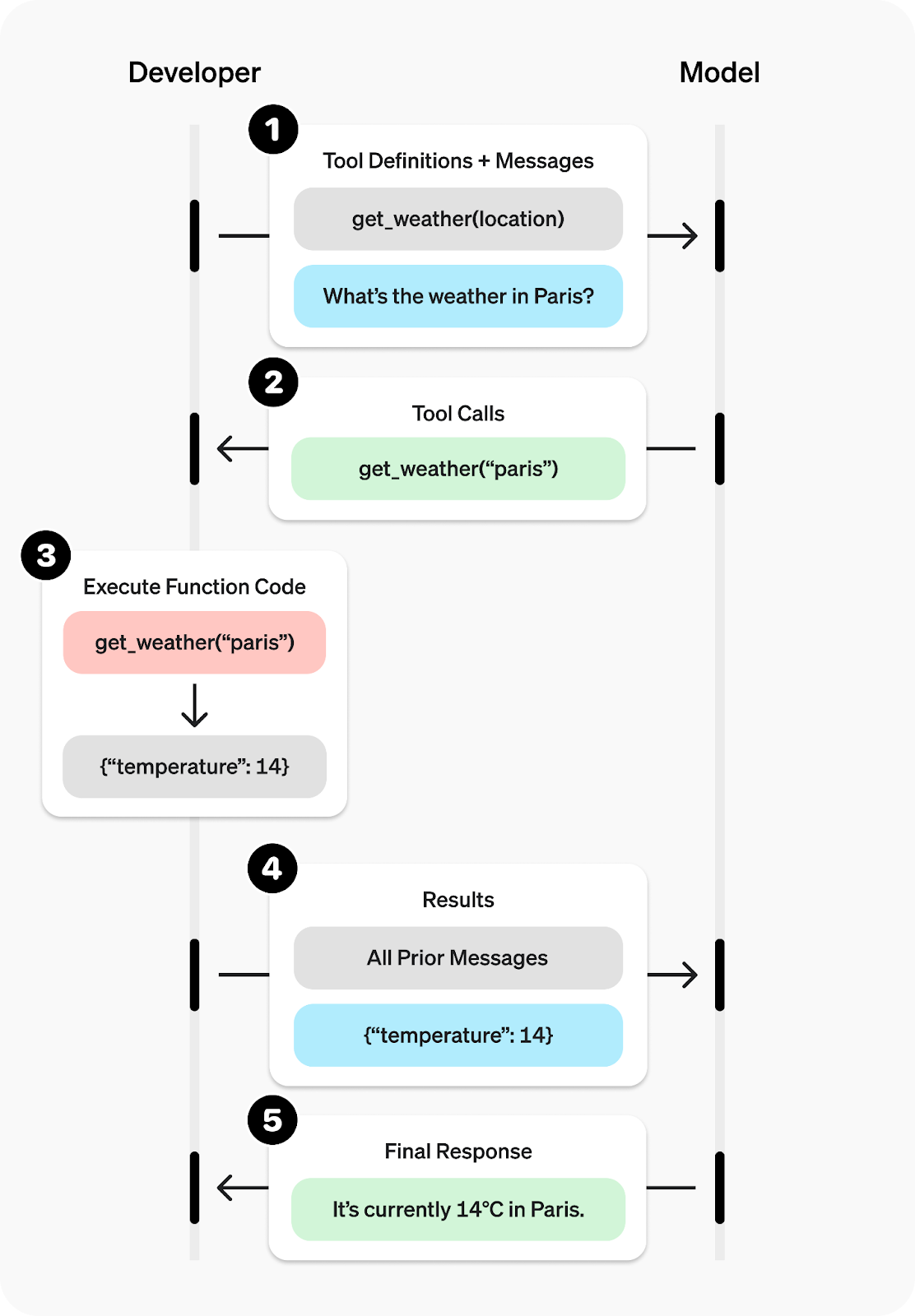
Source : Appel de fonction - API OpenAI
L'utilisation des outils fonctionnels avec JSON Schema vous permet d'obtenir des résultats prévisibles et structurés à partir du modèle. Le modèle évalue les outils que vous avez déclarés, détermine quand utiliser l'un d'entre eux, propose des arguments validés JSON, puis exécute la fonction correspondante dans votre code.
Ensuite, vous pouvez demander au modèle de générer une réponse basée uniquement sur les données renvoyées par l'outil, en veillant à ce que le résultat soit fondé, lisible par machine et facile à intégrer.
Cet exemple illustre plusieurs concepts clés :
pip install openai.Veuillez fournir une liste d'outils avec un nom, une description et un schéma JSON pour les paramètres. Le schéma aide le modèle à fournir des arguments bien formés.
make_coffee attend un paramètre de type chaîne : coffee_type.random_coffee_fact ne prend aucun paramètre (objet vide). Ces définitions sont transmises via l'argument ` tools ` dans l'appel API afin que le modèle puisse identifier les éléments disponibles.import os
from openai import OpenAI
import json
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
tools = [
{
"type": "function",
"name": "make_coffee",
"description": "Gives a simple recipe for making a coffee drink.",
"parameters": {
"type": "object",
"properties": {
"coffee_type": {
"type": "string",
"description": "The coffee drink, e.g. espresso, cappuccino, latte"
}
},
"required": ["coffee_type"],
},
},
{
"type": "function",
"name": "random_coffee_fact",
"description": "Returns a fun fact about coffee.",
"parameters": {"type": "object","properties":{}}
}
]
Vous implémentez les fonctions Python qui effectuent réellement le travail :
make_coffee(coffee_type) Renvoie une chaîne concise contenant la recette correspondant à la boisson demandée.random_coffee_fact() renvoie une petite charge utile factuelle. Les deux renvoient des dictionnaires sérialisables en JSON, ce qui est idéal pour les renvoyer au modèle.
def make_coffee(coffee_type):
recipes = {
"espresso": "Grind fine, 18g coffee → 36g espresso in ~28s.",
"cappuccino": "Brew 1 espresso shot, steam 150ml milk, pour and top with foam.",
"latte": "Brew 1 espresso shot, steam 250ml milk, pour for silky texture.",
}
return {"coffee_type": coffee_type, "recipe": recipes.get(coffee_type.lower(), "Unknown coffee type!")}
def random_coffee_fact():
return {"fact": "Coffee is the second most traded commodity in the world, after oil."}Commencez la conversation par la question de l'utilisateur : {"role": "user", "content": "How do I make a latte?"}
Le modèle peut renvoyer des messages contenant un élément function_call, tel que make_coffee avec {"coffee_type":"latte"}. Veuillez ensuite ajouter les messages du modèle dans input_list: input_list += response.output. Cela permet de conserver l'état de la conversation pour le tour suivant.
# Track used tools
used_tools = []
input_list = [{"role": "user", "content": "How do I make a latte?"}]
response = client.responses.create(
model="gpt-5",
tools=tools,
input=input_list,
)
input_list += response.outputVeuillez parcourir response.output et identifier les éléments pour lesquels item.type est égal à "function_call". Pour ces éléments, veuillez analyser item.arguments et transmettre les requêtes à vos fonctions Python.
Pour la fonction d'make_coffee, veuillez l'appeler en utilisant make_coffee(args["coffee_type"]). Pour la fonction d' random_coffee_fact, veuillez simplement appeler random_coffee_fact().
Après avoir exécuté les fonctions, veuillez ajouter un message d' function_call_output e comprenant les éléments suivants :
call_id (qui relie cette sortie à la requête du modèle) output (une chaîne JSON représentant le résultat de votre fonction).for item in response.output:
if getattr(item, "type", "") == "function_call":
used_tools.append(item.name)
args = json.loads(item.arguments or "{}")
if item.name == "make_coffee":
result = make_coffee(args["coffee_type"])
elif item.name == "random_coffee_fact":
result = random_coffee_fact()
else:
result = {"error": f"Unknown tool {item.name}"}
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps(result)
})Vous effectuez un deuxième appel à client.responses.create, en transmettant l'input_list mise à jour qui inclut désormais les résultats de l'outil.
La variable used_tools enregistre les noms des outils qui apparaissent dans les appels de fonction du modèle. Nous l'utiliserons pour indiquer quels outils ont été employés.
final = client.responses.create(
model="gpt-5",
tools=tools,
input=input_list,
instructions="Answer using only the tool results."
)
print("Final output:\n", final.output_text)
print("\n--- Tool Usage ---")
for t in tools:
status = "USED ✅" if t["name"] in used_tools else "NOT USED ❌"
print(f"{t['name']}: {status}")Étant donné que l'utilisateur a demandé un café au lait, le modèle a sélectionné make_coffee avec coffee_type = "latte". Votre code l'a exécuté et la réponse finale a été générée uniquement à partir du résultat de cet outil.
Final output:
{"coffee_type":"latte","recipe":"Brew 1 espresso shot, steam 250ml milk, pour for silky texture."}
--- Tool Usage ---
make_coffee: USED ✅
random_coffee_fact: NOT USED ❌Utilisez les outils personnalisés de format libre de GPT-5 pour permettre au modèle d'envoyer du texte brut directement à votre outil, tel que du code, du SQL, des commandes shell ou un simple CSV, sans nécessiter de schéma JSON.
Cette fonctionnalité va au-delà des anciens appels de fonction JSON uniquement, vous offrant une plus grande flexibilité pour l'intégration avec des exécuteurs, des moteurs de requête ou des interpréteurs de langage spécifique au domaine (DSL).
En mode libre, le modèle génère un appel d'outil personnalisé avec une charge utile de texte non structuré que vous pouvez acheminer vers votre environnement d'exécution. Vous renvoyez ensuite le résultat au modèle afin qu'il finalise la réponse destinée à l'utilisateur.
Nous allons maintenant écrire le code qui permet au modèle de sélectionner les outils appropriés et de renvoyer du texte brut non structuré comme résultat. Cette sortie sera ensuite transmise à une fonction Python afin de générer un résultat. De cette manière, l'utilisateur peut indiquer les ingrédients dont il dispose, et le modèle générera des recettes adaptées à ses besoins.
Dans cet exemple de code, nous avons :
meal_planner qui accepte les entrées de texte brut.plan_meal, un programme Python qui prend en entrée une liste d'ingrédients séparés par des virgules et propose une suggestion de repas en réponse.plan_meal, puis renvoyé le résultat au modèle sous forme d' function_call_output, lié via call_id.from openai import OpenAI
import json
import random
client = OpenAI()
# --- Custom tool ---
tools = [
{
"type": "custom",
"name": "meal_planner",
"description": "Takes ONLY a comma-separated list of ingredients and suggests a meal idea."
}
]
# --- Fake meal planner ---
def plan_meal(ingredients: str) -> str:
ideas = [
f"Stir-fry: {ingredients} with garlic & soy sauce.",
f"One-pot rice: cook {ingredients} together in broth until fluffy.",
f"Soup: simmer {ingredients} in stock with herbs.",
f"Sheet-pan bake: roast {ingredients} at 200°C for ~20 min."
]
return random.choice(ideas)
# --- Start conversation ---
messages = [
{"role": "user", "content": "I only have chicken, rice, and broccoli. Any dinner ideas?"}
]
# 1) Ask model with clear instruction
resp = client.responses.create(
model="gpt-5",
tools=tools,
input=messages,
instructions="If the user mentions ingredients, call the meal_planner tool with ONLY a comma-separated list like 'chicken, rice, broccoli'."
)
messages += resp.output
# 2) Find the tool call
tool_call = next((x for x in resp.output if getattr(x, "type", "") == "custom_tool_call"), None)
assert tool_call, "No tool call found!"
# Get clean CSV input
ingredients_csv = tool_call.input.strip()
# 3) Run the tool
meal_result = plan_meal(ingredients_csv)
# 4) Send tool output back
messages.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": meal_result
})
# 5) Final model response
final = client.responses.create(
model="gpt-5",
tools=tools,
input=messages,
instructions="Turn the meal idea into a short recipe with 3-4 steps."
)
print("\n--- Tool Call ---")
print("Name:", tool_call.name)
print("Input:", ingredients_csv)
print("Output:", meal_result)
print("\n--- Final Output ---\n", final.output_text)En conséquence, nous avons reçu des statistiques sur les outils utilisés, notamment l'installation, la saisie et la sortie. De plus, le résultat final fournit une recette complète sur la manière de préparer le repas.
--- Tool Call ---
Name: meal_planner
Input: chicken, rice, broccoli
Output: One-pot rice: cook chicken, rice, broccoli together in broth until fluffy.
--- Final Output ---
One-Pot Chicken, Rice & Broccoli
- Season bite-size chicken pieces with salt and pepper; sear in a little oil in a pot until lightly browned.
- Add 1 cup rinsed rice and 2 cups broth (or water + salt). Bring to a boil, then cover and simmer on low for 12 minutes.
- Scatter 2 cups small broccoli florets on top, cover, and cook 5-7 more minutes until rice is fluffy and broccoli is tender.
- Rest 5 minutes off heat, fluff, and adjust seasoning. Optional: stir in a knob of butter or a splash of soy.GPT-5 prend désormais en charge la grammaire sans contexte (CFG) afin de garantir un contrôle rigoureux des formats de sortie.
En appliquant une grammaire, telle que SQL ou un langage spécifique à un domaine (DSL), à ses réponses, GPT-5 garantit que les résultats respectent systématiquement la structure requise. Le CFG revêt une importance particulière pour les processus automatisés et les flux de travail à haut risque.
GPT-5 peut utiliser des grammaires définies dans des formats tels que Lark pour limiter les résultats de l'outil lors de la génération. Cette approche du décodage contraint améliore la fiabilité en empêchant la dérive des formats et en garantissant la cohérence structurelle.
Nous allons maintenant écrire le code permettant au modèle de sélectionner un outil et de générer UNIQUEMENT une expression arithmétique grammaticalement valide ; cette expression est ensuite évaluée en Python, le résultat est renvoyé à la conversation et la réponse finale est présentée clairement en langage naturel.
Dans cet exemple de code, nous avons :
math_solver qui doit produire UNIQUEMENT une expression arithmétique grammaticalement valide (Lark CFG).math_solver avec une expression conforme à la grammaire.call_id e d'origine.from openai import OpenAI
import json
client = OpenAI()
# --- Local fake evaluator ---
def eval_expression(expr: str) -> str:
try:
# Evaluate safely using Python's eval on restricted globals
result = eval(expr, {"__builtins__": {}}, {})
return f"{expr} = {result}"
except Exception as e:
return f"Error evaluating expression: {e}"
# --- Custom tool with grammar constraint ---
tools = [
{
"type": "custom",
"name": "math_solver",
"description": "Solve a math problem by outputting ONLY a valid arithmetic expression.",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": r"""
start: expr
?expr: term
| expr "+" term -> add
| expr "-" term -> sub
?term: factor
| term "*" factor -> mul
| term "/" factor -> div
?factor: NUMBER
| "(" expr ")"
%import common.NUMBER
%ignore " "
"""
},
}
]
# --- User asks ---
msgs = [
{"role": "user", "content": "What is (12 + 8) * 3 minus 5 divided by 5?"}
]
# 1) First model call: GPT-5 must emit a grammar-valid expression
resp = client.responses.create(
model="gpt-5",
tools=tools,
input=msgs,
instructions="Always call the math_solver tool with a grammar-valid arithmetic expression like '(12 + 8) * 3 - 5 / 5'."
)
msgs += resp.output
tool_call = next(
x for x in resp.output
if getattr(x, "type", "") in ("custom_tool_call", "tool_call", "function_call")
)
expr = getattr(tool_call, "input", "") or getattr(tool_call, "arguments", "")
print("\n=== Grammar-Constrained Expression ===")
print(expr)
# 2) Run the local evaluator
tool_result = eval_expression(expr)
print("\n=== Tool Execution Result ===")
print(tool_result)
# 3) Return tool output
msgs.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": tool_result
})
# 4) Final pass: GPT-5 presents answer nicely
final = client.responses.create(
model="gpt-5",
input=msgs,
tools=tools,
instructions="Present the evaluated result clearly in natural language."
)
print("\n=== Final Output ===")
print(final.output_text)Comme vous pouvez le constater, le modèle a sélectionné l'outil, puis généré une expression conforme aux règles grammaticales. Ensuite, il est transmis à la fonction Python afin de générer la réponse. Au final, nous obtenons une réponse appropriée en langage naturel.
=== Grammar-Constrained Expression ===
(12 + 8) * 3 - 5 / 5
=== Tool Execution Result ===
(12 + 8) * 3 - 5 / 5 = 59.0
=== Final Output ===
59Le paramètre « allowed_tools » vous permet de limiter le modèle à une sélection sécurisée d'outils parmi l'ensemble de vos outils. Cela améliore la prévisibilité et empêche les appels d'outils non intentionnels, tout en offrant au modèle une certaine flexibilité dans le cadre de l'ensemble autorisé.
Vous pouvez permettre au modèle de choisir parmi les outils autorisés ou exiger qu'il en utilise un, reflétant ainsi les comportements de « force tool » observés dans d'autres piles et s'alignant sur les meilleures pratiques générales en matière d'orchestration des appels d'outils.
Nous allons maintenant écrire le code qui autorise un seul outil, demande au modèle d'appeler uniquement cet outil, l'exécute, renvoie les résultats, puis génère un résumé concis destiné à l'utilisateur.
Remarque : Veuillez créer un compte gratuit compte Firecrawl, générez une clé API, enregistrez-la en tant que variable d'environnement FIRECRAWL_API_KEY et installez le SDK Python Firecrawl à l'aide de pip install firecrawl-py.
Dans cet exemple de code, nous avons :
dummy_web_search et firecrawl_search.firecrawl_search uniquement via tool_choice = { type: "allowed_tools", mode: "required", tools: [...] }.firecrawl_search est invoqué, les arguments désérialisés, Firecrawl exécuté, sa réponse est convertie en un dictionnaire sérialisable JSON, et la charge utile de données sécurisée est extraite.function_call_output, lié par call_id, puis un appel final au modèle a été effectué pour résumer le tout en 3 ou 4 points avec des liens Markdown.from openai import OpenAI
from firecrawl import Firecrawl
import json
import os
client = OpenAI()
firecrawl = Firecrawl(api_key=os.environ["FIRECRAWL_API_KEY"])
# --- Full toolset ---
tools = [
{
"type": "function",
"name": "dummy_web_search",
"description": "A fake web search that always returns static dummy results.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"limit": {"type": "integer"}
},
"required": ["query"]
},
},
{
"type": "function",
"name": "firecrawl_search",
"description": "Perform a real web search using Firecrawl.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"limit": {"type": "integer"}
},
"required": ["query"]
},
},
]
# --- Dummy implementation ---
def dummy_web_search(query, limit=3):
return {
"query": query,
"results": [f"[Dummy] Result {i+1} for '{query}'" for i in range(limit)]
}
# --- User asks ---
messages = [
{"role": "user", "content": "Find me the latest info about the stock market."}
]
# --- Restrict to Firecrawl only ---
resp = client.responses.create(
model="gpt-5",
tools=tools,
input=messages,
instructions="Only the firecrawl_search tool is allowed. Do not use dummy_web_search.",
tool_choice={
"type": "allowed_tools",
"mode": "required", # force Firecrawl
"tools": [{"type": "function", "name": "firecrawl_search"}],
},
)
for item in resp.output:
if getattr(item, "type", "") in ("function_call", "tool_call"):
print("\n--- Tool Call ---")
print("Tool name:", item.name)
print("Arguments:", item.arguments)
if item.name == "firecrawl_search":
args = json.loads(item.arguments)
# Firecrawl returns a SearchData object → convert it
results_obj = firecrawl.search(
query=args["query"],
limit=args.get("limit", 3),
)
# 🔥 Convert to JSON-serializable dict
if hasattr(results_obj, "to_dict"):
results = results_obj.to_dict()
elif hasattr(results_obj, "dict"):
results = results_obj.dict()
else:
results = json.loads(results_obj.json()) if hasattr(results_obj, "json") else results_obj
print("\n--- Firecrawl Raw Results ---")
print(json.dumps(results, indent=2)[:500])
# ✅ Extract only the data portion for summarization
safe_results = results.get("data", results)
# Feed back to GPT
messages += resp.output
messages.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps(safe_results) # now safe
})
# Final pass
final = client.responses.create(
model="gpt-5",
tools=tools,
input=messages,
instructions="Summarize the Firecrawl search results into 3-4 bullet points with clickable [Title](URL) links."
)
print("\n--- Final Natural Language Answer ---")
print(final.output_text)
elif item.name == "dummy_web_search":
args = json.loads(item.arguments)
results = dummy_web_search(args["query"], args.get("limit", 3))
print("\n--- Dummy Web Search Results ---")
print(json.dumps(results, indent=2))Il a sélectionné la recherche Firecrawl et, à l'aide de celle-ci, a généré la réponse finale au format Markdown.
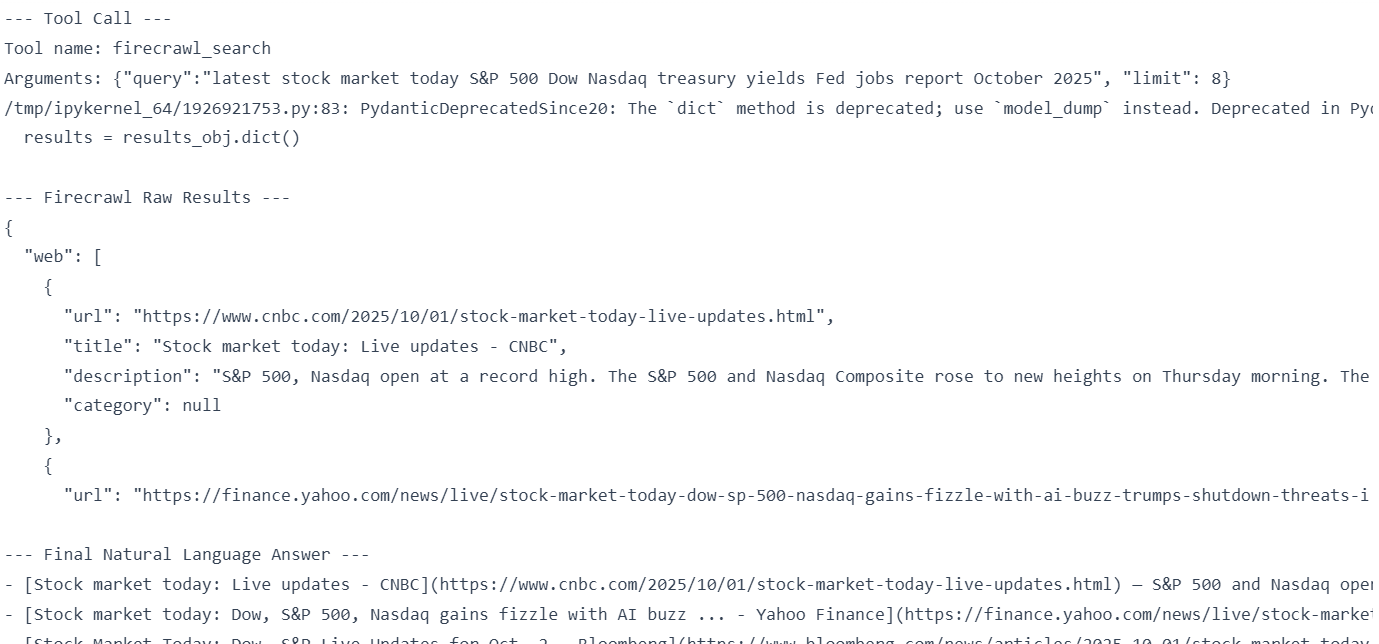
Les préambules sont de brèves explications générées par le modèle avant d'invoquer un outil, clarifiant la raison de l'appel. Ils renforcent la transparence, renforcent la confiance des utilisateurs et améliorent la clarté du débogage dans les flux de travail complexes. Vous pouvez les activer à l'aide d'une instruction simple telle que « expliquer avant d'appeler un outil », généralement sans ajouter de latence notable.
Nous allons maintenant écrire le code dans lequel le modèle génère d'abord une brève ligne « Préambule : » expliquant pourquoi il fait appel à un outil, puis appelle l'outil, vous l'exécutez localement, renvoyez le résultat, et le modèle produit une réponse finale claire.
Dans cet exemple de code, nous avons :
medical_advice) avec JSON Schema.“Preamble:” s avant tout appel d'outil.call_id.from openai import OpenAI
import json
import random
client = OpenAI()
# --- Fake tool implementation ---
def medical_advice(symptom: str):
remedies = {
"headache": "You can take acetaminophen (paracetamol) or ibuprofen, rest in a quiet room, and stay hydrated.",
"cough": "Drink warm fluids, use honey in tea, and consider over-the-counter cough syrup.",
"fever": "Use acetaminophen to reduce fever, stay hydrated, and rest. See a doctor if >39°C.",
}
return {"advice": remedies.get(symptom.lower(), "Please consult a healthcare provider for guidance.")}
# --- Tool definition ---
tools = [{
"type": "function",
"name": "medical_advice",
"description": "Provide safe, general over-the-counter advice for common symptoms.",
"parameters": {
"type": "object",
"properties": {"symptom": {"type": "string"}},
"required": ["symptom"],
"additionalProperties": False
},
"strict": True,
}]
# --- Messages (system preamble instruction) ---
messages = [
{"role": "system", "content": "Before you call a tool, explain why you are calling it in ONE short sentence prefixed with 'Preamble:'."},
{"role": "user", "content": "What should I take for a headache?"}
]
# 1) First call: expect preamble + tool call
resp = client.responses.create(model="gpt-5", input=messages, tools=tools)
print("=== First Response ===")
for item in resp.output:
t = getattr(item, "type", None)
if t == "message":
# Extract just the model's text
content = getattr(item, "content", None)
text = None
if isinstance(content, list):
text = "".join([c.text for c in content if hasattr(c, "text")])
elif content:
text = str(content)
if text:
# ✅ Only print once
print(text)
if t in ("function_call", "tool_call", "custom_tool_call"):
print("Tool:", getattr(item, "name", None))
print("Args:", getattr(item, "arguments", None))
# Extract tool call
tool_call = next(x for x in resp.output if getattr(x, "type", None) in ("function_call","tool_call","custom_tool_call"))
messages += resp.output
# 2) Execute tool locally
args = json.loads(getattr(tool_call, "arguments", "{}"))
symptom = args.get("symptom", "")
tool_result = medical_advice(symptom)
# 3) Return tool result
messages.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": json.dumps(tool_result)
})
# 4) Final model call → natural answer
final = client.responses.create(model="gpt-5", input=messages, tools=tools)
print("\n=== Final Answer ===")
print(final.output_text)Vous pouvez constater qu'avant d'appeler l'outil, il fournit une explication sur la raison pour laquelle il fait appel à cet outil. Cela est utile pour l'observabilité et le débogage.

GPT-5 est le modèle le plus avancé d'OpenAI à ce jour, particulièrement performant dans le domaine du codage et des flux de travail basés sur des agents. Ses dernières fonctionnalités API permettent le développement simple de systèmes de qualité production, de bout en bout.
Dans ce tutoriel, vous avez appris à :
Pour en savoir plus sur les possibilités offertes par les différents outils d'OpenAI, je vous recommande de suivre notre parcours de compétences cursus de compétences OpenAI Fundamentals et cours « Travailler avec l'API OpenAI ».
Meilleurs cours DataCamp
Cursus
Cours
Cours