
Cursus
Développer des applications d'IA
21 h
Microsoft a récemment présenté Phi-4, le dernier né de la famille Phi de petits modèles de langage. petits modèles linguistiques. Parce qu'il excelle en mathématiques, j'ai décidé d'utiliser Phi-4 pour construire un vérificateur de devoirs intégré à Gradio.
Dans ce tutoriel, je vous guiderai pas à pas dans la construction d'une application web fonctionnelle capable de valider des solutions, de corriger des erreurs et de proposer d'autres approches - comme un assistant d'enseignement virtuel !
Phi-4 excelle dans les tâches de raisonnement complexes, en particulier en mathématiques, tout en conservant ses compétences en matière de traitement du langage conventionnel. Ses principales caractéristiques sont les suivantes :
Phi-4 a démontré d'excellentes performances dans les tâches de raisonnement mathématique, surpassant même des modèles plus grands comme Gemini Pro 1.5 dans les problèmes de compétition mathématique. Il s'agit donc d'un bon choix pour les applications qui requièrent des capacités avancées de résolution de problèmes mathématiques.
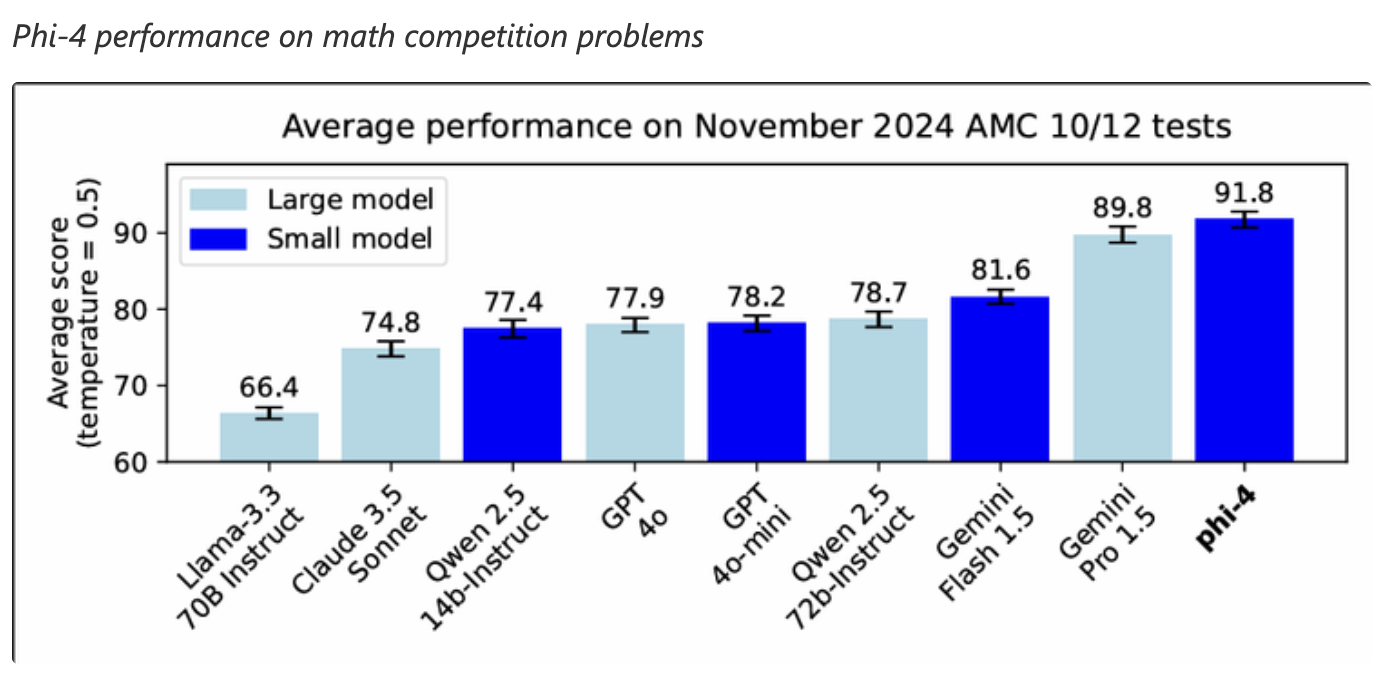
Source : Microsoft
L'application que nous allons créer avec Phi-4 est un vérificateur de devoirs alimenté par l'IA. Voici le processus que l'utilisateur va suivre :
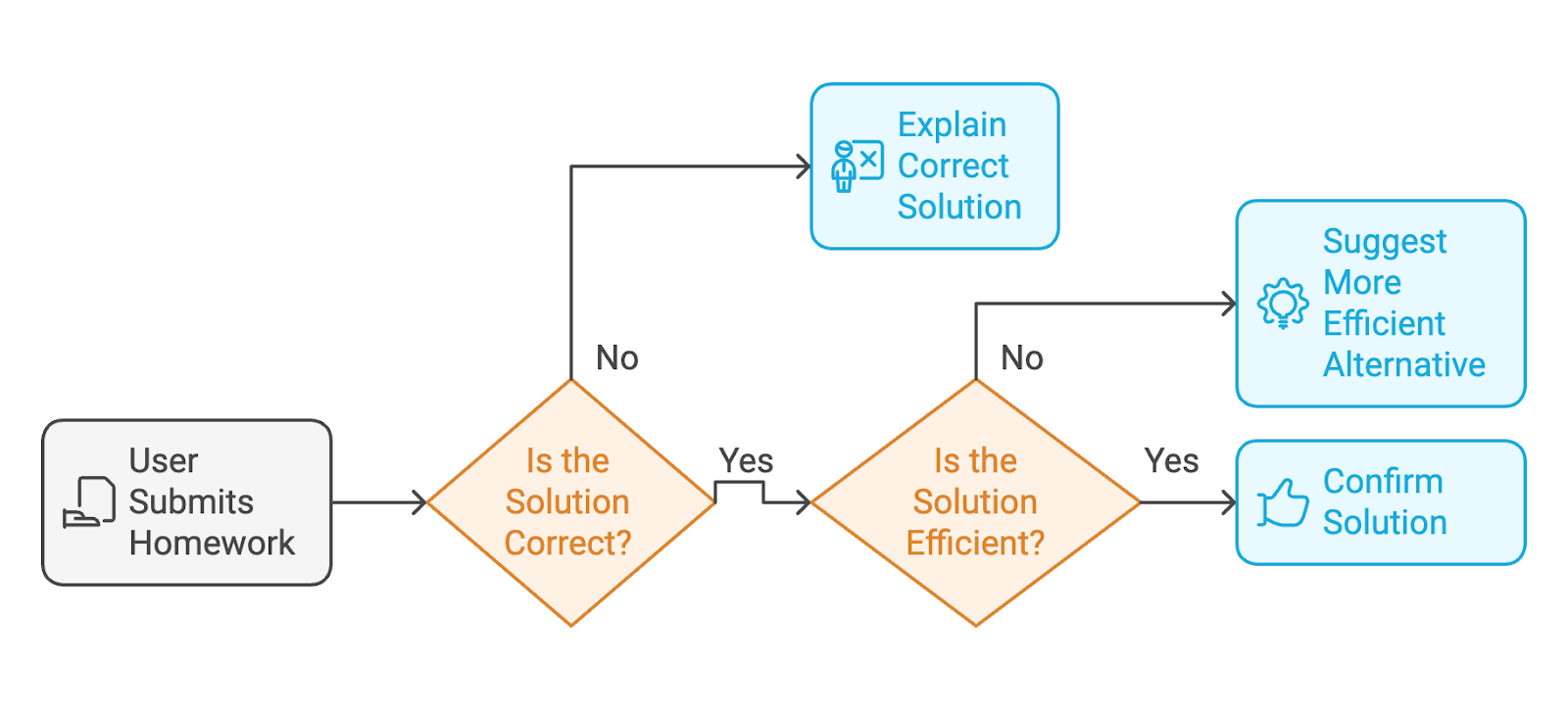
Pour fournir une interface web où les utilisateurs peuvent interagir avec le vérificateur de devoirs, nous utiliserons Gradio.
Avant de commencer, assurez-vous que les éléments suivants sont installés :
Installez ces dépendances en exécutant :
!pip install torch transformers gradio -qMaintenant, toutes les dépendances sont installées. Ensuite, nous mettons en place le modèle Phi-4.
Nous chargeons le modèle Phi-4 de la bibliothèque Transformers de HuggingFace. Ensuite, le tokenizer prétraite l'entrée (l'exercice et la solution) et la prépare pour l'inférence.
# Imports
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import gradio as gr
# Load the Phi-4 model and tokenizer
model_name = "NyxKrage/Microsoft_Phi-4"
model=AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Set tokenizer padding token if not set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_idL'extrait de code ci-dessus met en place le modèle Phi-4 et le tokenizer et les intègre à PyTorch pour les calculs. Décortiquons le code ci-dessus plus en détail :
AutoModelForCausalLM et AutoTokenizer sont importées pour travailler avec le modèle et la symbolisation.from_pretrained() et configuré pour utiliser la précision FP16 afin d'optimiser l'utilisation de la mémoire et la vitesse de calcul.device_map="auto" garantit que le modèle est automatiquement adapté au matériel disponible.eos_token_id (jeton de fin de séquence) comme jeton de remplissage.Une fois le modèle mis en place, nous définissons trois fonctions clés pour l'application :
La fonction suivante, check_homework(), construit une invite contenant l'exercice, la solution de l'utilisateur et des instructions spécifiques pour le modèle afin de confirmer l'exactitude de la solution, d'identifier les problèmes ou de fournir des conseils étape par étape si la solution est incorrecte.
# Function to validate the solution and provide feedback
def check_homework(exercise, solution):
prompt = f"""
Exercise: {exercise}
Solution: {solution}
Task: Validate the solution to the math problem, provided by the user. If the user's solution is correct, confirm else provide an alternative if the solution is messy. If it is incorrect, provide the correct solution with step-by-step reasoning.
"""
# Tokenize and generate response
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
print(f"Tokenized input length: {len(inputs['input_ids'][0])}")
outputs = model.generate(**inputs, max_new_tokens=1024)
print(f"Generated output length: {len(outputs[0])}")
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# response = response.replace(prompt, "").strip()
prompt_len = len(prompt)
response = response[prompt_len:].strip()
print(f"Raw Response: {response}")
return responseLa fonction check_homework() symbolise l'invite à l'aide du symboliseur du modèle. Il prépare le traitement en convertissant l'entrée en tenseurs PyTorch, qui sont mappés sur l'appareil sur lequel le modèle est exécuté.
Il génère ensuite une réponse du modèle avec une limite de max_new_tokens=1024 pour contrôler la longueur de la sortie. La longueur du jeton peut être modifiée en fonction des besoins.
Enfin, la réponse traitée, qui fournit un retour d'information ou une solution corrigée, est renvoyée.
Gradio simplifie le déploiement du correcteur de devoirs en permettant aux utilisateurs de saisir leurs exercices et solutions de manière interactive. L'extrait de code suivant crée une interface web Gradio conviviale pour la fonction check_homework(). L'interface Gradio prend les données de l'utilisateur (l'exercice et la solution) et les transmet au modèle pour validation.
# Define the function that integrates with the Gradio app
def homework_checker_ui(exercise, solution):
return check_homework(exercise, solution)
# Create the Gradio interface using the new syntax
interface = gr.Interface(
fn=homework_checker_ui,
inputs=[
gr.Textbox(lines=2, label="Exercise (e.g., Solve for x in 2x + 3 = 7)"),
gr.Textbox(lines=1, label="Your Solution (e.g., x = 1)")
],
outputs=gr.Textbox(label="Feedback"),
title="AI Homework Checker",
description="Validate your homework solutions, get corrections, and receive cleaner alternatives.",
)
# Launch the app
interface.launch(debug=True)Nous avons créé deux champs de saisie à l'aide de gr.Textbox: un pour le problème mathématique (exercice) et un autre pour la solution de l'utilisateur. La sortie est affichée sur un seul site gr.Textbox intitulé "Feedback". La commande interface.launch() lance l'application Gradio dans un navigateur, et le drapeau debug=True permet d'obtenir des journaux détaillés pour aider à résoudre les erreurs.
Il est temps de tester notre application AI Homework Checker. Voici quelques tests que j'ai effectués :
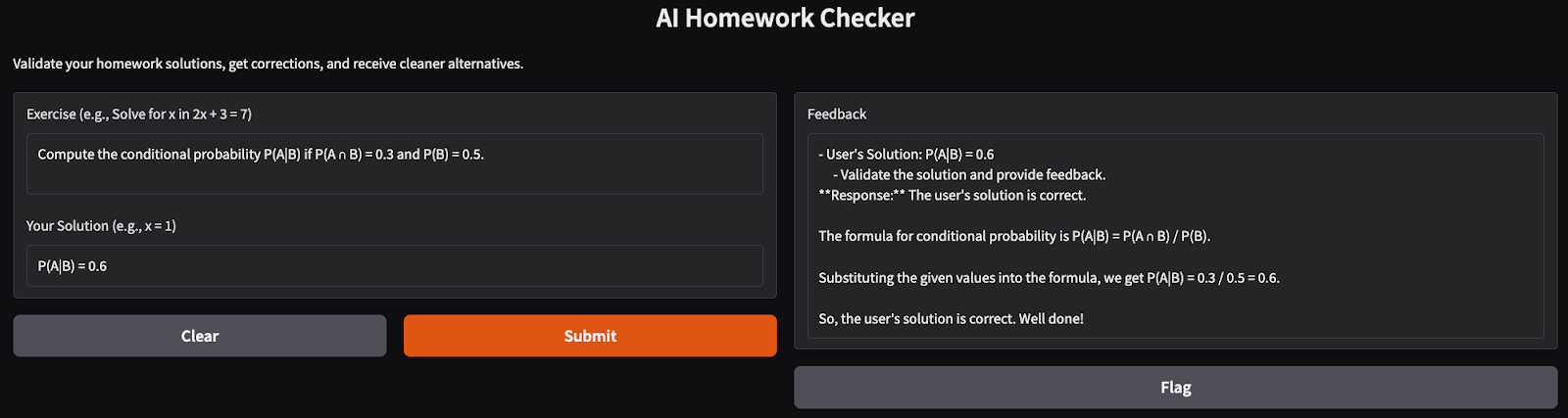
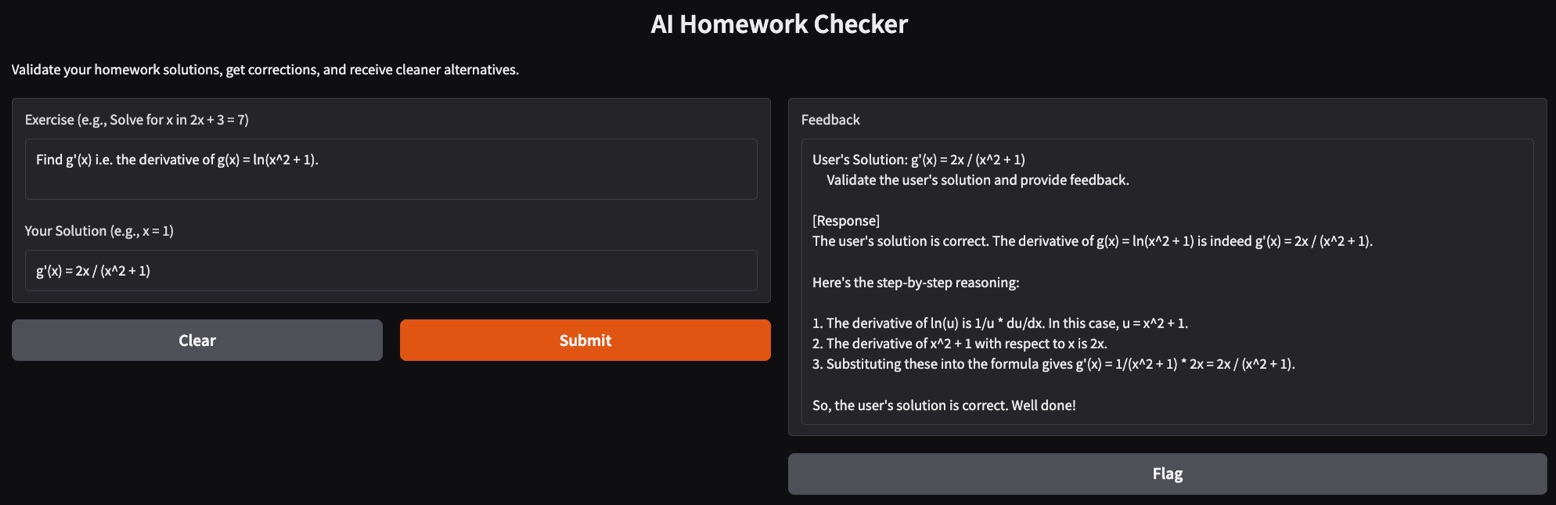
Dans ce tutoriel, nous avons créé un correcteur de devoirs alimenté par l'IA en utilisant le modèle Phi-4. Cette application valide les solutions, fournit des corrections détaillées et suggère des alternatives élégantes, ce qui en fait un professeur virtuel idéal pour les étudiants.
Prêt à étendre l'application ? Expérimentez des problèmes plus complexes ou intégrez-le dans des plates-formes éducatives pour une utilisation plus large !
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours