
Program
Associate Data Engineer in Databricks
37 Hr
Apache Kafka adalah kerangka event-streaming terdistribusi open-source yang dikembangkan di LinkedIn oleh tim yang mencakup Jay Kreps, Jun Rao, dan Neha Narkhede. Alat ini dioptimalkan untuk menyerap dan memproses data streaming secara real-time; karena itu, Kafka dapat digunakan untuk mengimplementasikan pipeline data berkinerja tinggi, aplikasi analitik streaming, dan layanan integrasi data.
Setelah menyimpan event, platform streaming event akan mengarahkan event tersebut ke layanan yang relevan. Pengembang dapat melakukan skala dan pemeliharaan sistem seperti ini tanpa bergantung pada layanan lain. Karena Kafka adalah paket serba ada yang dapat digunakan sebagai message broker, event store, atau kerangka pemrosesan stream, Kafka sangat cocok untuk kebutuhan tersebut.
Dengan throughput tinggi dan daya tahan, ratusan sumber data dapat secara simultan memberikan aliran data kontinu dalam jumlah besar yang dapat diproses secara berurutan dan progresif oleh sistem message broker Apache Kafka.
Kafka berbeda dari message broker tradisional seperti RabbitMQ dalam beberapa hal mendasar:
| Fitur | Apache Kafka | Broker Tradisional (mis., RabbitMQ) |
|---|---|---|
| Retensi pesan | Dapat dikonfigurasi (hari hingga tahun); pesan tetap ada setelah dikonsumsi | Pesan dihapus setelah ada pengakuan dari consumer |
| Model consumer | Berbasis tarik (pull); consumer membaca sesuai kecepatannya sendiri | Berbasis dorong (push); broker mengirimkan ke consumer |
| Throughput | Jutaan pesan per detik | Ribuan hingga puluhan ribu per detik |
| Pengurutan | Dijamin dalam satu partisi | Bervariasi menurut implementasi |
| Pemutaran ulang | Consumer dapat membaca ulang pesan lampau pada offset mana pun | Tidak didukung setelah pengiriman |
| Kasus penggunaan utama | Event streaming, agregasi log, pipeline real-time | Antrean tugas, pola permintaan-balas |
Keunggulan utama Apache Kafka mencakup:
Arsitektur Kafka yang dirancang dengan baik, termasuk pemartisian data, pemrosesan batch, teknik zero-copy, dan log append-only, memungkinkannya mencapai throughput tinggi dan menangani jutaan pesan per detik, melayani skenario data berkecepatan dan berkapasitas tinggi. Protokol komunikasi yang ringan yang memfasilitasi interaksi client-broker yang efektif membuat streaming data real-time menjadi layak.
Apache Kafka menyediakan penyeimbangan beban di seluruh server dengan membagi sebuah topik ke dalam beberapa partisi. Ini memungkinkan pengguna mendistribusikan klaster produksi di berbagai wilayah geografis atau zona ketersediaan dan melakukan scale up atau down sesuai kebutuhan. Dengan kata lain, Apache Kafka dapat dengan mudah diskalakan untuk menangani triliunan pesan per hari di banyak partisi.
Apache Kafka menggunakan klaster server dengan latensi rendah (serendah 2 milidetik) untuk mengirimkan pesan secara efisien pada throughput yang dibatasi jaringan dengan memisahkan (decoupling) aliran data.
Apache Kafka meningkatkan toleransi kesalahan dan daya tahan data dengan dua cara utama:
Karena broker berbasis klaster, Kafka tetap beroperasi selama terjadi gangguan server. Ini bekerja karena ketika salah satu server mengalami masalah, Kafka cukup cerdas untuk mengarahkan kueri ke broker lain.
Apache Kafka memungkinkan pengguna menganalisis data secara real-time, menyimpan rekaman menurut urutan dibuatnya, serta memublikasikan dan berlangganan rekaman tersebut.
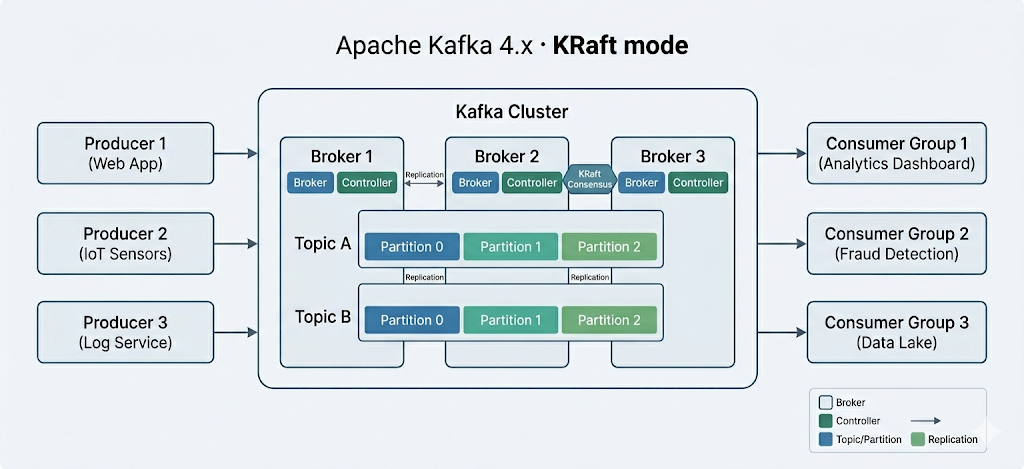
Komponen inti Apache Kafka
Apache Kafka adalah klaster yang skalabel secara horizontal dari server komoditas yang memproses data real-time dari berbagai sistem dan aplikasi "producer" (mis., logging, pemantauan, sensor, dan aplikasi Internet of Things) dan menyediakannya ke beragam sistem dan aplikasi "consumer" (mis., analitik real-time) dengan latensi sangat rendah – seperti ditunjukkan pada diagram di atas.
Perlu dicatat bahwa aplikasi yang bergantung pada pemrosesan data real-time dan sistem analitik keduanya dapat dianggap sebagai consumer. Misalnya, aplikasi untuk micromarketing berbasis lokasi atau logistik.
Berikut beberapa istilah kunci yang perlu diketahui untuk lebih memahami komponen inti Kafka:
Penting (pembaruan 2025): Apache Kafka 4.0, dirilis pada Maret 2025, menghapus ZooKeeper sepenuhnya dan beralih ke mode KRaft (Kafka Raft). Instruksi penyiapan di bawah ini menggunakan ZooKeeper dan berlaku untuk Kafka 3.x saja. Untuk Kafka 4.x, ZooKeeper tidak lagi diperlukan atau didukung. Jika Anda memulai dari nol, pertimbangkan menggunakan Docker dengan mode KRaft untuk penyiapan yang lebih sederhana.
Sering direkomendasikan agar Apache Kafka 3.x dijalankan dengan Zookeeper untuk kompatibilitas optimal. Selain itu, Kafka dapat mengalami beberapa masalah saat dipasang di Windows karena tidak dirancang secara native untuk sistem operasi ini. Karena itu, disarankan meluncurkan Apache Kafka di Windows menggunakan WSL2 atau Docker.
Tidak disarankan menggunakan JVM untuk menjalankan Kafka di Windows karena tidak memiliki beberapa karakteristik POSIX yang khas Linux. Anda pada akhirnya akan mengalami kesulitan jika mencoba menjalankan Kafka di Windows tanpa WSL2.
Dengan demikian, langkah pertama memasang Apache Kafka di Windows adalah memasang WSL2.
WSL2, atau Windows Subsystem for Linux 2, memberi PC Windows Anda akses ke lingkungan Linux tanpa memerlukan mesin virtual.
Kebanyakan perintah Linux kompatibel dengan WSL2, sehingga proses pemasangan Kafka menjadi mirip dengan instruksi untuk Mac dan Linux.
Tip: Pastikan Anda menjalankan Windows 10 versi 2004 atau lebih tinggi (Build 19041 ke atas) sebelum memasang WSL2. Tekan tombol logo Windows + R, ketik "winver," lalu klik OK untuk melihat versi Windows Anda.
Cara termudah memasang Windows Subsystem for Linux (WSL) adalah menjalankan perintah berikut di PowerShell atau Command Prompt Windows dengan hak administrator, lalu memulai ulang komputer Anda:
wsl --installPerhatikan Anda akan diminta membuat akun pengguna dan kata sandi untuk distribusi Linux yang baru dipasang.
Ikuti langkah-langkah di situs Microsoft Docs jika Anda menemui kendala.
Jika Java belum terpasang di mesin Anda, maka Anda perlu mengunduh versi terbaru.
Pada pembaruan ini, versi stabil terbaru Apache Kafka adalah 4.2.0, dirilis pada Februari 2026. Kafka 4.0 (Maret 2025) menggantikan ZooKeeper dengan mode KRaft untuk manajemen metadata. Untuk mendapatkan versi stabil saat ini, lihat halaman unduhan.
Unduh versi terbaru dari Binary downloads.
Setelah unduhan selesai, navigasikan ke folder tempat Kafka diunduh dan ekstrak semua file dari folder zip. Perlu dicatat kami menamai folder baru kami "Kafka."
Zookeeper diperlukan untuk manajemen klaster di Apache Kafka 3.x. Karena itu, Zookeeper harus dijalankan sebelum Kafka. Memasang Zookeeper secara terpisah tidak diperlukan karena sudah menjadi bagian dari Apache Kafka.
Buka command prompt dan arahkan ke direktori root Kafka. Setelah itu, jalankan perintah berikut untuk memulai Zookeeper:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesBuka command prompt lain dan jalankan perintah berikut dari root Apache Kafka untuk memulai Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesUntuk membuat topik, buka command prompt baru dari direktori root Kafka dan jalankan perintah berikut:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Ini akan membuat topik Kafka baru bernama "MyFirstTopic."
Catatan: untuk memastikan topik dibuat dengan benar, eksekusi perintah akan mengembalikan "Create topic <name of topic>."
Producer harus dijalankan untuk memasukkan pesan ke dalam topik Kafka. Jalankan perintah berikut untuk melakukannya:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Buka command prompt lain dari direktori root Kafka dan jalankan perintah berikut untuk memulai consumer Kafka:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Sekarang, ketika sebuah pesan diproduksi di Producer, pesan tersebut dibaca oleh Consumer secara real-time.
Sebuah GIF menunjukkan pesan yang diproduksi oleh Producer dan dibaca oleh Kafka Consumer secara real-time.
Anda baru saja membuat topik Kafka pertama dan mengirim pesan dari producer ke consumer secara real-time.
Kafka menawarkan sejumlah fitur lanjutan di luar pengiriman pesan dasar.
Dengan Apache Kafka, pengembang dapat membangun aplikasi pemrosesan stream yang toleran terhadap kesalahan menggunakan Kafka Streams. Kafka Streams menawarkan API dan Domain-Specific Language (DSL) tingkat tinggi untuk menangani, mengonversi, dan mengevaluasi aliran data yang berkelanjutan.
Beberapa fitur kunci meliputi:
Kafka Streams memungkinkan pemrosesan aliran rekaman secara real-time. Anda dapat mengambil data dari topic Kafka, memproses dan mentransformasi data tersebut, lalu mengembalikan informasi yang telah diproses kembali ke topic Kafka. Pemrosesan stream memungkinkan analitik hampir real-time, pemantauan, dan pengayaan data. Ini dapat diterapkan pada rekaman individual atau pada agregasi berjendela (windowed).
Dengan memanfaatkan stempel waktu yang terlampir pada rekaman, Anda dapat menangani rekaman yang tidak berurutan berkat dukungan Kafka Streams untuk pemrosesan berdasarkan event-time. Kafka Streams menyediakan semantik event-time untuk operasi windowing, memungkinkan window join, sessionization, dan agregasi berbasis waktu.
Kafka Streams menyediakan sejumlah operasi windowing yang memungkinkan pengguna melakukan komputasi pada session window, tumbling window, sliding window, dan fixed time window.
Pemicu berbasis event, analisis sensitif waktu, dan agregasi berbasis waktu dimungkinkan melalui prosedur ber-jendela.
Selama pemrosesan stream, Kafka Streams memungkinkan pengguna menyimpan dan memperbarui state. Dukungan bawaan untuk state store disediakan. Perlu dicatat bahwa state store adalah penyimpanan key-value yang dapat diperbarui dan di-kueri dalam sebuah topologi pemrosesan.
Operasi stateful memungkinkan fungsi pemrosesan stream tingkat lanjut seperti join, agregasi, dan deteksi anomali.
Kafka Streams menyediakan semantik end-to-end untuk pemrosesan exactly-once, menjamin setiap rekaman ditangani tepat satu kali—bahkan jika terjadi kegagalan. Ini dicapai dengan memanfaatkan jaminan daya tahan bawaan Kafka dan fitur transaksionalnya.
Kerangka kerja integrasi data yang deklaratif dan pluggable untuk Kafka disebut Kafka Connect. Ini adalah komponen open-source dan gratis dari Apache Kafka yang bertindak sebagai hub data terpusat untuk integrasi data yang mudah antara sistem berkas, basis data, indeks pencarian, dan key-value store.
Distribusi Kafka menyertakan Kafka Connect secara default. Untuk memasangnya, Anda hanya perlu memulai proses worker.
Gunakan perintah berikut dari direktori root Kafka untuk menjalankan proses worker Kafka Connect:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesIni akan menjalankan worker Kafka Connect dalam mode terdistribusi, memungkinkan ketersediaan tinggi dan skalabilitas dengan menjalankan banyak worker dalam sebuah klaster.
Catatan: File .\config\connect-distributed.properties menentukan informasi broker Kafka dan properti konfigurasi lain untuk Kafka Connect.
Connector digunakan oleh Kafka Connect untuk mentransfer data antara sistem eksternal dan topic Kafka. Connector dapat dipasang dan dikonfigurasi agar sesuai dengan kebutuhan integrasi data Anda.
Mengunduh dan menambahkan file JAR connector ke direktori plugin.path yang disebutkan dalam file .\config\connect-distributed.properties adalah semua yang diperlukan untuk memasang sebuah connector.
Sebuah file konfigurasi untuk connector harus dibuat, di mana kelas connector dan karakteristik lain harus ditentukan. Kafka Connect REST API dan alat baris perintah dapat digunakan untuk membuat dan memelihara connector.
Selanjutnya, untuk menggabungkan data dari sistem lain, Anda harus mengonfigurasi Kafka Connector. Kafka Connect menawarkan beragam connector untuk mengintegrasikan data dari berbagai sistem, seperti sistem berkas, message queue, dan basis data. Pilih connector berdasarkan kebutuhan integrasi Anda - lihat dokumentasi untuk daftar connector.
Berikut beberapa kasus penggunaan umum Apache Kafka.
Kafka dapat digunakan oleh platform e-niaga daring untuk melacak aktivitas pengguna secara real-time. Setiap tindakan pengguna, termasuk melihat produk, menambahkan item ke keranjang, melakukan pembelian, memberi ulasan, melakukan pencarian, dan sebagainya, dapat dipublikasikan sebagai event ke topic Kafka tertentu.
Microservice lain dapat menyimpan atau menggunakan event ini untuk deteksi penipuan real-time, pelaporan, penawaran yang dipersonalisasi, dan rekomendasi.
Dengan throughput yang ditingkatkan, pemartisian, replikasi, toleransi kesalahan, dan kemampuan penskalaan yang tertanam, Kafka adalah pengganti yang baik untuk message broker konvensional.
Aplikasi ride-hailing berbasis microservices dapat menggunakannya untuk memfasilitasi pertukaran pesan di berbagai layanan.
Misalnya, bisnis pemesanan perjalanan dapat menggunakan Kafka untuk berkomunikasi dengan layanan pencocokan pengemudi ketika penumpang melakukan pemesanan. Layanan pencocokan pengemudi kemudian dapat, hampir secara real-time, menemukan pengemudi di area tersebut dan membalas dengan sebuah pesan.
Biasanya, ini melibatkan pengambilan file log fisik dari server dan menyimpannya di lokasi terpusat untuk diproses, seperti server berkas atau data lake. Kafka mengabstraksikan data sebagai aliran pesan dan menyaring informasi spesifik berkas. Ini memungkinkan pemrosesan data dengan latensi lebih rendah dan memudahkan konsumsi data terdistribusi serta berbagai sumber data.
Setelah log dipublikasikan ke Kafka, log tersebut dapat digunakan untuk penanggulangan masalah, pemantauan keamanan, dan pelaporan kepatuhan oleh alat analisis log atau sistem security information and event management (SIEM).
Sejumlah pengguna Kafka memproses data dalam pipeline pemrosesan multi-tahap. Data input mentah diambil dari topic Kafka, diagregasi, diperkaya, atau ditransformasikan menjadi topic baru untuk dikonsumsi atau diproses lebih lanjut.
Sebagai contoh, bank dapat menggunakan Kafka untuk memproses transaksi real-time. Setiap transaksi yang dimulai nasabah kemudian diposting ke sebuah topic Kafka sebagai event. Selanjutnya, sebuah aplikasi dapat mengambil event ini, memverifikasi dan menangani transaksi, menghentikan transaksi yang mencurigakan, dan segera memperbarui saldo nasabah.
Kafka dapat digunakan oleh penyedia layanan cloud untuk mengagregasikan statistik dari aplikasi terdistribusi guna menghasilkan aliran terpusat data operasional secara real-time. Metrik dari ratusan server, seperti penggunaan CPU dan memori, jumlah permintaan, tingkat kesalahan, dan sebagainya, dapat dilaporkan ke Kafka. Aplikasi pemantauan kemudian dapat menggunakan metrik ini untuk identifikasi anomali, peringatan, dan visualisasi real-time.
Apache Kafka adalah standar industri untuk event streaming real-time, digunakan oleh lebih dari 80% perusahaan Fortune 100. Dengan Kafka 4.0 dan mode KRaft, penyebaran dan pengelolaan klaster menjadi lebih sederhana dibanding versi sebelumnya.
Dalam artikel ini, saya membahas mengapa Kafka penting, komponen intinya, penyiapan langkah demi langkah, fitur lanjutan seperti Kafka Streams dan Kafka Connect, serta penerapan di dunia nyata. Untuk melanjutkan pembelajaran Anda, lihat:
Mulai Perjalanan Data Engineer Anda Hari Ini!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
