
Program
Veri Mühendisi Python'da
40 sa
Olaylar depolandıktan sonra, olay akışı platformu bunları ilgili hizmetlere yönlendirir. Geliştiriciler, diğer hizmetlere bağımlı olmadan böyle bir sistemi ölçekleyip sürdürebilir. Kafka, mesaj aracısı, olay deposu veya akış işleme çerçevesi olarak kullanılabilen hepsi bir arada bir paket olduğundan, bu tür bir gereksinim için mükemmel çalışır.
Yüksek aktarım hızı ve dayanıklılığı sayesinde, yüzlerce veri kaynağı aynı anda kesintisiz veri akışlarını sağlayabilir ve bunlar Apache Kafka’nın mesaj aracısı sistemi tarafından sıralı ve aşamalı olarak işlenebilir.
Ayrıca Apache Kafka’nın avantajları şunlardır:
Veri bölümlendirme, toplu işleme, zero-copy teknikleri ve yalnızca ekleme (append-only) günlüklerini içeren Kafka’nın iyi tasarlanmış mimarisi, yüksek aktarım hızına ulaşmasını ve saniyede milyonlarca iletiyi işlemesini sağlar; bu da yüksek hız ve yüksek hacimli veri senaryolarına hitap eder. Böylelikle, istemci-aracı etkileşimini kolaylaştıran hafif iletişim protokolü, gerçek zamanlı veri akışını mümkün kılar.
Apache Kafka, bir konuyu birden çok bölüme (partition) ayırarak sunucular arasında yük dengelemesi sağlar. Bu da kullanıcıların üretim kümelerini coğrafi bölgeler veya erişilebilirlik alanları arasında dağıtmasına ve ihtiyaçlarına göre ölçeklendirmesine olanak tanır. Başka bir deyişle, Apache Kafka çok sayıda bölüm boyunca günde trilyonlarca iletiyi işleyecek şekilde kolayca ölçeklenebilir.
Apache Kafka, veri akışlarını ayrıştırarak, düşük gecikmeli (2 milisaniyeye kadar) bir sunucu kümesi kullanır ve ağ ile sınırlı aktarım hızında iletileri verimli şekilde teslim eder.
Apache Kafka, veri hata toleransını ve dayanıklılığını iki temel yolla artırır:
Aracıların küme tabanlı olması nedeniyle, bir sunucu kesintisi sırasında Kafka çalışmaya devam eder. Bu, sunuculardan biri sorun yaşadığında Kafka’nın sorguları diğer aracılara yönlendirebilmesi sayesinde mümkün olur.
Apache Kafka, kullanıcıların verileri gerçek zamanlı analiz etmesini, kayıtları oluşturuldukları sırayla depolamasını ve bunları yayımlayıp abone olmasını sağlar.
Apache Kafka’nın temel bileşenleri | Kaynak: Alex Kam tarafından Apache Kafka ile gerçek zamanlı veri hattınıza başlayın
Apache Kafka, birden fazla “üretici” sistem ve uygulamadan (ör. günlükleme, izleme, sensörler ve Nesnelerin İnterneti uygulamaları) gerçek zamanlı veri işleyen ve bunu birden fazla “tüketici” sistem ve uygulamaya (ör. gerçek zamanlı analitik) çok düşük gecikmeyle sunan, yatayda ölçeklenebilir bir sıradan sunucular kümesidir – yukarıdaki diyagramda gösterildiği gibi.
Gerçek zamanlı veri işleme ve analitiğe bağımlı uygulamaların her ikisinin de tüketici olarak değerlendirilebileceğine dikkat edin. Örneğin, konum tabanlı mikropazarlama veya lojistik için bir uygulama.
Kafka’nın temel bileşenlerini daha iyi anlamak için bilinmesi gereken bazı anahtar terimler şunlardır:
En iyi uyumluluk için Apache Kafka’nın Zookeeper ile başlatılması genellikle önerilir. Ayrıca, Kafka Windows üzerinde kurulduğunda bir dizi sorunla karşılaşabilir; çünkü bu işletim sistemi için yerel olarak tasarlanmamıştır. Bu nedenle, Windows’ta Apache Kafka’yı başlatmak için aşağıdakilerin kullanılması tavsiye edilir:
Kafka’yı Windows üzerinde JVM ile çalıştırmak önerilmez; çünkü Linux’a özgü bazı POSIX özellikleri bulunmaz. WSL2 olmadan Windows’ta Kafka’yı çalıştırmaya çalışırsanız, er ya da geç zorluklarla karşılaşırsınız.
Bununla birlikte, Windows’ta Apache Kafka’yı kurmanın ilk adımı WSL2’yi yüklemektir.
WSL2 (Windows Subsystem for Linux 2), Windows PC’nize sanal makineye gerek olmadan bir Linux ortamı sağlar.
Linux komutlarının çoğu WSL2 ile uyumludur; bu da Kafka kurulum sürecini Mac ve Linux için sunulan talimatlara yaklaştırır.
İpucu: WSL2’yi kurmadan önce Windows 10 sürüm 2004 veya üstünü (Derleme 19041 ve üstü) çalıştırdığınızdan emin olun. Windows logosu tuşu + R’ye basın, “winver” yazın ve sürümünüzü görmek için Tamam’a tıklayın.
Windows için Linux Alt Sistemi’ni (WSL) kurmanın en kolay yolu, yönetici PowerShell’inde veya Windows Komut İstemi’nde aşağıdaki komutu çalıştırmak ve ardından bilgisayarınızı yeniden başlatmaktır:
wsl --installYeni yüklenen Linux dağıtımı için bir kullanıcı hesabı ve parola oluşturmanız isteneceğini unutmayın.
Takılırsanız Microsoft Docs sitesindeki adımları izleyin.
Makinenizde Java kurulu değilse, en son sürümü indirmelisiniz.
Adım 3: Apache Kafka’yı kurun
Bu yazı yazıldığı sırada Apache Kafka’nın en son kararlı sürümü 27 Şubat 2024’te yayımlanan 3.7.0’dır. Bu durum her an değişebilir. En güncel ve kararlı Kafka sürümünü kullandığınızdan emin olmak için indirme sayfasına bakın.
İkili (Binary) indirmelerden en son sürümü indirin.
İndirme tamamlandıktan sonra Kafka’nın indirildiği klasöre gidin ve sıkıştırılmış klasördeki tüm dosyaları çıkarın. Yeni klasörümüze “Kafka” adını verdiğimizi unutmayın.
Apache Kafka’da küme yönetimi için Zookeeper gereklidir. Bu nedenle, Kafka’dan önce Zookeeper başlatılmalıdır. Zookeeper’ı ayrı kurmanız gerekmez; Apache Kafka’nın bir parçasıdır.
Komut istemini açın ve kök Kafka dizinine gidin. Oradayken Zookeeper’ı başlatmak için aşağıdaki komutu çalıştırın:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesBaşka bir komut istemi açın ve Apache Kafka’nın kök dizininden aşağıdaki komutu çalıştırarak Apache Kafka’yı başlatın:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesBir konu oluşturmak için kök Kafka dizininden yeni bir komut istemi başlatın ve aşağıdaki komutu çalıştırın:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Bu, “MyFirstTopic” adlı yeni bir Kafka konusu oluşturacaktır.
Not: Doğru oluşturulduğunu doğrulamak için komutu çalıştırdığınızda “Create topic <konu adı>.” çıktısını alırsınız.
Kafka konusuna bir ileti koymak için bir üretici başlatılmalıdır. Bunu yapmak için aşağıdaki komutu çalıştırın:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Kök Kafka dizininden başka bir komut istemi açın ve Kafka tüketicisini başlatmak için aşağıdaki komutu çalıştırın:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Artık Üretici’de bir ileti üretildiğinde, Tüketici bunu gerçek zamanlı olarak okur.
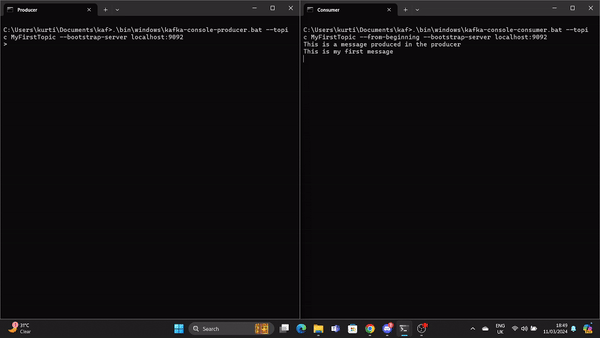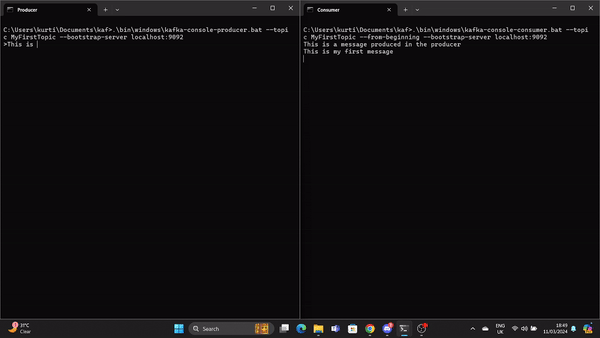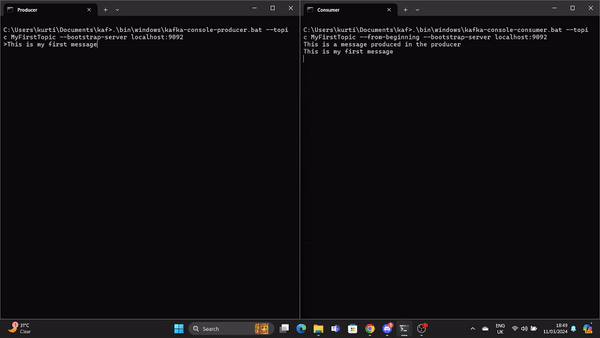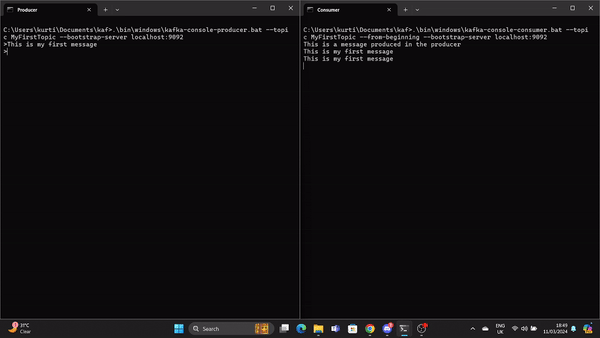
Bir GIF, Üretici tarafından üretilen ve gerçek zamanlı olarak Kafka Tüketicisi tarafından okunan bir iletiyi gösteriyor.
İşte bu kadar… İlk Kafka konunuzu oluşturdunuz.
İşte Kafka’nın bazı gelişmiş özellikleri…
Apache Kafka kullanarak geliştiriciler, Kafka Streams’in yardımıyla sağlam akış işleme uygulamaları oluşturabilir. Sürekli veri akışlarını işlemek, dönüştürmek ve değerlendirmek için API’ler ve üst düzey bir alan-özel dil (DSL) sunar.
Bazı temel özellikler şunlardır:
Kafka Streams, kayıt akışlarının gerçek zamanlı işlenmesini mümkün kılar. Kafka konularından veri almanızı, veriyi işleyip dönüştürmenizi ve ardından işlenmiş bilgiyi tekrar Kafka konularına döndürmenizi sağlar. Akış işleme, neredeyse gerçek zamanlı analitik, izleme ve veri zenginleştirmeyi mümkün kılar. Bireysel kayıtlara veya pencerelenmiş (windowed) toplamlara uygulanabilir.
Kaydedilen zaman damgalarını kullanarak, Kafka Streams’in olay-zamanı işlemeye desteğiyle sırasız kayıtları ele alabilirsiniz. Olay-zamanı semantiklerine sahip pencereleme işlemleri sunar; böylece pencere birleştirme, oturumlaştırma ve zamana dayalı toplamalar yapılabilir.
Kafka Streams; oturum pencereleri, düşen (tumbling) pencereler, kayan (sliding) pencereler ve sabit zaman pencereleri üzerinde hesaplama yapmayı sağlayan bir dizi pencereleme işlemi sağlar.
Pencerelemeli prosedürler, olaya dayalı tetikleyiciler, zamana duyarlı analiz ve zamana dayalı toplamaları mümkün kılar.
Akış işlemesi sırasında Kafka Streams, durumun tutulmasına ve güncellenmesine olanak tanır. Durum depoları için yerleşik destek sunar. Bir durum deposunun, bir işleme topolojisi içinde güncellenebilen ve sorgulanabilen bir anahtar-değer deposu olduğunu unutmayın.
Birleştirmeler, toplamalar ve anomali tespiti gibi gelişmiş akış işlevleri, durumlu işlemler sayesinde mümkün olur.
Kafka Streams, uçtan uca tam olarak bir kez işleme semantiği sağlar; böylece bir hata durumunda bile her kaydın tam olarak bir kez işlenmesini garanti eder. Bu, Kafka’nın güçlü dayanıklılık güvenceleri ve işlemsel özelliklerinden yararlanılarak başarılır.
Kafka’nın beyan temelli, takılabilir veri entegrasyon çerçevesi Kafka Connect olarak adlandırılır. Dosya sistemleri, veritabanları, arama dizinleri ve anahtar-değer depoları arasında kolay veri entegrasyonu için merkezi bir veri merkezi işlevi gören, Apache Kafka’nın açık kaynaklı ve ücretsiz bir bileşenidir.
Kafka dağıtımı varsayılan olarak Kafka Connect’i içerir. Kurmak için yalnızca bir işçi (worker) işlemi başlatmanız gerekir.
Kafka Connect işçi işlemini başlatmak için kök Kafka dizininden aşağıdaki komutu kullanın:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesBu, Kafka Connect işçisini dağıtık modda başlatır ve bir kümede çok sayıda işçiyi çalıştırmanın yüksek erişilebilirlik ve ölçeklenebilirliğini etkinleştirir.
Not: .\config\connect-distributed.properties dosyası, Kafka aracısı bilgilerini ve Kafka Connect için diğer yapılandırma özelliklerini belirtir.
Kafka Connect, harici sistemler ile Kafka konuları arasında veri taşımak için bağlayıcılar (connectors) kullanır. Bağlayıcılar, veri entegrasyonuna ilişkin benzersiz gereksinimlerinize uyacak şekilde kurulup yapılandırılabilir.
Bir bağlayıcıyı kurmak için, bağlayıcı JAR dosyasını .\config\connect-distributed.properties dosyasında belirtilen plugin.path dizinine indirip eklemeniz yeterlidir.
Bağlayıcı için, bağlayıcı sınıfının ve diğer özelliklerin belirtilmesi gereken bir yapılandırma dosyası oluşturulmalıdır. Bağlayıcıları oluşturmak ve yönetmek için Kafka Connect REST API’si ve komut satırı araçları kullanılabilir.
Ardından, diğer sistemlerden veri birleştirmek için Kafka Connector’ü yapılandırmanız gerekir. Kafka Connect; dosya sistemleri, ileti kuyrukları ve veritabanları gibi çeşitli sistemlerle entegrasyon için çeşitli bağlayıcılar sunar. Entegrasyon ihtiyaçlarınıza göre bir bağlayıcı seçin – bağlayıcı listesi için belgelere bakın.
Apache Kafka’nın yaygın bazı kullanım alanları şunlardır.
Bir çevrimiçi e-ticaret platformu, kullanıcı etkinliğini gerçek zamanlı izlemek için Kafka’yı kullanabilir. Ürün görüntüleme, sepete ekleme, satın alma, yorum yapma, arama yapma vb. her kullanıcı eylemi, belirli Kafka konularına bir olay olarak yayımlanabilir.
Diğer mikro hizmetler bu olayları gerçek zamanlı sahtekarlık tespiti, raporlama, kişiselleştirilmiş teklifler ve öneriler için depolayabilir veya kullanabilir.
Geliştirilmiş aktarım hızı, yerleşik bölümlendirme, çoğaltma, hata toleransı ve ölçekleme yetenekleriyle Kafka, geleneksel mesaj aracılarının iyi bir alternatifidir.
Mikro hizmet tabanlı bir yolculuk çağırma uygulaması, çeşitli hizmetler arasında mesaj alışverişini kolaylaştırmak için Kafka’yı kullanabilir.
Örneğin, yolculuk rezervasyonu yapan bir kullanıcı olduğunda işletme, sürücü eşleştirme hizmetiyle Kafka üzerinden iletişim kurabilir. Sürücü eşleştirme hizmeti de neredeyse gerçek zamanlı olarak yakındaki bir sürücüyü bulup bir mesajla yanıt verebilir.
Genellikle bu, sunuculardan fiziksel günlük dosyalarının alınmasını ve bunların bir dosya sunucusu veya veri gölü gibi merkezi bir konumda işlenmek üzere saklanmasını içerir. Kafka, veriyi bir ileti akışı olarak soyutlar ve dosyaya özel bilgileri ayıklar. Bu, daha düşük gecikmeyle işlemeyi ve dağıtık veri tüketimi ile farklı veri kaynaklarını daha kolay desteklemeyi mümkün kılar.
Günlükler Kafka’ya yayımlandıktan sonra, bir günlük analiz aracı veya güvenlik bilgileri ve olay yönetimi (SIEM) sistemi tarafından sorun giderme, güvenlik izleme ve uyumluluk raporlaması için kullanılabilir.
Pek çok Kafka kullanıcısı, veriyi çok aşamalı işleme boru hatlarında işler. Ham giriş verisi Kafka konularından alınır; toplanır, zenginleştirilir veya başka şekillerde dönüştürülerek ilave tüketim veya işleme için yeni konulara aktarılır.
Örneğin, bir banka gerçek zamanlı işlemleri işlemek için Kafka’yı kullanabilir. Bir müşterinin başlattığı her işlem, bir olay olarak bir Kafka konusuna gönderilir. Ardından bir uygulama bu olayları alabilir, işlemleri doğrulayıp işleyebilir, şüpheli olanları durdurabilir ve müşteri bakiyelerini anında güncelleyebilir.
Bir bulut hizmeti sağlayıcısı, dağıtık uygulamalardan istatistikleri toplayarak gerçek zamanlı merkezi operasyonel veri akışları üretmek için Kafka’yı kullanabilir. Yüzlerce sunucudan CPU ve bellek kullanımı, istek sayıları, hata oranları vb. metrikler Kafka’ya raporlanabilir. İzleme uygulamaları daha sonra bu metrikleri anomali tespiti, uyarı ve gerçek zamanlı görselleştirme için kullanabilir.
Kafka, uygulamaların büyük miktarda kayıt akışını hızlı ve güvenilir biçimde yayımlamasını, tüketmesini ve işlemesini sağlayan bir akış işleme çerçevesidir. Gerçek zamanlı veri akışının giderek yaygınlaşması göz önüne alındığında, veri uygulaması geliştiricileri için hayati bir araç haline gelmiştir.
Bu yazıda, neden Kafka kullanılabileceği, temel bileşenler, nasıl başlanacağı, gelişmiş özellikler ve gerçek dünya uygulamalarını ele aldık. Öğrenmeye devam etmek için şunlara göz atın:
Veri Mühendisi Yolculuğunuza Bugün Başlayın!
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
