Programa
Engenheiro de dados Em Python
40 h
Depois de armazenar os eventos, a plataforma de streaming de eventos os direciona para os serviços relevantes. Os desenvolvedores podem dimensionar e manter um sistema como esse sem depender de outros serviços. Como o Kafka é um pacote completo que pode ser usado como corretor de mensagens, armazenamento de eventos ou estrutura de processamento de fluxo, ele funciona de forma excelente para esse requisito.
Com alta taxa de transferência e durabilidade, centenas de fontes de dados podem fornecer simultaneamente enormes fluxos de dados contínuos que podem ser processados sequencial e progressivamente pelo sistema de corretor de mensagens do Apache Kafka.
Além disso, as vantagens do Apache Kafka incluem:
A arquitetura bem projetada do Kafka, que inclui particionamento de dados, processamento em lote, técnicas de cópia zero e registros somente de anexação, permite que ele atinja uma alta taxa de transferência e manipule milhões de mensagens por segundo, atendendo a cenários de dados de alta velocidade e alto volume. Assim, o protocolo de comunicação leve que facilita a interação eficaz entre cliente e corretor torna viável o streaming de dados em tempo real.
O Apache Kafka oferece balanceamento de carga entre servidores, dividindo um tópico em várias partições. Isso permite que os usuários distribuam clusters de produção entre áreas geográficas ou zonas de disponibilidade e aumentem ou diminuam sua escala para atender às suas necessidades. Em outras palavras, o Apache Kafka pode ser facilmente ampliado para lidar com trilhões de mensagens por dia em um grande número de partições.
O Apache Kafka usa um cluster de servidores com baixa latência (até 2 milissegundos) para entregar mensagens com eficiência em uma taxa de transferência limitada pela rede, desacoplando os fluxos de dados.
O Apache Kafka aprimora a tolerância a falhas e a durabilidade dos dados de duas maneiras principais:
Devido aos seus corretores baseados em cluster, o Kafka permanece operacional durante uma interrupção do servidor. Isso funciona porque, quando um dos servidores apresenta problemas, o Kafka é inteligente o suficiente para enviar consultas a diferentes brokers.
O Apache Kafka permite que os usuários analisem dados em tempo real, armazenem registros na ordem em que foram criados e publiquem e assinem esses dados.
Os principais componentes do Apache Kafka | Fonte: Inicie seu pipeline em tempo real com o Apache Kafka por Alex Kam
O Apache Kafka é um cluster horizontalmente dimensionável de servidores de commodities que processa dados em tempo real de vários sistemas e aplicativos "produtores" (por exemplo, registro, monitoramento, sensores e aplicativos da Internet das Coisas) e os disponibiliza para vários sistemas e aplicativos "consumidores" (por exemplo, análise em tempo real) com latência muito baixa, conforme mostrado no diagrama acima.
Observe que os aplicativos que dependem de sistemas de análise e processamento de dados em tempo real podem ser considerados consumidores. Por exemplo, um aplicativo para micromarketing ou logística com base em localização.
Aqui estão alguns termos importantes que você deve conhecer para entender melhor os principais componentes do Kafka:
Geralmente, recomenda-se que você inicie o Apache Kafka com o Zookeeper para obter compatibilidade ideal. Além disso, o Kafka pode ter vários problemas quando instalado no Windows, pois não foi projetado nativamente para uso com esse sistema operacional. Consequentemente, é recomendável que você use o seguinte para iniciar o Apache Kafka no Windows:
Não é aconselhável usar o JVM para executar o Kafka no Windows, pois ele não tem algumas das características POSIX exclusivas do Linux. Você acabará encontrando dificuldades se tentar executar o Kafka no Windows sem o WSL2.
Dito isso, a primeira etapa para instalar o Apache Kafka no Windows é instalar o WSL2.
O WSL2, ou Windows Subsystem for Linux 2, oferece ao seu PC com Windows acesso a um ambiente Linux sem a necessidade de uma máquina virtual.
A maioria dos comandos do Linux é compatível com o WSL2, o que aproxima o processo de instalação do Kafka das instruções oferecidas para Mac e Linux.
Dica: Verifique se você está executando o Windows 10 versão 2004 ou superior (Build 19041 e superior) antes de instalar o WSL2. Pressione a tecla do logotipo do Windows + R, digite "winver" e clique em OK para ver sua versão do Windows.
A maneira mais fácil de instalar o Windows Subsystem for Linux (WSL) é executando o seguinte comando em um PowerShell de administrador ou no prompt de comando do Windows e, em seguida, reiniciando o computador:
wsl --installObserve que você será solicitado a criar uma conta de usuário e uma senha para a distribuição do Linux recém-instalada.
Siga as etapas no site do Microsoft Docs se você tiver dúvidas.
Se o Java não estiver instalado em seu computador, você precisará fazer download da versão mais recente.
Etapa 3: Instalar o Apache Kafka
No momento em que este artigo foi escrito, a última versão estável do Apache Kafka era a 3.7.0, lançada em 27 de fevereiro de 2024. Isso pode mudar a qualquer momento. Para garantir que você esteja usando a versão mais atualizada e estável do Kafka, consulte a página de download.
Faça o download da versão mais recente nos downloads de binários.
Quando o download estiver concluído, navegue até a pasta em que o Kafka foi baixado e extraia todos os arquivos da pasta compactada. Observe que nomeamos nossa nova pasta como "Kafka".
O Zookeeper é necessário para o gerenciamento de clusters no Apache Kafka. Portanto, o Zookeeper deve ser iniciado antes do Kafka. Não é necessário instalar o Zookeeper separadamente, pois ele faz parte do Apache Kafka.
Abra o prompt de comando e navegue até o diretório raiz do Kafka. Uma vez lá, execute o seguinte comando para iniciar o Zookeeper:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesAbra outro prompt de comando e execute o seguinte comando na raiz do Apache Kafka para iniciar o Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesPara criar um tópico, inicie um novo prompt de comando no diretório raiz do Kafka e execute o seguinte comando:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Isso criará um novo tópico do Kafka chamado "MyFirstTopic".
Observação: para confirmar que ele foi criado corretamente, a execução do comando retornará "Criar tópico <nome do tópico>".
Um produtor deve ser iniciado para que você possa colocar uma mensagem no tópico do Kafka. Para isso, execute o seguinte comando:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Abra outro prompt de comando no diretório raiz do Kafka e execute o seguinte comando para enviar ao stat o consumidor do Kafka:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Agora, quando uma mensagem é produzida no Produtor, ela é lida pelo Consumidor em tempo real.
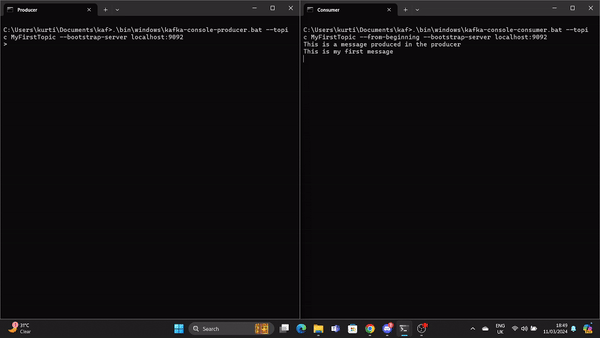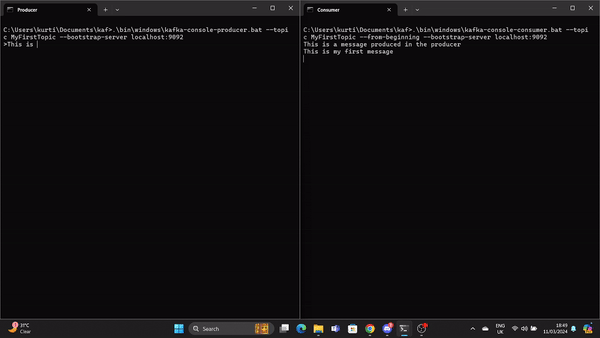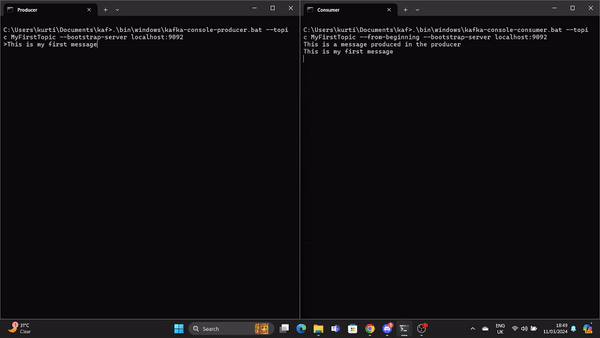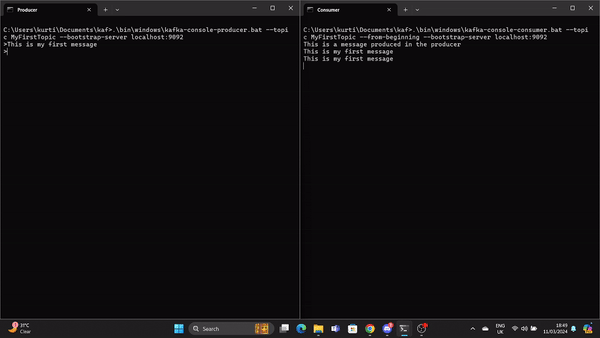
Um GIF demonstra uma mensagem produzida pelo Produtor e lida pelo Consumidor Kafka em tempo real.
Pronto... Você acabou de criar seu primeiro tópico do Kafka.
Aqui estão alguns recursos avançados do Kafka...
Usando o Apache Kafka, os desenvolvedores podem criar aplicativos robustos de processamento de fluxo com a ajuda do Kafka Streams. Ele oferece APIs e uma linguagem específica de domínio (DSL) de alto nível para manipulação, conversão e avaliação de fluxos contínuos de dados.
Alguns dos principais recursos incluem:
O processamento em tempo real de fluxos de registros é possível graças ao Kafka Streams. Ele permite que você receba dados dos tópicos do Kafka, processe e transforme os dados e, em seguida, retorne as informações processadas aos tópicos do Kafka. O processamento de fluxo permite a análise, o monitoramento e o enriquecimento de dados quase em tempo real. Ele pode ser aplicado a gravações individuais ou a agregações com janelas.
Usando os carimbos de data e hora anexados aos registros, você pode lidar com registros fora de ordem com o suporte do Kafka Streams para processamento em tempo de evento. Ele oferece operações de janelamento com semântica de tempo de evento, permitindo a junção de janelas, a sessionização e as agregações baseadas em tempo.
O Kafka Streams oferece várias operações de janelamento que permitem que os usuários executem cálculos em janelas de sessão, janelas móveis, janelas deslizantes e janelas de tempo fixo.
Acionadores baseados em eventos, análises sensíveis ao tempo e agregações baseadas no tempo são possíveis por meio de procedimentos em janelas.
Durante o processamento do fluxo, o Kafka Streams permite que os usuários mantenham e atualizem o estado. É fornecido suporte integrado para lojas estaduais. Observe que um armazenamento de estado é um armazenamento de valor-chave que pode ser atualizado e consultado em uma topologia de processamento.
As funções avançadas de processamento de fluxo, como junções, agregações e detecção de anomalias, são possibilitadas por operações com estado.
O Kafka Streams oferece semântica de ponta a ponta para processamento exatamente único, garantindo que cada registro seja tratado exatamente uma vez, mesmo em caso de falha. Para isso, você utiliza as robustas garantias de durabilidade e os recursos transacionais do Kafka.
A estrutura de integração de dados declarativa e conectável para o Kafka é chamada de Kafka Connect. É um componente gratuito e de código aberto do Apache Kafka que atua como um hub de dados centralizado para integração simples de dados entre sistemas de arquivos, bancos de dados, índices de pesquisa e armazenamentos de valores-chave.
A distribuição do Kafka inclui o Kafka Connect por padrão. Para instalá-lo, você só precisa iniciar um processo de trabalho.
Use o seguinte comando no diretório raiz do Kafka para iniciar o processo de trabalho do Kafka Connect:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesIsso iniciará o trabalhador do Kafka Connect no modo distribuído, permitindo a alta disponibilidade e o dimensionamento da execução de vários trabalhadores em um cluster.
Observação: O arquivo .\config\connect-distributed.properties especifica as informações do corretor Kafka e outras propriedades de configuração do Kafka Connect.
Os conectores são usados pelo Kafka Connect para transferir dados entre sistemas externos e tópicos do Kafka. Os conectores podem ser instalados e configurados para atender aos seus requisitos exclusivos de integração de dados.
Para instalar um conector, você só precisa fazer download e adicionar o arquivo JAR do conector ao diretório plugin.path mencionado no arquivo .\config\connect-distributed.properties.
Um arquivo de configuração para o conector deve ser criado, no qual a classe do conector e quaisquer outras características devem ser especificadas. A API REST do Kafka Connect e as ferramentas de linha de comando podem ser usadas para criar e manter conectores.
Em seguida, para combinar dados de outros sistemas, você deve configurar o Kafka Connector. O Kafka Connect oferece vários conectores para integrar dados de vários sistemas, como sistemas de arquivos, filas de mensagens e bancos de dados. Selecione um conector com base nas necessidades que você tem de integração - consulte a documentação para obter a lista de conectores.
Aqui estão alguns casos de uso comuns do Apache Kafka.
O Kafka pode ser usado por uma plataforma de comércio eletrônico on-line para rastrear a atividade do usuário em tempo real. Cada ação do usuário, inclusive visualizar produtos, adicionar itens a carrinhos, fazer compras, deixar comentários, fazer pesquisas e assim por diante, pode ser publicada como um evento em tópicos específicos do Kafka.
Outros microsserviços podem armazenar ou usar esses eventos para detecção de fraudes em tempo real, relatórios, ofertas personalizadas e recomendações.
Com sua taxa de transferência aprimorada, particionamento integrado, replicação, tolerância a falhas e recursos de dimensionamento, o Kafka é um bom substituto para os corretores de mensagens convencionais.
Um aplicativo de carona baseado em microsserviços pode usá-lo para facilitar a troca de mensagens entre vários serviços.
Por exemplo, a empresa de reservas de carona pode usar o Kafka para se comunicar com o serviço de correspondência de motoristas quando um passageiro faz uma reserva. O serviço de correspondência de motoristas pode então, quase em tempo real, localizar um motorista na área e responder com uma mensagem.
Normalmente, isso implica a obtenção de arquivos de log físicos dos servidores e seu armazenamento em um local central para processamento, como um servidor de arquivos ou um lago de dados. O Kafka abstrai os dados como um fluxo de mensagens e filtra as informações específicas do arquivo. Isso possibilita o processamento de dados com latência reduzida e a acomodação mais fácil do consumo de dados distribuídos e de diferentes fontes de dados.
Depois que os logs são publicados no Kafka, eles podem ser usados para solução de problemas, monitoramento de segurança e relatórios de conformidade por uma ferramenta de análise de logs ou um sistema de gerenciamento de eventos e informações de segurança (SIEM).
Vários usuários do Kafka processam dados em pipelines de processamento de vários estágios. Os dados brutos de entrada são obtidos dos tópicos do Kafka, agregados, enriquecidos ou transformados em novos tópicos para consumo ou processamento adicional.
Por exemplo, um banco pode usar o Kafka para processar transações em tempo real. Cada transação iniciada por um cliente é postada em um tópico do Kafka como um evento. Posteriormente, um aplicativo pode receber esses eventos, verificar e tratar as transações, interromper as duvidosas e atualizar instantaneamente os saldos dos clientes.
O Kafka pode ser usado por um provedor de serviços em nuvem para agregar estatísticas de aplicativos distribuídos para gerar fluxos centralizados de dados operacionais em tempo real. As métricas de centenas de servidores, como consumo de CPU e memória, contagem de solicitações, taxas de erro, etc., podem ser informadas ao Kafka. Os aplicativos de monitoramento podem então usar essas métricas para identificação de anomalias, alertas e visualização em tempo real.
O Kafka é uma estrutura para processamento de fluxos que permite que os aplicativos publiquem, consumam e processem grandes quantidades de fluxos de registros de forma rápida e confiável. Considerando a crescente prevalência do streaming de dados em tempo real, ele se tornou uma ferramenta vital para os desenvolvedores de aplicativos de dados.
Neste artigo, abordamos por que você pode decidir usar o Kafka, os componentes principais, como começar a usá-lo, os recursos avançados e os aplicativos do mundo real. Para continuar seu aprendizado, confira:
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Comece sua jornada de engenheiro de dados hoje mesmo!
Programa
Curso
Curso
blog
Adejumo Ridwan Suleiman
13 min
blog
Çağlar Uslu
15 min
blog
Kurtis Pykes
11 min
Tutorial
Javier Canales Luna
Tutorial
Moez Ali
Tutorial
Tim Lu