
Tracks
Associate Data Engineer in Databricks
37 giờ
Apache Kafka là một khung phát luồng sự kiện phân tán mã nguồn mở do nhóm tại LinkedIn phát triển, bao gồm Jay Kreps, Jun Rao và Neha Narkhede. Công cụ này được tối ưu để thu nhận và xử lý dữ liệu streaming theo thời gian thực; do đó có thể dùng để triển khai các pipeline dữ liệu hiệu năng cao, ứng dụng phân tích streaming và dịch vụ tích hợp dữ liệu.
Sau khi lưu trữ các sự kiện, nền tảng phát luồng sẽ chuyển chúng tới các dịch vụ phù hợp. Nhà phát triển có thể mở rộng và vận hành một hệ thống như vậy mà không phụ thuộc vào các dịch vụ khác. Vì Kafka là một gói tất cả trong một có thể dùng làm message broker, event store, hoặc khung xử lý luồng, nó hoạt động rất hiệu quả cho yêu cầu này.
Với thông lượng cao và độ bền dữ liệu, hàng trăm nguồn dữ liệu có thể đồng thời cung cấp lượng lớn dòng dữ liệu liên tục được hệ thống message broker của Apache Kafka xử lý tuần tự và dần dần.
Kafka khác với các message broker truyền thống như RabbitMQ ở một số điểm căn bản:
| Tính năng | Apache Kafka | Broker truyền thống (ví dụ: RabbitMQ) |
|---|---|---|
| Giữ lại thông điệp | Cấu hình được (từ ngày đến năm); thông điệp vẫn tồn tại sau khi tiêu thụ | Thông điệp bị xóa sau khi consumer xác nhận |
| Mô hình consumer | Kéo (pull); consumer đọc theo nhịp riêng | Đẩy (push); broker gửi đến consumer |
| Thông lượng | Hàng triệu thông điệp mỗi giây | Hàng nghìn đến hàng chục nghìn mỗi giây |
| Thứ tự | Đảm bảo trong một partition | Phụ thuộc hiện thực |
| Phát lại | Consumer có thể đọc lại thông điệp cũ tại mọi offset | Không hỗ trợ sau khi đã giao |
| Trường hợp sử dụng chính | Phát luồng sự kiện, tổng hợp log, pipeline thời gian thực | Hàng đợi tác vụ, mẫu yêu cầu–phản hồi |
Các ưu điểm chính của Apache Kafka gồm:
Kiến trúc được thiết kế tốt của Kafka, bao gồm phân vùng dữ liệu, xử lý theo lô, kỹ thuật zero-copy và log chỉ-thêm, cho phép đạt thông lượng cao và xử lý hàng triệu thông điệp mỗi giây, phục vụ các kịch bản dữ liệu tốc độ và khối lượng lớn. Nhờ đó, giao thức giao tiếp nhẹ giúp tương tác client–broker hiệu quả, biến phát luồng dữ liệu thời gian thực thành khả thi.
Apache Kafka cung cấp cân bằng tải giữa các máy chủ bằng cách phân chia một topic thành nhiều partition. Điều này cho phép phân phối cụm sản xuất giữa các khu vực địa lý hoặc vùng sẵn sàng và mở rộng lên/xuống theo nhu cầu. Nói cách khác, Apache Kafka có thể dễ dàng mở rộng để xử lý hàng nghìn tỷ thông điệp mỗi ngày trên số lượng lớn partition.
Apache Kafka sử dụng một cụm máy chủ với độ trễ thấp (chỉ khoảng 2 mili giây) để phân phối thông điệp hiệu quả ở mức thông lượng giới hạn bởi mạng bằng cách tách rời các luồng dữ liệu.
Apache Kafka tăng cường khả năng chịu lỗi và độ bền dữ liệu theo hai cách chính:
Nhờ các broker theo cụm, Kafka vẫn hoạt động khi một máy chủ gặp sự cố. Điều này hoạt động vì khi một máy chủ gặp vấn đề, Kafka đủ thông minh để chuyển truy vấn sang broker khác.
Apache Kafka cho phép bạn phân tích dữ liệu theo thời gian thực, lưu bản ghi theo thứ tự tạo ra, và xuất bản/đăng ký chúng.
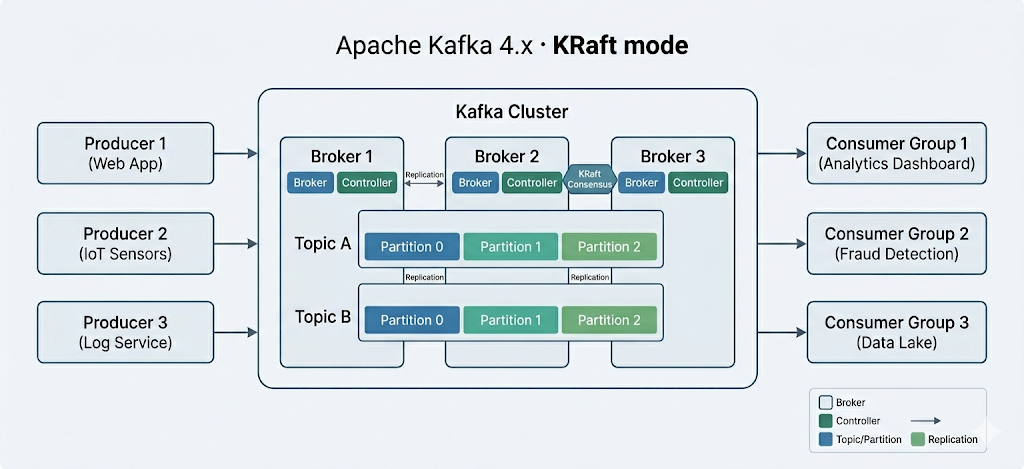
Các thành phần cốt lõi của Apache Kafka
Apache Kafka là một cụm mở rộng ngang của các máy chủ phổ thông, xử lý dữ liệu thời gian thực từ nhiều hệ thống và ứng dụng "producer" (ví dụ: logging, giám sát, cảm biến và ứng dụng Internet of Things) và cung cấp cho nhiều hệ thống và ứng dụng "consumer" (ví dụ: phân tích thời gian thực) với độ trễ rất thấp – như trong sơ đồ trên.
Lưu ý rằng các ứng dụng phụ thuộc vào xử lý dữ liệu thời gian thực và hệ thống phân tích đều được xem là consumer. Ví dụ, một ứng dụng micromarketing theo vị trí hoặc logistics.
Dưới đây là một số thuật ngữ quan trọng để bạn hiểu rõ hơn các thành phần cốt lõi của Kafka:
Quan trọng (cập nhật 2025): Apache Kafka 4.0, phát hành tháng 3/2025, đã loại bỏ ZooKeeper hoàn toàn để dùng KRaft (Kafka Raft) mode. Hướng dẫn cài đặt bên dưới dùng ZooKeeper và chỉ áp dụng cho Kafka 3.x. Với Kafka 4.x, ZooKeeper không còn cần thiết hay được hỗ trợ. Nếu bạn bắt đầu mới, hãy cân nhắc dùng Docker với chế độ KRaft để thiết lập đơn giản hơn.
Thường khuyến nghị khởi chạy Apache Kafka 3.x với Zookeeper để có độ tương thích tối ưu. Ngoài ra, Kafka có thể gặp một số vấn đề khi cài trên Windows vì không được thiết kế gốc cho hệ điều hành này. Do đó, nên chạy Apache Kafka trên Windows bằng WSL2 hoặc Docker.
Không khuyến nghị dùng JVM để chạy Kafka trên Windows vì thiếu một số đặc tính POSIX riêng của Linux. Bạn sẽ sớm gặp khó khăn nếu cố chạy Kafka trên Windows mà không dùng WSL2.
Vậy nên, bước đầu để cài Apache Kafka trên Windows là cài WSL2.
WSL2, hay Windows Subsystem for Linux 2, cung cấp cho máy Windows của bạn một môi trường Linux mà không cần máy ảo.
Hầu hết lệnh Linux đều tương thích với WSL2, đưa quá trình cài đặt Kafka gần hơn với hướng dẫn cho Mac và Linux.
Mẹo: Hãy đảm bảo bạn đang chạy Windows 10 phiên bản 2004 trở lên (Bản dựng 19041 trở lên) trước khi cài WSL2. Nhấn phím logo Windows + R, gõ “winver”, rồi nhấn OK để xem phiên bản Windows.
Cách dễ nhất để cài Windows Subsystem for Linux (WSL) là chạy lệnh sau trong PowerShell quản trị hoặc Command Prompt của Windows rồi khởi động lại máy:
wsl --installLưu ý bạn sẽ được nhắc tạo tài khoản và mật khẩu cho bản phân phối Linux mới cài.
Làm theo các bước trên trang Microsoft Docs nếu bạn gặp vướng mắc.
Nếu máy bạn chưa có Java, bạn cần tải phiên bản mới nhất.
Tính đến cập nhật này, phiên bản ổn định mới nhất của Apache Kafka là 4.2.0, phát hành tháng 2/2026. Kafka 4.0 (tháng 3/2025) đã thay ZooKeeper bằng chế độ KRaft để quản lý metadata. Để lấy phiên bản ổn định hiện tại, xem trang tải xuống.
Tải phiên bản mới nhất từ mục Binary downloads.
Sau khi tải xong, điều hướng đến thư mục đã tải Kafka và giải nén toàn bộ tệp từ thư mục nén. Lưu ý chúng tôi đã đặt tên thư mục mới là “Kafka.”
Zookeeper cần thiết để quản lý cụm trong Apache Kafka 3.x. Do đó phải khởi chạy Zookeeper trước Kafka. Không cần cài riêng Zookeeper vì nó là một phần của Apache Kafka.
Mở command prompt và chuyển đến thư mục gốc của Kafka. Tại đó, chạy lệnh sau để khởi động Zookeeper:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesMở một command prompt khác và chạy lệnh sau từ thư mục gốc Apache Kafka để khởi động Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesĐể tạo một topic, mở một command prompt mới từ thư mục gốc Kafka và chạy lệnh sau:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Lệnh này sẽ tạo một topic Kafka mới tên “MyFirstTopic.”
Lưu ý: để xác nhận đã tạo đúng, thực thi lệnh sẽ trả về “Create topic <name of topic>.”
Cần khởi động một producer để đưa thông điệp vào topic Kafka. Thực thi lệnh sau để làm điều đó:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Mở một command prompt khác từ thư mục gốc Kafka và chạy lệnh sau để khởi động consumer của Kafka:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Giờ đây, khi một thông điệp được tạo ở Producer, nó sẽ được Consumer đọc theo thời gian thực.
Một ảnh GIF minh họa thông điệp do Producer tạo ra và được Kafka Consumer đọc theo thời gian thực.
Bạn vừa tạo topic Kafka đầu tiên và gửi một thông điệp từ producer đến consumer theo thời gian thực.
Kafka cung cấp một số tính năng nâng cao vượt ra ngoài việc truyền thông điệp cơ bản.
Với Apache Kafka, nhà phát triển có thể xây dựng ứng dụng xử lý luồng chịu lỗi bằng Kafka Streams. Nó cung cấp API và một Ngôn ngữ Miền Chuyên biệt (DSL) cấp cao để xử lý, chuyển đổi và đánh giá các luồng dữ liệu liên tục.
Một vài tính năng chính gồm:
Kafka Streams cho phép xử lý thời gian thực các luồng bản ghi. Bạn có thể tiếp nhận dữ liệu từ các topic Kafka, xử lý và chuyển đổi dữ liệu, rồi đưa thông tin đã xử lý trở lại các topic Kafka. Xử lý luồng cho phép phân tích, giám sát và làm giàu dữ liệu gần thời gian thực. Có thể áp dụng cho từng bản ghi hoặc cho các phép tổng hợp theo cửa sổ.
Dựa trên timestamp gắn với bản ghi, bạn có thể xử lý bản ghi lệch thứ tự nhờ hỗ trợ xử lý theo thời gian sự kiện của Kafka Streams. Nó cung cấp các phép cửa sổ theo ngữ nghĩa thời gian sự kiện, cho phép join theo cửa sổ, phân phiên (sessionization) và tổng hợp theo thời gian.
Kafka Streams cung cấp nhiều phép cửa sổ cho phép thực hiện tính toán trên session window, tumbling window, sliding window và cửa sổ thời gian cố định.
Các thủ tục theo cửa sổ cho phép kích hoạt dựa trên sự kiện, phân tích nhạy thời gian và tổng hợp theo thời gian.
Trong khi xử lý luồng, Kafka Streams cho phép lưu và cập nhật trạng thái. Có hỗ trợ tích hợp cho state store. Lưu ý state store là một kho key–value có thể được cập nhật và truy vấn trong một topology xử lý.
Các chức năng xử lý luồng nâng cao như join, tổng hợp và phát hiện bất thường trở nên khả thi nhờ các phép có trạng thái.
Kafka Streams cung cấp ngữ nghĩa đầu-cuối cho xử lý đúng-một-lần, đảm bảo mỗi bản ghi được xử lý chính xác một lần — ngay cả khi có sự cố. Điều này đạt được bằng cách tận dụng các đảm bảo về độ bền tích hợp và tính năng giao dịch của Kafka.
Kafka Connect là khung tích hợp dữ liệu khai báo, có thể bổ sung plugin cho Kafka. Đây là một thành phần mã nguồn mở, miễn phí của Apache Kafka, hoạt động như một trung tâm dữ liệu tập trung để tích hợp dữ liệu dễ dàng giữa hệ thống tệp, cơ sở dữ liệu, chỉ mục tìm kiếm và kho key–value.
Bản phân phối Kafka bao gồm Kafka Connect theo mặc định. Để cài đặt, bạn chỉ cần khởi động một tiến trình worker.
Dùng lệnh sau từ thư mục gốc Kafka để khởi chạy tiến trình worker của Kafka Connect:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesLệnh này sẽ khởi chạy Kafka Connect worker ở chế độ phân tán, cho phép tính sẵn sàng cao và mở rộng bằng cách chạy nhiều worker trong một cụm.
Lưu ý: Tệp .\config\connect-distributed.properties chỉ định thông tin broker Kafka và các thuộc tính cấu hình khác cho Kafka Connect.
Kafka Connect sử dụng connector để chuyển dữ liệu giữa hệ thống bên ngoài và các topic Kafka. Connector có thể được cài đặt và cấu hình phù hợp với yêu cầu tích hợp dữ liệu cụ thể của bạn.
Để cài một connector, chỉ cần tải tệp JAR của connector và thêm vào thư mục plugin.path được nêu trong tệp .\config\connect-distributed.properties.
Cần tạo một tệp cấu hình cho connector, trong đó chỉ định lớp connector và các thuộc tính khác. Có thể dùng REST API và công cụ dòng lệnh của Kafka Connect để tạo và quản lý connector.
Tiếp theo, để hợp nhất dữ liệu từ hệ thống khác, bạn phải cấu hình Kafka Connector. Kafka Connect cung cấp nhiều connector để tích hợp dữ liệu từ các hệ thống như hệ thống tệp, hàng đợi thông điệp và cơ sở dữ liệu. Chọn connector dựa trên nhu cầu tích hợp của bạn — xem tài liệu để biết danh sách connector.
Dưới đây là một vài trường hợp sử dụng phổ biến của Apache Kafka.
Một nền tảng thương mại điện tử trực tuyến có thể dùng Kafka để theo dõi hoạt động của người dùng theo thời gian thực. Mỗi hành động của người dùng, bao gồm xem sản phẩm, thêm vào giỏ, mua hàng, để lại đánh giá, tìm kiếm, v.v., có thể được xuất bản như một sự kiện vào các topic Kafka cụ thể.
Các microservice khác có thể lưu trữ hoặc sử dụng các sự kiện này để phát hiện gian lận thời gian thực, báo cáo, đề xuất và ưu đãi cá nhân hóa.
Với thông lượng vượt trội, phân vùng, nhân bản, chịu lỗi và khả năng mở rộng tích hợp, Kafka là một lựa chọn thay thế tốt cho các message broker truyền thống.
Một ứng dụng gọi xe dựa trên microservices có thể dùng Kafka để hỗ trợ trao đổi thông điệp giữa các dịch vụ.
Ví dụ, doanh nghiệp đặt xe có thể dùng Kafka để liên lạc với dịch vụ ghép tài xế khi khách đặt chuyến. Dịch vụ ghép tài xế sau đó có thể tìm tài xế gần đó gần như theo thời gian thực và phản hồi bằng một thông điệp.
Thông thường, việc này bao gồm lấy tệp log vật lý từ các máy chủ và lưu vào một vị trí trung tâm để xử lý, như máy chủ tệp hoặc data lake. Kafka trừu tượng hóa dữ liệu thành một luồng thông điệp và lọc thông tin đặc thù của tệp. Điều này cho phép xử lý dữ liệu với độ trễ thấp hơn và dễ dàng đáp ứng tiêu thụ dữ liệu phân tán cùng các nguồn dữ liệu khác nhau.
Sau khi log được xuất bản lên Kafka, chúng có thể được công cụ phân tích log hoặc hệ thống quản lý thông tin và sự kiện bảo mật (SIEM) sử dụng cho việc khắc phục sự cố, giám sát an ninh và báo cáo tuân thủ.
Nhiều người dùng Kafka xử lý dữ liệu trong các pipeline nhiều giai đoạn. Dữ liệu đầu vào thô được lấy từ các topic Kafka, được tổng hợp, làm giàu hoặc chuyển đổi thành các topic mới để tiêu thụ hay xử lý tiếp.
Ví dụ, một ngân hàng có thể dùng Kafka để xử lý giao dịch thời gian thực. Mỗi giao dịch do khách hàng khởi tạo sẽ được đăng lên một topic Kafka như một sự kiện. Sau đó, một ứng dụng có thể tiếp nhận các sự kiện này, xác minh và xử lý giao dịch, chặn giao dịch đáng ngờ và cập nhật số dư khách hàng ngay lập tức.
Một nhà cung cấp dịch vụ đám mây có thể dùng Kafka để tổng hợp thống kê từ các ứng dụng phân tán nhằm tạo ra các luồng dữ liệu vận hành tập trung theo thời gian thực. Chỉ số từ hàng trăm máy chủ, như mức dùng CPU và bộ nhớ, số lượng yêu cầu, tỉ lệ lỗi, v.v., có thể được báo cáo về Kafka. Các ứng dụng giám sát sau đó có thể dùng các chỉ số này để phát hiện bất thường, cảnh báo và trực quan hóa theo thời gian thực.
Apache Kafka là tiêu chuẩn trong ngành cho phát luồng sự kiện thời gian thực, được hơn 80% công ty Fortune 100 sử dụng. Với Kafka 4.0 và chế độ KRaft, việc triển khai và quản lý cụm trở nên đơn giản hơn so với các phiên bản trước.
Trong bài viết này, tôi đã trình bày vì sao Kafka quan trọng, các thành phần cốt lõi, thiết lập từng bước, các tính năng nâng cao như Kafka Streams và Kafka Connect, cùng ứng dụng thực tế. Để tiếp tục học, hãy xem:
Bắt đầu hành trình Data Engineer của bạn ngay hôm nay!
Tracks
Courses
Courses