
Lernpfad
Dateningenieur in Python
40 Std.
Nachdem die Ereignisse gespeichert wurden, leitet die Event-Streaming-Plattform sie an die entsprechenden Dienste weiter. Die Entwickler können ein solches System skalieren und pflegen, ohne auf andere Dienste angewiesen zu sein. Da Kafka ein All-in-One-Paket ist, das als Message Broker, Event Store oder Stream Processing Framework eingesetzt werden kann, eignet es sich hervorragend für solche Anforderungen.
Dank des hohen Durchsatzes und der Langlebigkeit können Hunderte von Datenquellen gleichzeitig riesige, kontinuierliche Datenströme liefern, die vom Message Broker-System von Apache Kafka sequentiell und progressiv verarbeitet werden können.
Zu den Vorteilen von Apache Kafka gehören außerdem:
Die durchdachte Architektur von Kafka, die Datenpartitionierung, Batch-Verarbeitung, Zero-Copy-Techniken und Append-Only-Logs umfasst, ermöglicht einen hohen Durchsatz und die Verarbeitung von Millionen von Nachrichten pro Sekunde und eignet sich damit für Szenarien mit hoher Geschwindigkeit und großem Datenvolumen. Das leichtgewichtige Kommunikationsprotokoll, das eine effektive Client-Broker-Interaktion ermöglicht, macht das Datenstreaming in Echtzeit möglich.
Apache Kafka ermöglicht einen Lastausgleich zwischen den Servern, indem ein Topic in mehrere Partitionen aufgeteilt wird. Dies ermöglicht es den Nutzern, Produktionscluster auf geografische Gebiete oder Verfügbarkeitszonen zu verteilen und sie je nach Bedarf zu vergrößern oder zu verkleinern. Mit anderen Worten: Apache Kafka lässt sich problemlos so skalieren, dass es Billionen von Nachrichten pro Tag über eine große Anzahl von Partitionen verarbeiten kann.
Apache Kafka nutzt einen Cluster von Servern mit niedriger Latenz (bis zu 2 Millisekunden), um Nachrichten bei begrenztem Netzwerkdurchsatz durch Entkopplung von Datenströmen effizient zuzustellen.
Apache Kafka verbessert die Fehlertoleranz und Beständigkeit von Daten auf zwei wichtige Arten:
Dank seiner cluster-basierten Broker bleibt Kafka auch bei einem Serverausfall betriebsbereit. Das funktioniert, denn wenn einer der Server Probleme hat, ist Kafka intelligent genug, um Anfragen an verschiedene Broker zu senden.
Apache Kafka ermöglicht es, Daten in Echtzeit zu analysieren, Datensätze in der Reihenfolge zu speichern, in der sie erstellt wurden, und sie zu veröffentlichen und zu abonnieren.
Die Kernkomponenten von Apache Kafka | Quelle: Starte deine Echtzeit-Pipeline mit Apache Kafka von Alex Kam
Apache Kafka ist ein horizontal skalierbarer Cluster von Commodity-Servern, der Echtzeitdaten von mehreren "Producer"-Systemen und -Anwendungen (z. B. Logging-, Überwachungs-, Sensor- und Internet-of-Things-Anwendungen) verarbeitet und sie mehreren "Consumer"-Systemen und -Anwendungen (z. B. Echtzeit-Analysen) mit sehr geringer Latenz zur Verfügung stellt - wie in der Abbildung oben dargestellt.
Beachte, dass Anwendungen, die auf Echtzeit-Datenverarbeitung und Analysesysteme angewiesen sind, beide als Verbraucher betrachtet werden können. Zum Beispiel eine Anwendung für standortbasiertes Mikromarketing oder Logistik.
Hier sind einige wichtige Begriffe, die du kennen solltest, um die Kernkomponenten von Kafka besser zu verstehen:
Es wird oft empfohlen, Apache Kafka mit Zookeeper zu starten, um eine optimale Kompatibilität zu gewährleisten. Außerdem kann Kafka bei der Installation unter Windows auf einige Probleme stoßen, da es nicht von Haus aus für dieses Betriebssystem konzipiert ist. Es wird daher empfohlen, Apache Kafka unter Windows wie folgt zu starten:
Es ist nicht ratsam, die JVM zu verwenden, um Kafka unter Windows auszuführen, da sie einige der POSIX-Merkmale nicht besitzt, die es nur unter Linux gibt. Du wirst irgendwann auf Schwierigkeiten stoßen, wenn du versuchst, Kafka unter Windows ohne WSL2 auszuführen.
Der erste Schritt zur Installation von Apache Kafka unter Windows ist die Installation von WSL2.
WSL2, das Windows Subsystem für Linux 2, ermöglicht deinem Windows-PC den Zugriff auf eine Linux-Umgebung, ohne dass du eine virtuelle Maschine benötigst.
Die meisten Linux-Befehle sind mit WSL2 kompatibel, was den Kafka-Installationsprozess näher an die Anleitungen für Mac und Linux bringt.
Tipp: Stelle sicher, dass du Windows 10 Version 2004 oder höher (Build 19041 und höher) verwendest, bevor du WSL2 installierst. Drücke die Windows-Logo-Taste + R, gib "winver" ein und klicke dann auf OK, um deine Windows-Version zu sehen.
Am einfachsten lässt sich das Windows Subsystem für Linux (WSL) installieren, indem du den folgenden Befehl in einer Administrator-PowerShell oder Windows-Eingabeaufforderung ausführst und dann deinen Computer neu startest:
wsl --installBeachte, dass du aufgefordert wirst, ein Benutzerkonto und ein Passwort für deine neu installierte Linux-Distribution zu erstellen.
Folge den Schritten auf der Microsoft Docs Website, wenn du nicht weiterkommst.
Wenn Java auf deinem Computer nicht installiert ist, musst du die neueste Version herunterladen.
Schritt 3: Apache Kafka installieren
Zum Zeitpunkt der Erstellung dieses Artikels ist die letzte stabile Version von Apache Kafka 3.7.0, die am 27. Februar 2024 veröffentlicht wurde. Das kann sich jederzeit ändern. Um sicherzustellen, dass du die aktuellste und stabilste Version von Kafka verwendest, schau auf der Download-Seite nach.
Lade die neueste Version von den Binärdownloads herunter.
Sobald der Download abgeschlossen ist, navigiere zu dem Ordner, in dem Kafka heruntergeladen wurde, und entpacke alle Dateien aus dem gezippten Ordner. Beachte, dass wir unseren neuen Ordner "Kafka" genannt haben.
Zookeeper wird für das Cluster-Management in Apache Kafka benötigt. Deshalb muss Zookeeper vor Kafka gestartet werden. Eine separate Installation von Zookeeper ist nicht notwendig, da es Teil von Apache Kafka ist.
Öffne die Eingabeaufforderung und navigiere zum Stammverzeichnis von Kafka. Dort führst du den folgenden Befehl aus, um Zookeeper zu starten:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesÖffne eine weitere Eingabeaufforderung und führe den folgenden Befehl im Stammverzeichnis von Apache Kafka aus, um Apache Kafka zu starten:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesUm ein Thema zu erstellen, starte eine neue Eingabeaufforderung im Kafka-Stammverzeichnis und führe den folgenden Befehl aus:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Dadurch wird ein neues Kafka-Topic mit dem Namen "MyFirstTopic" erstellt.
Hinweis: Um zu bestätigen, dass das Thema korrekt erstellt wurde, wird bei der Ausführung des Befehls "Thema <Name des Themas> erstellen" zurückgegeben.
Ein Producer muss gestartet werden, um eine Nachricht in das Kafka-Topic zu stellen. Führe dazu den folgenden Befehl aus:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Öffne eine weitere Eingabeaufforderung im Kafka-Stammverzeichnis und führe den folgenden Befehl aus, um den Kafka-Consumer an stat zu senden:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Wenn der Produzent eine Nachricht erstellt, wird sie vom Konsumenten in Echtzeit gelesen.
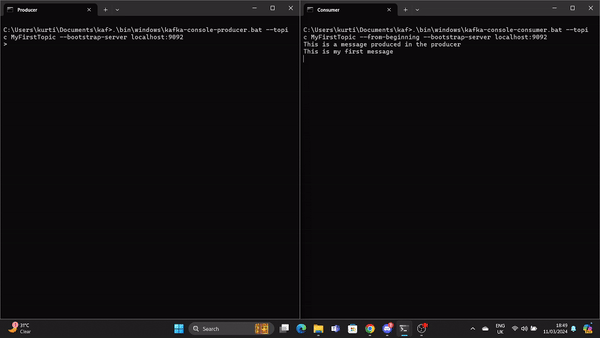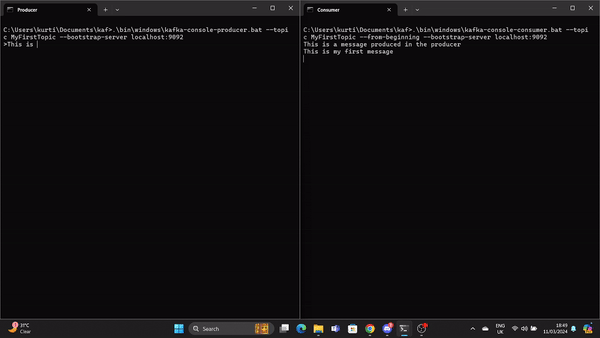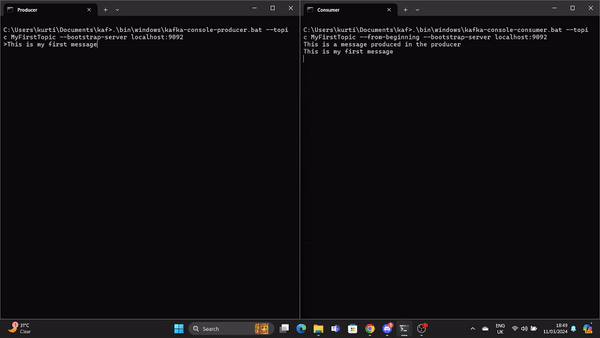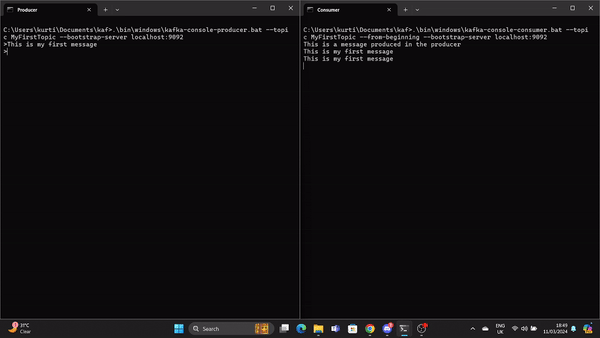
Ein GIF demonstriert eine Nachricht, die vom Producer produziert und vom Kafka-Consumer in Echtzeit gelesen wird.
Das war's... Du hast gerade dein erstes Kafka-Thema erstellt.
Hier sind ein paar erweiterte Funktionen von Kafka...
Mit Apache Kafka können Entwickler mit Hilfe von Kafka-Streams robuste Stream-Processing-Anwendungen erstellen. Sie bietet APIs und eine hochentwickelte domänenspezifische Sprache (DSL) für die Verarbeitung, Konvertierung und Auswertung von kontinuierlichen Datenströmen.
Einige der wichtigsten Merkmale sind:
Die Echtzeitverarbeitung von Datensatzströmen wird durch Kafka Streams ermöglicht. Sie ermöglicht es dir, Daten von Kafka-Themen zu empfangen, sie zu verarbeiten und umzuwandeln und die verarbeiteten Informationen dann wieder an Kafka-Themen zurückzugeben. Die Stream-Verarbeitung ermöglicht Analysen, Überwachung und Datenanreicherung nahezu in Echtzeit. Sie kann auf einzelne Aufzeichnungen oder auf gefensterte Aggregationen angewendet werden.
Mithilfe der Zeitstempel, die an die Datensätze angehängt sind, kannst du mit der Unterstützung von Kafka Streams für die Verarbeitung von Ereignissen in unregelmäßigen Abständen umgehen. Sie bietet Windowing-Operationen mit Ereigniszeit-Semantik und ermöglicht Window Joining, Sessionization und zeitbasierte Aggregationen.
Kafka Streams bietet eine Reihe von Fensteroperationen, mit denen du Berechnungen über Sitzungsfenster, wechselnde Fenster, gleitende Fenster und feste Zeitfenster durchführen kannst.
Ereignisbasierte Auslöser, zeitabhängige Analysen und zeitbasierte Aggregationen sind über gefensterte Verfahren möglich.
Während der Stream-Verarbeitung ermöglicht Kafka Streams den Nutzern, den Status zu halten und zu aktualisieren. Integrierte Unterstützung für State Stores ist vorhanden. Ein State Store ist ein Key-Value-Store, der innerhalb einer Verarbeitungstopologie aktualisiert und abgefragt werden kann.
Erweiterte Stream-Processing-Funktionen wie Joins, Aggregationen und Anomalieerkennung werden durch zustandsabhängige Operationen ermöglicht.
Kafka Streams bietet eine Ende-zu-Ende-Semantik für Exact-Once-Verarbeitung, die garantiert, dass jeder Datensatz genau einmal verarbeitet wird - auch im Falle eines Fehlers. Dies wird durch die Nutzung der robusten Haltbarkeitsgarantien und Transaktionsfunktionen von Kafka erreicht.
Das deklarative, anpassbare Datenintegrations-Framework für Kafka heißt Kafka Connect. Es ist eine kostenlose Open-Source-Komponente von Apache Kafka, die als zentrale Datendrehscheibe für die einfache Datenintegration zwischen Dateisystemen, Datenbanken, Suchindizes und Key-Value-Stores dient.
Die Kafka-Distribution enthält standardmäßig Kafka Connect. Um es zu installieren, musst du nur einen Worker-Prozess starten.
Verwende den folgenden Befehl aus dem Kafka-Stammverzeichnis, um den Kafka Connect Worker-Prozess zu starten:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesDadurch wird der Kafka-Connect-Worker im verteilten Modus gestartet, was die hohe Verfügbarkeit und Skalierbarkeit von zahlreichen Workern in einem Cluster ermöglicht.
Hinweis: In der Datei .\config\connect-distributed.properties werden die Kafka-Broker-Informationen und andere Konfigurationseigenschaften für Kafka Connect angegeben.
Konnektoren werden von Kafka Connect verwendet, um Daten zwischen externen Systemen und Kafka-Themen zu übertragen. Die Konnektoren können so installiert und konfiguriert werden, dass sie deinen individuellen Anforderungen an die Datenintegration entsprechen.
Um einen Konnektor zu installieren, musst du nur die JAR-Datei des Konnektors herunterladen und zu dem in der Datei .\config\connect-distributed.properties angegebenen Verzeichnis plugin.path hinzufügen.
Es muss eine Konfigurationsdatei für den Konnektor erstellt werden, in der die Konnektorklasse und alle anderen Eigenschaften angegeben werden müssen. Die Kafka Connect REST API und die Kommandozeilen-Tools können zum Erstellen und Verwalten von Konnektoren verwendet werden.
Um Daten aus anderen Systemen zu kombinieren, musst du als nächstes den Kafka Connector konfigurieren. Kafka Connect bietet verschiedene Konnektoren für die Integration von Daten aus unterschiedlichen Systemen, wie z.B. Dateisystemen, Message Queues und Datenbanken. Wähle einen Konnektor aus, der deinem Integrationsbedarf entspricht - eine Liste der Konnektoren findest du in der Dokumentation.
Hier sind ein paar häufige Anwendungsfälle von Apache Kafka.
Kafka kann von einer Online-E-Commerce-Plattform genutzt werden, um Nutzeraktivitäten in Echtzeit zu verfolgen. Jede Aktion eines Nutzers, wie z.B. das Ansehen von Produkten, das Hinzufügen von Artikeln zu Warenkörben, Einkäufe, das Abgeben von Bewertungen, Suchen usw., kann als Ereignis in bestimmten Kafka-Themen veröffentlicht werden.
Andere Microservices können diese Ereignisse speichern oder für Echtzeit-Betrugserkennung, Berichterstattung, personalisierte Angebote und Empfehlungen nutzen.
Mit seinem verbesserten Durchsatz, der eingebauten Partitionierung, Replikation, Fehlertoleranz und Skalierbarkeit ist Kafka ein guter Ersatz für herkömmliche Nachrichtenbroker.
Eine auf Microservices basierende Ride-Hailing-App kann sie nutzen, um den Nachrichtenaustausch zwischen verschiedenen Diensten zu erleichtern.
Zum Beispiel könnte das Unternehmen, das Fahrten bucht, Kafka nutzen, um mit dem Fahrervermittlungsdienst zu kommunizieren, wenn ein Fahrer eine Reservierung vornimmt. Der Fahrer-Vermittlungsdienst kann dann fast in Echtzeit einen Fahrer in der Nähe ausfindig machen und mit einer Nachricht antworten.
In der Regel bedeutet dies, dass physische Logdateien von Servern abgerufen und an einem zentralen Ort zur Verarbeitung gespeichert werden, z. B. auf einem Dateiserver oder Data Lake. Kafka abstrahiert die Daten als Strom von Nachrichten und filtert die dateispezifischen Informationen. Dadurch können Daten mit geringerer Latenzzeit verarbeitet und verteilter Datenkonsum und unterschiedliche Datenquellen leichter berücksichtigt werden.
Nachdem die Logs in Kafka veröffentlicht wurden, können sie von einem Log-Analyse-Tool oder einem SIEM-System (Security Information and Event Management) zur Fehlerbehebung, Sicherheitsüberwachung und Compliance-Berichterstattung verwendet werden.
Mehrere Kafka-Nutzer verarbeiten Daten in mehrstufigen Verarbeitungspipelines. Rohe Eingabedaten werden aus Kafka-Topics entnommen, aggregiert, angereichert oder anderweitig in neue Topics umgewandelt, die dann weiterverwendet oder verarbeitet werden.
Eine Bank kann Kafka zum Beispiel nutzen, um Transaktionen in Echtzeit zu verarbeiten. Jede Transaktion, die ein Kunde startet, wird dann als Ereignis an ein Kafka-Thema gesendet. Anschließend kann eine Anwendung diese Ereignisse aufnehmen, die Transaktionen überprüfen und bearbeiten, zweifelhafte Transaktionen stoppen und den Kontostand der Kunden sofort aktualisieren.
Kafka könnte von einem Cloud-Service-Anbieter genutzt werden, um Statistiken von verteilten Anwendungen zu aggregieren und zentralisierte Echtzeit-Betriebsdatenströme zu erzeugen. Metriken von Hunderten von Servern, wie z.B. CPU- und Speicherverbrauch, Anzahl der Anfragen, Fehlerraten usw., können an Kafka gemeldet werden. Überwachungsanwendungen können diese Metriken dann zur Erkennung von Anomalien, zur Alarmierung und zur Echtzeit-Visualisierung nutzen.
Kafka ist ein Framework für die Stream-Verarbeitung, das es Anwendungen ermöglicht, große Mengen an Datensatzströmen schnell und zuverlässig zu veröffentlichen, zu konsumieren und zu verarbeiten. In Anbetracht der zunehmenden Verbreitung von Echtzeit-Datenstreaming ist es zu einem wichtigen Werkzeug für Entwickler von Datenanwendungen geworden.
In diesem Artikel haben wir uns mit den Gründen für den Einsatz von Kafka, den Kernkomponenten, den ersten Schritten, den erweiterten Funktionen und den realen Anwendungen beschäftigt. Wenn du dich weiterbilden willst, schau dir das an:
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Beginne deine Reise als Data Engineer noch heute!
Lernpfad
Kurs
Kurs
Blog
Zoumana Keita
15 Min.
Blog
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
