
Programma
Associate Data Engineer in Databricks
37 h
Apache Kafka è un framework open-source distribuito per l'event streaming, sviluppato in LinkedIn da un team che includeva Jay Kreps, Jun Rao e Neha Narkhede. Lo strumento è ottimizzato per acquisire ed elaborare dati in streaming in tempo reale; per questo può essere usato per implementare pipeline dati ad alte prestazioni, applicazioni di analytics in streaming e servizi di integrazione dati.
Dopo aver archiviato gli eventi, la piattaforma di streaming degli eventi li indirizza ai servizi pertinenti. Gli sviluppatori possono scalare e mantenere un sistema di questo tipo senza dipendere da altri servizi. Poiché Kafka è un pacchetto all-in-one che può fungere da message broker, event store o framework di stream processing, è perfetto per questo tipo di necessità.
Grazie all'elevata capacità e durabilità, centinaia di sorgenti dati possono fornire simultaneamente enormi flussi continui di dati che possono essere elaborati in modo sequenziale e progressivo dal sistema di message broker di Apache Kafka.
Kafka differisce da broker di messaggi tradizionali come RabbitMQ in diversi aspetti fondamentali:
| Funzionalità | Apache Kafka | Broker tradizionali (es. RabbitMQ) |
|---|---|---|
| Retention dei messaggi | Configurabile (da giorni ad anni); i messaggi persistono dopo il consumo | Messaggi eliminati dopo l'acknowledgment del consumer |
| Modello di consumo | Basato su pull; i consumer leggono al proprio ritmo | Basato su push; il broker consegna ai consumer |
| Throughput | Milioni di messaggi al secondo | Migliaia o decine di migliaia al secondo |
| Ordinamento | Garantito all'interno di una partition | Varia in base all'implementazione |
| Replay | I consumer possono rileggere i messaggi passati a qualsiasi offset | Non supportato dopo la consegna |
| Caso d'uso principale | Event streaming, log aggregation, pipeline in tempo reale | Code di task, pattern request-reply |
Vantaggi chiave di Apache Kafka:
L'architettura ben progettata di Kafka, che include data partitioning, batch processing, tecniche zero-copy e log append-only, gli consente di raggiungere un elevato throughput e gestire milioni di messaggi al secondo, adattandosi a scenari di dati ad alta velocità e alto volume. Il protocollo di comunicazione leggero che favorisce un'interazione efficace client-broker rende così possibile lo streaming di dati in tempo reale.
Apache Kafka fornisce il bilanciamento del carico tra server partizionando un topic in più partition. Questo permette di distribuire i cluster di produzione tra aree geografiche o availability zone e scalarli in su o in giù in base alle esigenze. In altre parole, Apache Kafka può essere facilmente scalato per gestire trilioni di messaggi al giorno su un gran numero di partition.
Apache Kafka utilizza un cluster di server con bassa latenza (fino a 2 millisecondi) per consegnare i messaggi in modo efficiente a un throughput limitato dalla rete, disaccoppiando i flussi di dati.
Apache Kafka migliora tolleranza ai guasti e durabilità dei dati in due modi chiave:
Grazie ai broker basati su cluster, Kafka rimane operativo durante un'interruzione di un server. Funziona perché quando uno dei server ha problemi, Kafka è abbastanza intelligente da inviare le richieste a broker diversi.
Apache Kafka permette di analizzare i dati in tempo reale, archiviare i record nell'ordine in cui sono stati creati e pubblicarli/sottoscriverli.
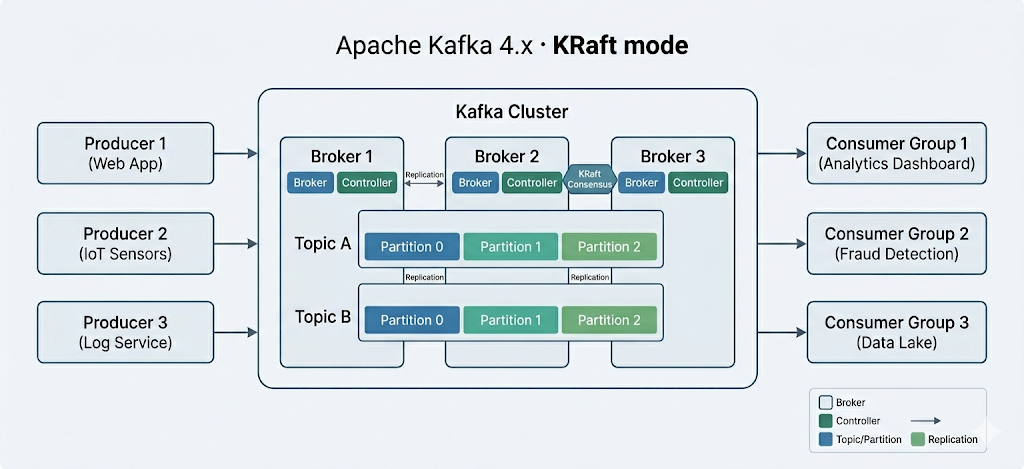
I componenti fondamentali di Apache Kafka
Apache Kafka è un cluster orizzontalmente scalabile di server commodity che elabora dati in tempo reale da più sistemi e applicazioni "producer" (ad es. logging, monitoring, sensori e applicazioni Internet of Things) e li rende disponibili a più sistemi e applicazioni "consumer" (ad es. analytics in tempo reale) con latenza molto bassa – come mostrato nello schema sopra.
Nota che applicazioni che dipendono dall'elaborazione dati in tempo reale e sistemi di analytics possono essere entrambe considerate consumer. Per esempio, un'applicazione per micromarketing o logistica basata sulla posizione.
Ecco alcuni termini chiave da conoscere per capire meglio i componenti fondamentali di Kafka:
Importante (aggiornamento 2025): Apache Kafka 4.0, rilasciato a marzo 2025, ha rimosso completamente ZooKeeper a favore della modalità KRaft (Kafka Raft). Le istruzioni di setup qui sotto usano ZooKeeper e si applicano solo a Kafka 3.x. Per Kafka 4.x, ZooKeeper non è più necessario né supportato. Se parti da zero, valuta di usare Docker con modalità KRaft per un setup più semplice.
Spesso si consiglia di avviare Apache Kafka 3.x con Zookeeper per la massima compatibilità. Inoltre, Kafka può incorrere in diversi problemi quando installato su Windows perché non è progettato nativamente per questo sistema operativo. Di conseguenza, si consiglia di avviare Apache Kafka su Windows usando WSL2 o Docker.
Non è consigliato usare la JVM per eseguire Kafka su Windows poiché manca di alcune caratteristiche POSIX tipiche di Linux. Prima o poi incontrerai difficoltà se provi a eseguire Kafka su Windows senza WSL2.
Detto ciò, il primo passo per installare Apache Kafka su Windows è installare WSL2.
WSL2, ovvero Windows Subsystem for Linux 2, dà al tuo PC Windows accesso a un ambiente Linux senza bisogno di una macchina virtuale.
La maggior parte dei comandi Linux è compatibile con WSL2, avvicinando il processo d'installazione di Kafka alle istruzioni fornite per Mac e Linux.
Consiglio: Assicurati di usare Windows 10 versione 2004 o superiore (Build 19041 e successive) prima di installare WSL2. Premi il tasto Windows + R, digita "winver", quindi fai clic su OK per vedere la versione di Windows.
Il modo più semplice per installare Windows Subsystem for Linux (WSL) è eseguire il seguente comando in un PowerShell o Prompt dei comandi con privilegi di amministratore e poi riavviare il computer:
wsl --installNota che ti verrà chiesto di creare un account utente e una password per la nuova distribuzione Linux installata.
Segui i passaggi sul sito Microsoft Docs se rimani bloccato.
Se Java non è installato sulla tua macchina, dovrai scaricare l'ultima versione.
Al momento di questo aggiornamento, l'ultima versione stabile di Apache Kafka è la 4.2.0, rilasciata a febbraio 2026. Kafka 4.0 (marzo 2025) ha sostituito ZooKeeper con la modalità KRaft per la gestione dei metadati. Per ottenere la versione stabile corrente, consulta la pagina dei download.
Scarica l'ultima versione dai Binary downloads.
Una volta completato il download, vai nella cartella in cui è stato scaricato Kafka ed estrai tutti i file dallo zip. Nota che abbiamo chiamato la nuova cartella "Kafka".
Zookeeper è richiesto per la gestione del cluster in Apache Kafka 3.x. Pertanto, Zookeeper deve essere avviato prima di Kafka. Non è necessario installare Zookeeper separatamente perché fa parte di Apache Kafka.
Apri il prompt dei comandi e vai alla directory root di Kafka. Da lì, esegui il seguente comando per avviare Zookeeper:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesApri un altro prompt dei comandi ed esegui il seguente comando dalla root di Apache Kafka per avviare Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesPer creare un topic, avvia un nuovo prompt dei comandi dalla directory root di Kafka ed esegui il seguente comando:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Questo creerà un nuovo topic Kafka chiamato "MyFirstTopic".
Nota: per confermare che sia stato creato correttamente, l'esecuzione del comando restituirà "Create topic <name of topic>."
Per inserire un messaggio nel topic Kafka, è necessario avviare un producer. Esegui il seguente comando:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Apri un altro prompt dei comandi dalla directory root di Kafka ed esegui il seguente comando per avviare il consumer Kafka:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Ora, quando un messaggio viene prodotto dal Producer, viene letto dal Consumer in tempo reale.
Una GIF mostra un messaggio prodotto dal Producer e letto dal Kafka Consumer in tempo reale.
Hai appena creato il tuo primo topic Kafka e inviato un messaggio dal producer al consumer in tempo reale.
Kafka offre diverse funzionalità avanzate oltre al semplice passaggio di messaggi.
Con Apache Kafka, gli sviluppatori possono creare applicazioni di stream processing tolleranti ai guasti con Kafka Streams. Offre API e un Domain-Specific Language (DSL) ad alto livello per gestire, trasformare e valutare flussi continui di dati.
Alcune funzionalità chiave includono:
Kafka Streams rende possibile l'elaborazione in tempo reale di flussi di record. Ti permette di acquisire dati dai topic Kafka, elaborare e trasformare i dati, quindi restituire le informazioni elaborate ai topic Kafka. Lo stream processing consente analytics quasi in tempo reale, monitoraggio e arricchimento dei dati. Può essere applicato a singoli record o ad aggregazioni con window.
Usando i timestamp associati ai record, puoi gestire record fuori ordine grazie al supporto di Kafka Streams per l'event-time processing. Fornisce operazioni di window con semantica event-time, consentendo window join, sessionizzazione e aggregazioni basate sul tempo.
Kafka Streams offre diverse operazioni di windowing che permettono di effettuare calcoli su session window, tumbling window, sliding window e window a tempo fisso.
Trigger basati su eventi, analisi time-sensitive e aggregazioni basate sul tempo sono possibili tramite procedure con window.
Durante lo stream processing, Kafka Streams ti permette di mantenere e aggiornare lo stato. È fornito il supporto integrato per i state store. Nota: un state store è un archivio key-value che può essere aggiornato e interrogato all'interno di una topologia di elaborazione.
Operazioni stateful come join, aggregazioni e rilevamento di anomalie abilitano funzionalità avanzate di stream processing.
Kafka Streams fornisce semantiche end-to-end per l'elaborazione exactly-once, garantendo che ogni record venga elaborato esattamente una volta, anche in caso di guasto. Ciò è ottenuto sfruttando le garanzie di durabilità integrate di Kafka e le funzionalità transazionali.
Il framework dichiarativo e plug-in per l'integrazione dati in Kafka si chiama Kafka Connect. È un componente open-source e gratuito di Apache Kafka che funge da hub dati centralizzato per un'integrazione semplice tra file system, database, indici di ricerca e key-value store.
La distribuzione Kafka include Kafka Connect di default. Per installarlo, devi solo avviare un processo worker.
Usa il seguente comando dalla directory root di Kafka per avviare il processo worker di Kafka Connect:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesQuesto avvierà il worker di Kafka Connect in modalità distributed, abilitando alta disponibilità e scalabilità con l'esecuzione di numerosi worker in un cluster.
Nota: Il file .\config\connect-distributed.properties specifica le informazioni sul broker Kafka e altre proprietà di configurazione per Kafka Connect.
Kafka Connect usa dei connector per trasferire dati tra sistemi esterni e topic Kafka. I connector possono essere installati e configurati per soddisfare le tue esigenze specifiche di integrazione dati.
Per installare un connector è sufficiente scaricare e aggiungere il file JAR del connector alla directory plugin.path indicata nel file .\config\connect-distributed.properties.
È necessario creare un file di configurazione per il connector, in cui specificare la classe del connector e le altre caratteristiche. L'API REST di Kafka Connect e gli strumenti da riga di comando possono essere usati per creare e gestire i connector.
Quindi, per combinare dati da altri sistemi, devi configurare il Kafka Connector. Kafka Connect offre vari connector per integrare dati da diversi sistemi, come file system, code di messaggi e database. Seleziona un connector in base alle tue esigenze di integrazione - vedi la documentazione per l'elenco dei connector.
Ecco alcuni casi d'uso comuni di Apache Kafka.
Un e-commerce online può usare Kafka per tracciare l'attività degli utenti in tempo reale. Ogni azione dell'utente, inclusa la visualizzazione di prodotti, l'aggiunta di articoli al carrello, gli acquisti, le recensioni, le ricerche e così via, può essere pubblicata come evento su specifici topic Kafka.
Altri microservizi possono archiviare o usare questi eventi per rilevamento frodi in tempo reale, reporting, offerte personalizzate e raccomandazioni.
Con il suo throughput migliorato, il partitioning integrato, la replica, la tolleranza ai guasti e la scalabilità, Kafka è un valido sostituto dei broker di messaggi convenzionali.
Un'app per ride-hailing basata su microservizi può usarlo per facilitare lo scambio di messaggi tra vari servizi.
Per esempio, l'azienda di ride-booking potrebbe usare Kafka per comunicare con il servizio di driver-matching quando un passeggero effettua una prenotazione. Il servizio di driver-matching può quindi, in quasi tempo reale, trovare un autista in zona e rispondere con un messaggio.
Tipicamente, questo comporta l'acquisizione di file di log fisici dai server e la loro archiviazione in una posizione centrale per l'elaborazione, come un file server o un data lake. Kafka astrae i dati come un flusso di messaggi e filtra le informazioni specifiche del file. Questo rende possibile l'elaborazione dei dati con latenza ridotta e facilita il consumo distribuito e le diverse sorgenti di dati.
Dopo che i log vengono pubblicati su Kafka, possono essere usati per il troubleshooting, il monitoraggio della sicurezza e il reporting di compliance da uno strumento di analisi dei log o da un sistema SIEM (Security Information and Event Management).
Diversi utenti Kafka elaborano i dati in pipeline di elaborazione a più stadi. I dati grezzi in input vengono prelevati dai topic Kafka, aggregati, arricchiti o altrimenti trasformati in nuovi topic per ulteriore consumo o elaborazione.
Per esempio, una banca può usare Kafka per elaborare transazioni in tempo reale. Ogni transazione avviata da un cliente viene quindi pubblicata come evento su un topic Kafka. Successivamente, un'applicazione può acquisire questi eventi, verificare e gestire le transazioni, bloccare quelle sospette e aggiornare istantaneamente i saldi dei clienti.
Un provider di servizi cloud potrebbe usare Kafka per aggregare statistiche da applicazioni distribuite e generare flussi centralizzati in tempo reale di dati operativi. Metriche da centinaia di server, come consumo di CPU e memoria, numero di richieste, tassi di errore, ecc., potrebbero essere riportate a Kafka. Le applicazioni di monitoraggio potrebbero quindi usare queste metriche per identificare anomalie, inviare allerte e visualizzare in tempo reale.
Apache Kafka è lo standard del settore per l'event streaming in tempo reale, usato da oltre l'80% delle aziende Fortune 100. Con Kafka 4.0 e la modalità KRaft, distribuire e gestire i cluster è più semplice rispetto alle versioni precedenti.
In questo articolo, ho trattato perché Kafka è importante, i suoi componenti fondamentali, un setup passo dopo passo, funzionalità avanzate come Kafka Streams e Kafka Connect, e applicazioni reali. Per continuare ad imparare, dai un'occhiata a:
Inizia oggi il tuo percorso da Data Engineer!
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

