
Cursus
Ingénieur de données en Python
40 h
Après avoir stocké les événements, la plateforme de streaming d' événements les dirige vers les services concernés. Les développeurs peuvent faire évoluer et maintenir un tel système sans dépendre d'autres services. Étant donné que Kafka est un logiciel tout-en-un qui peut être utilisé comme courtier de messages, magasin d'événements ou cadre de traitement de flux, il répond parfaitement à ce type d'exigence.
Avec un débit et une durabilité élevés, des centaines de sources de données peuvent fournir simultanément d'énormes flux de données continus qui peuvent être traités de manière séquentielle et progressive par le système de courtier en messages d'Apache Kafka.
De plus, les avantages d'Apache Kafka sont les suivants :
L'architecture bien conçue de Kafka, qui comprend le partitionnement des données, le traitement par lots, les techniques de copie zéro et les journaux de type append-only, lui permet d'atteindre un débit élevé et de gérer des millions de messages par seconde, ce qui répond aux scénarios de données à grande vitesse et à grand volume. Ainsi, le protocole de communication léger qui facilite l'interaction efficace entre le client et le courtier rend possible la diffusion de données en temps réel.
Apache Kafka permet d'équilibrer la charge entre les serveurs en divisant un sujet en plusieurs partitions. Cela permet aux utilisateurs de répartir les grappes de production entre les zones géographiques ou les zones de disponibilité et de les augmenter ou de les réduire en fonction de leurs besoins. En d'autres termes, Apache Kafka peut être facilement mis à l'échelle pour gérer des billions de messages par jour à travers un grand nombre de partitions.
Apache Kafka utilise une grappe de serveurs à faible latence (aussi peu que 2 millisecondes) pour transmettre efficacement des messages à un débit limité par le réseau en découplant les flux de données.
Apache Kafka améliore la tolérance aux pannes et la durabilité des données de deux manières principales :
Grâce à ses brokers basés sur des clusters, Kafka reste opérationnel lors d'une panne de serveur. Cela fonctionne parce que lorsque l'un des serveurs rencontre des problèmes, Kafka est suffisamment intelligent pour envoyer des requêtes à différents courtiers.
Apache Kafka permet aux utilisateurs d'analyser les données en temps réel, de stocker les enregistrements dans l'ordre où ils ont été créés, de les publier et de s'y abonner.
Les principaux composants d'Apache Kafka | Source : Démarrez votre pipeline temps réel avec Apache Kafka par Alex Kam
Apache Kafka est une grappe de serveurs de commodités évolutive horizontalement qui traite des données en temps réel provenant de plusieurs systèmes et applications "producteurs" (par exemple, des applications de journalisation, de surveillance, de capteurs et de l'internet des objets) et les met à la disposition de plusieurs systèmes et applications "consommateurs" (par exemple, des applications d'analyse en temps réel) avec un temps de latence très faible, comme le montre le diagramme ci-dessus.
Notez que les applications qui dépendent du traitement des données en temps réel et des systèmes d'analyse peuvent toutes deux être considérées comme des consommateurs. Par exemple, une application de micromarketing ou de logistique basée sur la localisation.
Voici quelques termes clés à connaître pour mieux comprendre les principaux composants de Kafka :
Il est souvent recommandé de démarrer Apache Kafka avec Zookeeper pour une compatibilité optimale. Par ailleurs, Kafka peut rencontrer plusieurs problèmes lorsqu'il est installé sous Windows, car il n'est pas conçu à l'origine pour être utilisé avec ce système d'exploitation. Par conséquent, il est conseillé d'utiliser ce qui suit pour lancer Apache Kafka sur Windows :
Il n'est pas conseillé d'utiliser la JVM pour exécuter Kafka sous Windows, car elle ne possède pas certaines des caractéristiques POSIX propres à Linux. Vous rencontrerez éventuellement des difficultés si vous essayez d'exécuter Kafka sur Windows sans WSL2.
Cela dit, la première étape de l'installation d'Apache Kafka sous Windows consiste à installer WSL2.
WSL2, ou Windows Subsystem for Linux 2, permet à votre PC Windows d'accéder à un environnement Linux sans avoir besoin d'une machine virtuelle.
La plupart des commandes Linux sont compatibles avec WSL2, ce qui rapproche le processus d'installation de Kafka des instructions proposées pour Mac et Linux.
Conseil : Assurez-vous que vous utilisez Windows 10 version 2004 ou supérieure (Build 19041 et plus) avant d'installer WSL2. Appuyez sur la touche du logo Windows + R, tapez "winver", puis cliquez sur OK pour connaître votre version de Windows.
La manière la plus simple d'installer Windows Subsystem for Linux (WSL) est d'exécuter la commande suivante dans un PowerShell administrateur ou une invite de commande Windows, puis de redémarrer votre ordinateur :
wsl --installNotez que vous serez invité à créer un compte d'utilisateur et un mot de passe pour votre distribution Linux nouvellement installée.
Suivez les étapes du site web Microsoft Docs si vous êtes bloqué.
Si Java n'est pas installé sur votre machine, vous devez télécharger la dernière version.
Étape 3 : Installer Apache Kafka
Au moment de la rédaction de cet article, la dernière version stable d'Apache Kafka est la 3.7.0, publiée le 27 février 2024. Cela peut changer à tout moment. Pour vous assurer que vous utilisez la version la plus récente et la plus stable de Kafka, consultez la page de téléchargement.
Téléchargez la dernière version à partir des téléchargements binaires.
Une fois le téléchargement terminé, accédez au dossier dans lequel Kafka a été téléchargé et extrayez tous les fichiers du dossier zippé. Notez que nous avons nommé notre nouveau dossier "Kafka".
Zookeeper est nécessaire pour la gestion des clusters dans Apache Kafka. Par conséquent, Zookeeper doit être lancé avant Kafka. Il n'est pas nécessaire d'installer Zookeeper séparément car il fait partie d'Apache Kafka.
Ouvrez l'invite de commande et naviguez jusqu'au répertoire racine de Kafka. Une fois sur place, exécutez la commande suivante pour démarrer Zookeeper :
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesOuvrez une autre invite de commande et exécutez la commande suivante à partir de la racine d'Apache Kafka pour démarrer Apache Kafka :
.\bin\windows\kafka-server-start.bat .\config\server.propertiesPour créer un sujet, démarrez une nouvelle invite de commande à partir du répertoire racine de Kafka et exécutez la commande suivante :
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Cela créera un nouveau sujet Kafka appelé "MyFirstTopic".
Note : pour confirmer qu'il a été créé correctement, l'exécution de la commande renverra le message suivant : "Create topic <name of topic>" (Créer le sujet <nom du sujet>).
Un producteur doit être démarré pour placer un message dans le sujet Kafka. Pour ce faire, exécutez la commande suivante :
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Ouvrez une autre invite de commande à partir du répertoire racine de Kafka et exécutez la commande suivante pour envoyer à stat le consommateur Kafka :
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Désormais, lorsqu'un message est produit par le producteur, il est lu par le consommateur en temps réel.
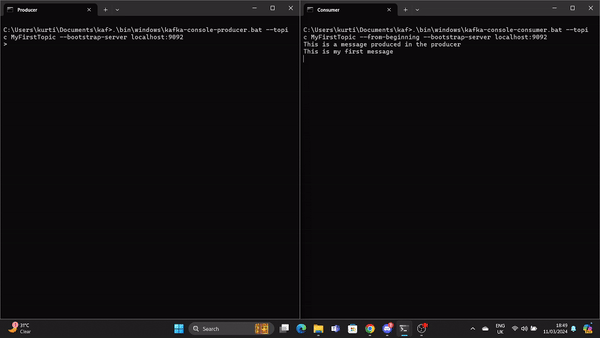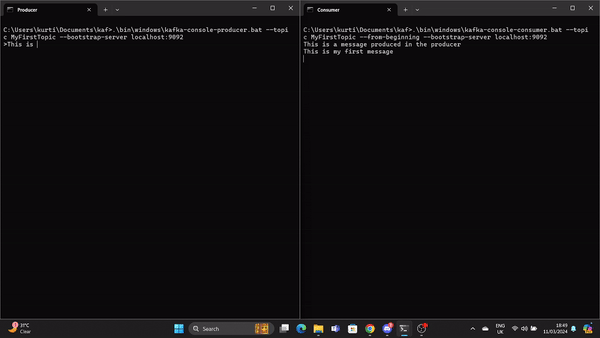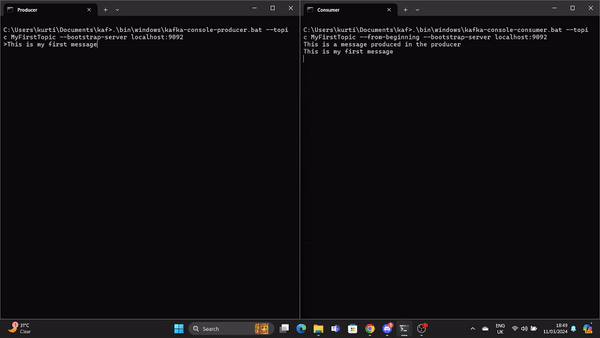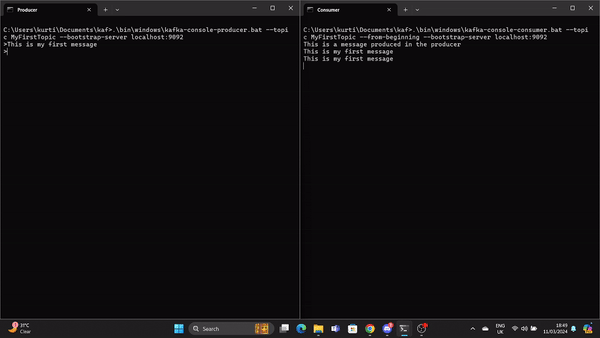
Un GIF montre un message produit par le producteur et lu par le consommateur Kafka en temps réel.
Et voilà... Vous venez de créer votre premier sujet Kafka.
Voici quelques fonctionnalités avancées de Kafka...
En utilisant Apache Kafka, les développeurs peuvent créer des applications robustes de traitement de flux à l'aide de Kafka Streams. Il propose des API et un langage de haut niveau spécifique au domaine (DSL) pour la manipulation, la conversion et l'évaluation de flux continus de données.
Parmi les principales caractéristiques, citons
Le traitement en temps réel des flux d'enregistrements est rendu possible par Kafka Streams. Il vous permet de recevoir des données des sujets Kafka, de les traiter et de les transformer, puis de renvoyer les informations traitées vers les sujets Kafka. Le traitement en continu permet des analyses, un contrôle et un enrichissement des données en temps quasi réel. Elle peut être appliquée à des enregistrements individuels ou à des agrégations fenêtrées.
En utilisant les horodatages attachés aux enregistrements, vous pouvez traiter les enregistrements hors ordre grâce à la prise en charge par Kafka Streams du traitement des événements. Il fournit des opérations de fenêtrage à la sémantique événementielle, permettant la jonction de fenêtres, la sessionnalisation et les agrégations basées sur le temps.
Kafka Streams propose un certain nombre d'opérations de fenêtrage qui permettent aux utilisateurs d'effectuer des calculs sur des fenêtres de session, des fenêtres mobiles, des fenêtres coulissantes et des fenêtres temporelles fixes.
Les procédures fenêtrées permettent de déclencher des événements, d'effectuer des analyses sensibles au temps et des agrégations temporelles.
Pendant le traitement des flux, Kafka Streams permet aux utilisateurs de conserver et de mettre à jour l'état. Une prise en charge intégrée des magasins d'État est prévue. Notez qu'une mémoire d'état est une mémoire clé-valeur qui peut être mise à jour et interrogée au sein d'une topologie de traitement.
Les fonctions avancées de traitement des flux, telles que les jointures, les agrégations et la détection des anomalies, sont rendues possibles par les opérations avec état.
Kafka Streams fournit une sémantique de bout en bout pour le traitement "exactly-once", garantissant que chaque enregistrement est traité précisément une fois, même en cas de défaillance. Pour ce faire, vous pouvez utiliser les solides garanties de durabilité et les fonctions transactionnelles de Kafka.
Le cadre d'intégration de données déclaratif et enfichable pour Kafka s'appelle Kafka Connect. Il s'agit d'un composant libre et gratuit d'Apache Kafka qui agit comme un hub de données centralisé pour une intégration simple des données entre les systèmes de fichiers, les bases de données, les index de recherche et les magasins de valeurs clés.
La distribution Kafka inclut Kafka Connect par défaut. Pour l'installer, il vous suffit de lancer un processus de travailleur.
Utilisez la commande suivante à partir du répertoire racine de Kafka pour lancer le processus de travailleur Kafka Connect :
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesCela lancera le travailleur Kafka Connect en mode distribué, permettant la haute disponibilité et l'évolutivité de l'exécution de nombreux travailleurs dans un cluster.
Note : Le fichier .\config\connect-distributed.properties spécifie les informations du courtier Kafka et d'autres propriétés de configuration pour Kafka Connect.
Les connecteurs sont utilisés par Kafka Connect pour transférer des données entre des systèmes externes et des sujets Kafka. Les connecteurs peuvent être installés et configurés pour répondre à vos besoins spécifiques en matière d'intégration de données.
Pour installer un connecteur, il suffit de télécharger le fichier JAR du connecteur et de l'ajouter au répertoire plugin.path mentionné dans le fichier .\config\connect-distributed.properties.
Un fichier de configuration du connecteur doit être créé, dans lequel la classe du connecteur et d'éventuelles autres caractéristiques doivent être spécifiées. L'API REST Kafka Connect et les outils de ligne de commande peuvent être utilisés pour construire et maintenir les connecteurs.
Ensuite, pour combiner des données provenant d'autres systèmes, vous devez configurer le connecteur Kafka. Kafka Connect propose plusieurs connecteurs pour intégrer des données provenant de différents systèmes, tels que les systèmes de fichiers, les files d'attente de messages et les bases de données. Sélectionnez un connecteur en fonction de vos besoins d'intégration - voir la documentation pour la liste des connecteurs.
Voici quelques cas d'utilisation courants d'Apache Kafka.
Kafka peut être utilisé par une plateforme de commerce en ligne pour suivre l'activité des utilisateurs en temps réel. Chaque action de l'utilisateur, y compris la consultation de produits, l'ajout d'articles au panier, les achats, les commentaires, les recherches, etc., peut être publiée en tant qu'événement dans des thèmes Kafka particuliers.
D'autres microservices peuvent stocker ou utiliser ces événements pour la détection des fraudes en temps réel, les rapports, les offres personnalisées et les recommandations.
Grâce à son débit amélioré, au partitionnement intégré, à la réplication, à la tolérance aux pannes et aux capacités de mise à l'échelle, Kafka est un bon substitut aux courtiers en messages conventionnels.
Une application de covoiturage basée sur des microservices peut l'utiliser pour faciliter les échanges de messages entre différents services.
Par exemple, l'entreprise de réservation de trajets peut utiliser Kafka pour communiquer avec le service de mise en relation avec les chauffeurs lorsqu'un usager effectue une réservation. Le service de mise en relation peut alors, presque en temps réel, localiser un chauffeur dans la région et lui répondre par un message.
En règle générale, il s'agit d'obtenir des fichiers journaux physiques à partir des serveurs et de les stocker dans un emplacement central pour traitement, tel qu'un serveur de fichiers ou un lac de données. Kafka présente les données sous la forme d'un flux de messages et filtre les informations spécifiques au fichier. Cela permet de traiter les données avec un temps de latence réduit et de s'adapter plus facilement à la consommation de données distribuées et à différentes sources de données.
Une fois les journaux publiés dans Kafka, ils peuvent être utilisés pour le dépannage, la surveillance de la sécurité et les rapports de conformité par un outil d'analyse des journaux ou un système de gestion des informations et des événements de sécurité (SIEM).
Plusieurs utilisateurs de Kafka traitent les données dans des pipelines de traitement en plusieurs étapes. Les données brutes sont extraites des sujets Kafka, agrégées, enrichies ou transformées en de nouveaux sujets pour une consommation ou un traitement supplémentaires.
Par exemple, une banque peut utiliser Kafka pour traiter des transactions en temps réel. Chaque transaction lancée par un client est ensuite publiée dans un sujet Kafka en tant qu'événement. Par la suite, une application peut prendre en compte ces événements, vérifier et traiter les transactions, arrêter celles qui sont douteuses et mettre instantanément à jour les soldes des clients.
Kafka pourrait être utilisé par un fournisseur de services cloud pour agréger des statistiques provenant d'applications distribuées afin de générer des flux centralisés de données opérationnelles en temps réel. Des mesures provenant de centaines de serveurs, telles que la consommation de CPU et de mémoire, le nombre de requêtes, les taux d'erreur, etc. peuvent être communiquées à Kafka. Les applications de surveillance peuvent ensuite utiliser ces mesures pour identifier les anomalies, lancer des alertes et visualiser les données en temps réel.
Kafka est un cadre de traitement des flux qui permet aux applications de publier, de consommer et de traiter de grandes quantités de flux d'enregistrements de manière rapide et fiable. Compte tenu de la prévalence croissante du flux de données en temps réel, il est devenu un outil essentiel pour les développeurs d'applications de données.
Dans cet article, nous avons abordé les raisons pour lesquelles on peut décider d'utiliser Kafka, les composants de base, la manière de commencer à l'utiliser, les fonctionnalités avancées et les applications du monde réel. Pour poursuivre votre apprentissage, consultez le site :
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Commencez dès aujourd'hui votre parcours de Data Engineer !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
Tutoriel
Matt Crabtree
Tutoriel
Mark Pedigo
Tutoriel
Tutoriel
Adel Nehme
