
Leerpad
Associate Data Engineer in Databricks
37 Hr
Apache Kafka is een open-source, gedistribueerd event-streamingframework, ontwikkeld bij LinkedIn door een team met onder andere Jay Kreps, Jun Rao en Neha Narkhede. De tool is geoptimaliseerd voor het inladen en verwerken van streamingdata in realtime; je kunt hem dus gebruiken om high-performance datapijplijnen, streaming analytics-applicaties en dataintegratieservices te implementeren.
Na het opslaan van events stuurt het event-streamingplatform ze door naar de relevante services. Ontwikkelaars kunnen zo'n systeem schalen en onderhouden zonder afhankelijk te zijn van andere services. Omdat Kafka een alles-in-één pakket is dat kan worden gebruikt als message broker, event store of stream processing-framework, werkt het uitstekend voor zo'n vereiste.
Met hoge throughput en duurzaamheid kunnen honderden databronnen gelijktijdig enorme instromen van continue datastromen leveren die sequentieel en progressief kunnen worden verwerkt door het message-brokersysteem van Apache Kafka.
Kafka verschilt op een aantal fundamentele punten van traditionele message brokers zoals RabbitMQ:
| Feature | Apache Kafka | Traditionele brokers (bijv. RabbitMQ) |
|---|---|---|
| Berichtretentie | Configureerbaar (dagen tot jaren); berichten blijven bestaan na consumptie | Berichten worden verwijderd na bevestiging door de consumer |
| Consumermodel | Pull-based; consumers lezen in eigen tempo | Push-based; broker levert aan consumers |
| Throughput | Miljoenen berichten per seconde | Duizenden tot tienduizenden per seconde |
| Volgorde | Gegarandeerd binnen een partitie | Verschilt per implementatie |
| Replay | Consumers kunnen eerdere berichten op elk offset opnieuw lezen | Niet ondersteund na levering |
| Primaire use-case | Event streaming, logaggregatie, realtime pijplijnen | Taakwachtrijen, request-reply-patronen |
Belangrijke voordelen van Apache Kafka zijn onder andere:
Kafka’s doordachte architectuur, met onder meer datapartitionering, batchverwerking, zero-copy-technieken en append-only logs, maakt hoge throughput mogelijk en het verwerken van miljoenen berichten per seconde in scenario’s met hoge snelheid en groot volume. De lichtgewicht communicatieprotocol die effectieve client-brokerinteractie faciliteert, maakt realtime datastreaming haalbaar.
Apache Kafka verzorgt load balancing over servers door een topic in meerdere partities op te splitsen. Dit stelt gebruikers in staat om productieclusters over geografische gebieden of availability zones te verdelen en ze op of af te schalen naar behoefte. Met andere woorden: Apache Kafka kan eenvoudig worden opgeschaald om triljoenen berichten per dag te verwerken over een groot aantal partities.
Apache Kafka gebruikt een cluster van servers met lage latentie (tot wel 2 milliseconden) om berichten efficiënt te leveren met door het netwerk begrensde throughput door datastromen los te koppelen.
Apache Kafka verhoogt de fouttolerantie en duurzaamheid van data op twee belangrijke manieren:
Dankzij zijn clustergebaseerde brokers blijft Kafka operationeel tijdens een serverstoring. Dit werkt omdat Kafka, wanneer een van de servers problemen ondervindt, slim genoeg is om queries naar andere brokers te sturen.
Apache Kafka stelt gebruikers in staat om data in realtime te analyseren, records op te slaan in de volgorde waarin ze zijn gemaakt, en ze te publiceren en erop te abonneren.
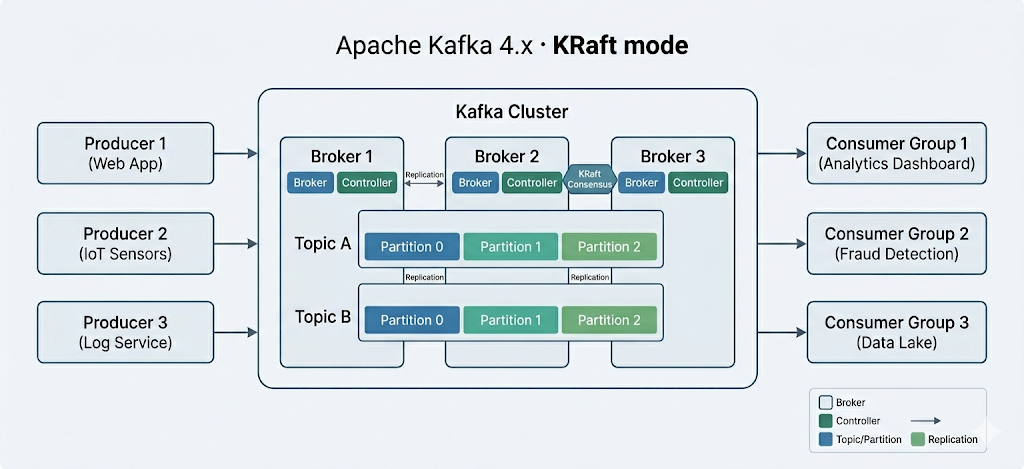
De kerncomponenten van Apache Kafka
Apache Kafka is een horizontaal schaalbaar cluster van commodity-servers dat realtime data verwerkt van meerdere "producer"-systemen en -applicaties (bijv. logging, monitoring, sensoren en Internet of Things-apps) en die met zeer lage latentie beschikbaar maakt voor meerdere "consumer"-systemen en -applicaties (bijv. realtime analytics) – zoals te zien in het diagram hierboven.
Let op: applicaties die afhankelijk zijn van realtime dataverwerking en analysetoepassingen kunnen beide als consumers worden beschouwd. Bijvoorbeeld een applicatie voor locatiegebonden micromarketing of logistiek.
Hier zijn enkele sleuteltermen die helpen om de kerncomponenten van Kafka beter te begrijpen:
Belangrijk (update 2025): Apache Kafka 4.0, uitgebracht in maart 2025, heeft ZooKeeper volledig vervangen door KRaft (Kafka Raft)-modus. De onderstaande installatie-instructies gebruiken ZooKeeper en zijn alleen van toepassing op Kafka 3.x. Voor Kafka 4.x is ZooKeeper niet meer nodig of ondersteund. Als je nieuw begint, overweeg dan Docker met KRaft-modus voor een eenvoudigere setup.
Het wordt vaak aangeraden om Apache Kafka 3.x met Zookeeper te starten voor optimale compatibiliteit. Ook kan Kafka op Windows tegen verschillende problemen aanlopen omdat het niet native is ontworpen voor dit besturingssysteem. Daarom is het aan te raden om Apache Kafka op Windows te starten met WSL2 of Docker.
Het is niet aan te raden om de JVM te gebruiken om Kafka op Windows te draaien, omdat het niet beschikt over enkele POSIX-eigenschappen die uniek zijn voor Linux. Je zult uiteindelijk problemen tegenkomen als je probeert Kafka op Windows te draaien zonder WSL2.
Dat gezegd hebbende, de eerste stap om Apache Kafka op Windows te installeren is het installeren van WSL2.
WSL2, of Windows Subsystem for Linux 2, geeft je Windows-pc toegang tot een Linux-omgeving zonder dat je een virtuele machine nodig hebt.
De meeste Linux-commando’s zijn compatibel met WSL2, waardoor het Kafka-installatieproces dichter bij de instructies voor Mac en Linux ligt.
Tip: Zorg dat je Windows 10 versie 2004 of hoger (Build 19041 en hoger) draait voordat je WSL2 installeert. Druk op de Windows-logotoets + R, typ "winver" en klik op OK om je Windows-versie te zien.
De eenvoudigste manier om Windows Subsystem for Linux (WSL) te installeren is door de volgende opdracht uit te voeren in een Administrator PowerShell of Windows Command Prompt en daarna je computer te herstarten:
wsl --installLet op: je wordt gevraagd om een gebruikersaccount en wachtwoord aan te maken voor je nieuw geïnstalleerde Linux-distributie.
Volg de stappen op de website van Microsoft Docs als je vastloopt.
Als Java niet op je machine is geïnstalleerd, moet je de laatste versie downloaden.
Op het moment van deze update is de nieuwste stabiele versie van Apache Kafka 4.2.0, uitgebracht in februari 2026. Kafka 4.0 (maart 2025) verving ZooKeeper door KRaft-modus voor metadatabeheer. Ga naar de downloadpagina voor de huidige stabiele versie.
Download de nieuwste versie bij de Binary downloads.
Zodra de download is voltooid, navigeer je naar de map waar Kafka is gedownload en pak je alle bestanden uit de gecomprimeerde map. Let op: wij hebben onze nieuwe map "Kafka" genoemd.
Zookeeper is vereist voor clustermanagement in Apache Kafka 3.x. Daarom moet Zookeeper worden gestart vóór Kafka. Het is niet nodig om Zookeeper apart te installeren, omdat het onderdeel is van Apache Kafka.
Open de opdrachtprompt en navigeer naar de root van de Kafka-directory. Voer daar de volgende opdracht uit om Zookeeper te starten:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesOpen een andere opdrachtprompt en voer de volgende opdracht uit vanaf de root van Apache Kafka om Apache Kafka te starten:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesOm een topic te maken, start je een nieuwe opdrachtprompt vanuit de root van de Kafka-directory en voer je de volgende opdracht uit:
.\bin\windows\kafka-topics.bat --create --topic MyFirstTopic --bootstrap-server localhost:9092Dit maakt een nieuw Kafka-topic met de naam "MyFirstTopic".
Let op: om te bevestigen dat het correct is aangemaakt, zal het uitvoeren van de opdracht "Create topic <name of topic>" teruggeven.
Er moet een producer worden gestart om een bericht in het Kafka-topic te plaatsen. Voer de volgende opdracht uit om dit te doen:
.\bin\windows\kafka-console-producer.bat --topic MyFirstTopic --bootstrap-server localhost:9092Open een andere opdrachtprompt vanuit de root van de Kafka-directory en voer de volgende opdracht uit om de Kafka-consumer te starten:
.\bin\windows\kafka-console-consumer.bat --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Wanneer er nu een bericht door de Producer wordt geproduceerd, wordt het in realtime door de Consumer gelezen.
Een GIF toont een bericht dat door de Producer is geproduceerd en in realtime is gelezen door de Kafka Consumer.
Je hebt zojuist je eerste Kafka-topic gemaakt en een bericht van producer naar consumer gestuurd in realtime.
Kafka biedt verschillende geavanceerde features naast het basis doorgeven van berichten.
Met Apache Kafka kunnen ontwikkelaars fault-tolerant streamverwerkingsapplicaties bouwen met Kafka Streams. Het biedt API’s en een high-level Domain-Specific Language (DSL) voor het verwerken, transformeren en evalueren van continue datastromen.
Enkele belangrijke features zijn:
Kafka Streams maakt realtime verwerking van recordstreams mogelijk. Het stelt je in staat om data uit Kafka-topics in te nemen, de data te verwerken en te transformeren, en de verwerkte informatie vervolgens terug te publiceren naar Kafka-topics. Streamverwerking maakt near-realtime analytics, monitoring en verrijking van data mogelijk. Het kan worden toegepast op individuele records of op geaggregeerde vensters.
Met behulp van de tijdstempels die aan records zijn gekoppeld, kun je out-of-order records afhandelen dankzij de ondersteuning van Kafka Streams voor event-time processing. Het biedt windowing-bewerkingen met event-time-semantiek, waardoor window joins, sessionization en tijdgebaseerde aggregaties mogelijk zijn.
Kafka Streams biedt een aantal windowing-bewerkingen waarmee gebruikers berekeningen kunnen uitvoeren over sessievensters, tumbling windows, sliding windows en vaste tijdvensters.
Eventgestuurde triggers, tijdgevoelige analyses en tijdgebaseerde aggregaties zijn mogelijk via windowed procedures.
Tijdens streamverwerking stelt Kafka Streams gebruikers in staat om state bij te houden en bij te werken. Er is ingebouwde ondersteuning voor state stores. Let op: een state store is een key-value store die binnen een verwerkingstopologie kan worden bijgewerkt en bevraagd.
Geavanceerde streamverwerkingsfuncties zoals joins, aggregaties en anomaliedetectie worden mogelijk gemaakt door stateful-operaties.
Kafka Streams biedt end-to-end semantiek voor exactly-once processing, wat garandeert dat elk record precies één keer wordt verwerkt—zelfs bij een storing. Dit wordt bereikt door gebruik te maken van Kafka’s ingebouwde duurzaamheidsgaranties en transactionele features.
Het declaratieve, plugbare dataintegratiekader voor Kafka heet Kafka Connect. Het is een open-source, gratis component van Apache Kafka dat fungeert als een gecentraliseerde datahub voor eenvoudige integratie tussen bestandssystemen, databases, zoekindexen en key-value stores.
Kafka Connect is standaard opgenomen in de Kafka-distributie. Om het te installeren hoef je alleen een workerproces te starten.
Gebruik de volgende opdracht vanuit de root van de Kafka-directory om het Kafka Connect-workerproces te starten:
.\bin\windows\connect-distributed.bat
.\config\connect-distributed.propertiesDit start de Kafka Connect-worker in distributed mode, waardoor hoge beschikbaarheid en schaalbaarheid mogelijk is door meerdere workers in een cluster te draaien.
Let op: het bestand .\config\connect-distributed.properties specificeert de informatie over de Kafka-broker en andere configuratie-eigenschappen voor Kafka Connect.
Connectors worden door Kafka Connect gebruikt om data tussen externe systemen en Kafka-topics over te brengen. Connectors kunnen worden geïnstalleerd en geconfigureerd om te voldoen aan jouw specifieke vereisten voor dataintegratie.
Een connector installeren is niet meer dan de connector-JAR downloaden en toevoegen aan de plugin.path-directory zoals vermeld in het bestand .\config\connect-distributed.properties.
Er moet een configuratiebestand voor de connector worden gemaakt, waarin de connectorclass en eventuele andere eigenschappen worden gespecificeerd. De Kafka Connect REST API en commandlinetools kunnen worden gebruikt om connectors te maken en te beheren.
Vervolgens moet je, om data uit andere systemen te combineren, de Kafka Connector configureren. Kafka Connect biedt diverse connectors voor het integreren van data uit verschillende systemen, zoals bestandssystemen, message queues en databases. Kies een connector op basis van jouw integratiebehoeften – zie de documentatie voor de lijst met connectors.
Hier zijn een paar veelvoorkomende use-cases van Apache Kafka.
Een online e-commerceplatform kan Kafka gebruiken om gebruikersactiviteit in realtime te volgen. Elke gebruikersactie, zoals het bekijken van producten, artikelen toevoegen aan winkelwagens, aankopen doen, reviews achterlaten, zoeken, enzovoort, kan als event worden gepubliceerd naar specifieke Kafka-topics.
Andere microservices kunnen deze events opslaan of gebruiken voor realtime fraudedetectie, rapportage, gepersonaliseerde aanbiedingen en aanbevelingen.
Met zijn verbeterde throughput en ingebouwde partitionering, replicatie, fouttolerantie en schaalbaarheid is Kafka een goed alternatief voor conventionele message brokers.
Een microservices-gebaseerde app voor ritten kan het gebruiken om berichtenuitwisseling tussen verschillende services te faciliteren.
Zo kan het rittenbedrijf Kafka gebruiken om met de driver-matchingservice te communiceren wanneer een passagier een reservering maakt. De driver-matchingservice kan vervolgens vrijwel in realtime een chauffeur in de buurt vinden en met een bericht antwoorden.
Dit houdt doorgaans in dat fysieke logbestanden van servers worden verzameld en opgeslagen op een centrale locatie voor verwerking, zoals een fileserver of data lake. Kafka abstraheert de data als een stream van berichten en filtert de bestandsspecifieke informatie weg. Dit maakt het mogelijk om data met lagere latentie te verwerken en om gedistribueerde dataconsumptie en verschillende databronnen eenvoudiger te ondersteunen.
Nadat de logs naar Kafka zijn gepubliceerd, kunnen ze worden gebruikt voor troubleshooting, beveiligingsmonitoring en compliance-rapportage door een loganalysetool of een security information and event management (SIEM)-systeem.
Veel Kafka-gebruikers verwerken data in meertrapsverwerkingspijplijnen. Ruwe inputdata wordt uit Kafka-topics gehaald, geaggregeerd, verrijkt of anderszins getransformeerd naar nieuwe topics voor verdere consumptie of verwerking.
Een bank kan bijvoorbeeld Kafka gebruiken om realtime transacties te verwerken. Elke transactie die een klant start, wordt vervolgens als event gepost naar een Kafka-topic. Daarna kan een applicatie deze events innemen, de transacties verifiëren en afhandelen, verdachte transacties blokkeren en klantsaldi direct bijwerken.
Een cloudprovider zou Kafka kunnen gebruiken om statistieken van gedistribueerde applicaties te aggregeren om realtime gecentraliseerde stromen van operationele data te genereren. Metrics van honderden servers, zoals CPU- en geheugengebruik, aantal verzoeken, foutpercentages, enzovoort, kunnen aan Kafka worden gerapporteerd. Monitoringapplicaties kunnen deze metrics vervolgens gebruiken voor anomaliedetectie, waarschuwingen en realtime visualisatie.
Apache Kafka is de industriestandaard voor realtime event streaming en wordt gebruikt door meer dan 80% van de Fortune 100-bedrijven. Met Kafka 4.0 en KRaft-modus is het uitrollen en beheren van clusters eenvoudiger dan in eerdere versies.
In dit artikel besprak ik waarom Kafka ertoe doet, de kerncomponenten, een stapsgewijze setup, geavanceerde features zoals Kafka Streams en Kafka Connect, en toepassingen in de echte wereld. Ga verder met leren via:
Begin vandaag nog aan je Data Engineer-reis!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
