
Kursus
Mengembangkan Aplikasi LLM dengan LangChain
3 Hr
47.9K
Retrieval-Augmented Generation (RAG) adalah salah satu teknik paling menarik dalam AI saat ini. Teknik ini memadukan ketepatan pengambilan informasi nyata dari kumpulan data masif dengan kemampuan penalaran model bahasa berukuran besar. Hasilnya? Respons yang tidak hanya akurat, tetapi juga sangat relevan. Itulah mengapa RAG digunakan untuk segala hal mulai dari chatbot dan mesin pencari hingga konten yang dipersonalisasi.
Namun ada tantangannya: membangun purwarupa hanyalah separuh perjalanan. Tantangan sesungguhnya ada pada deployment: mengubah ide Anda menjadi produk yang andal dan dapat diskalakan.
Dalam artikel ini, saya akan menunjukkan cara membangun dan menerapkan sistem RAG menggunakan LangChain dan FastAPI. Anda akan mempelajari cara beralih dari purwarupa yang berfungsi ke aplikasi skala penuh yang siap digunakan pengguna nyata.
Mari kita mulai!
Sebagaimana kami bahas dalam panduan terpisah, Retrieval-Augmented Generation, atau RAG, adalah metode yang cukup canggih dalam pemrosesan bahasa alami yang benar-benar meningkatkan kapabilitas model bahasa.
Alih-alih hanya mengandalkan pengetahuan yang sudah dimiliki model, RAG melangkah lebih jauh dengan menarik informasi baru yang relevan dari sumber eksternal sebelum menghasilkan respons.
Begini cara kerjanya: ketika pengguna mengajukan pertanyaan, sistem tidak hanya mengandalkan data yang dipelajari sebelumnya oleh model. Sistem terlebih dahulu mencari di sekumpulan besar dokumen atau sumber data, mengambil bagian yang paling relevan, lalu memasukkannya ke dalam model bahasa. Dengan menggabungkan pengetahuan internal dan informasi yang baru diambil ini, model dapat membuat respons yang jauh lebih akurat dan mutakhir.
RAG memadukan pengambilan dan generasi, sehingga respons tidak hanya cerdas—tetapi juga berpijak pada informasi faktual. Ini sangat cocok untuk tugas seperti menjawab pertanyaan, chatbot, atau bahkan menghasilkan konten di mana ketepatan fakta dan pemahaman konteks sangat penting.
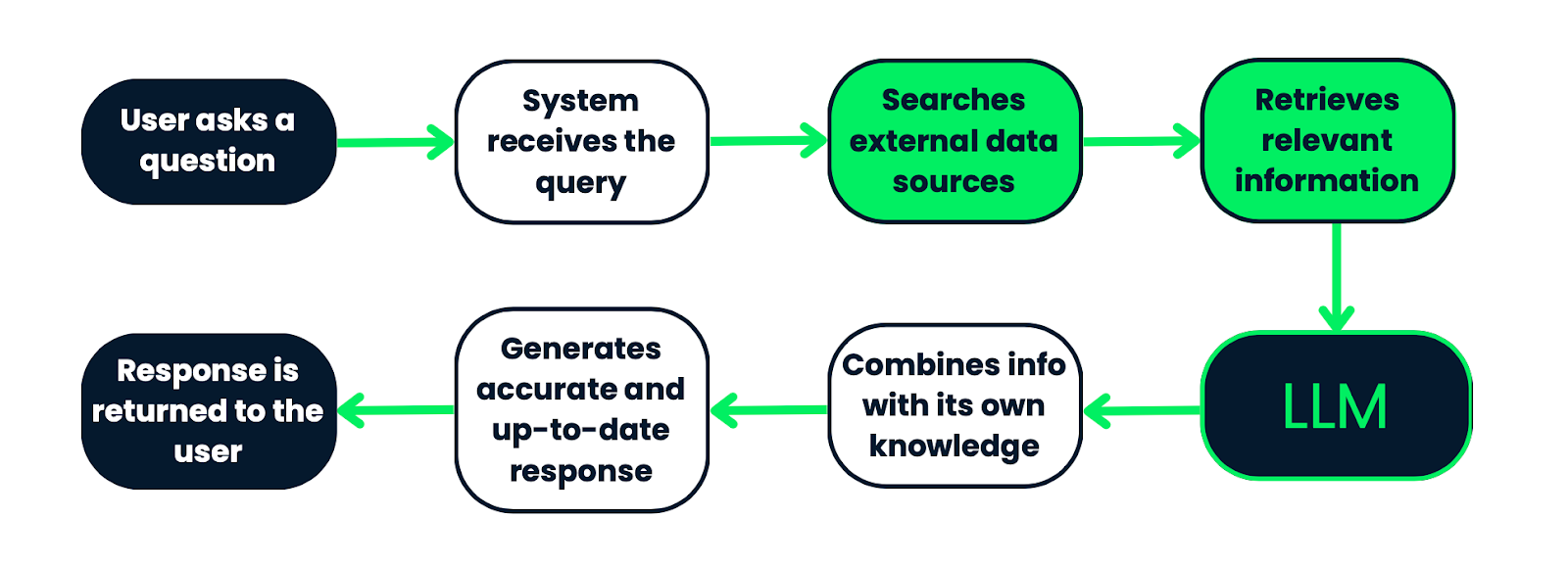
Alur kerja sistem RAG. Dimulai dari kueri pengguna, yang diproses oleh sistem untuk mencari informasi relevan di sumber data eksternal. Informasi yang diambil kemudian dimasukkan ke dalam LLM, yang menggabungkannya dengan pengetahuan bawaan untuk menghasilkan respons yang akurat dan mutakhir. Terakhir, respons dikembalikan kepada pengguna. Proses ini memastikan bahwa respons berpijak pada data faktual yang relevan secara kontekstual.
Saat Anda membangun sistem RAG, ada beberapa bagian esensial agar sistem berjalan: pemuat dokumen, pemisahan teks, pengindeksan, model pengambilan, dan model generatif. Mari kita uraikan:
Langkah pertama adalah menyiapkan data Anda. Itulah fungsi pemuat dokumen, pemisahan teks, dan pengindeksan:
Ini adalah jantung dari sistem RAG. Mereka bertanggung jawab menelusuri semua data terindeks untuk menemukan yang Anda butuhkan.
Di sinilah keajaiban terjadi. Setelah data relevan diambil, model generatif mengambil alih dan menghasilkan respons akhir.
|
Komponen |
Deskripsi |
|
Document Loaders |
Menarik data dari sumber seperti file teks, PDF, atau basis data, mengonversi informasi ke format yang dapat digunakan sistem. |
|
Text Splitting |
Memecah data yang dimuat menjadi potongan lebih kecil, sehingga lebih mudah ditelusuri dan diproses dalam batasan model bahasa. |
|
Indexing |
Mengorganisasi data yang dipecah ke dalam representasi vektor, memungkinkan pencarian cepat dan efisien untuk menemukan informasi relevan bagi sebuah kueri. |
|
Vector Stores |
Basis data khusus yang menyimpan representasi vektor, menggunakan pencarian kemiripan vektor untuk mengambil informasi paling relevan berdasarkan kueri. |
|
Retrievers |
Komponen pencarian yang mengonversi kueri menjadi vektor, menelusuri vector store, dan mengambil potongan data paling relevan untuk langkah berikutnya. |
|
Language Models |
Menghasilkan respons yang koheren dan sesuai konteks menggunakan data yang diambil dan pengetahuan internal. |
|
Contextual Response Generation |
Menggabungkan pertanyaan pengguna dengan data yang diambil untuk membuat respons terperinci yang menjawab pertanyaan sambil memasukkan informasi relevan. |
Sebelum membangun sistem RAG, kita perlu memastikan lingkungan pengembangan disiapkan dengan benar. Berikut yang Anda perlukan:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsInstall Dependencies: Sekarang, pasang paket yang diperlukan menggunakan pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
Kerangka kerja web modern untuk membangun API. |
Server ASGI untuk menyajikan aplikasi FastAPI Anda. |
Pustaka utama yang menjalankan sistem RAG. |
Untuk menggunakan model GPT dalam pembuatan respons. |
Pro tip: Pastikan membuat file requirements.txt untuk menentukan paket yang diperlukan proyek Anda. Jika Anda menggunakan: pip freeze > requirements.txt
Perintah ini akan menghasilkan file requirements.txt yang berisi semua paket terpasang beserta versinya, yang dapat Anda gunakan untuk deployment atau berbagi lingkungan dengan orang lain.
Tambahkan Kunci API OpenAI Anda: Untuk mengintegrasikan model bahasa OpenAI ke dalam sistem RAG Anda, Anda perlu menyediakan kunci API OpenAI:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Sekarang, kunci API OpenAI Anda dimuat dengan aman dari lingkungan, dan Anda siap menggunakannya dalam sistem RAG Anda!
PostgreSQL dan PGVector (Opsional): Jika Anda berencana menggunakan PGVector untuk penyimpanan vektor, pastikan untuk memasang dan menyiapkan PostgreSQL di mesin Anda. Anda dapat menggunakan FAISS (yang akan kita gunakan di artikel ini) atau basis data vektor lain yang didukung LangChain.
Docker (Opsional): Docker dapat membantu Anda membuat container aplikasi untuk memastikan deployment konsisten di berbagai lingkungan. Jika Anda berencana menggunakan Docker, pastikan juga sudah terpasang di mesin Anda.
Langkah pertama dalam membangun sistem RAG adalah menyiapkan data yang akan digunakan sistem untuk mengambil informasi relevan. Ini mencakup memuat dokumen ke dalam sistem, memprosesnya, lalu memastikan dokumen berada dalam format yang mudah diindeks dan diambil kembali.
LangChain menyediakan berbagai pemuat dokumen untuk menangani berbagai sumber data, seperti file teks, PDF, atau laman web. Anda dapat menggunakan pemuat ini untuk memasukkan dokumen Anda ke dalam sistem.
Saya sangat menyukai beruang kutub, jadi saya memutuskan untuk mengunggah berkas teks berikut (my_document.txt) yang berisi informasi ini:“Polar Bears: The Arctic Giants
Polar bears (Ursus maritimus) adalah karnivora darat terbesar di Bumi, dan mereka beradaptasi sempurna dengan kehidupan di dinginnya Arktik. Dikenal dengan bulu putih tebal yang membantu mereka menyatu dengan lanskap bersalju, beruang kutub adalah pemburu yang kuat, mengandalkan es laut untuk berburu anjing laut, sumber makanan utama mereka.
Yang menarik dari beruang kutub adalah kemampuan adaptasi mereka yang luar biasa terhadap lingkungannya. Di bawah bulu tebal itu ada lapisan lemak yang bisa mencapai 4,5 inci, memberikan isolasi dan cadangan energi selama bulan-bulan musim dingin yang keras. Telapak kaki mereka yang besar membantu mereka melangkah melintasi es dan perairan terbuka, menjadikan mereka perenang yang kuat—mampu menempuh jarak jauh untuk mencari makanan atau wilayah baru.
Sayangnya, beruang kutub menghadapi ancaman serius akibat perubahan iklim. Saat Arktik menghangat, es laut mencair lebih awal di tahun tersebut dan terbentuk lebih lambat, mengurangi waktu beruang kutub untuk berburu anjing laut. Tanpa cukup makanan, banyak beruang kesulitan bertahan hidup, dan jumlah populasi mereka menurun di beberapa area.
Beruang kutub memainkan peran penting dalam menjaga kesehatan ekosistem Arktik, dan nasib mereka menjadi pengingat kuat akan dampak perubahan iklim yang lebih luas terhadap satwa liar dunia. Upaya konservasi sedang dilakukan untuk melindungi habitat mereka dan memastikan makhluk megah ini terus berkembang di alam liar.”
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Berikut adalah berkas teks sederhana yang dimuat ke dalam sistem, hanya sebagai contoh pedagogis, namun Anda bisa menambahkan jenis dokumen apa pun yang Anda inginkan! Misalnya, Anda bisa menambahkan dokumentasi internal dari organisasi Anda. Variabel documents kini menyimpan isi berkas, siap diproses.
Dokumen besar sering dipecah menjadi potongan kecil agar lebih mudah diindeks dan diambil kembali. Proses ini sangat penting karena potongan kecil lebih mudah ditangani oleh model bahasa dan memungkinkan pengambilan yang lebih presisi. Anda dapat mempelajari lebih lanjut di panduan kami tentang strategi chunking untuk AI dan RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Di sini, teks dipecah menjadi potongan 500 karakter dengan tumpang tindih 50 karakter antar potongan. Tumpang tindih ini membantu mempertahankan konteks antarpotongan saat pengambilan.
Setelah data disiapkan, langkah berikutnya adalah mengindeksnya untuk pengambilan yang efisien. Pengindeksan melibatkan konversi potongan teks menjadi embedding vektor dan menyimpannya di vector store.
LangChain mendukung pembuatan embedding vektor menggunakan berbagai model, seperti model OpenAI atau HuggingFace. Embedding ini merepresentasikan makna semantik dari potongan teks, sehingga cocok untuk pencarian kemiripan.
Secara sederhana, embedding adalah cara untuk mengubah teks, seperti paragraf dari dokumen, menjadi angka yang dapat dipahami model AI. Angka-angka ini, atau vektor, merepresentasikan makna teks dengan cara yang memudahkan sistem AI memprosesnya.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Kita menggunakan embedding dari OpenAI untuk menangani transformasi tersebut. Pertama, kita memanggil alat embedding OpenAI, lalu menginisialisasinya agar siap digunakan.
Setelah menghasilkan embedding, langkah berikutnya adalah menyimpannya di vector store seperti PGVector, FAISS, atau yang lain yang didukung LangChain. Ini memungkinkan pengambilan dokumen relevan yang cepat dan akurat saat kueri diajukan.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)Dalam kasus ini, kita menggunakan FAISS, yang merupakan alat hebat yang dirancang untuk menelusuri kumpulan vektor besar. FAISS membantu kita menemukan vektor paling mirip dengan sangat cepat.
Jadi, begini alurnya: Kita memanggil FAISS dari LangChain dan menggunakannya untuk membuat yang disebut sebagai vector store. Ini seperti basis data khusus yang dibangun untuk menyimpan dan menelusuri vektor secara efisien.
Keunggulan pengaturan ini adalah, saat kita melakukan pencarian nanti, FAISS dapat menelusuri semua vektor tersebut, menemukan yang paling mirip dengan kueri tertentu, dan mengembalikan potongan dokumen yang sesuai.
Dengan data yang telah diindeks, Anda sekarang dapat menerapkan komponen retrieval, yang bertanggung jawab mengambil informasi relevan berdasarkan kueri pengguna.
Sekarang kita menyiapkan retriever. Ini adalah komponen yang menelusuri dokumen terindeks dan menemukan yang paling relevan dengan kueri pengguna.
Keunggulannya, Anda tidak sekadar mencari secara acak—Anda mencari dengan cerdas menggunakan kekuatan embedding, sehingga hasil yang didapat mirip secara semantik dengan apa yang ditanyakan pengguna. Mari kita lihat baris kodenya:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Pertama, kita mengonversi vector store menjadi retriever. Anda sudah punya vector store FAISS berisi embedding dokumen, kan? Sekarang kita memberitahukannya, "Gunakan itu untuk mencari saat pengguna mengajukan pertanyaan."
Bagian search_type adalah tempat terjadinya keajaiban. Retriever dapat mencari dengan berbagai cara, dan Anda punya beberapa opsi di sini. Pencarian similarity adalah andalan retrieval. Ia memeriksa dokumen yang paling dekat maknanya dengan kueri.
Jadi ketika Anda menetapkan "search_type='similarity'", Anda memberi tahu retriever, "Temukan dokumen yang paling mirip dengan kueri berdasarkan embedding yang telah kita buat."
Dengan search_kwargs={"k": 5} Anda menyetel parameter lebih lanjut. Nilai k memberi tahu retriever berapa banyak dokumen yang diambil dari vector store. Dalam hal ini, k=5 berarti, “Berikan 5 dokumen paling relevan.”
Ini sangat bermanfaat karena membantu mengurangi noise. Alih-alih mendapatkan banyak hasil yang mungkin agak relevan, Anda hanya mengambil potongan informasi yang paling penting.
Di bagian kode ini, kita menyiapkan mesin inti sistem RAG Anda menggunakan LangChain. Anda sudah punya retriever, yang dapat menarik dokumen relevan berdasarkan kueri.
Sekarang, kita menambahkan LLM dan menggunakannya untuk benar-benar menghasilkan respons berdasarkan dokumen yang diambil.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQADi sini, kita mengimpor dua elemen kunci:
llm = OpenAI(openai_api_key=openai_api_key)Baris ini menginisialisasi LLM menggunakan kunci API OpenAI Anda. Anggap saja ini seperti memuat “otak” sistem Anda—model yang akan menerima teks, memahaminya, dan menghasilkan respons.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Di sinilah mulai menarik. Kita menyiapkan QA Chain, yang menyatukan semuanya. Metode RetrievalQA.from_chain_type() membuat rantai tanya-jawab, yang artinya, "Gabungkan retriever dan LLM untuk membuat sistem yang menjawab pertanyaan berdasarkan dokumen yang diambil."
Lalu, kita memberi tahu rantai untuk menggunakan LLM OpenAI yang baru kita inisialisasi guna menghasilkan jawaban. Setelah itu kita menghubungkan retriever yang Anda buat sebelumnya. Retriever bertanggung jawab menemukan dokumen relevan berdasarkan kueri pengguna.
Selanjutnya kita menetapkan chain_type="stuff": Apa itu "stuff"? Ini sebenarnya tipe rantai di LangChain. "Stuff" berarti kita memuat semua dokumen yang relevan ke LLM dan memintanya menghasilkan respons berdasarkan semuanya.
Ibarat menumpuk banyak catatan di meja LLM dan berkata, "Ini, gunakan semua info ini untuk menjawab pertanyaan."
Ada tipe rantai lain juga (seperti "map_reduce" atau "refine"), tetapi "stuff" adalah yang paling sederhana dan langsung.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Di sinilah kita benar-benar mengajukan pertanyaan ke sistem dan mendapatkan respons. Metode invoke() memicu seluruh pipeline.
Metode ini mengambil kueri Anda, mengirimkannya ke retriever untuk mengambil dokumen relevan, lalu meneruskan dokumen tersebut ke LLM, yang menghasilkan respons akhir.
print(response)Baris terakhir ini mencetak respons yang dihasilkan LLM. Berdasarkan dokumen yang diambil, sistem menghasilkan jawaban lengkap dan berbasis informasi untuk kueri, yang kemudian dicetak.
Skrip finalnya terlihat seperti ini:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Sekarang saatnya membangun API untuk berinteraksi dengan sistem RAG Anda. Namun mengapa langkah ini perlu dalam deployment?
Bayangkan Anda mengikuti tutorial ini dan sudah memiliki sistem RAG yang hebat, dipersonalisasi untuk dokumen dan kebutuhan Anda—sistem tersebut menarik informasi relevan, memproses kueri, dan menghasilkan respons cerdas. Namun, bagaimana cara pengguna atau sistem lain berinteraksi dengannya?
FastAPI adalah perantara Anda. Ia menciptakan cara sederhana dan terstruktur bagi pengguna atau aplikasi untuk mengajukan pertanyaan ke sistem RAG Anda dan mendapatkan jawaban.
FastAPI bersifat asynchronous dan berkinerja tinggi. Artinya, ia dapat menangani banyak permintaan sekaligus tanpa melambat, yang sangat penting saat menangani sistem AI yang mungkin perlu mengambil potongan data besar atau menjalankan kueri kompleks.
Di bagian ini, kita akan memodifikasi skrip sebelumnya dan membuat skrip tambahan untuk memastikan sistem RAG Anda dapat diakses, dapat diskalakan, dan siap menangani lalu lintas dunia nyata.Mari mulai dengan membuat rute yang akan menangani permintaan masuk ke sistem RAG.
Di direktori kerja Anda, buat berkas main.py. Ini adalah titik masuk untuk aplikasi FastAPI. Ini akan menjadi “otak” FastAPI Anda—berkas ini akan menyatukan semua rute API, dependensi, dan sistem RAG.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)Ini pengaturan yang cukup sederhana, namun bersih. Yang kita lakukan di sini adalah menyiapkan instance FastAPI, lalu menarik semua rute (atau jalur API) dari berkas lain, yang akan kita buat berikutnya.
Di sinilah semuanya menyatu. Kita akan menulis fungsi yang benar-benar mengeksekusi sistem RAG Anda saat pengguna mengirimkan kueri.
async def get_rag_response(query: str):Fungsi ini ditandai sebagai async, artinya asynchronous. Ini berarti fungsi dapat menangani hal lain sambil menunggu respons.
Fitur seperti ini sangat berguna saat Anda menangani sistem berbasis retrieval di mana pengambilan dokumen atau kueri ke LLM bisa memakan waktu. Dengan cara ini, FastAPI dapat memproses permintaan lain sementara yang ini berjalan di latar belakang.
retriever = setup_rag_system()Di sini kita memanggil fungsi setup_rag_system(), yang, seperti telah dibahas, menginisialisasi seluruh pipeline retriever. Ini berarti:
Retriever ini akan bertanggung jawab mengambil potongan teks relevan berdasarkan kueri pengguna.
Kini, saat pengguna mengajukan pertanyaan, retriever menelusuri semua dokumen di vector store dan mengambil yang paling relevan berdasarkan kueri.
retrieved_docs = retriever.get_relevant_documents(query)Metode invoke(query) ini mengambil dokumen relevan tersebut. Di balik layar, metode ini mencocokkan kueri dengan vektor embedding dan mengambil kecocokan teratas berdasarkan kemiripan.
Setelah kita memiliki dokumen relevan, kita perlu memformatnya untuk LLM.
context = "\n".join([doc.page_content for doc in retrieved_docs])Di sini, kita mengambil semua dokumen yang diambil dan menggabungkan isinya menjadi satu string. Ini penting karena LLM mengharapkan satu blok teks yang rapi, bukan banyak potongan terpisah.
Kita menggunakan fungsi join() milik Python untuk menjahit potongan dokumen ini menjadi satu blok informasi yang koheren. Konten setiap dokumen disimpan di bidang doc.page_content, dan kita menggabungkannya dengan baris baru (\n).
Sekarang kita membuat prompt untuk LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]Prompt disusun sedemikian rupa untuk memberi tahu LLM agar menggunakan informasi yang diambil untuk menjawab kueri pengguna.
Sekarang saatnya menghasilkan respons.
generated_response = llm.generate(prompt) # Pass as a list of stringsDi sini, model OpenAI bertugas mengambil prompt dan menghasilkan respons yang sadar konteks berdasarkan pertanyaan dan dokumen relevan.
Terakhir, kita mengembalikan respons yang dihasilkan kepada pemanggil fungsi (baik itu pengguna, aplikasi frontend, atau sistem lain).
return generated_responseRespons ini sudah lengkap, kontekstual, dan siap digunakan dalam aplikasi dunia nyata.
Singkatnya, fungsi ini melakukan loop retrieval dan generasi secara penuh. Berikut ringkasan alurnya:
1. Menyiapkan retriever untuk menemukan dokumen relevan.
2. Dokumen tersebut diambil berdasarkan kueri.
3. Konteks dari dokumen disiapkan untuk LLM.
4. LLM menghasilkan respons akhir menggunakan konteks tersebut.
5. Respons dikembalikan ke pengguna.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyBerikutnya, mari buat berkas endpoints.py. Di sinilah kita akan mendefinisikan jalur yang dipanggil pengguna untuk berinteraksi dengan sistem RAG Anda.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Kita membuat APIRouter untuk mengelola rute API. Endpoint /query/ didefinisikan untuk menerima permintaan GET dengan string kueri. Endpoint ini memanggil fungsi get_rag_response dari berkas rag.py Anda, yang menangani seluruh pipeline RAG (pengambilan dokumen + generasi bahasa). Jika terjadi kesalahan, kita mengeluarkan error HTTP 500 dengan pesan terperinci.
Dengan semua itu disiapkan, kini Anda dapat menjalankan aplikasi FastAPI menggunakan Uvicorn. Ini adalah web server yang memungkinkan pengguna mengakses API Anda.
Buka terminal dan jalankan:
uvicorn app.main:app --reloadapp.main:app memberi tahu Uvicorn untuk mencari instance app di berkas main.py dan --reload mengaktifkan pemuatan ulang otomatis jika Anda melakukan perubahan pada kode.
Setelah server berjalan, buka peramban Anda dan kunjungi http://127.0.0.1:8000/docs. FastAPI secara otomatis membuat dokumentasi Swagger UI untuk API Anda, sehingga Anda dapat mengujinya langsung dari peramban!
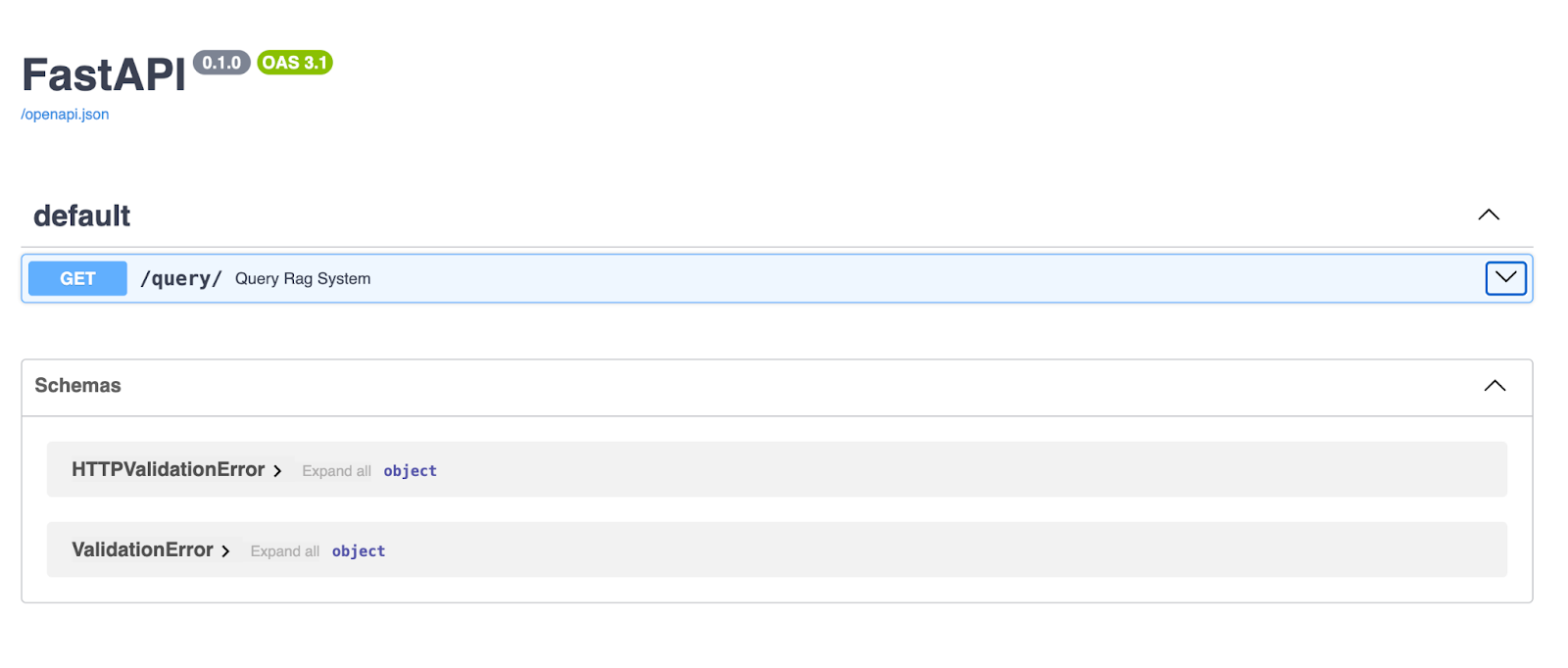
FastAPI Swagger UI menyediakan antarmuka yang bersih dan interaktif untuk menjelajahi serta menguji endpoint API Anda. Di sini, endpoint /query/ memungkinkan pengguna memasukkan string kueri dan menerima respons yang dihasilkan oleh pipeline RAG.
Dengan server FastAPI Anda berjalan, buka peramban atau gunakan Postman atau Curl untuk membuat permintaan GET ke endpoint /query/ Anda.
Di peramban, melalui Swagger:
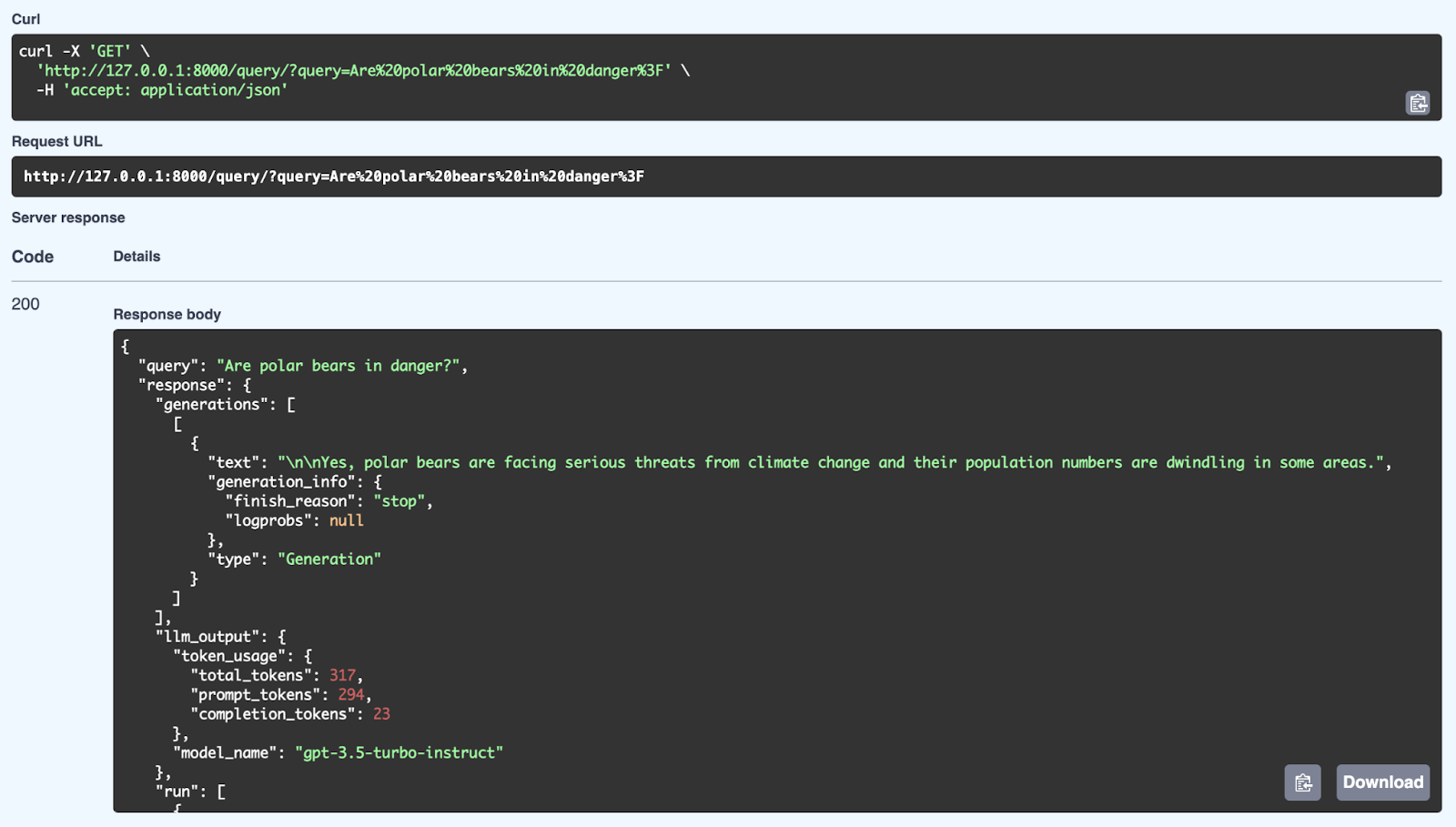
Di sini kita dapat melihat respons yang berhasil dari sistem RAG menggunakan kueri: "Are polar bears in danger?". Sistem mengambil informasi relevan dari basis pengetahuannya dan menghasilkan respons yang koheren menggunakan model GPT-3.5 Turbo-Instruct. Respons terperinci mencakup tidak hanya jawaban (Ya, beruang kutub menghadapi ancaman serius akibat perubahan iklim dan jumlah populasinya menurun) tetapi juga metadata seperti penggunaan token (jumlah token yang diproses) dan model yang digunakan untuk menghasilkan. API mampu memberikan jawaban yang terstruktur dan sadar konteks dengan menggunakan mekanisme retrieval dan generasi melalui FastAPI.
Sekarang mari bahas manfaat Pemrosesan Asinkron di FastAPI dan mengapa ini membuat perbedaan besar dalam menangani permintaan API dunia nyata.
Anda telah menjalankan sistem RAG Anda. API menerima pertanyaan, mengambil informasi relevan dari basis pengetahuannya, lalu menghasilkan respons dengan model bahasa.
Sekarang, jika seluruh proses itu sinkron, sistem akan menunggu setiap tugas selesai sebelum melanjutkan ke berikutnya. Misalnya, saat mengambil dokumen, sistem tidak bisa memproses permintaan baru.
|
Non-blocking I/O |
Kinerja Meningkat |
Pengalaman Pengguna Lebih Baik |
|
Fungsi async memungkinkan server menangani banyak permintaan sekaligus, alih-alih menunggu satu selesai sebelum memulai yang lain. |
Untuk tugas seperti mengambil dokumen dari vector store atau menghasilkan teks, pemrosesan async memastikan API dapat mengelola beban tinggi secara efisien. |
Klien mendapatkan respons lebih cepat, dan API Anda tetap responsif bahkan saat beban tinggi. |
Mari bahas strategi deployment—langkah yang sangat penting untuk mengubah sistem RAG Anda dari purwarupa menjadi produk yang benar-benar beroperasi. Tujuannya adalah memastikan sistem Anda dikemas, diterapkan, dan siap diskalakan sehingga dapat menangani pengguna dunia nyata.
Pertama, mari bahas Docker. Docker bagaikan kotak ajaib yang mengemas semua yang dibutuhkan sistem RAG Anda—kode, dependensi, konfigurasi—ke dalam sebuah container yang rapi.
Ini memastikan di mana pun Anda menerapkan aplikasi, perilakunya tetap sama. Anda bisa menjalankan aplikasi di berbagai lingkungan, tetapi karena berada dalam container, Anda tidak perlu khawatir dengan masalah “berfungsi di mesin saya”.

Anda membuat Dockerfile, yaitu serangkaian instruksi yang memberi tahu Docker cara menyiapkan lingkungan aplikasi Anda, memasang paket yang diperlukan, dan memulai menjalankannya. Setelah itu, Anda dapat membangun image Docker darinya dan menjalankan aplikasi Anda di dalam container. Ini efisien, dapat diulang, dan sangat portabel.
Setelah sistem Anda dikemas dan siap, kemungkinan Anda ingin menerapkannya ke cloud. Di sinilah menjadi menarik karena menerapkan sistem RAG ke cloud berarti sistem dapat diakses dari mana saja di dunia. Selain itu, Anda mendapatkan skalabilitas, keandalan, dan akses ke layanan cloud lain yang dapat meningkatkan sistem Anda.
Mari lihat beberapa platform cloud populer lainnya, termasuk Azure dan Google Cloud:
AWS menawarkan alat seperti Elastic Beanstalk, yang memudahkan deployment. Anda cukup menyerahkan container Docker Anda, dan AWS mengurus penskalaan, load balancing, dan pemantauan. Jika Anda butuh kontrol lebih, Anda dapat menggunakan Amazon ECS, yang memungkinkan Anda menjalankan container Docker di klaster server dan menskalakannya naik atau turun sesuai kebutuhan.
Heroku adalah opsi lain yang menyederhanakan deployment. Anda cukup mendorong kode Anda, dan Heroku menangani infrastrukturnya untuk Anda. Ini pilihan yang bagus jika Anda tidak ingin terlalu dalam mengelola sumber daya cloud.
Azure menawarkan Azure App Service, yang memungkinkan Anda menerapkan dan mengelola sistem RAG dengan mudah, menyediakan dukungan bawaan untuk autoscaling, load balancing, dan continuous deployment.
Untuk fleksibilitas lebih, Anda dapat menggunakan Azure Kubernetes Service (AKS) untuk mengelola container Docker dalam skala besar, memastikan sistem Anda dapat menangani lalu lintas tinggi dengan kemampuan menyesuaikan sumber daya secara dinamis sesuai kebutuhan.
GCP memiliki Google Cloud Run, platform terkelola penuh yang memungkinkan Anda menerapkan container dan menskalakannya secara otomatis berdasarkan lalu lintas.
Jika Anda menginginkan kontrol lebih atas infrastruktur, Anda dapat menggunakan Google Kubernetes Engine (GKE), yang memberi Anda kemampuan mengelola dan menskalakan container Docker di berbagai node, dengan manfaat tambahan integrasi mendalam dengan layanan cloud Google seperti API AI dan pembelajaran mesin.
Setiap platform memiliki keunggulannya, apakah Anda menginginkan kesederhanaan dan otomatisasi atau kontrol yang lebih granular atas deployment Anda.
Kita telah membahas banyak hal dalam artikel ini, menelusuri proses membangun sistem RAG menggunakan LangChain dan FastAPI. Sistem RAG merupakan lompatan besar dalam pemrosesan bahasa alami karena memasukkan informasi eksternal, memberi AI kemampuan menghasilkan respons yang lebih akurat, relevan, dan sadar konteks.
Dengan LangChain, kita memiliki kerangka kerja solid yang menangani semuanya mulai dari memuat dokumen, memisahkan teks, membuat embedding, hingga mengambil informasi berdasarkan kueri pengguna.
Kemudian, FastAPI hadir memberikan kerangka kerja web yang cepat dan siap async, membantu kita menerapkan sistem RAG sebagai API yang dapat diskalakan.
Bersama-sama, alat ini memudahkan pembuatan aplikasi AI yang dapat menangani kueri kompleks, memberikan jawaban presisi, dan pada akhirnya menyediakan pengalaman pengguna yang lebih baik.
Sekarang, saatnya Anda mengambil apa yang telah dipelajari dan menerapkannya pada proyek Anda sendiri.
Pikirkan kemungkinannya: melakukan kueri ke basis pengetahuan internal perusahaan Anda, mengotomatisasi proses peninjauan dokumen, atau membuat chatbot cerdas untuk dukungan klien.
Jangan lupa—ada banyak cara untuk memperluas pengaturan ini! Anda bisa bereksperimen dengan permintaan POST untuk mengirim struktur data yang lebih kompleks, atau bahkan menjajaki koneksi WebSocket untuk interaksi secara real-time.
Saya mendorong Anda untuk menggali lebih dalam, bereksperimen, dan melihat ke mana ini dapat membawa Anda. Ini baru permulaan dari apa yang bisa Anda capai dengan LangChain, FastAPI, dan alat AI modern! Berikut beberapa sumber yang saya rekomendasikan:
Kursus Teratas di DataCamp
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
