
Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
A Geração Aumentada por Recuperação (RAG) é uma das técnicas mais empolgantes da IA atualmente. Combina a precisão de recuperar informações reais de conjuntos de dados enormes com o poder de raciocínio de grandes modelos de linguagem. O resultado? Respostas que não são só precisas, mas também super relevantes. É por isso que a RAG está impulsionando tudo, desde chatbots e mecanismos de busca até conteúdo personalizado.
Mas tem um porém: fazer um protótipo é só metade do caminho. O verdadeiro desafio está naimplementação de um : transformar sua ideia em um produto confiável e escalável.
Neste artigo, vou mostrar como criar e implementar um sistema RAG usando LangChain e FastAPI. Você vai aprender como passar de um protótipo funcional para um aplicativo completo, pronto para usuários reais.
Vamos lá!
Como exploramos em um guia separado, Geração Aumentada por Recuperação, ou RAG, é um método bem avançado no processamento de linguagem natural que realmente eleva o nível do que os modelos de linguagem podem fazer.
Em vez de só confiar no que o modelo já sabe, o RAG vai além, pegando informações novas e relevantes de fontes externas antes de gerar uma resposta.
Funciona assim: quando alguém faz uma pergunta, o sistema não depende só dos dados que o modelo já aprendeu. Primeiro, ele sai, procura em um monte de documentos ou fontes de dados, pega as partes mais relevantes e depois coloca isso no modelo de linguagem. Com o conhecimento que já tem e essas novas informações, o modelo consegue criar uma resposta bem mais precisa e atualizada.
O RAG combina recuperação e geração, então as respostas não são só inteligentes, mas também baseadas em informações reais e factuais. Isso o torna perfeito para coisas como responder perguntas, chatbots ou até mesmo gerar conteúdo, onde acertar os fatos e entender o contexto realmente importa.
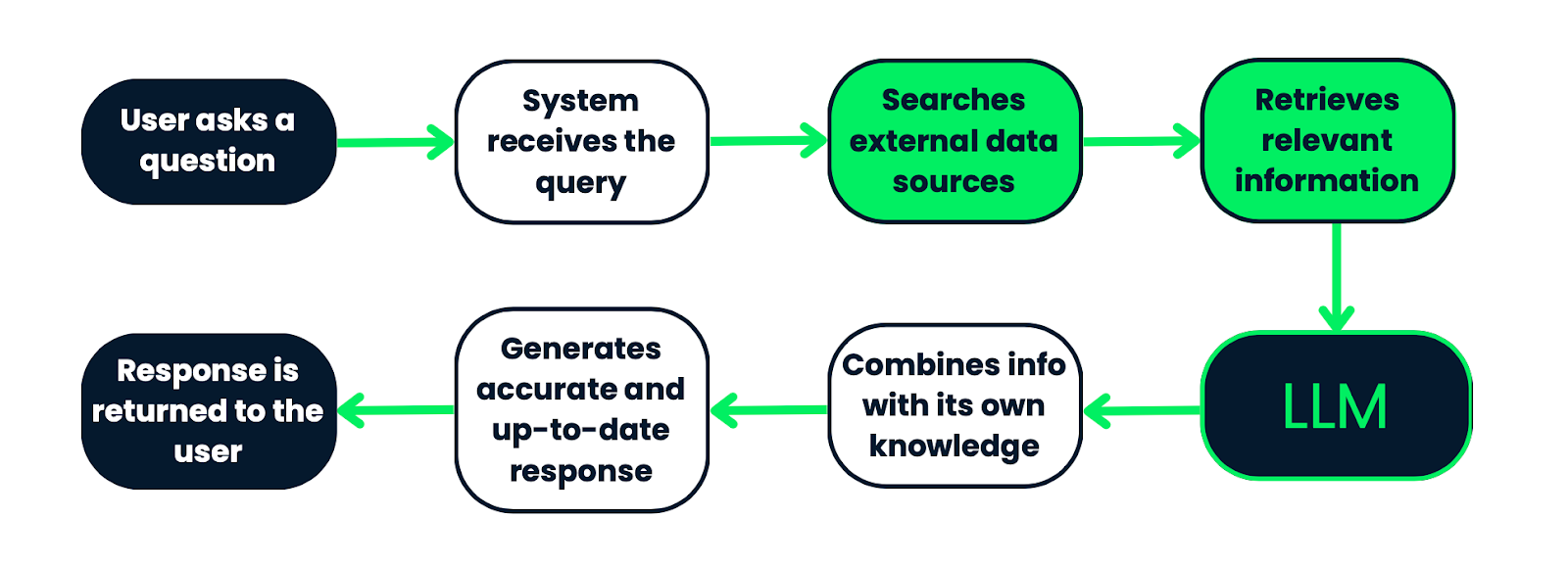
Fluxo de trabalho de um sistema RAG. Começa com uma consulta do usuário, que é processada pelo sistema para procurar informações relevantes em fontes de dados externas. As informações recuperadas são então inseridas em um LLM, que as combina com seu conhecimento pré-existente para gerar uma resposta precisa e atualizada. Por fim, a resposta é devolvida ao usuário. Esse processo garante que as respostas sejam baseadas em dados factuais e contextualmente relevantes.
Quando você está construindo um sistema RAG, existem algumas partes essenciais para colocá-lo em funcionamento: carregadores de documentos, divisão de texto, indexação, modelos de recuperação e modelos generativos. Vamos analisar:
O primeiro passo é preparar seus dados. É isso que os carregadores de documentos, a divisão de texto e a indexação fazem:
Esses são o coração do sistema RAG. Eles são os responsáveis por vasculhar todos esses dados indexados para encontrar o que você precisa.
É aqui que a mágica acontece. Depois que os dados relevantes são recuperados, os modelos generativos assumem e produzem uma resposta final.
|
Componente |
Descrição |
|
Carregadores de documentos |
Pegue os dados de fontes como arquivos de texto, PDFs ou bancos de dados, transformando as informações em um formato que o sistema possa usar. |
|
Divisão de texto |
O Chops divide os dados em pedaços menores, facilitando a busca e o processamento dentro dos limites dos modelos de linguagem. |
|
Indexação |
Organiza dados divididos em representações vetoriais, permitindo pesquisas rápidas e eficientes para encontrar informações relevantes para uma consulta. |
|
Lojas Vector |
Bancos de dados especializados que guardam representações vetoriais, usando a pesquisa de similaridade vetorial para pegar as informações mais relevantes com base na consulta. |
|
Retrievers |
Pesquise componentes que transformam a consulta em um vetor, procure no armazenamento de vetores e pegue os pedaços de dados mais relevantes para a próxima etapa. |
|
Modelos de linguagem |
Crie respostas que façam sentido e sejam adequadas ao contexto usando tanto os dados que você encontrou quanto o seu próprio conhecimento. |
|
Geração de respostas contextuais |
Junta a pergunta do usuário com os dados que encontrou para criar uma resposta detalhada que responde à pergunta e inclui as informações relevantes. |
Antes de montar nosso sistema RAG, precisamos ter certeza de que nosso ambiente de desenvolvimento está configurado direitinho. Aqui está o que você vai precisar:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsInstalar dependências: Agora, instale os pacotes necessários usando o pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
API OpenAI |
|
Uma estrutura web moderna para criar APIs. |
Um servidor ASGI para servir sua aplicação FastAPI. |
A biblioteca principal que alimenta o sistema RAG. |
Usar modelos GPT para gerar respostas. |
Dica profissional: Não esqueça de criar um arquivo requirements.txt pra especificar os pacotes necessários pro seu projeto. Se você usar: pip freeze > requirements.txt
Esse comando vai criar um arquivo requirements.txt com todos os pacotes instalados e suas versões, que você pode usar pra implantar ou compartilhar o ambiente com outras pessoas.
Adicione sua chave API OpenAI: Pra integrar o modelo de linguagem OpenAI no seu sistema RAG, você vai precisar fornecer sua chave API OpenAI:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Agora, sua chave API OpenAI está carregada com segurança do ambiente e você está pronto para começar a usá-la no seu sistema RAG!
PostgreSQL e PGVector (opcional): Se você está pensando em usar o PGVector para armazenamento vetorial, certifique-se de instalar e configurar o PostgreSQL na sua máquina. Você pode usar o FAISS (que vamos usar neste artigo) ou outros bancos de dados vetoriais compatíveis com o LangChain.
Docker (opcional): O Docker pode te ajudar a colocar sua aplicação em um contêiner pra garantir uma implantação consistente em todos os ambientes. Se você planeja usar o Docker, certifique-se de que ele também esteja instalado na sua máquina.
O primeiro passo pra montar um sistema RAG é preparar os dados que o sistema vai usar pra pegar as informações relevantes. Isso envolve carregar documentos no sistema, processá-los e, em seguida, garantir que eles estejam em um formato que possa ser facilmente indexado e recuperado.
O LangChain oferece vários carregadores de documentos para lidar com diferentes fontes de dados, como arquivos de texto, PDFs ou páginas da web. Você pode usar esses carregadores para trazer seus documentos para o sistema.
Eu curto muito os ursos polares, então resolvi mandar o arquivo de texto (meu_documento.txt) com essas informações:“Ursos polares: Os gigantes do Ártico
Os ursos polares (Ursus maritimus) são os maiores carnívoros terrestres do planeta e se adaptaram super bem à vida no frio extremo do Ártico. Conhecidos por sua pelagem branca e espessa, que os ajuda a se camuflar na paisagem nevada, os ursos polares são caçadores poderosos, dependendo do gelo marinho para caçar focas, sua principal fonte de alimento.
O que é fascinante nos ursos polares é a incrível adaptação deles ao ambiente. Debaixo dessa pelagem grossa tem uma camada de gordura que pode chegar a 11 cm de espessura, que dá isolamento e reserva de energia durante os meses rigorosos de inverno. Suas grandes patas ajudam a andar tanto no gelo quanto na água aberta, o que faz deles ótimos nadadores — capazes de percorrer grandes distâncias em busca de comida ou novos territórios.
Infelizmente, os ursos polares estão enfrentando sérias ameaças devido às mudanças climáticas. Com o aquecimento do Ártico, o gelo marinho está derretendo mais cedo no ano e se formando mais tarde, reduzindo o tempo que os ursos polares têm para caçar focas. Sem comida suficiente, muitos ursos lutam para sobreviver, e sua população está diminuindo em algumas áreas.
Os ursos polares são super importantes para manter o ecossistema do Ártico saudável, e a situação deles é um lembrete forte dos efeitos maiores das mudanças climáticas na vida selvagem do mundo todo. Esforços de conservação estão em andamento para proteger seu habitat e garantir que essas criaturas incríveis continuem a prosperar na natureza.
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Aqui está um arquivo de texto simples carregado no sistema, só como um exemplo, mas você pode adicionar qualquer tipo de documento que quiser! Por exemplo, você pode adicionar documentação interna da sua organização. A variável documents agora tem o conteúdo do arquivo, pronto para ser processado.
Documentos grandes costumam ser divididos em partes menores para facilitar a indexação e a recuperação. Esse processo é super importante porque pedaços menores são mais fáceis de lidar para o modelo de linguagem e permitem uma recuperação mais precisa. Você pode saber mais no nosso guia sobre estratégias de chunking para IA e RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Aqui, o texto é dividido em blocos de 500 caracteres com uma sobreposição de 50 caracteres entre os blocos. Essa sobreposição ajuda a manter o contexto entre os trechos durante a recuperação.
Depois que os dados estiverem prontos, o próximo passo é indexá-los para facilitar a recuperação. A indexação envolve converter os trechos de texto em incorporações vetoriais e armazená-los em um repositório vetorial.
O LangChain dá suporte à criação de incorporações vetoriais usando vários modelos, como os modelos OpenAI ou HuggingFace. Essas incorporações representam o significado semântico dos trechos de texto, o que as torna adequadas para pesquisas de similaridade.
Em termos simples, os embeddings são basicamente uma forma de pegar um texto, tipo um parágrafo de um documento, e transformá-lo em números que um modelo de IA consegue entender. Esses números, ou vetores, mostram o que o texto quer dizer de um jeito que os sistemas de IA conseguem entender mais fácil.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Estamos usando os embeddings da OpenAI para lidar com essa transformação. Primeiro, a gente traz a ferramenta de incorporação da OpenAI e, em seguida, a inicializa para que esteja pronta para uso.
Depois de gerar as incorporações, o próximo passo é armazená-las em um armazenamento vetorial como PGVector, FAISS ou qualquer outro compatível com LangChain. Isso permite uma recuperação rápida e precisa de documentos relevantes quando uma consulta é feita.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)Nesse caso, estamos usando o FAISS, que é uma ferramenta incrível feita pra pesquisar em grandes conjuntos de vetores. O FAISS ajuda a achar os vetores mais parecidos rapidinho.
Então, é o seguinte: Pegamos o FAISS do LangChain e usamos ele pra criar o que chamamos de armazenamento vetorial. É tipo um banco de dados especial feito pra guardar e procurar vetores de forma eficiente.
O legal dessa configuração é que, quando fizermos uma pesquisa mais tarde, o FAISS vai poder dar uma olhada em todos esses vetores, achar os que são mais parecidos com uma determinada consulta e devolver os trechos de documentos correspondentes.
Com os dados indexados, agora você pode implementar o componente de recuperação, que é responsável por buscar informações relevantes com base nas consultas dos usuários.
Agora estamos configurando um recuperador. É o componente que analisa os documentos indexados e encontra os mais relevantes para a consulta do usuário.
O legal é que você não está apenas pesquisando aleatoriamente, mas sim de forma inteligente, com o poder das incorporações, de modo que os resultados obtidos são semanticamente semelhantes ao que o usuário está procurando. Vamos dar uma olhada na linha de código:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Primeiro, a gente transforma o armazenamento vetorial em um recuperador. Você sabe que já tem essa loja de vetores FAISS cheia de incorporações de documentos? Bom, agora estamos dizendo: “Ei, vá em frente e use isso pra procurar coisas quando um usuário me fizer uma pergunta”.
Agora, search_type é onde a mágica acontece. O recuperador pode fazer a busca de várias maneiras, e você tem algumas opções aqui. A busca por semelhanças é o básico da recuperação de dados. Ele verifica quais documentos têm o significado mais próximo da consulta.
Então, quando você diz “search_type=’similarity’”, você está dizendo ao recuperador: “Encontre documentos que sejam mais parecidos com a consulta com base nas incorporações que geramos”.
Com search_kwargs={“k”: 5} você faz os ajustes finais. O valor k diz ao recuperador quantos documentos ele deve pegar do armazenamento vetorial. Nesse caso, k=5 quer dizer: “Mostre os 5 documentos mais relevantes”.
Isso é superpoderoso porque ajuda a reduzir o ruído. Em vez de obter uma infinidade de resultados que talvez sejam mais ou menos relevantes, você está obtendo apenas as informações mais importantes.
Nesta parte do código, estamos configurando o mecanismo central do seu sistema RAG usando o LangChain. Você já tem seu recuperador, que pode trazer os documentos relevantes com base em uma consulta.
Agora, estamos adicionando o LLM e usando-o para realmente gerar a resposta com base nos documentos recuperados.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQAAqui, estamos importando dois elementos principais:
llm = OpenAI(openai_api_key=openai_api_key)Essa linha inicializa o LLM usando sua chave da API OpenAI. Pense nisso como carregar o cérebro do seu sistema — é o modelo que vai receber o texto, entendê-lo e gerar respostas.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)É aqui que as coisas começam a ficar realmente emocionantes. A gente está montando a Cadeia de Controle de Qualidade, que junta tudo. O método RetrievalQA.from_chain_type() cria uma cadeia de perguntas e respostas, que é uma forma de dizer: “Junte o recuperador e o LLM para criar um sistema que responda a perguntas com base nos documentos recuperados”.
Então, estamos dizendo à cadeia para usar o OpenAI LLM que acabamos de inicializar para gerar respostas. Depois disso, vamos conectar o recuperador que você montou antes. O recuperador é responsável por encontrar os documentos relevantes com base na consulta do usuário.
Então, estamos definindo chain_type="stuff": Ok, o que é “coisas” aqui? Na verdade, é um tipo de cadeia no LangChain. “Coisas” quer dizer que estamos colocando todos os documentos relevantes que achamos no LLM e fazendo ele gerar uma resposta com base em tudo isso.
É como jogar um monte de notas na mesa do LLM e dizer: “Aqui, use todas essas informações para responder à pergunta”.
Existem outros tipos de cadeias também (como “map_reduce” ou “refine”), mas “stuff” é a mais simples e direta.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})É aqui que a gente faz uma pergunta pro sistema e recebe uma resposta. O método invoke() aciona todo o pipeline.
Ele pega sua consulta, manda pro recuperador buscar os documentos relevantes e, em seguida, passa esses documentos pro LLM, que gera a resposta final.
print(response)Isso imprime a resposta gerada pelo LLM. Com base nos documentos recuperados, o sistema gera uma resposta completa e bem informada à consulta, que é impressa.
O script final fica assim:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Agora é hora de criar uma API para interagir com seu sistema RAG. Mas por que essa etapa é necessária na implantação?
Então, imagina que você seguiu este tutorial e tem esse incrível sistema RAG configurado e personalizado para seus documentos e necessidades — ele está coletando informações relevantes, processando consultas e gerando respostas inteligentes. Mas como você realmente permite que usuários ou outros sistemas interajam com ele?
O FastAPI é o seu intermediário. Isso cria uma maneira simples e estruturada para os usuários ou aplicativos fazerem perguntas ao seu sistema RAG e obterem respostas.
O FastAPI é assíncrono e tem um desempenho incrível. Isso quer dizer que ele consegue lidar com várias solicitações ao mesmo tempo sem ficar lento, o que é super importante quando se trata de sistemas de IA que podem precisar recuperar grandes quantidades de dados ou executar consultas complexas.
Nesta seção, vamos modificar o script anterior e criar outros adicionais para garantir que seu sistema RAG seja acessível, escalável e pronto para lidar com o tráfego do mundo real.Vamos começar criando as rotas que vão lidar com as solicitações recebidas pelo sistema RAG.
No seu diretório de trabalho, crie um arquivo chamado main.py. Este é o ponto de entrada para o aplicativo FastAPI. Esse vai ser o seu cérebro FastAPI — esse arquivo vai juntar todas as rotas da API, dependências e o sistema RAG.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)É uma configuração bem simples, mas é clara. O que estamos fazendo aqui é configurar uma instância FastAPI e, em seguida, puxar todas as rotas (ou caminhos API) de outro arquivo, que criaremos a seguir.
Então, é aqui que tudo se junta. Vamos escrever uma função que realmente executa seu sistema RAG quando um usuário envia uma consulta.
async def get_rag_response(query: str):Essa função está marcada como ` async`, o que significa que é assíncrona. Isso quer dizer que ele pode cuidar de outras coisas enquanto espera por uma resposta.
Esse recurso é super útil quando você está lidando com sistemas baseados em recuperação, onde buscar documentos ou consultar um LLM pode demorar um pouco. Assim, o FastAPI pode processar outras solicitações enquanto essa é processada em segundo plano.
retriever = setup_rag_system()Aqui estamos chamando a função ` setup_rag_system() `, que, como falamos antes, inicializa todo o pipeline do recuperador. Isso quer dizer:
Esse recuperador vai ser responsável por buscar os trechos relevantes do texto com base na consulta do usuário.
Agora, quando alguém faz uma pergunta, o recuperador dá uma olhada em todos os documentos no armazenamento vetorial e pega os que são mais relevantes com base na consulta.
retrieved_docs = retriever.get_relevant_documents(query)Esse método ` invoke(query) ` está pegando os documentos relevantes. Nos bastidores, ele está comparando a consulta com os vetores de incorporação e selecionando as principais correspondências com base na similaridade.
Agora que temos os documentos certos, precisamos formatá-los para o LLM.
context = "\n".join([doc.page_content for doc in retrieved_docs])Aqui, estamos pegando todos os documentos recuperados e juntando o conteúdo deles em uma única sequência. Isso é importante porque o LLM espera um trecho de texto limpo para trabalhar, não um monte de pedaços separados.
Estamos usando a função ` join() ` do Python para juntar esses pedaços de documentos em um único bloco de informações que faz sentido. O conteúdo de cada documento é guardado no campo “ doc.page_content ” e estamos juntando eles com novas linhas (\n).
Agora estamos criando o prompt para o LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]A solicitação está estruturada de forma a indicar ao LLM que utilize as informações recuperadas para responder à consulta do usuário.
Agora é hora de gerar uma resposta.
generated_response = llm.generate(prompt) # Pass as a list of stringsAqui, o modelo OpenAI agora tem a tarefa de pegar o prompt e gerar uma resposta contextualizada com base na pergunta e nos documentos relevantes.
Por fim, devolvemos a resposta gerada para quem chamou a função (seja um usuário, um aplicativo front-end ou outro sistema).
return generated_responseEssa resposta está totalmente pronta, contextualizada e pronta para ser usada em aplicações do mundo real.
Resumindo, essa função faz todo o ciclo de recuperação e geração. Aqui vai um resumo rápido do fluxo:
1. Ele configura o recuperador para encontrar documentos relevantes.
2. Esses documentos são extraídos com base na consulta.
3. O contexto desses documentos está pronto para o LLM.
4. O LLM gera uma resposta final usando esse contexto.
5. A resposta é devolvida ao usuário.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyA seguir, vamos criar nosso arquivo endpoints.py. É aqui que vamos definir os caminhos reais que os usuários vão usar pra interagir com o seu sistema RAG.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Criamos um objeto ` APIRouter ` para gerenciar nossas rotas de API. O endpoint /query/ está configurado para aceitar uma solicitação **GET** com uma string de consulta. Ele chama a função get_rag_response do seu arquivo rag.py, que cuida de todo o pipeline RAG (recuperação de documentos + geração de linguagem). Se algo der errado, a gente gera um erro HTTP 500 com uma mensagem detalhada.
Com tudo isso configurado, agora você pode rodar seu aplicativo FastAPI usando o Uvicorn. Esse é o servidor web que vai deixar os usuários acessarem sua API.
Vá até o terminal e execute:
uvicorn app.main:app --reloadapp.main:app diz ao Uvicorn para procurar a instância app no arquivo main.py e --reload permite o recarregamento automático se você fizer alguma alteração no seu código.
Quando o servidor estiver funcionando, abra o seu navegador e vá para http://127.0.0.1:8000/docs. O FastAPI gera automaticamente a documentação Swagger UI para sua API, para que você possa testá-la diretamente no seu navegador!
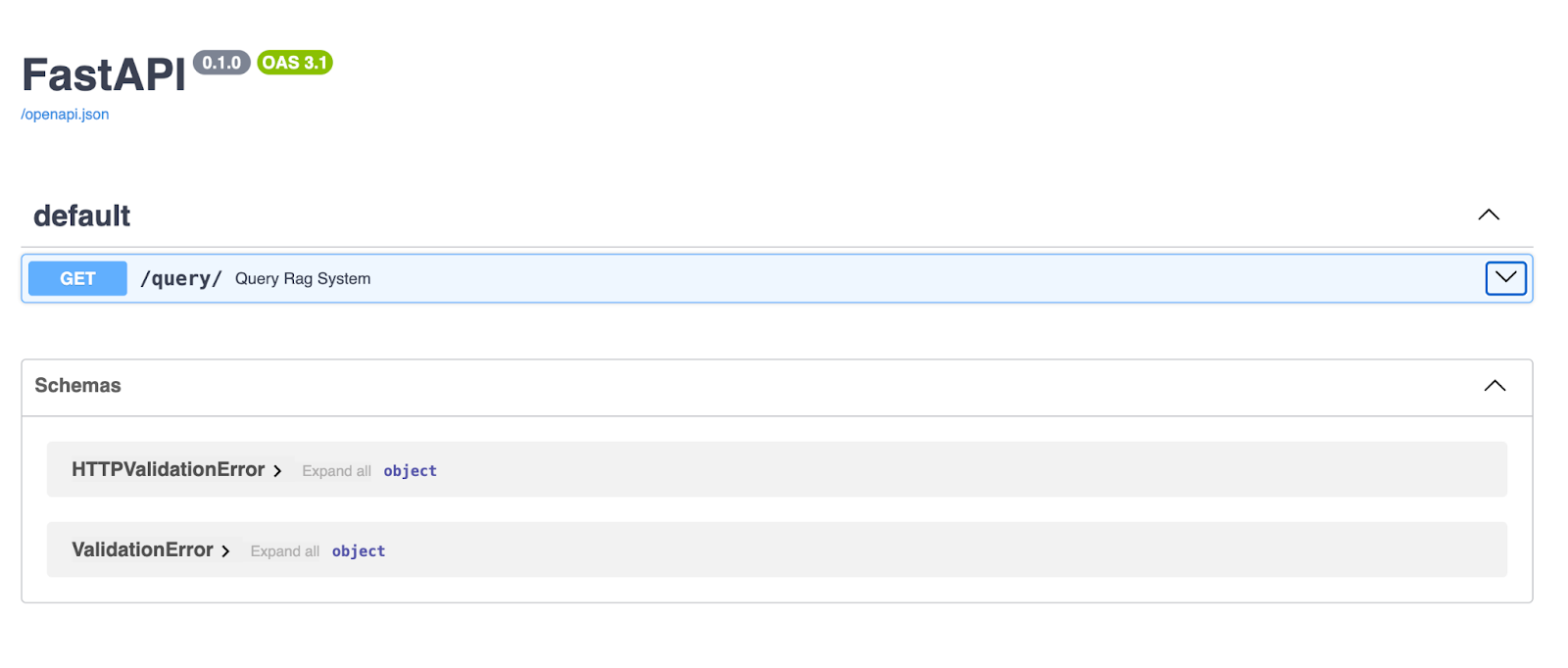
A interface FastAPI Swagger oferece uma interface limpa e interativa para explorar e testar seus pontos finais de API. Aqui, o endpoint /query/ permite que os usuários insiram uma string de consulta e recebam uma resposta gerada pelo pipeline RAG.
Com o servidor FastAPI funcionando, vá até o seu navegador ou use o Postman ou o Curl para fazer uma solicitação GET ao seu endpoint /query/.
No seu navegador, através do Swagger:
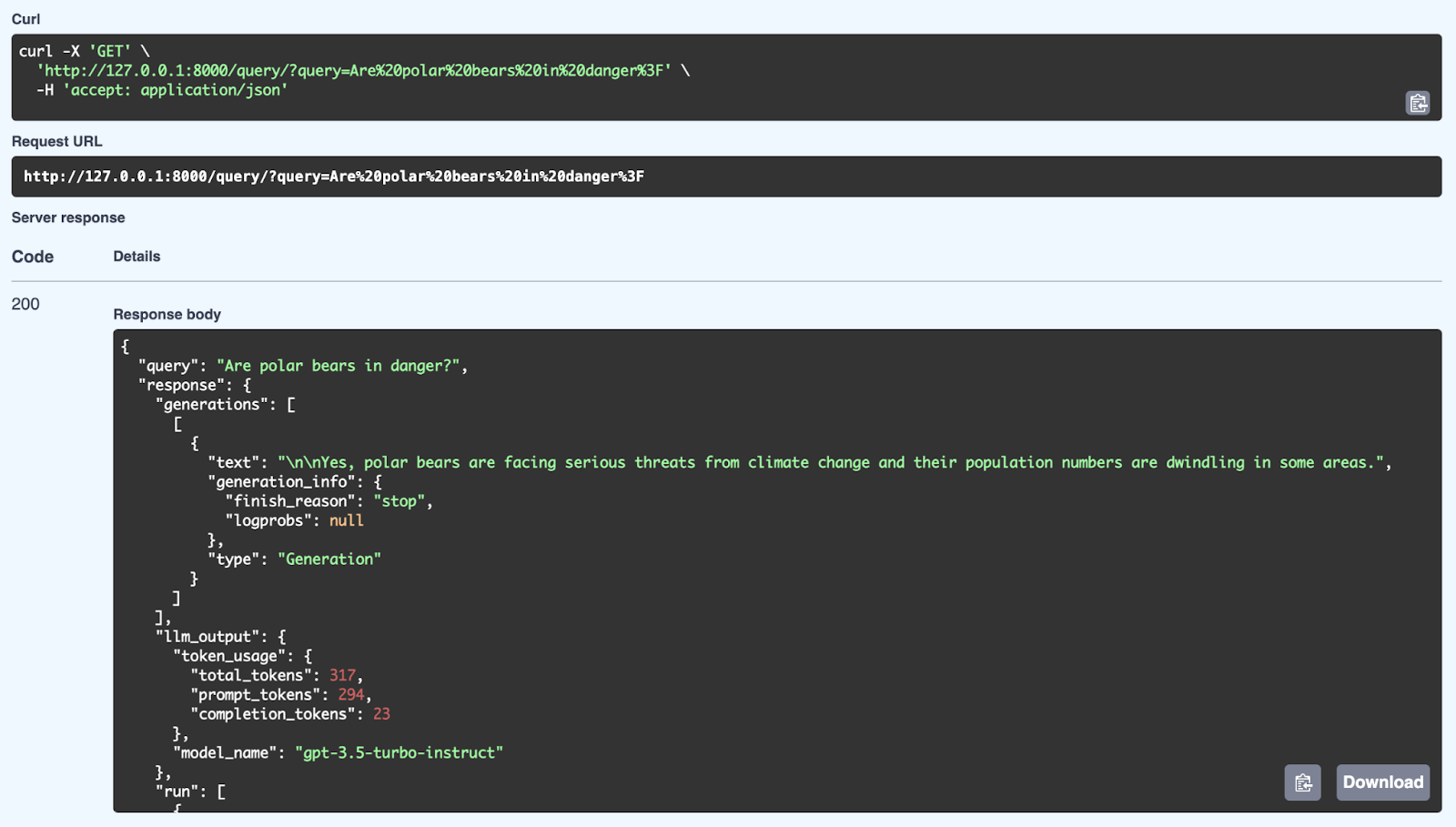
Aqui podemos ver uma resposta bem-sucedida do sistema RAG usando uma consulta: “Os ursos polares estão em perigo?”. O sistema pega as informações relevantes da sua base de conhecimento e cria uma resposta que faz sentido usando o modelo GPT-3.5 Turbo-Instruct. A resposta detalhada inclui não só a resposta (Sim, os ursos polares estão enfrentando sérias ameaças das mudanças climáticas e sua população está diminuindo), mas também metadados, como uso de tokens (número de tokens processados) e o modelo usado para geração. A API consegue dar respostas bem estruturadas e que entendem o contexto usando mecanismos de recuperação e geração através do FastAPI.
Vamos falar agora sobre as vantagens do processamento assíncrono no FastAPI e por que ele faz tanta diferença no tratamento dessas solicitações de API do mundo real.
Você já tem seu sistema RAG funcionando. A API está recebendo perguntas, pegando informações relevantes da sua base de conhecimento e, em seguida, gerando respostas com um modelo de linguagem.
Agora, se todo esse processo fosse síncrono, o sistema ficaria parado, esperando cada tarefa terminar antes de passar para a próxima. Por exemplo, enquanto estiver recuperando documentos, ele não poderá processar novas solicitações.
|
E/S sem bloqueio |
Desempenho melhorado |
Melhor experiência do usuário |
|
As funções assíncronas permitem que o servidor lide com várias solicitações ao mesmo tempo, em vez de esperar que uma termine antes de iniciar outra. |
Para tarefas como recuperar documentos de um armazenamento vetorial ou gerar texto, o processamento assíncrono garante que a API possa gerenciar cargas altas de forma eficiente. |
Os clientes recebem respostas mais rápidas e sua API continua ágil mesmo com uso intenso. |
Vamos falar sobre estratégias de implantação - uma etapa super importante pra transformar seu sistema RAG de um protótipo em um produto totalmente operacional. O objetivo aqui é garantir que seu sistema esteja empacotado, implantado e pronto para ser escalonado, para que possa lidar com usuários reais.
Primeiro, vamos falar sobre o Docker. O Docker é tipo uma caixa mágica que junta tudo o que seu sistema RAG precisa — seu código, dependências, configurações — e coloca tudo isso num pequeno contêiner bem organizado.
Isso garante que, onde quer que você implante seu aplicativo, ele funcione exatamente da mesma maneira. Você pode rodar seu aplicativo em diferentes ambientes, mas como ele está em um contêiner, não precisa se preocupar com o problema “funciona na minha máquina”.

Você cria um Dockerfile, que é um conjunto de instruções que diz ao Docker como configurar o ambiente do seu aplicativo, instalar os pacotes necessários e começar a rodar. Depois de fazer isso, você pode criar uma imagem Docker a partir dela e rodar seu aplicativo dentro de um contêiner. É eficiente, repetível e super portátil.
Agora, quando seu sistema estiver pronto, você provavelmente vai querer colocá-lo na nuvem. É aqui que fica interessante, porque colocar seu sistema RAG na nuvem significa que ele pode ser acessado de qualquer lugar do mundo. Além disso, oferece escalabilidade, confiabilidade e acesso a outros serviços em nuvem que podem impulsionar seu sistema.
Vamos dar uma olhada em mais algumas plataformas de nuvem populares, incluindo Azure e Google Cloud:
A AWS oferece ferramentas como o Elastic Beanstalk, que facilita muito a implantação. Basicamente, você entrega seu contêiner Docker e a AWS cuida do dimensionamento, do balanceamento de carga e do monitoramento. Se você precisar de mais controle, pode usar o Amazon ECS, que permite executar seus contêineres Docker em um cluster de servidores e dimensioná-los para cima ou para baixo, dependendo das suas necessidades.
O Heroku é outra opção que facilita a implantação. Você só precisa enviar seu código, e o Heroku cuida da infraestrutura pra você. É uma ótima opção se você não quer se aprofundar muito nos detalhes da gestão de recursos em nuvem.
O Azure oferece o Azure App Service, que permite implantar e gerenciar seu sistema RAG com facilidade, fornecendo suporte integrado para dimensionamento automático, balanceamento de carga e implantação contínua.
Pra ter mais flexibilidade, você pode usar o Azure Kubernetes Service (AKS) pra gerenciar seus contêineres Docker em escala, garantindo que seu sistema consiga lidar com tráfego intenso com a capacidade de ajustar recursos dinamicamente conforme necessário.
O GCP tem o Google Nuvem Run, uma plataforma totalmente gerenciada que permite implantar seus contêineres e dimensioná-los automaticamente com base no tráfego.
Se você quer ter mais controle sobre sua infraestrutura, pode usar o Google Kubernetes Engine (GKE), que te dá o poder de gerenciar e dimensionar seus contêineres Docker em vários nós, com a vantagem extra de uma integração profunda com os serviços em nuvem do Google, como APIs de IA e machine learning.
Cada plataforma tem seus pontos fortes, seja você quer simplicidade e automação ou um controle mais detalhado sobre sua implantação.
A gente falou de várias coisas nesse artigo, mostrando como criar um sistema RAG usando LangChain e FastAPI. Os sistemas RAG são um grande avanço no processamento de linguagem natural porque trazem informações de fora, dando à IA o poder de criar respostas mais precisas, relevantes e que entendem o contexto.
Com o LangChain, temos uma estrutura sólida que cuida de tudo, desde carregar documentos, dividir textos e criar embeddings até buscar informações com base nas consultas dos usuários.
Então, o FastAPI entra em cena para nos oferecer uma estrutura web rápida e pronta para assíncronia, ajudando-nos a implantar o sistema RAG como uma API escalável.
Juntas, essas ferramentas facilitam a criação de aplicativos de IA que podem lidar com consultas complexas, fornecer respostas precisas e, por fim, proporcionar uma melhor experiência ao usuário.
Agora, é hora de você pegar o que aprendeu e aplicar nos seus próprios projetos.
Pense nas possibilidades: consultar a base de conhecimento interna da sua própria empresa, automatizar processos de revisão de documentos ou criar chatbots inteligentes para suporte ao cliente.
Não esqueça: tem várias maneiras de expandir essa configuração! Você pode experimentar solicitações POST para enviar estruturas de dados mais complexas ou até mesmo explorar conexões WebSocket para interações em tempo real.
Te encorajo a ir mais fundo, experimentar e ver aonde isso pode te levar. Isso é só o começo do que você pode fazer com LangChain, FastAPI e as ferramentas modernas de IA! Aqui estão alguns recursos que eu recomendo:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Natassha Selvaraj
10 min
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Zoumana Keita

