
Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.2K
Die Retrieval-Augmented Generation (RAG) ist gerade eine der spannendsten Techniken in der KI. Es verbindet die Genauigkeit beim Abrufen echter Infos aus riesigen Datensätzen mit der Denkfähigkeit großer Sprachmodelle. Das Ergebnis? Antworten, die nicht nur richtig, sondern auch echt relevant sind. Deshalb macht RAG alles möglich, von Chatbots und Suchmaschinen bis hin zu personalisierten Inhalten.
Aber hier ist der Haken: Einen Prototyp zu bauen ist nur die halbe Miete. Die eigentliche Herausforderung istdie Umsetzung von„ “: deine Idee in ein zuverlässiges, skalierbares Produkt zu verwandeln.
In diesem Artikel zeige ich dir, wie du ein RAG-System mit LangChain und FastAPIaufbaust und einsetzt:. Du lernst, wie du von einem funktionierenden Prototyp zu einer vollwertigen Anwendung kommst, die für echte Nutzer bereit ist.
Los geht's!
Wie wir in einem separaten Leitfaden zeigen, Retrieval-Augmented Generationoder RAG, eine ziemlich fortschrittliche Methode in der natürlichen Sprachverarbeitung, die die Möglichkeiten von Sprachmodellen wirklich verbessert.
Anstatt sich nur auf das zu verlassen, was das Modell schon weiß, geht RAG noch einen Schritt weiter, indem es neue, relevante Infos aus externen Quellen einholt, bevor es eine Antwort generiert.
So läuft's: Wenn jemand eine Frage stellt, verlässt sich das System nicht nur auf die Daten, die das Modell vorher gelernt hat. Es geht erst mal los, durchsucht einen großen Satz von Dokumenten oder Datenquellen, schnappt sich die relevantesten Teile und speist diese dann in das Sprachmodell ein. Mit dem eingebauten Wissen und den neuen Infos kann das Modell eine Antwort erstellen, die viel genauer und aktueller ist.
RAG kombiniert das Abrufen und Generieren von Infos, sodass die Antworten nicht nur clever sind, sondern auch auf echten, sachlichen Infos basieren. Das macht es super für Sachen wie das Beantworten von Fragen, Chatbots oder sogar das Erstellen von Inhalten, wo es echt wichtig ist, die Fakten richtig zu haben und den Kontext zu verstehen.
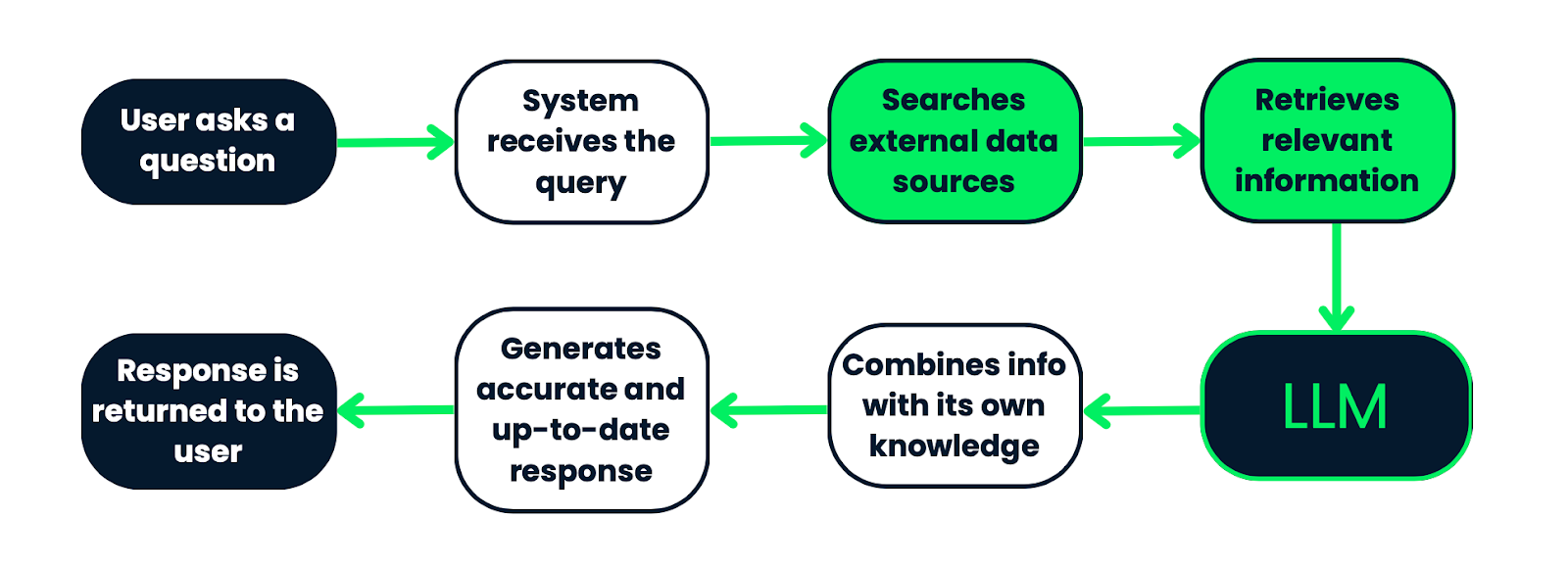
Wie ein RAG-System funktioniert. Es fängt mit einer Anfrage vom Nutzer an, die vom System bearbeitet wird, um externe Datenquellen nach relevanten Infos zu durchsuchen. Die gefundenen Infos werden dann in ein LLM eingespeist, das sie mit seinem vorhandenen Wissen kombiniert, um eine genaue und aktuelle Antwort zu generieren. Schließlich wird die Antwort an den Nutzer zurückgeschickt. Dieser Prozess stellt sicher, dass die Antworten auf tatsächlichen, kontextbezogenen Daten basieren.
Wenn du ein RAG-System aufbaust, gibt es ein paar wichtige Teile, die man braucht, um es zum Laufen zu bringen: Dokumentenlader, Texttrennung, Indizierung, Abrufmodelle und generative Modelle. Lass uns das mal genauer anschauen:
Der erste Schritt ist, deine Daten fertig zu machen. Genau das machen Dokumentenlader, Texttrennung und Indizierung:
Das ist das Herzstück des RAG-Systems. Die Leute sind dafür zuständig, alle diese indexierten Daten zu durchsuchen, um das zu finden, was du brauchst.
Jetzt wird's spannend. Sobald die relevanten Daten abgerufen sind, übernehmen die generativen Modelle und erstellen eine endgültige Antwort.
|
Komponente |
Beschreibung |
|
Dokumentenlader |
Hol dir Daten aus Quellen wie Textdateien, PDFs oder Datenbanken und mach die Infos in ein Format um, das das System nutzen kann. |
|
Texttrennung |
Chops packt Daten in kleinere Teile, was das Suchen und Verarbeiten innerhalb der Grenzen von Sprachmodellen einfacher macht. |
|
Indexierung |
Organisiert geteilte Daten in Vektordarstellungen, was schnelle und effiziente Suchvorgänge ermöglicht, um relevante Infos für eine Anfrage zu finden. |
|
Vektor-Shops |
Spezielle Datenbanken, die Vektordarstellungen speichern und mit Hilfe der Vektorähnlichkeitssuche die relevantesten Infos basierend auf der Suchanfrage finden. |
|
Retriever |
Suchkomponenten, die die Abfrage in einen Vektor umwandeln, den Vektorspeicher durchsuchen und die relevantesten Datenblöcke für den nächsten Schritt abrufen. |
|
Sprachmodelle |
Erstelle zusammenhängende und passende Antworten, indem du sowohl die gefundenen Daten als auch dein eigenes Wissen nutzt. |
|
Kontextbezogene Antwortgenerierung |
Kombiniert die Frage des Benutzers mit den gefundenen Daten, um eine ausführliche Antwort zu erstellen, die die Frage beantwortet und gleichzeitig die relevanten Infos enthält. |
Bevor wir unser RAG-System aufbauen, müssen wir sicherstellen, dass unsere Entwicklungsumgebung richtig eingerichtet ist. Hier ist, was du brauchst:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsInstalliere Abhängigkeiten: Jetzt installierst du die benötigten Pakete mit pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
Ein modernes Web-Framework zum Erstellen von APIs. |
Ein ASGI-Server für deine FastAPI-App. |
Die Hauptbibliothek, die das RAG-System unterstützt. |
GPT-Modelle für die Antwortgenerierung nutzen. |
Profi-Tipp-: Mach mal eine Datei namens requirements.txt, um die Pakete zu spezifizieren, die du für dein Projekt brauchst. Wenn du benutzt: pip freeze > requirements.txt
Dieser Befehl erstellt eine Datei namens „requirements.txt“, die alle installierten Pakete und ihre Versionen enthält. Diese Datei kannst du für die Bereitstellung oder zum Teilen der Umgebung mit anderen nutzen.
Füge deinen OpenAI-API-Schlüssel hinzu: Um das OpenAI-Sprachmodell in dein RAG-System einzubauen, musst du deinen OpenAI-API-Schlüssel angeben:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Jetzt ist dein OpenAI-API-Schlüssel sicher aus der Umgebung geladen und du kannst ihn in deinem RAG-System verwenden!
PostgreSQL und PGVector (optional): Wenn du vorhast, PGVector für die Vektorspeicherung zu nutzen, musst du PostgreSQL auf deinem Rechner installieren und einrichten. Du kannst FAISS (das wir in diesem Artikel verwenden werden) oder andere Vektordatenbanken nutzen, die LangChain unterstützt.
Docker (optional): Docker kann dir dabei helfen, deine Anwendung zu containerisieren, um eine konsistente Bereitstellung in verschiedenen Umgebungen sicherzustellen. Wenn du vorhast, Docker zu nutzen, stell sicher, dass es auch auf deinem Rechner installiert ist.
Der erste Schritt beim Aufbau eines RAG-Systems ist, die Daten vorzubereiten, die das System zum Abrufen relevanter Infos nutzen wird. Dazu muss man Dokumente ins System laden, bearbeiten und dann sicherstellen, dass sie in einem Format vorliegen, das einfach indexiert und abgerufen werden kann.
LangChain hat verschiedene Dokumentenlader, um mit unterschiedlichen Datenquellen wie Textdateien, PDFs oder Webseiten klarzukommen. Du kannst diese Loader nutzen, um deine Dokumente ins System zu laden.
Ich finde Eisbären echt spannend, deshalb habe ich beschlossen, die folgende Textdatei (my_document.txt) mit diesen Infos hochzuladen:„Eisbären: Die Giganten der Arktis
Eisbären (Ursus maritimus) sind die größten Landraubtiere auf der Erde und haben sich perfekt an das Leben in der extremen Kälte der Arktis angepasst. Bekannt für ihr dickes weißes Fell, mit dem sie sich gut in die verschneite Landschaft einfügen, sind Eisbären starke Jäger, die auf Meereis angewiesen sind, um Robben zu jagen, ihre Hauptnahrungsquelle.
Das Faszinierende an Eisbären ist, wie unglaublich gut sie sich an ihre Umgebung anpassen können. Unter dem dicken Fell ist eine Fettschicht, die bis zu 11 cm dick sein kann und im kalten Winter für Isolierung und Energiereserven sorgt. Ihre großen Pfoten helfen ihnen, sowohl über Eis als auch über offenes Wasser zu laufen, was sie zu starken Schwimmern macht – sie können auf der Suche nach Futter oder neuen Revieren große Entfernungen zurücklegen.
Leider sind Eisbären durch den Klimawandel echt gefährdet. Da es in der Arktis wärmer wird, schmilzt das Meereis jetzt früher im Jahr und bildet sich später, sodass die Eisbären weniger Zeit haben, um Robben zu jagen. Ohne genug Futter haben viele Bären echt Probleme zu überleben, und in manchen Gegenden werden sie immer weniger.
Eisbären sind echt wichtig für die Gesundheit des arktischen Ökosystems, und ihre schwierige Lage zeigt uns deutlich, wie der Klimawandel die Tierwelt auf der ganzen Welt beeinflusst. Es gibt Naturschutzmaßnahmen, um ihren Lebensraum zu schützen und sicherzustellen, dass diese coolen Tiere weiterhin in freier Wildbahn leben können.
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Hier ist eine einfache Textdatei, die ich als Beispiel ins System geladen habe, aber du kannst echt jedes Dokument hinzufügen, das du willst! Du kannst zum Beispiel interne Unterlagen aus deiner Organisation hinzufügen. Die Variable „documents“ enthält jetzt den Inhalt der Datei, der verarbeitet werden kann.
Große Dokumente werden oft in kleinere Teile aufgeteilt, damit man sie leichter indexieren und wiederfinden kann. Dieser Prozess ist echt wichtig, weil kleinere Teile für das Sprachmodell einfacher zu verarbeiten sind und ein genaueres Abrufen ermöglichen. Mehr Infos findest du in unserem Leitfaden zu Chunking-Strategien für KI und RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Hier wird der Text in Blöcke von 500 Zeichen aufgeteilt, wobei sich die Blöcke um 50 Zeichen überlappen. Diese Überlappung hilft dabei, den Kontext zwischen den einzelnen Blöcken beim Abruf beizubehalten.
Sobald die Daten fertig sind, geht's weiter mit dem Indexieren, damit man sie später schnell finden kann. Beim Indexieren werden Textabschnitte in Vektor-Einbettungen umgewandelt und in einem Vektorspeicher abgelegt.
LangChain hilft dir dabei, Vektor-Embeddings mit verschiedenen Modellen zu erstellen, wie zum Beispiel OpenAI- oder HuggingFace-Modellen. Diese Einbettungen zeigen die Bedeutung der Textabschnitte und sind deshalb super für Ähnlichkeitssuchen.
Einfach gesagt, sind Einbettungen im Grunde eine Methode, um Text, wie zum Beispiel einen Absatz aus einem Dokument, in Zahlen umzuwandeln, die ein KI-Modell verstehen kann. Diese Zahlen oder Vektoren zeigen die Bedeutung des Textes so, dass KI-Systeme ihn besser verstehen können.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Wir nutzen die Embeddings von OpenAI, um diese Umwandlung zu machen. Zuerst holen wir uns das Einbettungstool von OpenAI rein und machen es startklar, damit es einsatzbereit ist.
Nachdem die Einbettungen erstellt wurden, speicherst du sie in einem Vektorspeicher wie PGVector, FAISS oder einem anderen, der von LangChain unterstützt wird. So kannst du relevante Dokumente schnell und genau finden, wenn du eine Anfrage machst.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)In diesem Fall benutzen wir FAISS, ein super Tool, das für die Suche in großen Vektorsätzen entwickelt wurde. FAISS hilft uns, die ähnlichsten Vektoren echt schnell zu finden.
Also, hier ist, was gerade los ist: Wir holen uns FAISS von LangChain und machen damit einen sogenannten Vektorspeicher. Es ist wie eine spezielle Datenbank, die entwickelt wurde, um Vektoren effizient zu speichern und zu durchsuchen.
Das Coole an dieser Konfiguration ist, dass FAISS bei einer späteren Suche alle diese Vektoren durchsuchen, die ähnlichsten zu einer bestimmten Suchanfrage finden und die entsprechenden Dokumentteile zurückgeben kann.
Nachdem die Daten indexiert sind, kannst du jetzt die Suchkomponente einrichten, die dafür zuständig ist, relevante Infos basierend auf den Suchanfragen der Nutzer zu finden.
Jetzt richten wir einen Retriever ein. Das ist die Komponente, die die indizierten Dokumente durchsucht und die für die Anfrage eines Benutzers relevantesten Dokumente findet.
Das Coole daran ist, dass du nicht einfach nur wahllos suchst, sondern mit der Kraft von Embeddings clever suchst, sodass die Ergebnisse, die du bekommst, dem, was der Nutzer sucht, semantisch ähnlich sind. Schauen wir uns mal die Codezeile genauer an:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Zuerst machen wir aus dem Vektorspeicher einen Retriever. Weißt du noch, dass du diesen FAISS-Vektor-Speicher mit Dokument-Einbettungen schon hast? Also, jetzt sagen wir: „Hey, mach ruhig und such damit nach Sachen, wenn ein Nutzer mir eine Frage stellt.“
Jetzt passiert das Besondere bei search_type. Der Retriever kann auf verschiedene Arten suchen, und du hast hier ein paar Optionen. Die Ähnlichkeitssuche ist das A und O der Informationsgewinnung. Es wird überprüft, welche Dokumente der Suchanfrage am ehesten entsprechen.
Wenn du also „search_type=‚similarity‘“ sagst, sagst du dem Retriever: „Finde Dokumente, die der Anfrage auf der Grundlage der von uns generierten Einbettungen am ähnlichsten sind.“
Mit search_kwargs={"k": 5} Du feinjustierst die Dinge. Der k-Wert sagt dem Retriever, wie viele Dokumente er aus dem Vektorspeicher holen soll. In diesem Fall heißt k=5: „Gib mir die fünf relevantesten Dokumente.“
Das ist echt super, weil es hilft, das Rauschen zu reduzieren. Statt eine Menge Ergebnisse zu kriegen, die vielleicht irgendwie relevant sind, holst du dir nur die wichtigsten Infos.
In diesem Teil des Codes richten wir die Kern-Engine deines RAG-Systems mit LangChain ein. Du hast schon deinen Retriever, der anhand einer Suchanfrage die passenden Dokumente rausholen kann.
Jetzt fügen wir das LLM hinzu und nutzen es, um die Antwort anhand der gefundenen Dokumente zu erstellen.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQAHier importieren wir zwei wichtige Sachen:
llm = OpenAI(openai_api_key=openai_api_key)Diese Zeile startet das LLM mit deinem OpenAI-API-Schlüssel. Stell dir das so vor, als würdest du das Gehirn deines Systems laden – es ist das Modell, das Texte aufnimmt, versteht und Antworten generiert.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Jetzt wird's richtig spannend. Wir bauen die QA-Kette auf, die alles zusammenhält. Die Methode RetrievalQA.from_chain_type() baut eine Frage-Antwort-Kette auf, was so viel heißt wie: „Kombiniere den Retriever und das LLM, um ein System zu erstellen, das Fragen anhand der gefundenen Dokumente beantwortet.“
Dann sagen wir der Kette, dass sie das gerade initialisierte OpenAI LLM nutzen soll, um Antworten zu generieren. Danach schließen wir den Retriever an, den du vorher gebaut hast. Der Retriever sucht die passenden Dokumente anhand der Anfrage des Benutzers.
Dann setzen wir chain_type="stuff": Okay, was ist hier mit „Zeug“ gemeint? Es ist eigentlich eine Art Kette in LangChain. „Stuff“ heißt, dass wir alle relevanten Dokumente, die wir gefunden haben, in das LLM laden und es dann eine Antwort auf der Grundlage von allem generieren lassen.
Das ist so, als würde man einen Haufen Notizen auf den Schreibtisch des LLM werfen und sagen: „Hier, benutz all diese Infos, um die Frage zu beantworten.“
Es gibt auch andere Kettentypen (wie „map_reduce” oder „refine”), aber „stuff” ist der einfachste und direkteste.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Hier stellen wir dem System tatsächlich eine Frage und kriegen eine Antwort zurück. Die Methode invoke() startet die ganze Pipeline.
Es nimmt deine Anfrage, schickt sie an den Retriever, um passende Dokumente zu finden, und gibt diese Dokumente dann an das LLM weiter, das die endgültige Antwort erstellt.
print(response)Das letzte druckt die Antwort, die vom LLM generiert wurde. Basierend auf den gefundenen Dokumenten macht das System eine komplette, gut recherchierte Antwort auf die Anfrage, die dann ausgedruckt wird.
Das endgültige Skript sieht so aus:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Jetzt ist es an der Zeit, eine API zu erstellen, um mit deinem RAG-System zu interagieren. Aber warum ist dieser Schritt bei der Bereitstellung überhaupt nötig?
Stell dir vor, du hast dieses Tutorial durchgemacht und jetzt dieses coole RAG-System, das genau auf deine Dokumente und Bedürfnisse zugeschnitten ist – es sammelt relevante Infos, verarbeitet Anfragen und gibt clevere Antworten. Aber wie lässt du eigentlich Benutzer oder andere Systeme damit interagieren?
FastAPI ist dein Mittelsmann. Es bietet eine einfache, strukturierte Möglichkeit für Nutzer oder Apps, deinem RAG-System Fragen zu stellen und Antworten zu bekommen.
FastAPI ist asynchron und super leistungsstark. Das heißt, es kann viele Anfragen gleichzeitig bearbeiten, ohne langsamer zu werden, was bei KI-Systemen, die möglicherweise große Datenmengen abrufen oder komplexe Abfragen ausführen müssen, super wichtig ist.
In diesem Abschnitt ändern wir das vorherige Skript und erstellen neue, damit dein RAG-System zugänglich und skalierbar ist und den tatsächlichen Datenverkehr bewältigen kann.Lass uns damit anfangen, die Routen zu erstellen, die eingehende Anfragen an das RAG-System bearbeiten werden.
Mach in deinem Arbeitsverzeichnis eine Datei namens „ main.py “. Das ist dein Einstiegspunkt für die FastAPI-App. Das wird dein FastAPI-Gehirn sein – diese Datei wird alle API-Routen, Abhängigkeiten und das RAG-System zusammenführen.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)Das ist ein ziemlich einfaches Setup, aber es ist übersichtlich. Wir richten hier eine FastAPI-Instanz ein und holen dann alle Routen (oder API-Pfade) aus einer anderen Datei rein, die wir als Nächstes erstellen werden.
Hier kommt also alles zusammen. Wir schreiben jetzt eine Funktion, die dein RAG-System tatsächlich ausführt, wenn ein Benutzer eine Anfrage sendet.
async def get_rag_response(query: str):Diese Funktion ist als „ async “ markiert, was bedeutet, dass sie asynchron ist. Das heißt, es kann andere Sachen erledigen, während es auf eine Antwort wartet.
So eine Funktion ist besonders praktisch, wenn du mit abrufbasierten Systemen arbeitest, bei denen das Abrufen von Dokumenten oder das Abfragen eines LLM eine Weile dauern kann. So kann FastAPI andere Anfragen bearbeiten, während diese im Hintergrund läuft.
retriever = setup_rag_system()Hier rufen wir die Funktion „ setup_rag_system() “ auf, die, wie wir schon gesagt haben, die ganze Retriever-Pipeline startet. Das heißt:
Dieser Retriever holt die passenden Textteile, die zur Anfrage des Nutzers passen.
Wenn jetzt jemand eine Frage stellt, checkt der Retriever alle Dokumente im Vektorspeicher und holt die raus, die am besten zur Frage passen.
retrieved_docs = retriever.get_relevant_documents(query)Die Methode „ invoke(query) “ ruft die entsprechenden Dokumente ab. Im Hintergrund wird die Suchanfrage mit den Einbettungsvektoren abgeglichen und die besten Treffer werden nach Ähnlichkeit rausgesucht.
Jetzt, wo wir die wichtigen Dokumente haben, müssen wir sie für das LLM formatieren.
context = "\n".join([doc.page_content for doc in retrieved_docs])Hier packen wir alle gefundenen Dokumente zusammen und machen aus ihrem Inhalt eine einzige Zeichenfolge. Das ist wichtig, weil das LLM einen sauberen Textblock zum Arbeiten braucht und nicht viele einzelne Teile.
Wir benutzen die Python-Funktion „ join() “, um diese Dokumentteile zu einem zusammenhängenden Informationsblock zusammenzufügen. Der Inhalt jedes Dokuments wird im Feld „ doc.page_content “ gespeichert, und wir verbinden sie mit neuen Zeilen (\n).
Jetzt machen wir die Eingabeaufforderung für das LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]Die Eingabeaufforderung ist so aufgebaut, dass das LLM die gefundenen Infos nutzen soll, um die Frage des Benutzers zu beantworten.
Jetzt ist es an der Zeit, eine Antwort zu geben.
generated_response = llm.generate(prompt) # Pass as a list of stringsHier soll das OpenAI-Modell jetzt die Eingabe nehmen und eine kontextbezogene Antwort machen, die sowohl auf der Frage als auch auf den relevanten Dokumenten basiert.
Schließlich schicken wir die erzeugte Antwort an denjenigen zurück, der die Funktion aufgerufen hat (egal ob das ein Benutzer, eine Frontend-App oder ein anderes System ist).
return generated_responseDiese Antwort ist komplett ausgearbeitet, passt zum Kontext und kann direkt in echten Anwendungen genutzt werden.
Kurz gesagt, diese Funktion macht die ganze Abfrage- und Generierungsschleife. Hier eine kurze Zusammenfassung des Ablaufs:
1. Es richtet den Retriever ein, um relevante Dokumente zu finden.
2. Die Dokumente werden anhand der Abfrage rausgesucht.
3. Der Kontext aus diesen Dokumenten ist für den LLM vorbereitet.
4. Der LLM macht eine endgültige Antwort mit diesem Kontext.
5. Die Antwort wird an den Nutzer zurückgeschickt.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyAls Nächstes erstellen wir unsere Datei „ endpoints.py “. Hier legen wir die tatsächlichen Pfade fest, die Benutzer aufrufen, um mit deinem RAG-System zu interagieren.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Wir erstellen ein „ APIRouter “, um unsere API-Routen zu verwalten. Der Endpunkt „ /query/ “ ist so eingerichtet, dass er eine **GET**-Anfrage mit einer Abfragezeichenfolge akzeptiert. Es ruft die Funktion „ get_rag_response ” aus deiner Datei „ rag.py ” auf, die die ganze RAG-Pipeline (Dokumentabruf + Sprachgenerierung) abwickelt. Wenn was schiefgeht, schicken wir einen HTTP-500-Fehler mit einer detaillierten Meldung.
Jetzt kannst du deine FastAPI-App mit Uvicorn starten. Das ist der Webserver, über den Leute auf deine API zugreifen können.
Geh zum Terminal und gib Folgendes ein:
uvicorn app.main:app --reloadapp.main:app sagt Uvicorn, dass es nach der Instanz „ app ” in der Datei „ main.py ” suchen soll, und „ --reload ” aktiviert das automatische Neuladen, wenn du Änderungen an deinem Code vornimmst.
Sobald der Server läuft, öffne deinen Browser und geh zu http://127.0.0.1:8000/docs. FastAPI macht automatisch eine Swagger-UI-Dokumentation für deine API, sodass du sie direkt in deinem Browser ausprobieren kannst!
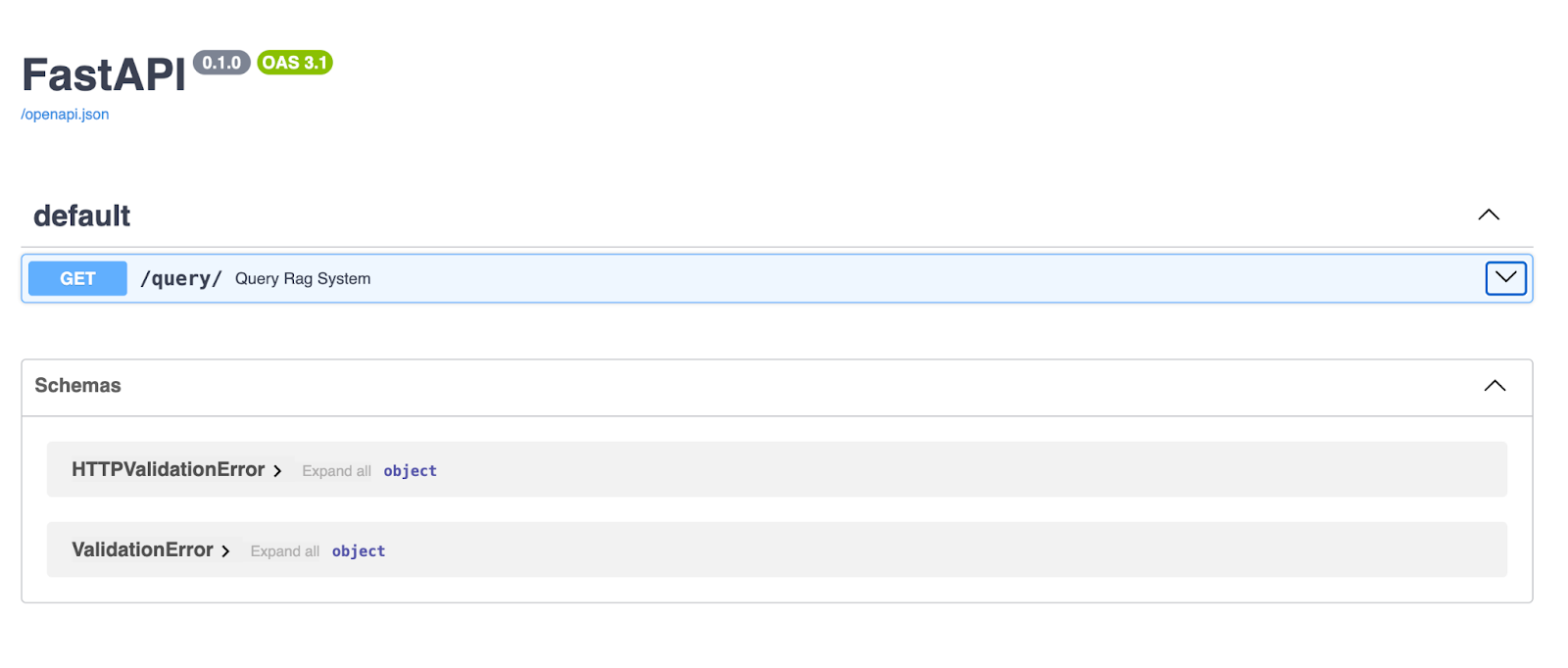
Die FastAPI Swagger UI bietet eine übersichtliche und interaktive Oberfläche zum Erkunden und Testen deiner API-Endpunkte. Hier können Leute über den Endpunkt /query/ eine Abfrage eingeben und kriegen dann eine Antwort, die von der RAG-Pipeline generiert wird.
Wenn dein FastAPI-Server läuft, öffne deinen Browser oder benutze Postman oder Curl, um eine GET-Anfrage an deinen Endpunkt „ /query/ “ zu senden.
In deinem Browser über Swagger:
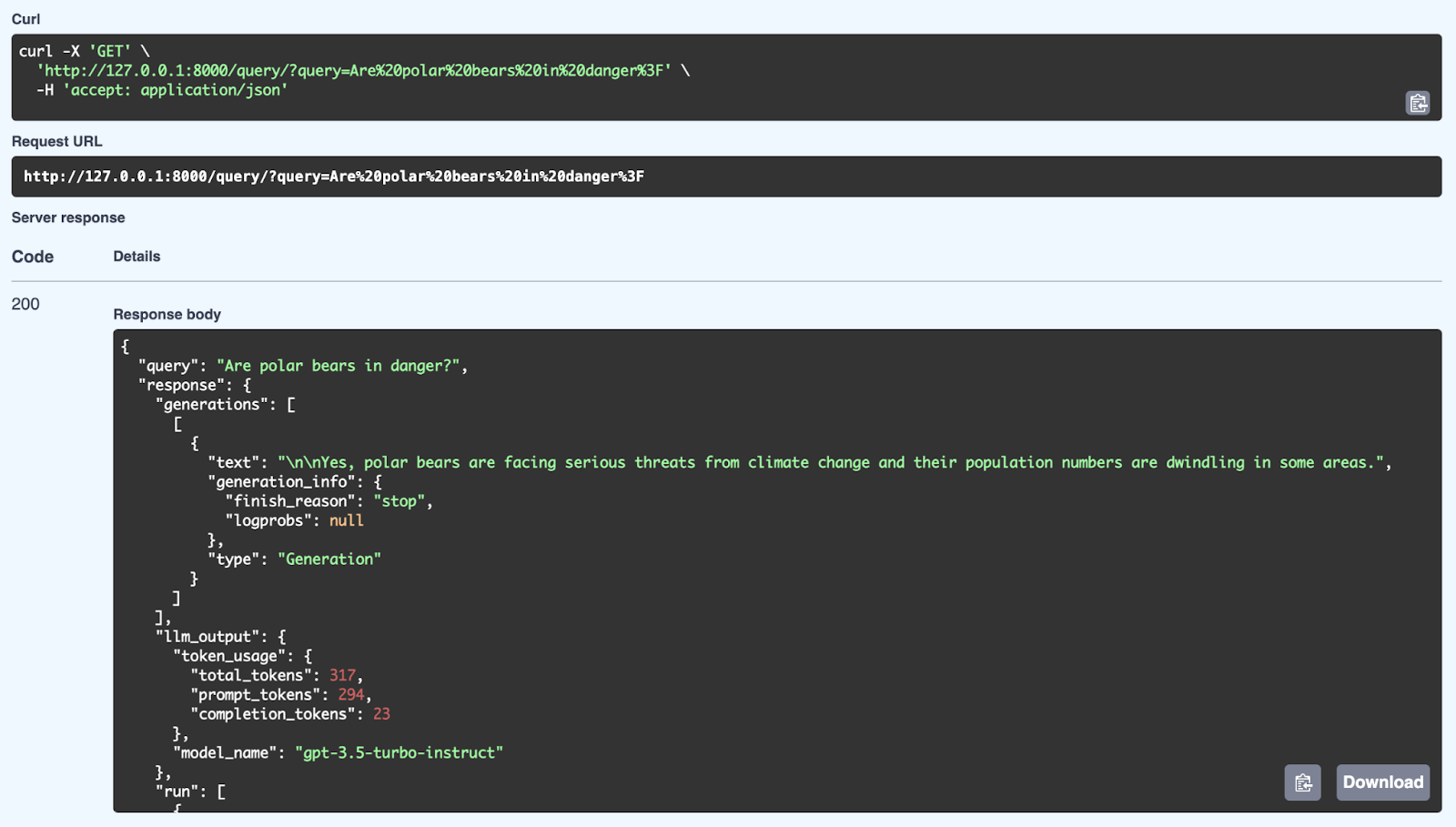
Hier sehen wir eine erfolgreiche Antwort vom RAG-System, die eine Abfrage benutzt: „Sind Eisbären in Gefahr?“ Das System holt sich relevante Infos aus seiner Wissensdatenbank und macht dann mit dem GPT-3.5 Turbo-Instruct-Modell eine passende Antwort. Die ausführliche Antwort enthält nicht nur die Antwort (Ja, Eisbären sind durch den Klimawandel ernsthaft bedroht und ihre Populationen gehen zurück), sondern auch Metadaten wie die Token-Verwendung (Anzahl der verarbeiteten Token) und das für die Generierung verwendete Modell. Die API kann gut strukturierte, kontextbezogene Antworten liefern, indem sie sowohl Abruf- als auch Generierungsmechanismen über FastAPI nutzt.
Lass uns jetzt mal über die Vorteile der asynchronen Verarbeitung in FastAPI quatschen und warum sie bei der Bearbeitung von echten API-Anfragen so einen großen Unterschied macht.
Du hast dein RAG-System eingerichtet und es läuft. Die API nimmt Fragen entgegen, holt sich relevante Infos aus ihrer Wissensdatenbank und erstellt dann Antworten mit einem Sprachmodell.
Wenn der ganze Prozess synchron wäre, würde das System einfach da sitzen und warten, bis jede Aufgabe fertig ist, bevor es mit der nächsten weitermacht. Während es zum Beispiel Dokumente abruft, kann es keine neuen Anfragen bearbeiten.
|
Nicht blockierende E/A |
Verbesserte Leistung |
Bessere Benutzererfahrung |
|
Mit asynchronen Funktionen kann der Server mehrere Anfragen gleichzeitig bearbeiten, anstatt zu warten, bis eine Anfrage abgeschlossen ist, bevor die nächste gestartet wird. |
Bei Aufgaben wie dem Abrufen von Dokumenten aus einem Vektorspeicher oder dem Generieren von Text sorgt die asynchrone Verarbeitung dafür, dass die API hohe Lasten effizient bewältigen kann. |
Kunden kriegen schnellere Antworten, und deine API bleibt auch bei hoher Auslastung reaktionsschnell. |
Reden wir mal über Einsatzstrategien – ein echt wichtiger Schritt, um dein RAG-System von einem Prototyp zu einem voll funktionsfähigen Produkt zu machen. Das Ziel ist, dass dein System so verpackt, bereitgestellt und skalierbar ist, dass es echte Nutzer bewältigen kann.
Zuerst mal reden wir über Docker-. Docker ist wie eine Zauberkiste, die alles, was dein RAG-System braucht – seinen Code, Abhängigkeiten, Konfigurationen – zusammenpackt und in einen ordentlichen kleinen Container steckt.
So stellst du sicher, dass deine App überall, wo du sie einsetzt, genau gleich funktioniert. Du kannst deine App in verschiedenen Umgebungen ausführen, aber da sie in einem Container läuft, musst du dir keine Gedanken über das Problem „Auf meinem Rechner funktioniert es“ machen.

Du erstellst eine Dockerfile, also eine Reihe von Anweisungen, die Docker sagen, wie die Umgebung deiner App eingerichtet, die notwendigen Pakete installiert und die Ausführung gestartet werden soll. Sobald das erledigt ist, kannst du daraus ein Docker-Image erstellen und deine Anwendung in einem Container ausführen. Es ist effizient, wiederholbar und super tragbar.
Sobald dein System fertig gepackt und einsatzbereit ist, wirst du es wahrscheinlich in der Cloud bereitstellen wollen. Jetzt wird's spannend, denn wenn du dein RAG-System in der Cloud einsetzt, kannst du von überall auf der Welt drauf zugreifen. Außerdem bekommst du damit Skalierbarkeit, Zuverlässigkeit und Zugriff auf andere Cloud-Dienste, die dein System aufpeppen können.
Schauen wir uns noch ein paar beliebte Cloud-Plattformen an, darunter Azure und Google Cloud:
AWS bietet Tools wie Elastic Beanstalk, die die Bereitstellung echt einfach machen. Du gibst im Grunde deinen Docker-Container ab, und AWS kümmert sich um Skalierung, Lastenausgleich und Überwachung. Wenn du mehr Kontrolle brauchst, kannst du Amazon ECS nutzen. Damit kannst du deine Docker-Container auf einem Servercluster laufen lassen und je nach Bedarf hoch- oder herunterskalieren.
Heroku ist eine weitere Option, die die Bereitstellung einfacher macht. Du musst nur deinen Code hochladen, und Heroku kümmert sich um die Infrastruktur für dich. Das ist eine super Wahl, wenn du dich nicht zu sehr mit den Details der Verwaltung von Cloud-Ressourcen beschäftigen willst.
Azure bietet Azure App Service, mit dem du dein RAG-System einfach bereitstellen und verwalten kannst. Es bietet integrierte Unterstützung für automatische Skalierung, Lastenausgleich und kontinuierliche Bereitstellung.
Für mehr Flexibilität kannst du Azure Kubernetes Service (AKS) nutzen, um deine Docker-Container in großem Maßstab zu verwalten. So stellst du sicher, dass dein System hohen Datenverkehr bewältigen kann, indem du Ressourcen nach Bedarf dynamisch anpasst.
GCP hat Google Cloud Run, eine komplett verwaltete Plattform, mit der du deine Container bereitstellen und je nach Traffic automatisch skalieren kannst.
Wenn du mehr Kontrolle über deine Infrastruktur haben willst, kannst du dich für Google Kubernetes Engine (GKE) entscheiden. Damit kannst du deine Docker-Container über mehrere Knoten hinweg verwalten und skalieren und hast den zusätzlichen Vorteil einer tiefen Integration mit den Cloud-Diensten von Google wie KI- und Machine-Learning-APIs.
Jede Plattform hat ihre Vorteile, egal ob du es einfach und automatisch haben willst oder lieber mehr Kontrolle über deine Bereitstellung haben möchtest.
In diesem Artikel haben wir viel behandelt und sind den Prozess der Erstellung eines RAG-Systems mit LangChain und FastAPI durchgegangen. RAG-Systeme sind ein riesiger Schritt vorwärts in der Verarbeitung natürlicher Sprache, weil sie externe Infos einbeziehen und der KI die Möglichkeit geben, genauere, relevantere und kontextbezogene Antworten zu generieren.
Mit LangChain haben wir ein solides Framework, das alles abdeckt, vom Laden von Dokumenten über das Aufteilen von Text und das Erstellen von Einbettungen bis hin zum Abrufen von Infos basierend auf Nutzeranfragen.
Dann kommt FastAPI ins Spiel und gibt uns ein schnelles, asynchronfähiges Web-Framework, das uns dabei hilft, das RAG-System als skalierbare API einzusetzen.
Zusammen machen diese Tools es einfacher, KI-Anwendungen zu entwickeln, die komplexe Anfragen bearbeiten, präzise Antworten liefern und letztendlich eine bessere Benutzererfahrung bieten können.
Jetzt ist es an der Zeit, dass du das Gelernte nutzt und in deinen eigenen Projekten anzuwenden.
Stell dir mal vor, was alles möglich wäre: die interne Wissensdatenbank deines Unternehmens abfragen, Dokumentenprüfungsprozesse automatisieren oder intelligente Chatbots für den Kundensupport erstellen.
Vergiss nicht – es gibt so viele Möglichkeiten, dieses Setup zu erweitern! Du kannst mit POST-Anfragen experimentieren, um komplexere Datenstrukturen zu senden, oder sogar WebSocket-Verbindungen für Echtzeit-Interaktionen ausprobieren.
Ich ermutige dich, tiefer zu graben, zu experimentieren und zu sehen, wohin dich das führen kann. Das ist erst der Anfang von dem, was du mit LangChain, FastAPI und modernen KI-Tools machen kannst! Hier sind ein paar Ressourcen, die ich dir empfehlen kann:
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Laiba Siddiqui
Tutorial
Sejal Jaiswal
Tutorial
Mark Pedigo
Tutorial
DataCamp Team
