
Courses
Phát triển ứng dụng LLM với LangChain
3 giờ
47.9K
Retrieval-Augmented Generation (RAG) là một trong những kỹ thuật thú vị nhất trong AI hiện nay. Nó kết hợp độ chính xác của việc truy xuất thông tin thực từ các tập dữ liệu khổng lồ với khả năng suy luận của các mô hình ngôn ngữ lớn. Kết quả? Câu trả lời không chỉ chính xác mà còn cực kỳ phù hợp. Đó là lý do RAG đang cung cấp sức mạnh cho mọi thứ từ chatbot, công cụ tìm kiếm đến nội dung cá nhân hóa.
Nhưng có một điểm cần lưu ý: xây dựng nguyên mẫu chỉ là nửa chặng đường. Thử thách thực sự nằm ở triển khai: biến ý tưởng của bạn thành một sản phẩm đáng tin cậy, có khả năng mở rộng.
Trong bài viết này, tôi sẽ hướng dẫn bạn cách xây dựng và triển khai một hệ thống RAG sử dụng LangChain và FastAPI. Bạn sẽ học cách đi từ một nguyên mẫu hoạt động đến một ứng dụng hoàn chỉnh, sẵn sàng cho người dùng thực.
Hãy bắt đầu!
Như chúng tôi đã trình bày trong một hướng dẫn riêng, Retrieval-Augmented Generation, hay RAG, là một phương pháp khá tiên tiến trong xử lý ngôn ngữ tự nhiên, thực sự nâng tầm khả năng của các mô hình ngôn ngữ.
Thay vì chỉ dựa vào những gì mô hình đã biết, RAG tiến xa hơn bằng cách kéo vào thông tin mới, phù hợp từ các nguồn bên ngoài trước khi tạo câu trả lời.
Cách hoạt động như sau: khi người dùng đặt câu hỏi, hệ thống không chỉ dựa vào dữ liệu đã học sẵn của mô hình. Nó sẽ ra ngoài, tìm kiếm trong một tập lớn tài liệu hoặc nguồn dữ liệu, lấy những phần liên quan nhất, rồi đưa chúng vào mô hình ngôn ngữ. Với cả kiến thức sẵn có và thông tin vừa truy xuất, mô hình có thể tạo ra câu trả lời chính xác và cập nhật hơn nhiều.
RAG pha trộn giữa truy xuất và sinh, vì vậy các câu trả lời không chỉ thông minh—mà còn có cơ sở trên thông tin thực tế. Điều này khiến nó lý tưởng cho những tác vụ như trả lời câu hỏi, chatbot, hoặc thậm chí tạo nội dung nơi độ chính xác và hiểu bối cảnh rất quan trọng.
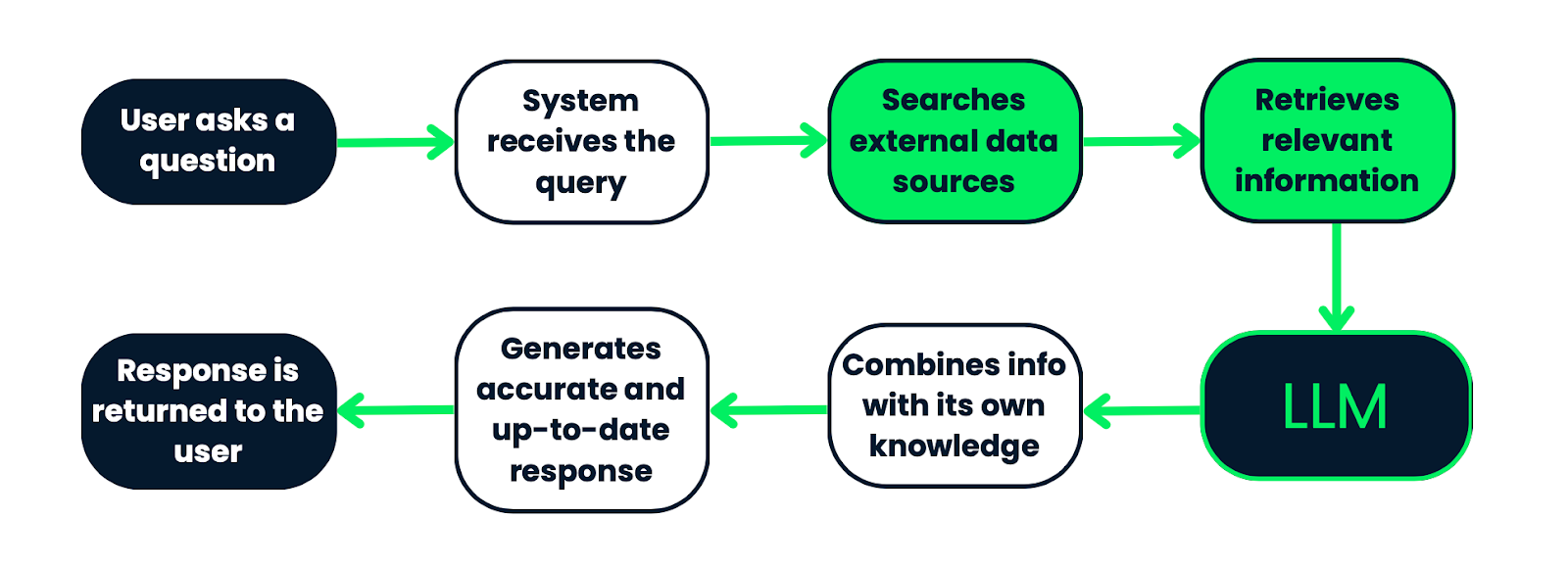
Luồng hoạt động của một hệ thống RAG. Bắt đầu bằng truy vấn của người dùng, hệ thống xử lý để tìm kiếm các nguồn dữ liệu bên ngoài nhằm lấy thông tin liên quan. Thông tin truy xuất sau đó được đưa vào LLM, kết hợp với kiến thức sẵn có để tạo câu trả lời chính xác và cập nhật. Cuối cùng, câu trả lời được trả lại cho người dùng. Quy trình này đảm bảo câu trả lời có cơ sở trên dữ liệu thực, phù hợp với ngữ cảnh.
Khi bạn xây dựng một hệ thống RAG, có vài phần cốt lõi để nó vận hành: bộ nạp tài liệu, tách văn bản, lập chỉ mục, mô hình truy xuất và mô hình sinh. Cùng bóc tách nhé:
Bước đầu là chuẩn bị dữ liệu. Đó là việc bộ nạp tài liệu, tách văn bản và lập chỉ mục đảm nhiệm:
Đây là trái tim của hệ thống RAG. Chúng chịu trách nhiệm đào bới qua toàn bộ dữ liệu đã lập chỉ mục để tìm thứ bạn cần.
Đây là nơi điều kỳ diệu xảy ra. Khi dữ liệu liên quan đã được truy xuất, mô hình sinh đảm nhiệm việc tạo ra câu trả lời cuối cùng.
|
Thành phần |
Mô tả |
|
Document Loaders |
Kéo dữ liệu từ các nguồn như tệp văn bản, PDF hoặc cơ sở dữ liệu, chuyển đổi thông tin sang định dạng hệ thống có thể sử dụng. |
|
Text Splitting |
Cắt nhỏ dữ liệu đã nạp thành các mảnh, giúp dễ tìm kiếm và xử lý trong giới hạn của mô hình ngôn ngữ. |
|
Indexing |
Tổ chức dữ liệu đã tách thành các biểu diễn vector, cho phép tìm kiếm nhanh và hiệu quả để tìm thông tin liên quan cho một truy vấn. |
|
Vector Stores |
Cơ sở dữ liệu chuyên dụng lưu trữ biểu diễn vector, dùng tìm kiếm tương đồng vector để truy xuất thông tin liên quan nhất dựa trên truy vấn. |
|
Retrievers |
Thành phần tìm kiếm chuyển truy vấn thành vector, tìm trong vector store và truy xuất các mảnh dữ liệu liên quan nhất cho bước tiếp theo. |
|
Language Models |
Sinh các câu trả lời mạch lạc và phù hợp ngữ cảnh sử dụng cả dữ liệu truy xuất và kiến thức nội bộ. |
|
Contextual Response Generation |
Kết hợp câu hỏi của người dùng với dữ liệu truy xuất để tạo câu trả lời chi tiết, vừa trả lời câu hỏi vừa lồng ghép thông tin liên quan. |
Trước khi xây dựng hệ thống RAG, chúng ta cần đảm bảo môi trường phát triển đã được thiết lập đúng. Dưới đây là những gì bạn cần:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsCài đặt phụ thuộc: Bây giờ, cài các gói cần thiết bằng pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
Một framework web hiện đại để xây dựng API. |
Máy chủ ASGI để phục vụ ứng dụng FastAPI của bạn. |
Thư viện chính cung cấp sức mạnh cho hệ thống RAG. |
Để dùng các mô hình GPT cho việc sinh câu trả lời. |
Mẹo nhỏ: Hãy tạo tệp requirements.txt để chỉ định các gói cần thiết cho dự án. Nếu bạn dùng: pip freeze > requirements.txt
Lệnh này sẽ tạo tệp requirements.txt chứa tất cả các gói đã cài và phiên bản của chúng, hữu ích cho việc triển khai hoặc chia sẻ môi trường với người khác.
Thêm khóa OpenAI API của bạn: Để tích hợp mô hình ngôn ngữ OpenAI vào hệ thống RAG, bạn cần cung cấp khóa OpenAI API:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Giờ đây, khóa OpenAI API của bạn được nạp an toàn từ môi trường, và bạn đã sẵn sàng sử dụng trong hệ thống RAG!
PostgreSQL và PGVector (Tùy chọn): Nếu bạn dự định dùng PGVector cho lưu trữ vector, hãy cài đặt và cấu hình PostgreSQL trên máy. Bạn có thể dùng FAISS (chúng ta sẽ dùng trong bài này) hoặc các cơ sở dữ liệu vector khác mà LangChain hỗ trợ.
Docker (Tùy chọn): Docker có thể giúp bạn đóng gói ứng dụng để triển khai nhất quán trên các môi trường. Nếu định dùng Docker, hãy đảm bảo nó cũng đã được cài trên máy bạn.
Bước đầu tiên để xây dựng hệ thống RAG là chuẩn bị dữ liệu mà hệ thống sẽ dùng để truy xuất thông tin liên quan. Việc này gồm nạp tài liệu vào hệ thống, xử lý chúng, và đảm bảo chúng ở định dạng có thể dễ dàng lập chỉ mục và truy xuất.
LangChain cung cấp nhiều bộ nạp tài liệu cho các nguồn dữ liệu khác nhau, như tệp văn bản, PDF, hay trang web. Bạn có thể dùng các bộ nạp này để đưa tài liệu vào hệ thống.
Tôi rất hứng thú với gấu Bắc Cực, nên tôi quyết định tải lên tệp văn bản sau (my_document.txt) chứa thông tin này:“Gấu Bắc Cực: Những người khổng lồ vùng Bắc Cực
Gấu Bắc Cực (Ursus maritimus) là loài thú ăn thịt trên cạn lớn nhất Trái Đất, và chúng đã thích nghi hoàn hảo với cuộc sống trong cái lạnh khắc nghiệt của Bắc Cực. Nổi tiếng với bộ lông trắng dày giúp hòa lẫn vào cảnh quan tuyết phủ, gấu Bắc Cực là những thợ săn mạnh mẽ, dựa vào băng biển để săn hải cẩu, nguồn thức ăn chính của chúng.
Điều thú vị ở gấu Bắc Cực là khả năng thích nghi đáng kinh ngạc với môi trường. Bên dưới lớp lông dày là một lớp mỡ có thể dày tới 4,5 inch, cung cấp cách nhiệt và năng lượng dự trữ trong những tháng mùa đông khắc nghiệt. Bàn chân lớn giúp chúng di chuyển trên cả băng và nước mở, biến chúng thành những tay bơi cừ khôi—có thể vượt quãng đường dài để tìm thức ăn hoặc lãnh thổ mới.
Đáng tiếc, gấu Bắc Cực đang đối mặt với những mối đe dọa nghiêm trọng từ biến đổi khí hậu. Khi Bắc Cực ấm lên, băng biển tan sớm hơn trong năm và hình thành muộn hơn, rút ngắn thời gian gấu có thể săn hải cẩu. Không có đủ thức ăn, nhiều cá thể chật vật sinh tồn, và số lượng quần thể đang suy giảm ở một số khu vực.
Gấu Bắc Cực đóng vai trò quan trọng trong việc duy trì sức khỏe của hệ sinh thái Bắc Cực, và tình cảnh của chúng là lời nhắc nhở mạnh mẽ về tác động rộng hơn của biến đổi khí hậu lên động vật hoang dã trên toàn thế giới. Các nỗ lực bảo tồn đang được tiến hành để bảo vệ môi trường sống của chúng và đảm bảo những sinh vật uy nghi này tiếp tục phát triển trong tự nhiên.”
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Đây là một tệp văn bản đơn giản được nạp vào hệ thống, chỉ như ví dụ sư phạm, nhưng bạn có thể thêm bất kỳ loại tài liệu nào bạn muốn! Ví dụ, bạn có thể thêm tài liệu nội bộ của tổ chức. Biến documents hiện chứa nội dung tệp, sẵn sàng để xử lý.
Các tài liệu lớn thường được chia thành các mảnh nhỏ hơn để dễ lập chỉ mục và truy xuất. Quy trình này cực kỳ quan trọng vì các mảnh nhỏ giúp mô hình ngôn ngữ xử lý thuận lợi hơn và cho phép truy xuất chính xác hơn. Bạn có thể tìm hiểu thêm trong hướng dẫn về chiến lược chia nhỏ cho AI và RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Ở đây, văn bản được chia thành các mảnh 500 ký tự với phần chồng lắp 50 ký tự giữa các mảnh. Phần chồng lắp này giúp duy trì ngữ cảnh xuyên suốt khi truy xuất.
Khi dữ liệu đã sẵn sàng, bước tiếp theo là lập chỉ mục để truy xuất hiệu quả. Lập chỉ mục bao gồm chuyển các mảnh văn bản thành embedding vector và lưu vào vector store.
LangChain hỗ trợ tạo vector embeddings bằng nhiều mô hình như OpenAI hoặc HuggingFace. Các embedding này biểu diễn nghĩa ngữ nghĩa của các mảnh văn bản, giúp phù hợp cho tìm kiếm tương đồng.
Nói đơn giản, embedding về cơ bản là cách biến văn bản, như một đoạn trong tài liệu, thành các con số mà mô hình AI có thể hiểu. Những con số này, hay vector, biểu diễn ý nghĩa văn bản theo cách giúp hệ thống AI xử lý dễ dàng hơn.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Chúng ta đang dùng embedding của OpenAI để đảm nhiệm việc chuyển đổi đó. Đầu tiên, chúng ta nhập công cụ embedding của OpenAI, rồi khởi tạo để sẵn sàng sử dụng.
Sau khi tạo embedding, bước tiếp theo là lưu chúng vào một vector store như PGVector, FAISS, hoặc bất kỳ loại nào LangChain hỗ trợ. Điều này cho phép truy xuất nhanh và chính xác tài liệu liên quan khi có truy vấn.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)Trong trường hợp này, chúng ta dùng FAISS, một công cụ tuyệt vời được thiết kế để tìm kiếm qua các tập vector lớn. FAISS giúp chúng ta tìm các vector tương đồng nhất rất nhanh.
Cụ thể: Chúng ta nhập FAISS từ LangChain và dùng nó để tạo cái gọi là vector store. Nó giống như một cơ sở dữ liệu chuyên biệt để lưu trữ và tìm kiếm qua các vector hiệu quả.
Ưu điểm của thiết lập này là, khi tìm kiếm sau này, FAISS có thể quét qua tất cả vector, tìm những vector giống nhất với truy vấn và trả về các mảnh tài liệu tương ứng.
Với dữ liệu đã được lập chỉ mục, bạn có thể triển khai thành phần truy xuất, chịu trách nhiệm lấy thông tin liên quan dựa trên truy vấn của người dùng.
Giờ chúng ta thiết lập một retriever. Đây là thành phần đi qua các tài liệu đã lập chỉ mục và tìm ra những tài liệu liên quan nhất với truy vấn của người dùng.
Điểm hay là, bạn không tìm kiếm ngẫu nhiên—bạn tìm kiếm một cách thông minh dựa trên embedding, nên kết quả nhận được sẽ tương đồng ngữ nghĩa với điều người dùng hỏi. Cùng xem dòng mã:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Trước hết, chúng ta chuyển vector store thành retriever. Bạn biết vector store FAISS đã chứa đầy embedding tài liệu rồi chứ? Bây giờ, chúng ta bảo nó: "Hãy dùng cái đó để tìm kiếm khi người dùng đặt câu hỏi."
search_type là nơi phép màu xảy ra. Retriever có thể tìm theo nhiều cách, và bạn có vài lựa chọn. Tìm kiếm tương đồng là “món tủ”: nó kiểm tra tài liệu nào gần nghĩa với truy vấn nhất.
Vì vậy khi bạn đặt "search_type='similarity'", bạn đang nói với retriever: "Hãy tìm những tài liệu tương tự nhất với truy vấn dựa trên embedding mà chúng ta đã tạo."
Với search_kwargs={"k": 5} bạn tinh chỉnh thêm. Giá trị k cho retriever biết cần lấy bao nhiêu tài liệu từ vector store. Ở đây, k=5 nghĩa là: “Hãy đưa tôi 5 tài liệu liên quan nhất.”
Điều này rất mạnh vì giúp giảm nhiễu. Thay vì nhận một đống kết quả chỉ hơi liên quan, bạn chỉ lấy những mẩu thông tin quan trọng nhất.
Trong phần này, chúng ta thiết lập động cơ cốt lõi của hệ thống RAG bằng LangChain. Bạn đã có retriever, có thể kéo về tài liệu liên quan dựa trên truy vấn.
Giờ chúng ta thêm LLM và dùng nó để thực sự tạo câu trả lời dựa trên tài liệu đã truy xuất.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQAỞ đây, chúng ta nhập hai thành phần chính:
llm = OpenAI(openai_api_key=openai_api_key)Dòng này khởi tạo LLM bằng khóa OpenAI API của bạn. Hãy xem như đang “nạp bộ não” cho hệ thống—mô hình sẽ tiếp nhận văn bản, hiểu và sinh phản hồi.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Đây là lúc mọi thứ trở nên thú vị. Chúng ta thiết lập QA Chain, buộc mọi thứ lại với nhau. Phương thức RetrievalQA.from_chain_type() tạo một chuỗi hỏi đáp, tức là “kết hợp retriever và LLM để tạo hệ thống trả lời dựa trên tài liệu truy xuất”.
Sau đó, chúng ta chỉ định chuỗi dùng LLM OpenAI vừa khởi tạo để sinh câu trả lời. Rồi kết nối retriever bạn đã xây dựng. Retriever chịu trách nhiệm tìm tài liệu liên quan dựa trên truy vấn của người dùng.
Tiếp theo, đặt chain_type="stuff": "stuff" là gì? Đây là một kiểu chain trong LangChain. "Stuff" nghĩa là nạp toàn bộ tài liệu liên quan vào LLM và để nó sinh câu trả lời dựa trên tất cả.
Nôm na là đổ một đống ghi chú lên bàn LLM và nói: "Đây, dùng hết chỗ này để trả lời câu hỏi."
Cũng có các kiểu chain khác (như "map_reduce" hay "refine"), nhưng "stuff" là đơn giản và trực diện nhất.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Đây là nơi chúng ta thực sự đặt câu hỏi và nhận phản hồi. Phương thức invoke() kích hoạt toàn bộ pipeline.
Nó nhận truy vấn của bạn, gửi tới retriever để lấy tài liệu liên quan, rồi chuyển các tài liệu đó cho LLM, mô hình sẽ sinh câu trả lời cuối cùng.
print(response)Dòng cuối in ra phản hồi do LLM tạo. Dựa trên tài liệu đã truy xuất, hệ thống sinh một câu trả lời đầy đủ, có cơ sở cho truy vấn và in ra.
Tập lệnh cuối cùng trông như sau:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Giờ là lúc xây dựng API để tương tác với hệ thống RAG của bạn. Nhưng vì sao bước này cần thiết khi triển khai?
Hãy tưởng tượng bạn đã theo sát hướng dẫn này và đã có một hệ thống RAG tuyệt vời, cá nhân hóa theo tài liệu và nhu cầu của bạn—nó kéo thông tin liên quan, xử lý truy vấn và sinh phản hồi thông minh. Nhưng làm sao để người dùng hoặc hệ thống khác thực sự tương tác với nó?
FastAPI là “người trung gian” của bạn. Nó tạo ra một cách thức đơn giản, có cấu trúc để người dùng hoặc ứng dụng đặt câu hỏi cho hệ thống RAG và nhận câu trả lời.
FastAPI là bất đồng bộ và hiệu năng cao. Điều đó nghĩa là nó có thể xử lý nhiều yêu cầu cùng lúc mà không bị chậm, rất quan trọng khi làm việc với hệ thống AI có thể cần truy xuất lượng dữ liệu lớn hoặc chạy truy vấn phức tạp.
Trong phần này, chúng ta sẽ sửa đổi tập lệnh trước và tạo thêm tập lệnh để đảm bảo hệ thống RAG của bạn có thể truy cập, mở rộng và sẵn sàng xử lý lưu lượng thực tế.Bắt đầu bằng việc tạo các route xử lý yêu cầu đến hệ thống RAG.
Trong thư mục làm việc, tạo tệp main.py. Đây là điểm vào của ứng dụng FastAPI. Nó sẽ là “bộ não” FastAPI—tệp này sẽ tập hợp tất cả route API, phụ thuộc và hệ thống RAG.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)Thiết lập khá đơn giản, nhưng gọn gàng. Chúng ta khởi tạo một FastAPI instance, rồi nạp tất cả route (đường dẫn API) từ tệp khác, mà ta sẽ tạo ở bước tiếp theo.
Đây là nơi mọi thứ kết hợp. Chúng ta sẽ viết một hàm thực thi hệ thống RAG khi người dùng gửi truy vấn.
async def get_rag_response(query: str):Hàm này được đánh dấu async, nghĩa là bất đồng bộ. Nó có thể xử lý việc khác trong lúc chờ phản hồi.
Tính năng này đặc biệt hữu ích khi làm việc với hệ thống dựa trên truy xuất, nơi việc lấy tài liệu hoặc truy vấn LLM có thể tốn thời gian. Bằng cách này, FastAPI có thể xử lý yêu cầu khác trong khi yêu cầu này chạy nền.
retriever = setup_rag_system()Ở đây chúng ta gọi hàm setup_rag_system(), như đã nói, để khởi tạo toàn bộ pipeline retriever. Bao gồm:
Retriever này sẽ chịu trách nhiệm lấy các mảnh văn bản liên quan dựa trên truy vấn của người dùng.
Khi người dùng đặt câu hỏi, retriever sẽ duyệt qua mọi tài liệu trong vector store và lấy ra tài liệu liên quan nhất dựa trên truy vấn.
retrieved_docs = retriever.get_relevant_documents(query)Phương thức invoke(query) này sẽ lấy các tài liệu liên quan. Ẩn bên dưới, nó so khớp truy vấn với các embedding và kéo ra những kết quả phù hợp nhất dựa trên độ tương đồng.
Giờ khi đã có tài liệu liên quan, chúng ta cần định dạng chúng cho LLM.
context = "\n".join([doc.page_content for doc in retrieved_docs])Ở đây, chúng ta lấy tất cả tài liệu truy xuất và gộp nội dung thành một chuỗi. Điều này quan trọng vì LLM kỳ vọng một khối văn bản gọn gàng, không phải nhiều mảnh rời rạc.
Chúng ta dùng hàm join() của Python để khâu các mảnh lại thành một khối thông tin mạch lạc. Nội dung mỗi tài liệu nằm trong trường doc.page_content, và chúng ta nối bằng xuống dòng (\n).
Giờ chúng ta tạo prompt cho LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]Prompt được cấu trúc để yêu cầu LLM dùng thông tin đã truy xuất để trả lời truy vấn của người dùng.
Đã đến lúc sinh phản hồi.
generated_response = llm.generate(prompt) # Pass as a list of stringsTại đây, mô hình OpenAI nhận nhiệm vụ lấy prompt và sinh phản hồi có ngữ cảnh dựa trên cả câu hỏi và tài liệu liên quan.
Cuối cùng, chúng ta trả về phản hồi cho bên gọi hàm (có thể là người dùng, ứng dụng frontend, hoặc hệ thống khác).
return generated_responsePhản hồi này đã được hình thành đầy đủ, có ngữ cảnh, sẵn sàng dùng trong ứng dụng thực tế.
Tóm lại, hàm này thực hiện trọn vòng lặp truy xuất và sinh. Tóm tắt luồng:
1. Thiết lập retriever để tìm tài liệu liên quan.
2. Kéo tài liệu dựa trên truy vấn.
3. Chuẩn bị ngữ cảnh từ các tài liệu cho LLM.
4. LLM sinh câu trả lời cuối cùng dựa trên ngữ cảnh đó.
5. Trả về phản hồi cho người dùng.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyTiếp theo, hãy tạo tệp endpoints.py. Đây là nơi chúng ta định nghĩa các đường dẫn mà người dùng sẽ gọi để tương tác với hệ thống RAG.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Chúng ta tạo một APIRouter để quản lý các route API. Endpoint /query/ được định nghĩa để chấp nhận yêu cầu **GET** với chuỗi truy vấn. Nó gọi hàm get_rag_response từ tệp rag.py, hàm này xử lý toàn bộ pipeline RAG (truy xuất tài liệu + sinh ngôn ngữ). Nếu có lỗi, chúng ta ném lỗi HTTP 500 kèm thông điệp chi tiết.
Với mọi thứ đã sẵn sàng, giờ bạn có thể chạy ứng dụng FastAPI bằng Uvicorn. Đây là máy chủ web cho phép người dùng truy cập API của bạn.
Vào terminal và chạy:
uvicorn app.main:app --reloadapp.main:app bảo Uvicorn tìm app instance trong tệp main.py và --reload bật tính năng tự động tải lại khi bạn thay đổi mã.
Khi máy chủ chạy, mở trình duyệt và truy cập http://127.0.0.1:8000/docs. FastAPI tự động tạo tài liệu Swagger UI cho API của bạn, nên bạn có thể thử trực tiếp trên trình duyệt!
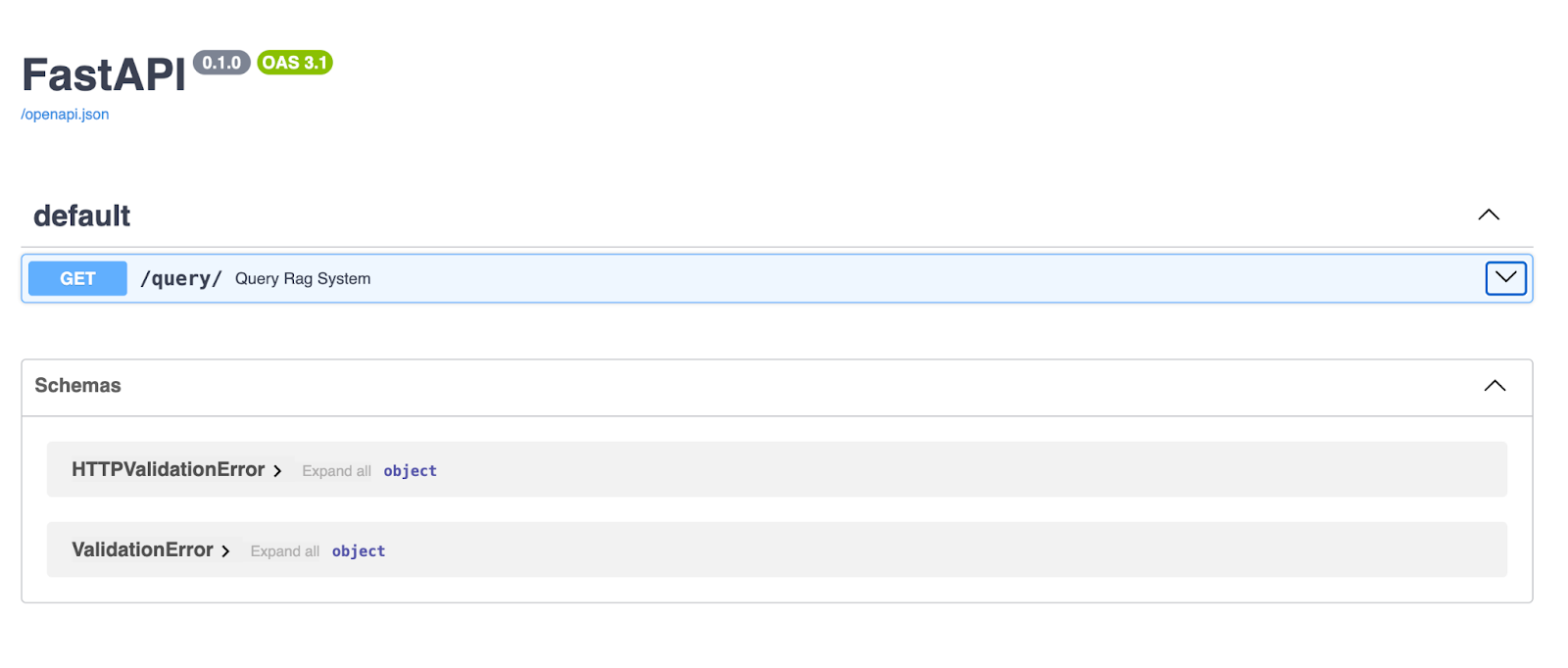
FastAPI Swagger UI cung cấp giao diện gọn gàng, tương tác để khám phá và kiểm thử các endpoint API của bạn. Ở đây, endpoint /query/ cho phép người dùng nhập chuỗi truy vấn và nhận phản hồi do pipeline RAG sinh ra.
Khi máy chủ FastAPI đang chạy, hãy mở trình duyệt hoặc dùng Postman hay Curl để gửi yêu cầu GET đến endpoint /query/ của bạn.
Trong trình duyệt, qua Swagger:
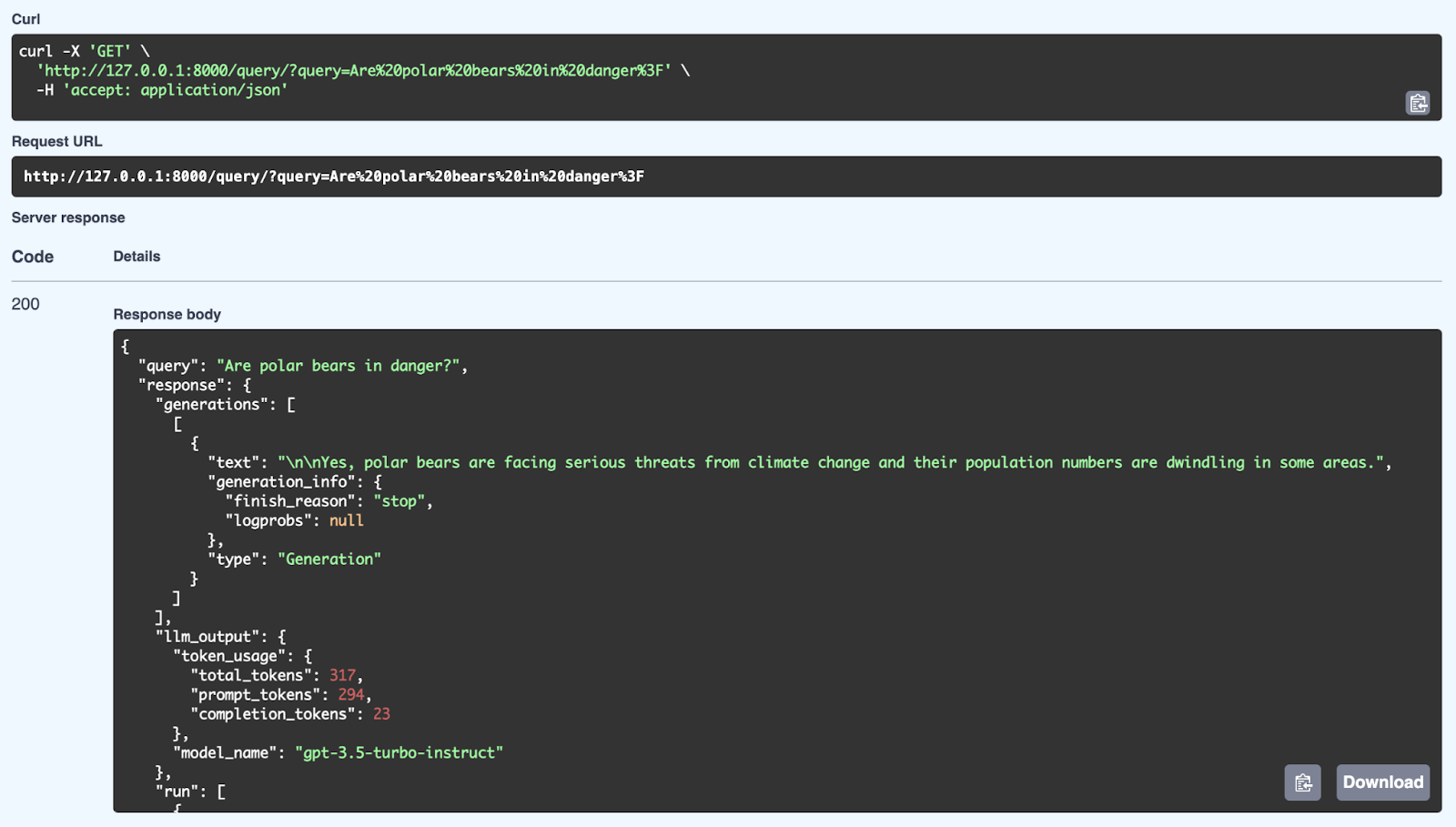
Ở đây chúng ta thấy một phản hồi thành công từ hệ thống RAG với truy vấn: "Are polar bears in danger?". Hệ thống truy xuất thông tin liên quan từ kho tri thức và sinh phản hồi mạch lạc bằng mô hình GPT-3.5 Turbo-Instruct. Phản hồi chi tiết không chỉ gồm câu trả lời (Có, gấu Bắc Cực đang đối mặt với đe dọa nghiêm trọng từ biến đổi khí hậu và số lượng đang suy giảm) mà còn có siêu dữ liệu như số token sử dụng và mô hình dùng để sinh. API có thể cung cấp câu trả lời có cấu trúc tốt, nhận thức ngữ cảnh bằng cách kết hợp cơ chế truy xuất và sinh qua FastAPI.
Giờ hãy bàn về lợi ích của Xử lý Bất đồng bộ trong FastAPI và vì sao nó tạo khác biệt lớn khi xử lý các yêu cầu API thực tế.
Hệ thống RAG của bạn đã chạy. API đang nhận câu hỏi, truy xuất thông tin từ kho tri thức, rồi sinh phản hồi bằng mô hình ngôn ngữ.
Nếu toàn bộ quy trình đó đồng bộ, hệ thống sẽ ngồi chờ từng tác vụ xong mới chuyển sang tác vụ tiếp theo. Ví dụ, trong lúc đang truy xuất tài liệu, nó sẽ không thể xử lý yêu cầu mới.
|
I/O không chặn |
Hiệu năng cải thiện |
Trải nghiệm người dùng tốt hơn |
|
Hàm async cho phép máy chủ xử lý nhiều yêu cầu cùng lúc, thay vì đợi một yêu cầu xong mới bắt đầu yêu cầu khác. |
Với các tác vụ như truy xuất tài liệu từ vector store hoặc sinh văn bản, xử lý async giúp API quản lý tải cao hiệu quả. |
Khách hàng nhận phản hồi nhanh hơn, và API của bạn vẫn phản hồi tốt ngay cả khi tải nặng. |
Hãy nói về các chiến lược triển khai—một bước rất quan trọng để biến hệ thống RAG của bạn từ nguyên mẫu thành sản phẩm vận hành đầy đủ. Mục tiêu là đảm bảo hệ thống được đóng gói, triển khai và sẵn sàng mở rộng để xử lý người dùng thực.
Trước hết, nói về Docker. Docker giống như một chiếc hộp kỳ diệu đóng gói mọi thứ hệ thống RAG của bạn cần—mã nguồn, phụ thuộc, cấu hình—và gói tất cả vào một container gọn gàng.
Điều này đảm bảo dù bạn triển khai ở đâu, ứng dụng cũng hoạt động y như vậy. Bạn có thể chạy ứng dụng ở các môi trường khác nhau, nhưng vì nó nằm trong container, bạn không phải lo vấn đề “chạy được trên máy tôi”.

Bạn tạo một Dockerfile, là tập hợp hướng dẫn bảo Docker cách thiết lập môi trường ứng dụng, cài đặt các gói cần thiết và chạy ứng dụng. Khi xong, bạn có thể build Docker image từ đó và chạy ứng dụng trong container. Nó hiệu quả, lặp lại được và cực kỳ linh hoạt.
Khi hệ thống đã được đóng gói và sẵn sàng, rất có thể bạn sẽ muốn triển khai lên đám mây. Đây là phần thú vị vì triển khai hệ thống RAG lên đám mây nghĩa là có thể truy cập từ bất kỳ đâu. Ngoài ra, bạn có khả năng mở rộng, độ tin cậy, và truy cập các dịch vụ đám mây khác có thể tăng cường cho hệ thống.
Hãy xem một vài nền tảng đám mây phổ biến như Azure và Google Cloud:
AWS cung cấp các công cụ như Elastic Beanstalk, giúp việc triển khai rất dễ. Bạn chỉ cần chuyển giao container Docker, và AWS lo phần mở rộng, cân bằng tải và giám sát. Nếu cần kiểm soát nhiều hơn, bạn có thể dùng Amazon ECS, cho phép chạy container Docker trên cụm máy chủ và mở rộng lên/xuống theo nhu cầu.
Heroku là một lựa chọn khác giúp đơn giản hóa triển khai. Bạn chỉ việc đẩy mã nguồn, và Heroku xử lý hạ tầng cho bạn. Rất phù hợp nếu bạn không muốn đi quá sâu vào việc quản lý tài nguyên đám mây.
Azure cung cấp Azure App Service, cho phép bạn triển khai và quản lý hệ thống RAG dễ dàng, hỗ trợ sẵn auto-scaling, cân bằng tải và triển khai liên tục.
Để linh hoạt hơn, bạn có thể dùng Azure Kubernetes Service (AKS) để quản lý container Docker ở quy mô lớn, đảm bảo hệ thống chịu tải cao với khả năng điều chỉnh tài nguyên động khi cần.
GCP có Google Cloud Run, nền tảng được quản lý hoàn toàn cho phép bạn triển khai container và tự động mở rộng theo lưu lượng.
Nếu muốn kiểm soát hạ tầng nhiều hơn, bạn có thể dùng Google Kubernetes Engine (GKE), cho phép quản lý và mở rộng container Docker qua nhiều node, với lợi thế tích hợp sâu với các dịch vụ AI và ML của Google.
Mỗi nền tảng có điểm mạnh riêng, tùy bạn muốn đơn giản, tự động hay kiểm soát chi tiết quá trình triển khai.
Chúng ta đã đi qua khá nhiều nội dung trong bài viết này, từ quy trình xây dựng hệ thống RAG bằng LangChain và FastAPI. Các hệ thống RAG là bước tiến lớn trong xử lý ngôn ngữ tự nhiên vì chúng đưa thông tin bên ngoài vào, giúp AI sinh phản hồi chính xác, phù hợp và nhận thức ngữ cảnh hơn.
Với LangChain, chúng ta có một framework vững chắc xử lý mọi thứ từ nạp tài liệu, tách văn bản, tạo embedding cho đến truy xuất thông tin dựa trên truy vấn người dùng.
Sau đó, FastAPI xuất hiện như một framework web nhanh, sẵn sàng cho async, giúp chúng ta triển khai hệ thống RAG thành một API có khả năng mở rộng.
Cùng nhau, các công cụ này giúp việc xây dựng ứng dụng AI trở nên dễ dàng hơn—có thể xử lý truy vấn phức tạp, đưa ra câu trả lời chính xác và cuối cùng mang lại trải nghiệm người dùng tốt hơn.
Giờ là lúc bạn áp dụng những gì đã học để triển khai cho dự án của riêng mình.
Hãy nghĩ về các khả năng: truy vấn kho tri thức nội bộ của công ty, tự động hóa quy trình rà soát tài liệu, hoặc tạo chatbot thông minh cho hỗ trợ khách hàng.
Đừng quên—có rất nhiều cách để mở rộng thiết lập này! Bạn có thể thử nghiệm với yêu cầu POST để gửi cấu trúc dữ liệu phức tạp hơn, hoặc khám phá kết nối WebSocket cho tương tác thời gian thực.
Tôi khuyến khích bạn đào sâu, thử nghiệm và xem điều này có thể đưa bạn đến đâu. Đây mới chỉ là khởi đầu cho những gì bạn có thể đạt được với LangChain, FastAPI và các công cụ AI hiện đại! Dưới đây là vài tài nguyên tôi khuyên dùng:
Các khóa học hàng đầu trên DataCamp
Courses
Courses
Courses