
Corso
Sviluppare applicazioni LLM con LangChain
3 h
47.9K
La Retrieval-Augmented Generation (RAG) è una delle tecniche più interessanti dell’IA in questo momento. Combina la precisione del recupero di informazioni reali da dataset enormi con la capacità di ragionamento dei large language model. Il risultato? Risposte non solo accurate, ma anche estremamente pertinenti. Ecco perché RAG alimenta di tutto, dai chatbot e motori di ricerca ai contenuti personalizzati.
Ma c’è un problema: costruire un prototipo è solo metà dell’opera. La vera sfida sta nella messa in produzione: trasformare l’idea in un prodotto affidabile e scalabile.
In questo articolo ti mostro come creare e distribuire un sistema RAG usando LangChain e FastAPI. Imparerai a passare da un prototipo funzionante a un’applicazione completa, pronta per utenti reali.
Partiamo!
Come spieghiamo in una guida a parte, la Retrieval-Augmented Generation, o RAG, è un metodo avanzato di elaborazione del linguaggio naturale che porta a un livello superiore le capacità dei modelli linguistici.
Invece di basarsi solo su ciò che il modello sa già, RAG fa un passo in più: recupera nuove informazioni rilevanti da fonti esterne prima di generare una risposta.
Ecco come funziona: quando un utente fa una domanda, il sistema non si limita ai dati pre-acquisiti dal modello. Prima effettua una ricerca in un grande insieme di documenti o sorgenti dati, estrae i passaggi più pertinenti e poi fornisce tutto al modello linguistico. Conoscenza interna più informazioni appena recuperate permettono al modello di creare una risposta molto più accurata e aggiornata.
RAG fonde recupero e generazione, così le risposte non sono solo intelligenti: sono anche ancorate a informazioni reali e fattuali. È perfetta per Q&A, chatbot e generazione di contenuti in cui accuratezza e contesto contano davvero.
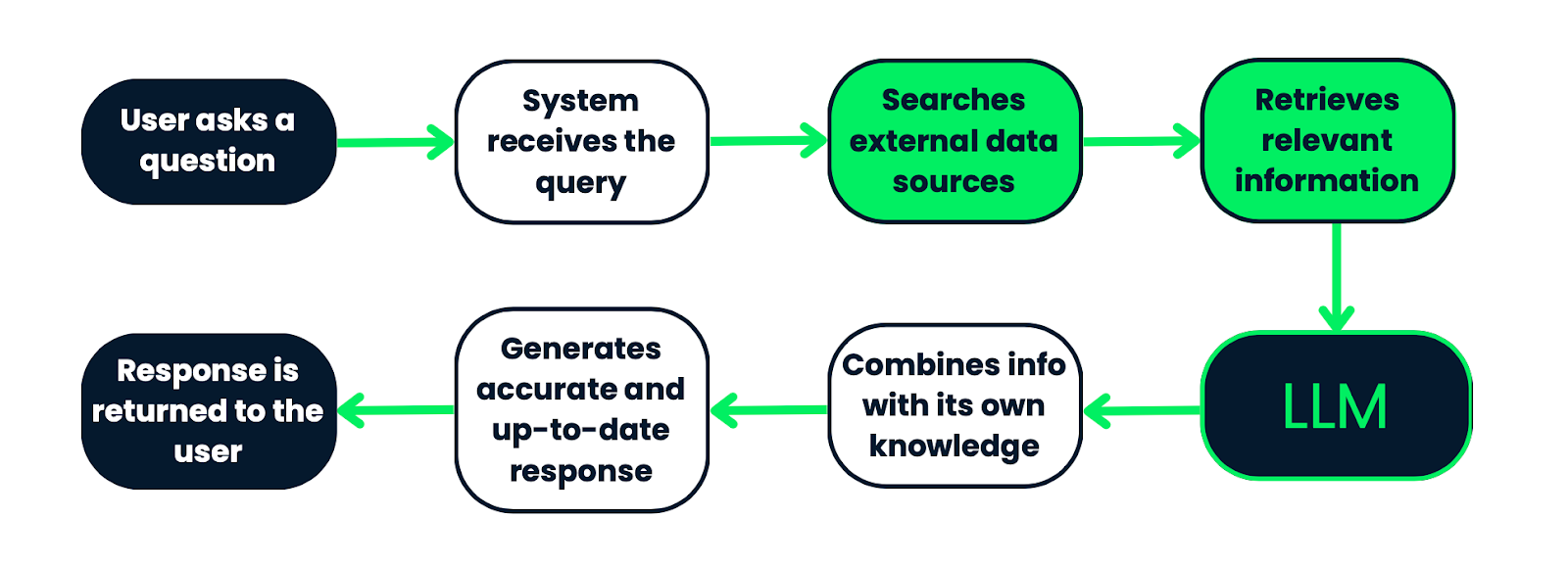
Flusso di lavoro di un sistema RAG. Si parte dalla query dell’utente, che viene elaborata dal sistema per cercare informazioni pertinenti in fonti dati esterne. Le informazioni recuperate vengono quindi fornite a un LLM, che le combina con la propria conoscenza preesistente per generare una risposta accurata e aggiornata. Infine, la risposta viene restituita all’utente. Questo processo garantisce risposte fondate su dati fattuali e rilevanti nel contesto.
Quando costruisci un sistema RAG, servono alcuni elementi essenziali per farlo funzionare: caricamento documenti, suddivisione del testo, indicizzazione, modelli di recupero e modelli generativi. Vediamoli:
Il primo passo è preparare i dati. È ciò che fanno i caricatori di documenti, la suddivisione del testo e l’indicizzazione:
Sono il cuore del sistema RAG. Si occupano di setacciare tutti i dati indicizzati per trovare ciò che serve.
Qui avviene la magia. Recuperati i dati rilevanti, i modelli generativi producono la risposta finale.
|
Component |
Description |
|
Document Loaders |
Importano dati da fonti come file di testo, PDF o database, convertendo le informazioni in un formato utilizzabile dal sistema. |
|
Text Splitting |
Divide i dati caricati in blocchi più piccoli, rendendoli più facili da cercare ed elaborare entro i limiti dei modelli linguistici. |
|
Indexing |
Organizza i dati suddivisi in rappresentazioni vettoriali, abilitando ricerche rapide ed efficienti per trovare informazioni pertinenti a una query. |
|
Vector Stores |
Database specializzati che memorizzano rappresentazioni vettoriali, usando la similarity search per recuperare le informazioni più pertinenti in base alla query. |
|
Retrievers |
Componenti di ricerca che convertono la query in un vettore, interrogano il vector store e recuperano i blocchi di dati più rilevanti per lo step successivo. |
|
Language Models |
Generano risposte coerenti e adeguate al contesto usando sia i dati recuperati sia la conoscenza interna. |
|
Contextual Response Generation |
Combina la domanda dell’utente con i dati recuperati per creare una risposta dettagliata che includa le informazioni pertinenti. |
Prima di costruire il nostro sistema RAG, assicuriamoci di avere l’ambiente di sviluppo configurato correttamente. Ecco cosa ti serve:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsInstalla le dipendenze: Ora installa i pacchetti richiesti con pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
Un framework web moderno per creare API. |
Un server ASGI per servire la tua applicazione FastAPI. |
La libreria principale che alimenta il sistema RAG. |
Per usare i modelli GPT nella generazione delle risposte. |
Consiglio: crea un file requirements.txt per specificare i pacchetti necessari al progetto. Se usi: pip freeze > requirements.txt
Questo comando genera un requirements.txt con tutti i pacchetti installati e le relative versioni, utile per la distribuzione o per condividere l’ambiente con altri.
Aggiungi la tua OpenAI API Key: per integrare il modello linguistico di OpenAI nel sistema RAG, ti serve la tua API key di OpenAI:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Ora la tua OpenAI API key è caricata in modo sicuro dall’ambiente e sei pronto a usarla nel tuo sistema RAG!
PostgreSQL e PGVector (Opzionale): se hai in programma di usare PGVector per l’archiviazione dei vettori, installa e configura PostgreSQL sulla tua macchina. Puoi usare FAISS (che useremo in questo articolo) o altri database vettoriali supportati da LangChain.
Docker (Opzionale): Docker può aiutarti a containerizzare l’applicazione per garantire distribuzioni uniformi tra ambienti. Se prevedi di usarlo, installalo anche sulla tua macchina.
Il primo passo per costruire un sistema RAG è preparare i dati che il sistema userà per recuperare informazioni pertinenti. Significa caricare i documenti nel sistema, elaborarli e assicurarsi che siano in un formato facilmente indicizzabile e recuperabile.
LangChain fornisce vari caricatori di documenti per gestire diverse sorgenti dati, come file di testo, PDF o pagine web. Puoi usarli per importare i documenti nel sistema.
Sono affascinato dagli orsi polari, quindi ho deciso di caricare il seguente file di testo (my_document.txt) con queste informazioni:“Polar Bears: The Arctic Giants
Gli orsi polari (Ursus maritimus) sono i più grandi carnivori terrestri del pianeta e si sono adattati perfettamente alla vita nel freddo estremo dell’Artico. Noti per la loro spessa pelliccia bianca, che li aiuta a mimetizzarsi nel paesaggio innevato, sono cacciatori potenti e fanno affidamento sul ghiaccio marino per cacciare le foche, la loro principale fonte di cibo.
Ciò che affascina degli orsi polari sono gli incredibili adattamenti al loro ambiente. Sotto la folta pelliccia c’è uno strato di grasso che può arrivare a 4,5 pollici, fornendo isolamento e riserve di energia durante i rigidi mesi invernali. Le loro grandi zampe li aiutano a camminare su ghiaccio e acqua aperta, rendendoli nuotatori forti — capaci di coprire grandi distanze alla ricerca di cibo o di nuovi territori.
Purtroppo gli orsi polari affrontano gravi minacce dovute al cambiamento climatico. Con il riscaldamento dell’Artico, il ghiaccio marino si scioglie prima e si riforma più tardi, riducendo il tempo a disposizione per cacciare le foche. Senza abbastanza cibo, molti orsi faticano a sopravvivere e in alcune aree la popolazione è in calo.
Gli orsi polari giocano un ruolo cruciale nel mantenere la salute dell’ecosistema artico e la loro condizione è un forte promemoria dei più ampi impatti del cambiamento climatico sulla fauna mondiale. Sono in corso sforzi di conservazione per proteggere il loro habitat e garantire che queste creature maestose continuino a prosperare in natura.”
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Ecco un semplice file di testo caricato nel sistema, solo come esempio didattico, ma puoi aggiungere qualsiasi tipo di documento! Ad esempio, documentazione interna della tua organizzazione. La variabile documents ora contiene il contenuto del file, pronto per l’elaborazione.
I documenti di grandi dimensioni vengono spesso suddivisi in parti più piccole per facilitarne l’indicizzazione e il recupero. Questo passaggio è fondamentale perché i chunk più piccoli sono più gestibili per il modello linguistico e consentono un recupero più preciso. Puoi approfondire nella nostra guida sulle strategie di chunking per l’IA e RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Qui il testo è suddiviso in blocchi da 500 caratteri con una sovrapposizione di 50 caratteri. Questa sovrapposizione aiuta a mantenere il contesto tra i chunk durante il recupero.
Una volta preparati i dati, il passo successivo è indicizzarli per un recupero efficiente. L’indicizzazione prevede la conversione dei chunk in embedding vettoriali e la loro memorizzazione in un vector store.
LangChain supporta la creazione di embedding vettoriali con vari modelli, come OpenAI o HuggingFace. Questi embedding rappresentano il significato semantico dei chunk di testo, rendendoli adatti alle ricerche per similarità.
In parole semplici, gli embedding sono un modo per trasformare il testo, ad esempio un paragrafo di un documento, in numeri che un modello di IA può comprendere. Questi numeri, o vettori, rappresentano il significato del testo in una forma più facile da elaborare.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()Qui usiamo gli embedding di OpenAI per gestire la trasformazione. Prima importiamo lo strumento di embedding di OpenAI, poi lo inizializziamo per l’uso.
Dopo aver generato gli embedding, il passo successivo è archiviarli in un vector store come PGVector, FAISS o altri supportati da LangChain. Questo consente di recuperare rapidamente e con precisione i documenti pertinenti quando arriva una query.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)In questo caso usiamo FAISS, uno strumento eccellente per cercare in grandi insiemi di vettori. FAISS ci aiuta a trovare velocemente i vettori più simili.
In pratica: importiamo FAISS da LangChain e lo usiamo per creare un vector store, una sorta di database speciale progettato per archiviare e cercare vettori in modo efficiente.
Il bello di questa configurazione è che, durante la ricerca, FAISS scorrerà tutti i vettori, troverà quelli più simili a una query e restituirà i chunk di documento corrispondenti.
Indicizzati i dati, puoi implementare il componente di recupero, responsabile di estrarre le informazioni pertinenti in base alle query degli utenti.
Ora configuriamo un retriever. È il componente che scorre i documenti indicizzati e trova quelli più rilevanti per la query dell’utente.
La cosa interessante è che non cerchi “a caso”: cerchi in modo intelligente grazie agli embedding, quindi i risultati sono semanticamente simili a ciò che l’utente sta chiedendo. Vediamo la riga di codice:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Per prima cosa convertiamo il vector store in un retriever. Hai già lo store FAISS pieno di embedding dei documenti? Ora gli diciamo: “Usalo per cercare quando l’utente mi fa una domanda”.
Il parametro search_type è cruciale. Il retriever può cercare in modi diversi, e hai alcune opzioni. La similarity search è la base del recupero: verifica quali documenti sono più vicini, in termini di significato, alla query.
Quindi con "search_type='similarity'" stai dicendo: “Trova i documenti più simili alla query in base agli embedding che abbiamo generato”.
Con search_kwargs={"k": 5} affini la ricerca. Il valore k indica quanti documenti recuperare dallo store. Qui k=5 significa: “Dammi i 5 documenti più rilevanti”.
È molto utile perché riduce il rumore. Invece di ottenere una valanga di risultati solo vagamente pertinenti, prendi i pezzi di informazione più importanti.
In questa parte del codice impostiamo il motore centrale del tuo sistema RAG con LangChain. Hai già il retriever, che può riportare i documenti pertinenti in base a una query.
Ora aggiungiamo l’LLM e lo usiamo per generare la risposta a partire dai documenti recuperati.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQAQui importiamo due elementi chiave:
llm = OpenAI(openai_api_key=openai_api_key)Questa riga inizializza l’LLM usando la tua OpenAI API key. È come caricare il “cervello” del sistema: il modello che riceve testo, lo comprende e genera risposte.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Qui si fa davvero interessante. Configuriamo la QA Chain, che mette insieme tutto. Il metodo RetrievalQA.from_chain_type() crea una catena di Q&A, ossia “Combina retriever e LLM per rispondere alle domande basandoti sui documenti recuperati”.
Diciamo alla chain di usare l’LLM di OpenAI appena inizializzato per generare risposte. Poi colleghiamo il retriever creato prima. Il retriever trova i documenti pertinenti in base alla query dell’utente.
Infine impostiamo chain_type="stuff": cos’è “stuff”? È un tipo di chain in LangChain. “Stuff” significa caricare tutti i documenti recuperati nell’LLM e fargli generare una risposta usando tutto.
È come buttare una pila di appunti sulla scrivania dell’LLM e dirgli: “Usa tutto questo per rispondere alla domanda”.
Esistono anche altri chain type (come “map_reduce” o “refine”), ma “stuff” è il più semplice e diretto.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Qui poniamo effettivamente una domanda al sistema e otteniamo una risposta. Il metodo invoke() avvia l’intera pipeline.
Prende la query, la invia al retriever per recuperare i documenti pertinenti e poi passa tali documenti all’LLM, che genera la risposta finale.
print(response)Questa ultima riga stampa la risposta generata dall’LLM. In base ai documenti recuperati, il sistema produce una risposta completa e informata, che viene stampata.
Lo script finale è il seguente:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Ora è il momento di creare un’API per interagire con il tuo sistema RAG. Ma perché è necessario per la messa in produzione?
Immagina di aver seguito il tutorial e di avere un sistema RAG fantastico, personalizzato sui tuoi documenti e bisogni — recupera informazioni pertinenti, elabora query e genera risposte intelligenti. Ma come permetti a utenti o ad altri sistemi di interagirci?
FastAPI è l’intermediario. Crea un modo semplice e organizzato per consentire a utenti o applicazioni di fare domande al tuo sistema RAG e ricevere risposte.
FastAPI è asincrono e ad alte prestazioni. Ciò significa che può gestire molte richieste contemporaneamente senza rallentare, caratteristica fondamentale con sistemi di IA che potrebbero dover recuperare grandi quantità di dati o eseguire query complesse.
In questa sezione modificheremo lo script precedente e ne creeremo altri per rendere il tuo sistema RAG accessibile, scalabile e pronto a gestire traffico reale.Iniziamo creando le route che gestiranno le richieste in arrivo al sistema RAG.
Nella cartella di lavoro, crea un file main.py. È il punto di ingresso per l’app FastAPI. Sarà il “cervello” di FastAPI — questo file riunirà tutte le route API, le dipendenze e il sistema RAG.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)È una configurazione semplice ma pulita. Creiamo un’istanza di FastAPI e importiamo tutte le route (o percorsi API) da un altro file, che creeremo a breve.
Qui si unisce tutto. Scriveremo una funzione che esegue il sistema RAG quando un utente invia una query.
async def get_rag_response(query: str):La funzione è contrassegnata come async, quindi è asincrona. Significa che può svolgere altro mentre attende una risposta.
È particolarmente utile con sistemi basati sul recupero, dove ottenere documenti o interrogare un LLM può richiedere tempo. Così FastAPI può gestire altre richieste mentre questa è in lavorazione.
retriever = setup_rag_system()Qui chiamiamo la funzione setup_rag_system() che, come visto, inizializza l’intera pipeline del retriever. Significa che:
Questo retriever recupererà i chunk di testo più rilevanti in base alla query dell’utente.
Quando l’utente fa una domanda, il retriever scorre tutti i documenti nel vector store e prende quelli più pertinenti in base alla query.
retrieved_docs = retriever.get_relevant_documents(query)Questo metodo invoke(query) sta recuperando i documenti pertinenti. Dietro le quinte, confronta la query con i vettori degli embedding ed estrae i migliori match per similarità.
Ora che abbiamo i documenti rilevanti, dobbiamo formattarli per l’LLM.
context = "\n".join([doc.page_content for doc in retrieved_docs])Qui prendiamo tutti i documenti recuperati e uniamo i loro contenuti in un’unica stringa. È importante perché l’LLM si aspetta un blocco di testo pulito, non tanti pezzi separati.
Usiamo la funzione join() di Python per cucire insieme questi chunk in un blocco coerente. Il contenuto di ciascun documento è nel campo doc.page_content, e li separiamo con nuove righe (\n).
Ora creiamo il prompt per l’LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]Il prompt è strutturato per dire all’LLM di usare le informazioni recuperate per rispondere alla query dell’utente.
È il momento di generare una risposta.
generated_response = llm.generate(prompt) # Pass as a list of stringsQui il modello di OpenAI prende il prompt e genera una risposta contestualizzata in base sia alla domanda sia ai documenti rilevanti.
Infine restituiamo la risposta generata a chi ha chiamato la funzione (utente, frontend o un altro sistema).
return generated_responseQuesta risposta è completa, contestuale e pronta per l’uso in applicazioni reali.
In sintesi, questa funzione copre l’intero ciclo recupero–generazione. Ecco il flusso:
1. Configura il retriever per trovare i documenti pertinenti.
2. I documenti vengono recuperati in base alla query.
3. Il contesto dai documenti viene preparato per l’LLM.
4. L’LLM genera la risposta finale usando quel contesto.
5. La risposta viene restituita all’utente.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyCreiamo ora il file endpoints.py. Qui definiremo i percorsi che gli utenti chiameranno per interagire con il sistema RAG.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))Creiamo un APIRouter per gestire le route API. L’endpoint /query/ accetta una richiesta GET con una query string. Chiama la funzione get_rag_response del file rag.py, che gestisce l’intera pipeline RAG (recupero documenti + generazione). Se qualcosa va storto, solleviamo un errore HTTP 500 con un messaggio dettagliato.
Con tutto configurato, puoi eseguire l’app FastAPI con Uvicorn. È il web server che consente agli utenti di accedere alla tua API.
Vai nel terminale ed esegui:
uvicorn app.main:app --reloadapp.main:app indica a Uvicorn di cercare l’istanza app nel file main.py e --reload abilita il ricaricamento automatico se apporti modifiche al codice.
Una volta avviato il server, apri il browser e vai su http://127.0.0.1:8000/docs. FastAPI genera automaticamente la documentazione Swagger UI per la tua API, così puoi testarla direttamente dal browser!
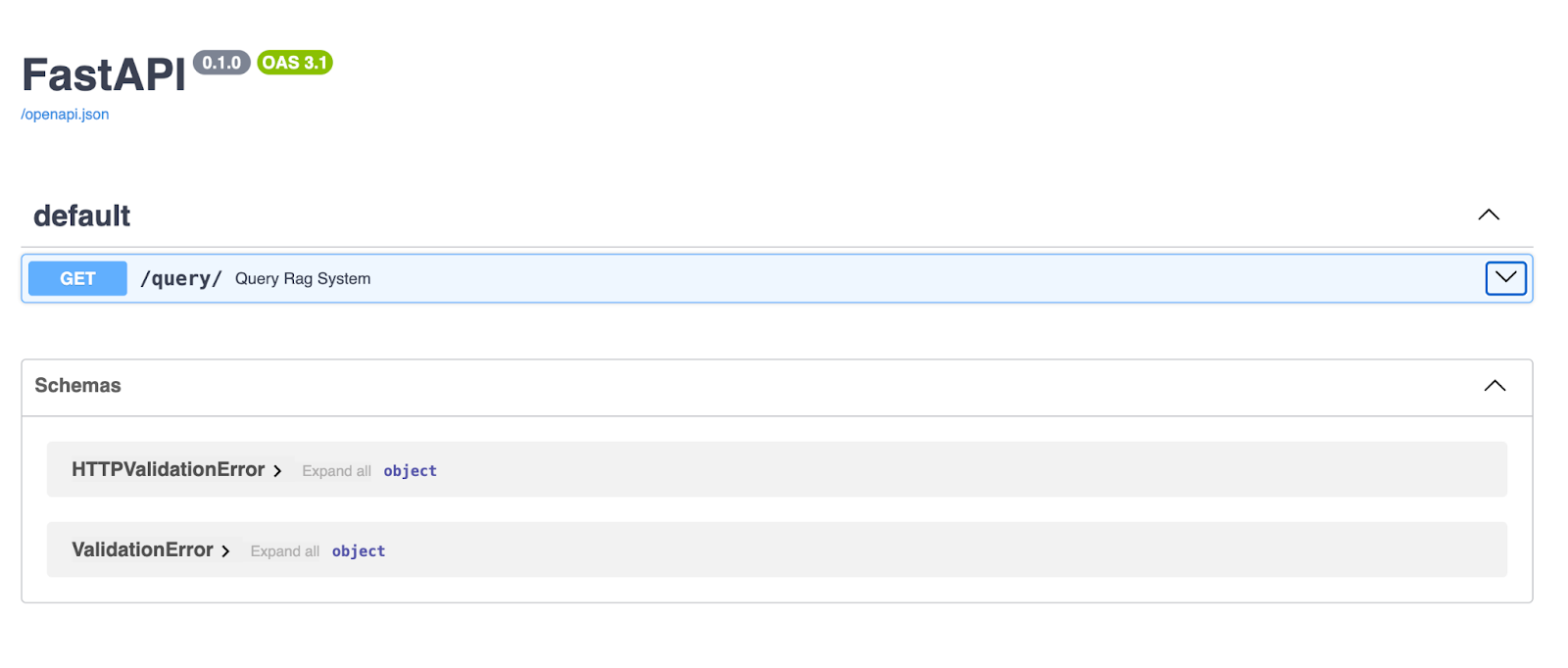
La Swagger UI di FastAPI offre un’interfaccia pulita e interattiva per esplorare e testare gli endpoint della tua API. Qui, l’endpoint /query/ permette agli utenti di inserire una query string e ricevere una risposta generata dalla pipeline RAG.
Con il server FastAPI in esecuzione, apri il browser o usa Postman o Curl per effettuare una richiesta GET all’endpoint /query/.
Nel browser, tramite Swagger:
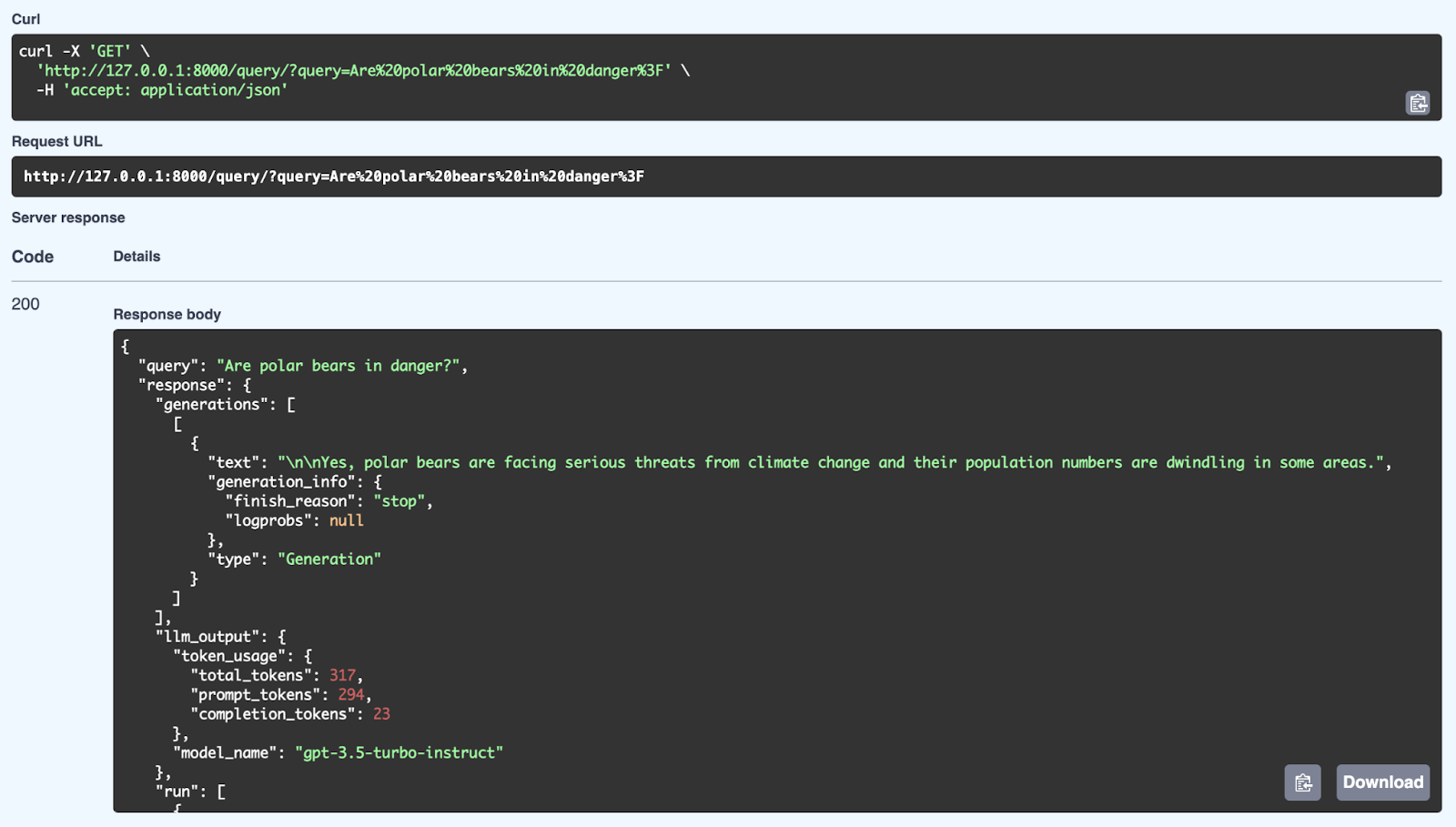
Qui vediamo una risposta corretta dal sistema RAG alla query: "Are polar bears in danger?". Il sistema recupera informazioni pertinenti dalla propria knowledge base e genera una risposta coerente usando il modello GPT-3.5 Turbo-Instruct. La risposta include non solo l’esito (Sì, gli orsi polari affrontano gravi minacce legate al cambiamento climatico e in alcune aree la popolazione è in diminuzione), ma anche metadati come l’utilizzo dei token (numero di token elaborati) e il modello usato per la generazione. L’API fornisce risposte ben strutturate e contestuali combinando meccanismi di recupero e generazione tramite FastAPI.
Parliamo ora dei vantaggi dell’elaborazione asincrona in FastAPI e del perché fa una grande differenza nella gestione di richieste API reali.
Il tuo sistema RAG è operativo. L’API riceve domande, recupera informazioni pertinenti dalla knowledge base e genera risposte con un modello linguistico.
Se tutto questo fosse sincrono, il sistema resterebbe in attesa del completamento di ogni attività prima di passare alla successiva. Ad esempio, mentre recupera documenti, non potrebbe elaborare nuove richieste.
|
I/O non bloccante |
Migliori prestazioni |
Migliore esperienza utente |
|
Le funzioni async consentono al server di gestire più richieste in parallelo, senza aspettare che una finisca prima di iniziare la successiva. |
Per attività come il recupero di documenti da un vector store o la generazione di testo, l’elaborazione async garantisce che l’API gestisca carichi elevati in modo efficiente. |
I client ottengono risposte più rapide e la tua API resta reattiva anche sotto forte utilizzo. |
Parliamo delle strategie di distribuzione — un passaggio fondamentale per trasformare il tuo sistema RAG da prototipo a prodotto operativo. L’obiettivo è impacchettare, distribuire e scalare il sistema in modo che possa gestire utenti reali.
Partiamo da Docker. Docker è come una scatola magica che racchiude tutto ciò che serve al tuo sistema RAG — codice, dipendenze, configurazioni — in un unico container ordinato.
Così, ovunque distribuisci l’app, si comporta sempre allo stesso modo. Puoi eseguirla in ambienti diversi, ma essendo in un container non avrai il problema del “sul mio computer funziona”.

Crei un Dockerfile, un insieme di istruzioni che dice a Docker come configurare l’ambiente dell’app, installare i pacchetti necessari e avviarla. Fatto ciò, puoi costruire un’immagine Docker e avviare l’applicazione in un container. È efficiente, ripetibile e molto portabile.
Una volta che il sistema è pronto, vorrai probabilmente distribuirlo nel cloud. Questo lo rende accessibile ovunque e ti offre scalabilità, affidabilità e accesso ad altri servizi cloud che possono potenziare il sistema.
Vediamo alcune piattaforme popolari, tra cui Azure e Google Cloud:
AWS offre strumenti come Elastic Beanstalk, che semplifica molto la distribuzione. In pratica consegni il tuo container Docker e AWS si occupa di scalabilità, bilanciamento del carico e monitoraggio. Se ti serve più controllo, puoi usare Amazon ECS, che esegue i container Docker su un cluster di server e scala su o giù in base alle esigenze.
Heroku è un’altra opzione che semplifica la distribuzione. Effettui il push del codice e Heroku gestisce l’infrastruttura per te. È ottimo se non vuoi addentrarti troppo nei dettagli della gestione delle risorse cloud.
Azure offre Azure App Service, che ti consente di distribuire e gestire il tuo sistema RAG con facilità, con supporto integrato per auto-scaling, bilanciamento del carico e deployment continuo.
Per maggiore flessibilità, puoi usare Azure Kubernetes Service (AKS) per gestire i container Docker su larga scala, assicurandoti che il sistema gestisca traffico elevato con la possibilità di regolare dinamicamente le risorse.
GCP offre Google Cloud Run, una piattaforma completamente gestita che consente di distribuire i container e scalarli automaticamente in base al traffico.
Se vuoi più controllo sull’infrastruttura, puoi usare Google Kubernetes Engine (GKE), che ti permette di gestire e scalare i container Docker su più nodi, con l’integrazione dei servizi cloud di Google come API di IA e machine learning.
Ogni piattaforma ha i suoi punti di forza, a seconda che tu voglia semplicità e automazione o un controllo più granulare sul deployment.
In questo articolo abbiamo visto come costruire un sistema RAG usando LangChain e FastAPI. I sistemi RAG rappresentano un grande passo avanti nell’elaborazione del linguaggio naturale perché incorporano informazioni esterne, consentendo all’IA di generare risposte più accurate, pertinenti e consapevoli del contesto.
Con LangChain abbiamo un framework solido che gestisce tutto: dal caricamento dei documenti, alla suddivisione del testo e alla creazione degli embedding, fino al recupero delle informazioni in base alle query degli utenti.
Poi entra in gioco FastAPI, che ci offre un framework web veloce e pronto per l’asincronia, aiutandoci a distribuire il sistema RAG come un’API scalabile.
Insieme, questi strumenti semplificano la creazione di applicazioni IA in grado di gestire query complesse, fornire risposte precise e offrire un’esperienza utente migliore.
Ora tocca a te applicare quanto hai imparato ai tuoi progetti.
Pensa alle possibilità: interrogare la knowledge base interna della tua azienda, automatizzare i processi di revisione documentale, o creare chatbot intelligenti per il supporto clienti.
Non dimenticare — ci sono molti modi per estendere questa configurazione! Puoi sperimentare con richieste POST per inviare strutture dati più complesse o esplorare le connessioni WebSocket per interazioni in tempo reale.
Ti invito ad approfondire, sperimentare e vedere dove può portarti tutto questo. È solo l’inizio di ciò che puoi realizzare con LangChain, FastAPI e i moderni strumenti di IA! Ecco alcune risorse consigliate:
I migliori corsi DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

