
Kurs
LangChain ile LLM Uygulamaları Geliştirme
3 sa
46.2K
Retrieval-Augmented Generation (RAG), şu anda yapay zekâdaki en heyecan verici tekniklerden biri. Devasa veri kümelerinden gerçek bilgileri alma hassasiyetini büyük dil modellerinin muhakeme gücüyle birleştirir. Sonuç mu? Yalnızca doğru değil, aynı zamanda son derece ilgili yanıtlar. Bu yüzden RAG; sohbet botlarından arama motorlarına, kişiselleştirilmiş içerikten daha pek çok şeye güç veriyor.
Ama işin püf noktası şu: bir prototip inşa etmek mücadelenin yalnızca yarısı. Asıl zorluk yayına almakta: fikrinizi güvenilir ve ölçeklenebilir bir ürüne dönüştürmekte yatıyor.
Bu yazıda, RAG sistemini nasıl kurup dağıtacağınızı LangChain ve FastAPI kullanarak göstereceğim. Çalışan bir prototipten, gerçek kullanıcılar için hazır tam ölçekli bir uygulamaya nasıl geçeceğinizi öğreneceksiniz.
Haydi başlayalım!
Ayrı bir rehberde incelediğimiz üzere, Retrieval-Augmented Generation ya da RAG, dil modellerinin yapabildiklerini gerçekten bir üst seviyeye taşıyan, doğal dil işlemeye dair epey gelişmiş bir yöntemdir.
Modelin yalnızca kendi bildiklerine güvenmek yerine, RAG bir yanıt üretmeden önce dış kaynaklardan yeni ve ilgili bilgileri çekerek işi bir adım öteye taşır.
İşleyiş şöyle: kullanıcı bir soru sorduğunda, sistem yalnızca modelin önceden öğrendiklerine dayanmaz. Önce dış kaynaklardaki büyük bir belge veya veri kümesini tarar, en ilgili kısımları alır ve bunları dil modeline besler. Model de hem yerleşik bilgisi hem de yeni alınan bu bilgilerle çok daha doğru ve güncel bir yanıt üretebilir.
RAG, getirme ve üretimi harmanlar; böylece yanıtlar yalnızca akıllı olmakla kalmaz, aynı zamanda gerçek ve olgusal verilere dayanır. Bu da onu soru yanıtlamadan sohbet botlarına, içerik üretiminden bağlamın ve doğruluğun kritik olduğu her senaryoya kadar ideal kılar.
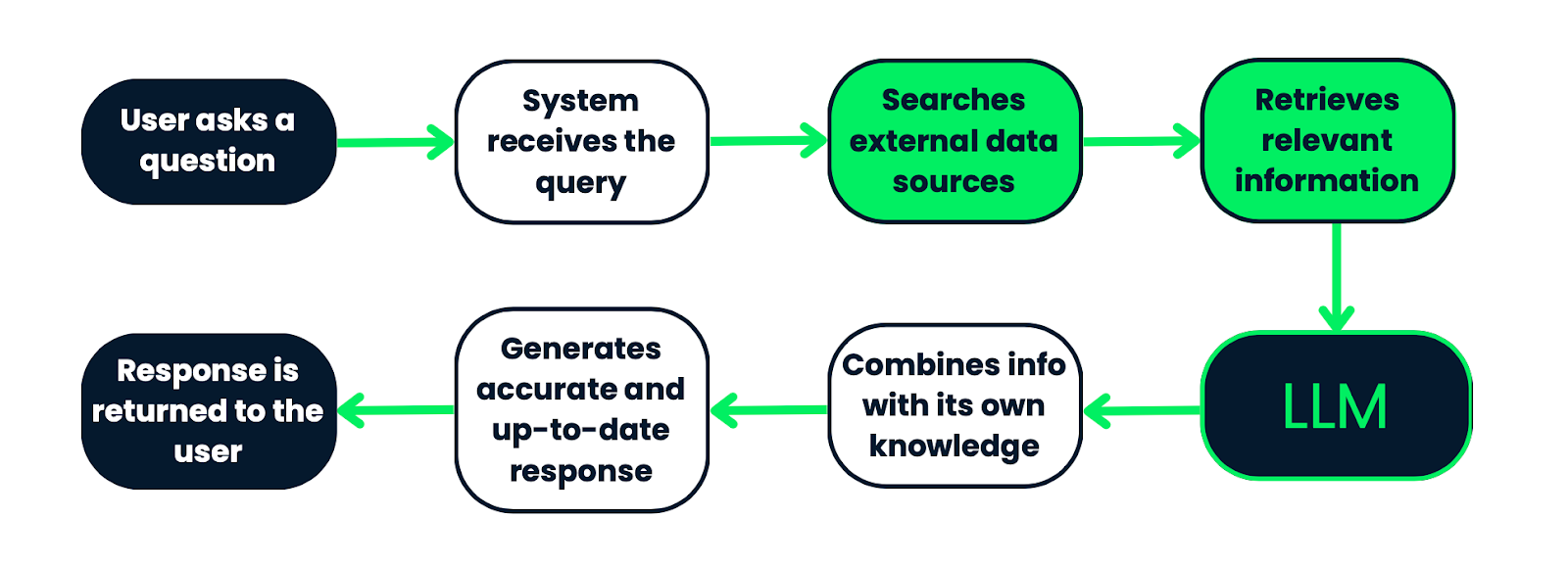
Bir RAG sisteminin iş akışı. Kullanıcı sorgusuyla başlar; sistem, ilgili bilgileri bulmak için haricî veri kaynaklarını arar. Alınan bilgiler daha sonra bir LLM’ye verilir; LLM bunları kendi ön bilgisiyle birleştirerek doğru ve güncel bir yanıt üretir. Son olarak yanıt kullanıcıya döndürülür. Bu süreç, yanıtların olgusal ve bağlamsal olarak ilgili verilere dayandığını garanti eder.
Bir RAG sistemi kurarken çalışır hâle getirmek için gereken bazı temel parçalar vardır: belge yükleyiciler, metin parçalama, indeksleme, getirme modelleri ve üretken modeller. Haydi parçalara ayıralım:
İlk adım veriyi hazırlamaktır. Bunu belge yükleyiciler, metin parçalama ve indeksleme yapar:
Bunlar RAG sisteminin kalbidir. İlgili olanı bulmak için tüm indekslenmiş veriyi taramaktan sorumludurlar.
Büyü tam burada gerçekleşir. İlgili veriler alındıktan sonra üretken modeller devreye girer ve nihai yanıtı üretir.
|
Bileşen |
Açıklama |
|
Belge Yükleyiciler |
Metin dosyaları, PDF’ler veya veritabanları gibi kaynaklardan veri çeker; bilgiyi sistem için kullanılabilir bir formata dönüştürür. |
|
Metin Parçalama |
Yüklenen veriyi daha küçük parçalara böler; bu da dil modellerinin sınırları içinde aramayı ve işlemeyi kolaylaştırır. |
|
İndeksleme |
Bölünmüş veriyi vektör gösterimlerine dönüştürerek bir sorgu için ilgili bilgileri bulmayı hızlı ve verimli kılar. |
|
Vektör Depoları |
Sorguya göre en ilgili bilgiyi almak için vektör benzerlik araması kullanan, vektör gösterimlerini saklayan özel veritabanları. |
|
Retriever’lar |
Sorguyu vektöre çeviren, vektör deposunda arama yapan ve bir sonraki adım için en ilgili metin parçalarını getiren arama bileşenleri. |
|
Dil Modelleri |
Alınan verileri ve içsel bilgiyi kullanarak tutarlı ve bağlama uygun yanıtlar üretir. |
|
Bağlamsal Yanıt Üretimi |
Kullanıcının sorusunu alınan verilerle birleştirerek, ilgili bilgileri içeren ayrıntılı bir yanıt üretir. |
RAG sistemimizi kurmadan önce geliştirme ortamımızın doğru şekilde ayarlandığından emin olmalıyız. İhtiyacınız olanlar şunlar:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsBağımlılıkları Yükleyin: Şimdi, gerekli paketleri pip ile yükleyin.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
API’ler oluşturmak için modern bir web çatısı. |
FastAPI uygulamanızı sunmak için bir ASGI sunucusu. |
||
|
RAG sistemine güç veren ana kütüphane. |
Yanıt üretimi için GPT modellerini kullanmak üzere. |
İpucu: Projeniz için gerekli paketleri belirtmek üzere bir requirements.txt dosyası oluşturduğunuzdan emin olun. Şunu kullanırsanız: pip freeze > requirements.txt
Bu komut, kurulu tüm paketleri ve sürümlerini içeren bir requirements.txt dosyası üretir; bunu dağıtımda veya ortamı başkalarıyla paylaşırken kullanabilirsiniz.
OpenAI API Anahtarınızı Ekleyin: OpenAI dil modelini RAG sisteminize entegre etmek için OpenAI API anahtarınızı sağlamanız gerekir:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Artık OpenAI API anahtarınız ortamdan güvenli şekilde yüklendi ve RAG sisteminizde kullanmaya hazırsınız!
PostgreSQL ve PGVector (İsteğe Bağlı): Vektör depolama için PGVector kullanmayı planlıyorsanız, makinenize PostgreSQL kurup yapılandırdığınızdan emin olun. FAISS’i (bu yazıda kullanacağız) veya LangChain’in desteklediği diğer vektör veritabanlarını da kullanabilirsiniz.
Docker (İsteğe Bağlı): Docker, uygulamanızı konteynerize ederek farklı ortamlarda tutarlı dağıtım yapmanızı sağlar. Docker kullanmayı planlıyorsanız, makinenizde kurulu olduğundan emin olun.
Bir RAG sistemi kurmanın ilk adımı, sistemin ilgili bilgileri almak için kullanacağı verileri hazırlamaktır. Bu; belgeleri sisteme yüklemeyi, işlemeyi ve kolayca indekslenip getirilebilecek bir formata sokmayı içerir.
LangChain; metin dosyaları, PDF’ler veya web sayfaları gibi farklı veri kaynaklarını işlemek için çeşitli belge yükleyiciler sağlar. Belgelerinizi sisteme almak için bu yükleyicileri kullanabilirsiniz.
Kutup ayılarına ilgim var; bu nedenle aşağıdaki metni içeren (my_document.txt) dosyasını yüklemeye karar verdim:“Kutup Ayıları: Arktik’in Devleri
Kutup ayıları (Ursus maritimus) yeryüzündeki en büyük kara etoburlarıdır ve Arktik’in aşırı soğuğuna mükemmel şekilde uyum sağlamışlardır. Onları karlı manzaraya karışmalarını sağlayan kalın beyaz kürkleriyle tanırız; kutup ayıları güçlü avcılardır ve başlıca besin kaynakları olan fokları avlamak için deniz buzuna güvenirler.
Kutup ayılarıyla ilgili büyüleyici olan, çevrelerine inanılmaz uyum sağlamalarıdır. O kalın kürkün altında, 4,5 inçe kadar çıkabilen bir yağ tabakası bulunur; bu tabaka sert kış aylarında yalıtım ve enerji rezervi sağlar. Büyük patileri hem buz hem de açık suda ilerlemelerine yardımcı olur; onları güçlü yüzücüler yapar—yiyecek veya yeni yaşam alanı ararken uzun mesafeleri kat edebilirler.
Ne yazık ki kutup ayıları iklim değişikliğinden kaynaklanan ciddi tehditlerle karşı karşıya. Arktik ısınırken deniz buzu yılın daha erken dönemlerinde eriyor ve daha geç oluşuyor; bu da kutup ayılarının fok avlamak için sahip oldukları zamanı azaltıyor. Yeterli yiyecek bulamayan birçok ayı hayatta kalmakta zorlanıyor ve bazı bölgelerde nüfusları azalıyor.
Kutup ayıları, Arktik ekosisteminin sağlığını korumada kritik bir rol oynar ve içinde bulundukları durum, iklim değişikliğinin dünya yaban hayatı üzerindeki daha geniş etkilerine güçlü bir hatırlatmadır. Yaşam alanlarını korumak ve bu görkemli canlıların vahşi doğada varlığını sürdürmesini sağlamak için koruma çalışmaları yürütülmektedir.”
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Burada örnek olması için sisteme yüklenmiş basit bir metin dosyası görüyoruz; ancak istediğiniz her tür belgeyi ekleyebilirsiniz! Örneğin, kurumunuzun iç dokümantasyonunu ekleyebilirsiniz. Artık documents değişkeni, dosyanın içeriğini barındırıyor ve işlenmeye hazır.
Büyük belgeler, indekslemeyi ve getirmeyi kolaylaştırmak için genellikle daha küçük parçalara bölünür. Bu süreç, küçük parçaların model için daha yönetilebilir olması ve daha isabetli getirme sağlaması nedeniyle çok önemlidir. Daha fazlasını AI ve RAG için parçalama stratejileri rehberimizde öğrenebilirsiniz.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Burada metin, her biri 500 karakterlik parçalara ayrılıyor ve parçalar arasında 50 karakterlik örtüşme bulunuyor. Bu örtüşme, getirme sırasında parçalar arasındaki bağlamın korunmasına yardımcı olur.
Veri hazırlandıktan sonra sıradaki adım, verimli getirme için indekslemektir. İndeksleme, metin parçalarının vektör gömlemelerine dönüştürülmesini ve bir vektör deposunda saklanmasını içerir.
LangChain, OpenAI veya HuggingFace gibi çeşitli modelleri kullanarak vektör gömlemeleri oluşturmayı destekler. Bu gömlemeler, metin parçalarının anlamsal içeriğini temsil eder; bu da onları benzerlik aramaları için uygun kılar.
Basitçe söylemek gerekirse, gömlemeler; bir belgeden bir paragraf gibi metinleri, bir yapay zekâ modelinin anlayabileceği sayılara dönüştürmenin bir yoludur. Bu sayılar (vektörler), metnin anlamını modelin işlemesini kolaylaştıracak bir biçimde temsil eder.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()OpenAI’nin gömlemelerini bu dönüşümü gerçekleştirmek için kullanıyoruz. Önce OpenAI’nin gömme aracını içe aktarıyoruz, ardından kullanıma hazır hâle getirmek için başlatıyoruz.
Gömlemeler üretildikten sonra sıradaki adım, bunları PGVector, FAISS veya LangChain’in desteklediği diğer bir vektör deposunda saklamaktır. Bu, bir sorgu yapıldığında ilgili belgelerin hızlı ve doğru şekilde getirilmesini sağlar.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)Bu durumda, büyük vektör kümelerinde arama yapmak için tasarlanmış harika bir araç olan FAISS kullanıyoruz. FAISS, en benzer vektörleri çok hızlı bulmamıza yardımcı olur.
Yani olan şey şu: FAISS’i LangChain’den içe aktarıyoruz ve bir vektör deposu oluşturmak için kullanıyoruz. Bu, vektörleri verimli şekilde saklayıp aramak için özel olarak oluşturulmuş bir veritabanı gibidir.
Bu yapının güzelliği, daha sonra arama yaptığımızda FAISS’in tüm vektörleri tarayıp sorguyla en benzer olanları bulması ve karşılık gelen belge parçalarını döndürmesidir.
Veriler indekslendikten sonra, kullanıcı sorgularına göre ilgili bilgileri getirmekten sorumlu getirme bileşenini uygulayabilirsiniz.
Şimdi bir retriever kuruyoruz. Bu, indekslenmiş belgeler arasında gezinen ve kullanıcının sorgusuna en uygun olanları bulan bileşendir.
Buradaki güzel nokta, rastgele değil; gömlemelerin gücüyle akıllıca arama yapmanızdır; böylece elde ettiğiniz sonuçlar, kullanıcının sorduğuyla anlamsal olarak benzerdir. Kod satırına yakından bakalım:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Önce vektör deposunu bir retriever’a dönüştürüyoruz. FAISS vektör deponuz zaten belge gömlemeleriyle dolu ya; şimdi ona “Kullanıcı bir soru sorduğunda onu aramak için bunu kullan” diyoruz.
search_type ise büyünün gerçekleştiği yer. Retriever farklı şekillerde arama yapabilir ve burada birkaç seçeneğiniz var. Benzerlik araması getirmelerin bel kemiğidir. Sorguyla anlamca en yakın belgeleri bulur.
Yani "search_type='similarity'" dediğinizde retriever’a, “Oluşturduğumuz gömlemelere göre sorguya en benzer belgeleri bul” demiş oluyorsunuz.
search_kwargs={"k": 5} ile de ince ayar yapıyorsunuz. k değeri, retriever’ın vektör deposundan kaç belge çekeceğini söyler. Bu örnekte k=5, “En ilgili 5 belgeyi getir” anlamına geliyor.
Bu çok güçlüdür çünkü gürültüyü azaltır. Kısmen ilgili çok sayıda sonuç yerine, en önemli bilgi parçalarını alırsınız.
Bu bölümde, LangChain kullanarak RAG sisteminizin çekirdek motorunu kuruyoruz. Sorguya göre ilgili belgeleri çekebilen bir retriever’ınız zaten var.
Şimdi LLM’i ekliyor ve getirilen belgelere dayanarak yanıt oluşturmak için kullanıyoruz.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQABurada iki önemli öğeyi içe aktarıyoruz:
llm = OpenAI(openai_api_key=openai_api_key)Bu satır, OpenAI API anahtarınızı kullanarak LLM’i başlatır. Bunu sisteminizin beynini yüklemek gibi düşünün—metni alıp anlayacak ve yanıtlar üretecek modeldir.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)İşte heyecan verici kısım. QA Zincirini kuruyoruz ve her şeyi birbirine bağlıyoruz. RetrievalQA.from_chain_type() yöntemi bir soru-cevap zinciri oluşturur; bu, “Retriever ve LLM’i birleştir; getirilen belgelere dayalı yanıt üreten bir sistem oluştur” demektir.
Ardından, yeni başlattığımız OpenAI LLM’ini cevapları üretmek için kullanmasını söylüyoruz. Sonrasında da daha önce kurduğunuz retriever’ı bağlıyoruz. Retriever, kullanıcının sorgusuna göre ilgili belgeleri bulmaktan sorumludur.
chain_type="stuff" ayarlıyoruz: Peki “stuff” nedir? Aslında LangChain’de bir zincir türüdür. “Stuff”, getirilen tüm ilgili belgeleri LLM’e yükleyip, onun her şeye dayanarak yanıt üretmesi anlamına gelir.
Bu, LLM’in masasının üzerine bir sürü notu bırakıp “İşte, soruyu yanıtlamak için bunların hepsini kullan” demeye benzer.
Başka zincir türleri de vardır ("map_reduce" veya "refine" gibi), ancak “stuff” en basit ve en doğrudan olandır.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Burada sisteme bir soru sorduğumuz ve yanıt aldığımız kısımdayız. invoke() yöntemi tüm boru hattını tetikler.
Sorgunuzu alır, ilgili belgeleri getirmek için retriever’a gönderir ve ardından bu belgeleri LLM’e aktarır; LLM de nihai yanıtı üretir.
print(response)Son olarak, LLM tarafından üretilen yanıtı yazdırır. Getirilen belgelere dayanarak sistem, sorguya kapsamlı ve bilgili bir yanıt üretir ve bu yanıt yazdırılır.
Nihai betik şu şekildedir:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Şimdi RAG sisteminizle etkileşim kurmak için bir API inşa etme zamanı. Peki bu adım dağıtımda neden gerekli?
Bu eğitimi takip ettiniz ve belgelerinize ve ihtiyaçlarınıza göre kişiselleştirilmiş harika bir RAG sistemi kurdunuz—ilgili bilgileri çekiyor, sorguları işliyor ve akıllı yanıtlar üretiyor. Peki kullanıcıların veya diğer sistemlerin bununla nasıl etkileşim kurmasını sağlarsınız?
FastAPI aradaki aracınızdır. Kullanıcıların veya uygulamaların RAG sisteminize soru sorması ve yanıt alması için basit, yapılandırılmış bir yol sunar.
FastAPI eşzamanlı olmayan ve yüksek performanslıdır. Bu, aynı anda birçok isteği yavaşlamadan işleyebileceği anlamına gelir—bu da büyük veri parçalarını getirebilen veya karmaşık sorgular çalıştırabilen AI sistemleriyle uğraşırken çok önemlidir.
Bu bölümde, önceki betiği değiştirecek ve RAG sisteminizin erişilebilir, ölçeklenebilir ve gerçek dünya trafiğini karşılamaya hazır olmasını sağlamak için ek betikler oluşturacağız.Öncelikle, RAG sistemine gelen istekleri karşılayacak yolları oluşturalım.
Çalışma dizininizde bir main.py dosyası oluşturun. Bu, FastAPI uygulaması için giriş noktanızdır. FastAPI’nin beyni gibi—bu dosya tüm API yollarını, bağımlılıkları ve RAG sistemini bir araya getirecek.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)Oldukça basit ama temiz bir kurulum. Burada bir FastAPI örneği oluşturuyor ve ardından bir sonraki adımda oluşturacağımız başka bir dosyadan tüm yolları (veya API patikalarını) içe alıyoruz.
Şimdi her şeyin bir araya geldiği yer burası. Kullanıcı bir sorgu gönderdiğinde RAG sisteminizi gerçekten çalıştıracak bir işlev yazacağız.
async def get_rag_response(query: str):Bu işlev async olarak işaretlenmiştir; yani eşzamanlı olmayan bir işlevdir. Yanıt beklerken başka işleri de ele alabileceği anlamına gelir.
Bu özellik, belgelerin getirilmesi veya bir LLM’in sorgulanması zaman alabileceği için getirmeye dayalı sistemlerde özellikle faydalıdır. Bu sayede FastAPI, bu işlem arka planda çalışırken diğer istekleri işleyebilir.
retriever = setup_rag_system()Burada, daha önce konuştuğumuz setup_rag_system() işlevini çağırıyoruz; bu işlev tüm retriever hattını başlatır. Bu şu anlama gelir:
Bu retriever, kullanıcının sorgusuna göre ilgili metin parçalarını getirmekten sorumlu olacaktır.
Artık bir kullanıcı soru sorduğunda, retriever vektör deposundaki tüm belgeleri tarar ve sorguya göre en ilgili olanları getirir.
retrieved_docs = retriever.get_relevant_documents(query)Bu invoke(query) yöntemi ilgili belgeleri getirir. Arka planda, sorguyu gömme vektörleriyle eşleştirir ve benzerliğe göre en iyi eşleşmeleri çıkarır.
Artık ilgili belgelere sahip olduğumuza göre, bunları LLM için biçimlendirmemiz gerekiyor.
context = "\n".join([doc.page_content for doc in retrieved_docs])Burada, getirilen tüm belgeleri alıp içeriklerini tek bir metin olarak birleştiriyoruz. Bu önemlidir çünkü LLM bir sürü ayrı parça yerine temiz bir metin bloğu bekler.
Python’un join() işlevini kullanarak bu belge parçalarını tek bir tutarlı bilgi bloğu hâline getiriyoruz. Her belgenin içeriği doc.page_content alanında saklanır ve bunları yeni satırlarla (\n) birleştiriyoruz.
Şimdi LLM için istemi oluşturuyoruz.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]İstem, LLM’e getirilen bilgileri kullanarak kullanıcının sorusunu yanıtlamasını söyleyecek şekilde yapılandırılmıştır.
Şimdi yanıt üretme zamanı.
generated_response = llm.generate(prompt) # Pass as a list of stringsBurada OpenAI modeli, istemi alıp hem soruya hem de ilgili belgelere dayalı bağlama duyarlı bir yanıt üretmekle görevlendirilir.
Son olarak, üretilen yanıtı (ister bir kullanıcı, ister bir ön uç uygulaması, ister başka bir sistem çağırmış olsun) işlevi çağıran tarafa döndürüyoruz.
return generated_responseBu yanıt tamamen şekillenmiş, bağlamsal ve gerçek dünya uygulamalarında kullanılmaya hazırdır.
Özetle, bu işlev tam bir getirme ve üretim döngüsü yürütür. Akışın hızlı bir özeti:
1. İlgili belgeleri bulmak için retriever kurulur.
2. Belgeler sorguya göre çekilir.
3. Bu belgelerden gelen bağlam LLM için hazırlanır.
4. LLM, bu bağlamı kullanarak nihai bir yanıt üretir.
5. Yanıt kullanıcıya döndürülür.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.py içinde API Rotalarını TanımlamaSırada endpoints.py dosyamızı oluşturalım. Kullanıcıların RAG sisteminizle etkileşim kurmak için çağıracağı gerçek yolları burada tanımlayacağız.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))API rotalarını yönetmek için bir APIRouter oluşturuyoruz. /query/ uç noktası, bir sorgu dizesi alan bir GET isteği kabul edecek şekilde tanımlanır. rag.py dosyanızdaki get_rag_response işlevini çağırır; bu işlev tüm RAG hattını (belge getirme + dil üretimi) yürütür. Bir şeyler ters giderse ayrıntılı bir mesajla 500 HTTP hatası fırlatırız.
Tüm bunları kurduktan sonra FastAPI uygulamanızı Uvicorn ile çalıştırabilirsiniz. Bu, kullanıcıların API’nize erişmesini sağlayacak web sunucusudur.
Terminale gidip şunu çalıştırın:
uvicorn app.main:app --reloadapp.main:app, Uvicorn’a main.py dosyasındaki app örneğini aramasını söyler ve --reload kodunuzda değişiklik yaptığınızda otomatik yeniden yüklemeyi etkinleştirir.
Sunucu çalışırken tarayıcınızı açıp http://127.0.0.1:8000/docs adresine gidin. FastAPI, API’niz için otomatik olarak Swagger UI dokümantasyonu üretir; böylece doğrudan tarayıcınızdan test edebilirsiniz!
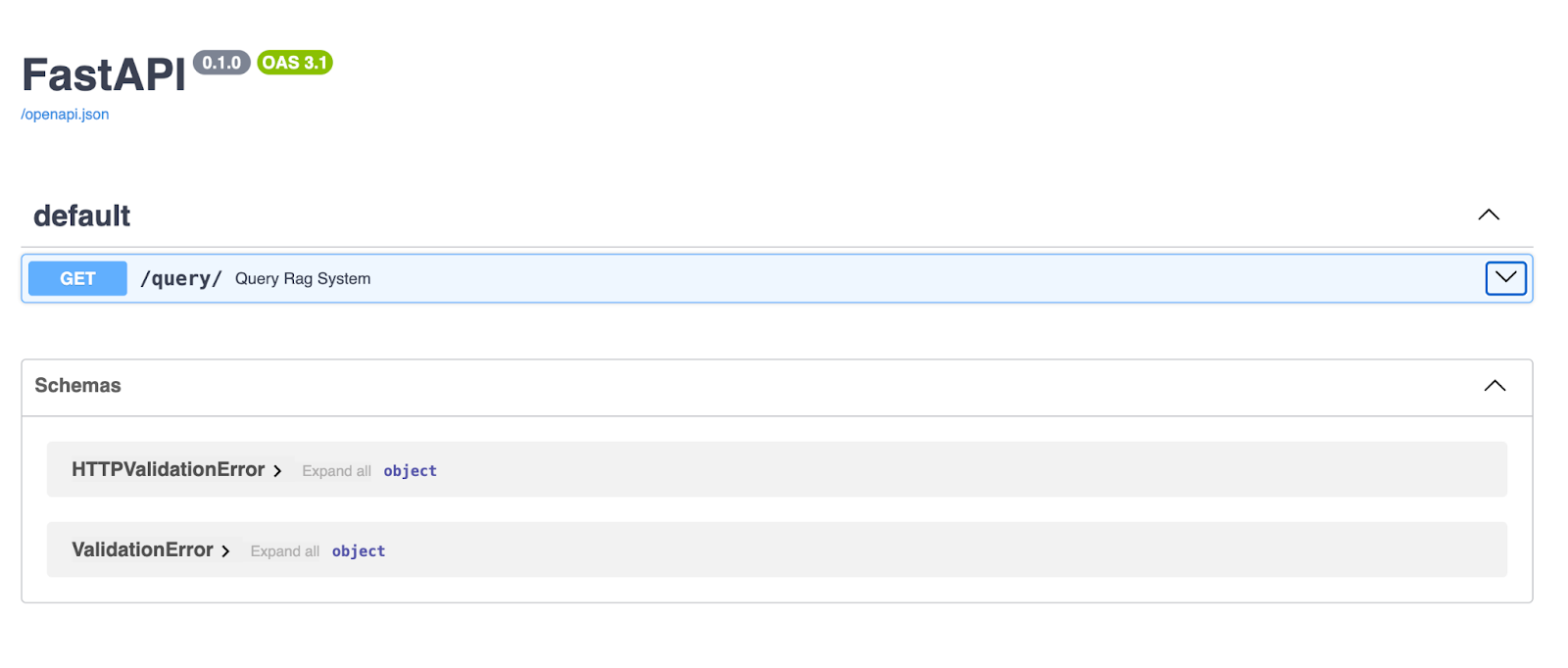
FastAPI Swagger UI, API uç noktalarınızı keşfetmek ve test etmek için temiz ve etkileşimli bir arayüz sağlar. Burada, /query/ uç noktası kullanıcıların bir sorgu dizesi girmesine ve RAG boru hattı tarafından üretilen bir yanıt almasına olanak tanır.
FastAPI sunucunuz çalışırken, tarayıcınızla veya Postman ya da Curl kullanarak /query/ uç noktanıza bir GET isteği yapın.
Tarayıcıda, Swagger üzerinden:
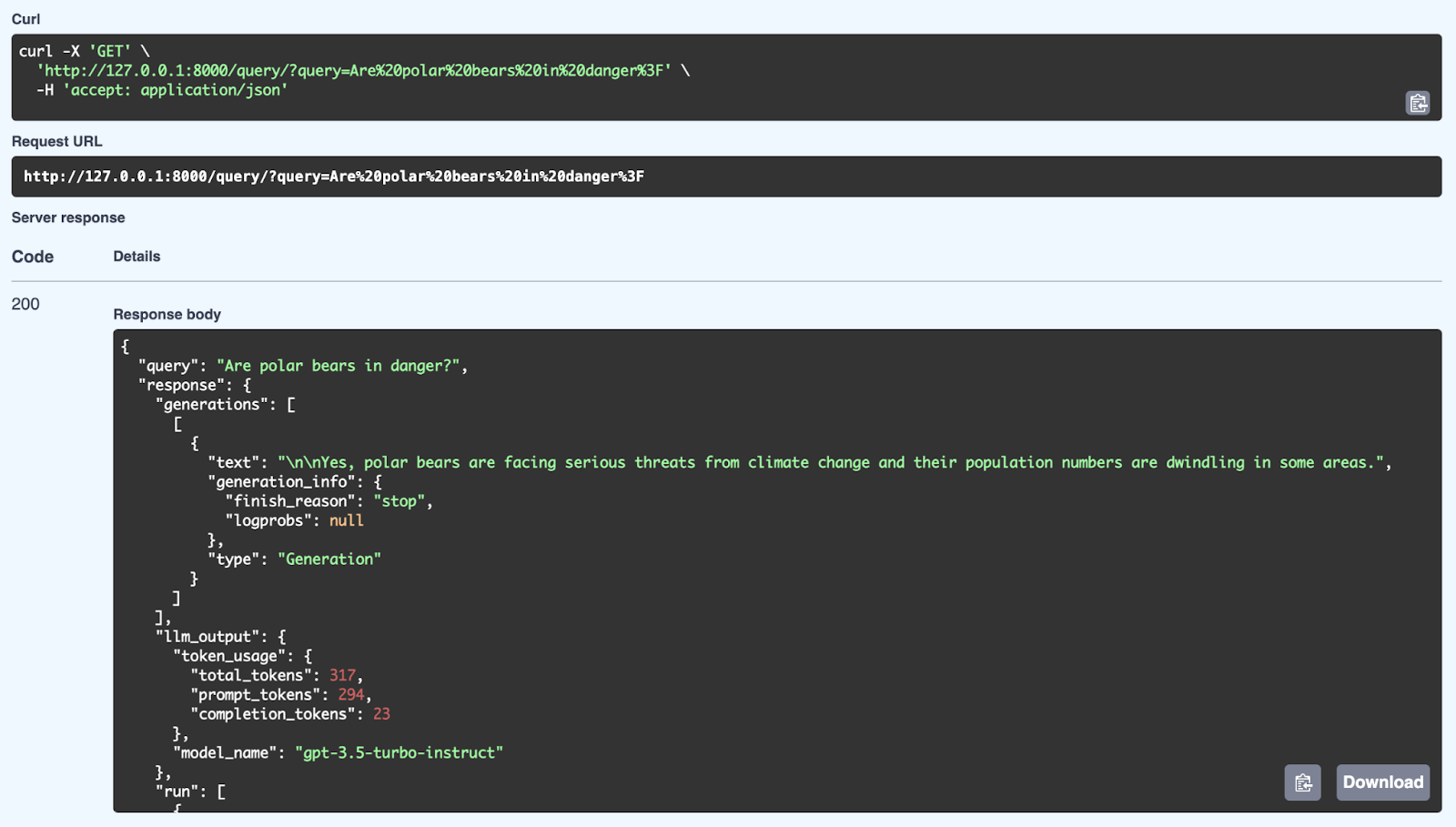
Burada “Are polar bears in danger?” sorgusunu kullanarak RAG sisteminden alınan başarılı bir yanıtı görüyoruz. Sistem, bilgi tabanından ilgili bilgileri getirir ve GPT-3.5 Turbo-Instruct modelini kullanarak tutarlı bir yanıt üretir. Ayrıntılı yanıtta yalnızca cevap (Evet, kutup ayıları iklim değişikliğinden kaynaklanan ciddi tehditlerle karşı karşıya ve bazı bölgelerde nüfusları azalıyor) değil, aynı zamanda kullanılan belirteç sayısı (işlenen token sayısı) ve üretimde kullanılan model gibi metaveriler de bulunur. API, FastAPI aracılığıyla hem getirme hem de üretim mekanizmalarını kullanarak iyi yapılandırılmış ve bağlama duyarlı yanıtlar sunabilir.
Şimdi FastAPI’de Eşzamanlı Olmayan (Asenkron) İşlemenin avantajlarından ve gerçek dünya API isteklerini karşılamada neden bu kadar fark yarattığından bahsedelim.
RAG sisteminizi kurdunuz. API soruları alıyor, bilgi tabanından ilgili bilgileri getiriyor ve bir dil modeliyle yanıtlar üretiyor.
Eğer tüm bu süreç eşzamanlı olsaydı, sistem bir sonraki adıma geçmeden önce her görevin tamamlanmasını beklerdi. Örneğin, belgeleri getirirken yeni istekleri işleyemezdi.
|
Engellemesiz G/Ç |
Geliştirilmiş Performans |
Daha İyi Kullanıcı Deneyimi |
|
Async işlevler, sunucunun bir isteğin bitmesini beklemek yerine aynı anda birden çok isteği işlemesine imkân verir. |
Bir vektör deposundan belge getirmek veya metin üretmek gibi görevler için asenkron işleme, API’nizin yüksek yükleri verimli şekilde yönetmesini sağlar. |
İstemciler daha hızlı yanıt alır ve API’niz yoğun kullanım altında bile duyarlı kalır. |
Şimdi dağıtım stratejilerinden bahsedelim—RAG sisteminizi bir prototipten tam anlamıyla çalışan bir ürüne dönüştürmenin çok önemli bir adımı. Hedef; sisteminizin paketlenmiş, dağıtılmış ve ölçeklenmeye hazır olduğundan; gerçek kullanıcıları karşılayabileceğinden emin olmaktır.
Önce Docker hakkında konuşalım. Docker, RAG sisteminizin ihtiyaç duyduğu her şeyi—kodunu, bağımlılıklarını, yapılandırmalarını—sihirli bir kutu gibi paketleyip derli toplu bir konteynere sığdırır.
Bu, uygulamanızı nerede dağıtırsanız dağıtın aynı şekilde davranmasını sağlar. Uygulamanızı farklı ortamlarda çalıştırabilirsiniz; ancak konteynerde olduğu için “benim makinemde çalışıyor” sorununu düşünmenize gerek kalmaz.

Bir Dockerfile oluşturursunuz; bu dosya Docker’a uygulamanızın ortamını nasıl kuracağını, gerekli paketleri nasıl yükleyeceğini ve nasıl çalıştıracağını anlatan bir dizi talimattır. Bu hazır olduğunda, bundan bir Docker imajı oluşturup uygulamanızı bir konteyner içinde çalıştırabilirsiniz. Verimli, tekrarlanabilir ve son derece taşınabilirdir.
Sisteminiz paketlenip hazır hâle geldikten sonra muhtemelen buluta dağıtmak isteyeceksiniz. Burası ilginçleşir; çünkü RAG sisteminizi buluta dağıtmak, dünyanın her yerinden erişilebilir kılar. Ayrıca ölçeklenebilirlik, güvenilirlik ve sisteminizi güçlendirebilecek diğer bulut hizmetlerine erişim sağlar.
Azure ve Google Cloud dâhil olmak üzere birkaç popüler bulut platformuna bakalım:
AWS, dağıtımı kolaylaştıran Elastic Beanstalk gibi araçlar sunar. Temelde Docker konteynerinizi verirsiniz; AWS ölçeklendirme, yük dengeleme ve izlemeyi halleder. Daha fazla kontrol isterseniz, Docker konteynerlerinizi sunucu kümelerinde çalıştırıp ihtiyaca göre ölçeklemek için Amazon ECS kullanabilirsiniz.
Heroku, dağıtımı basitleştiren bir başka seçenektir. Kodu itersiniz ve Heroku altyapıyı sizin için yönetir. Bulut kaynaklarını yönetmenin teknik detaylarına çok girmek istemiyorsanız iyi bir tercihtir.
Azure, RAG sisteminizi kolayca dağıtıp yönetebileceğiniz Azure App Service’i sunar; otomatik ölçeklendirme, yük dengeleme ve sürekli dağıtım için yerleşik destek sağlar.
Daha fazla esneklik için, Docker konteynerlerinizi ölçekli şekilde yönetmek üzere Azure Kubernetes Service’i (AKS) kullanabilirsiniz; bu sayede sisteminiz, kaynakları ihtiyaçlara göre dinamik olarak ayarlayıp yüksek trafiği kaldırabilir.
GCP, konteynerlerinizi dağıtıp trafiğe göre otomatik ölçekleyebileceğiniz, tamamen yönetilen Google Cloud Run’ı sunar.
Altyapınız üzerinde daha fazla kontrol istiyorsanız, Docker konteynerlerini çok sayıda düğümde yönetip ölçekleyebileceğiniz Google Kubernetes Engine’i (GKE) kullanabilirsiniz; ayrıca Google’ın AI ve makine öğrenimi API’leri gibi bulut hizmetleriyle derin entegrasyon avantajı sağlar.
İster sadelik ve otomasyon, ister dağıtım üzerinde daha ayrıntılı kontrol isteyin; her platformun güçlü yönleri vardır.
Bu yazıda LangChain ve FastAPI kullanarak bir RAG sistemi kurma sürecini adım adım ele aldık. RAG sistemleri, dış bilgileri devreye soktukları için doğal dil işleme alanında büyük bir sıçrama; böylece AI daha doğru, ilgili ve bağlama duyarlı yanıtlar üretebiliyor.
LangChain ile; belge yüklemeden metin parçalamaya, gömlemeler oluşturmaktan kullanıcı sorgularına göre bilgi getirmeye kadar her şeyi yöneten sağlam bir çatıya sahibiz.
Ardından FastAPI devreye girerek, RAG sistemimizi ölçeklenebilir bir API olarak dağıtmamıza yardımcı olan hızlı ve asenkron hazır bir web çatısı sunuyor.
Birlikte, bu araçlar; karmaşık sorguları karşılayabilen, isabetli yanıtlar sunabilen ve nihayetinde daha iyi bir kullanıcı deneyimi sağlayan AI uygulamaları geliştirmeyi kolaylaştırır.
Artık öğrendiklerinizi kendi projelerinize uygulama zamanı.
Olasılıkları düşünün: kendi şirketinizin iç bilgi tabanını sorgulamak, belge inceleme süreçlerini otomatikleştirmek veya müşteri desteği için akıllı sohbet botları oluşturmak.
Unutmayın—bu kurulumu genişletmenin sayısız yolu var! Daha karmaşık veri yapıları göndermek için POST istekleriyle deneyler yapabilir veya gerçek zamanlı etkileşimler için WebSocket bağlantılarını keşfedebilirsiniz.
Daha derine inmeye, denemeye ve bunun sizi nereye götürebileceğini görmeye sizi teşvik ediyorum. Bu, LangChain, FastAPI ve modern AI araçlarıyla neler başarabileceğinizin yalnızca başlangıcı! İşte önerdiğim bazı kaynaklar:
En İyi DataCamp Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
