
Cursus
LLM-toepassingen ontwikkelen met LangChain
3 Hr
47.9K
Retrieval-Augmented Generation (RAG) is op dit moment een van de spannendste technieken in AI. Het combineert de precisie van het ophalen van echte informatie uit enorme datasets met het redeneervermogen van grote taalmodellen. Het resultaat? Antwoorden die niet alleen accuraat zijn, maar ook diep relevant. Daarom drijft RAG alles aan, van chatbots en zoekmachines tot gepersonaliseerde content.
Maar hier zit het addertje: een prototype bouwen is nog maar de helft van het werk. De echte uitdaging zit in de uitrol: je idee omzetten in een betrouwbaar, schaalbaar product.
In dit artikel laat ik je zien hoe je een RAG-systeem bouwt en uitrolt met LangChain en FastAPI. Je leert hoe je van een werkend prototype naar een volwaardige applicatie gaat, klaar voor echte gebruikers.
Laten we erin duiken!
Zoals we in een aparte gids verkennen, is Retrieval-Augmented Generation, of RAG, een behoorlijk geavanceerde methode in natural language processing die de capaciteiten van taalmodellen flink opschroeft.
In plaats van alleen te vertrouwen op wat het model al weet, gaat RAG een stap verder door eerst nieuwe, relevante info uit externe bronnen op te halen voordat er een antwoord wordt gegenereerd.
Zo werkt het: wanneer een gebruiker een vraag stelt, vertrouwt het systeem niet alleen op de voorgeleerde data van het model. Het gaat eerst op pad, doorzoekt een grote set documenten of databronnen, pikt de meest relevante stukken eruit en voert die aan het taalmodel. Met zowel de ingebouwde kennis als deze nieuw opgehaalde info kan het model een antwoord creëren dat veel nauwkeuriger en actueler is.
RAG combineert retrieval en generatie, waardoor antwoorden niet alleen slim zijn, maar ook gestoeld op echte, feitelijke info. Dat maakt het ideaal voor zaken als vraagbeantwoording, chatbots of zelfs het genereren van content waar feitelijke juistheid en context echt tellen.
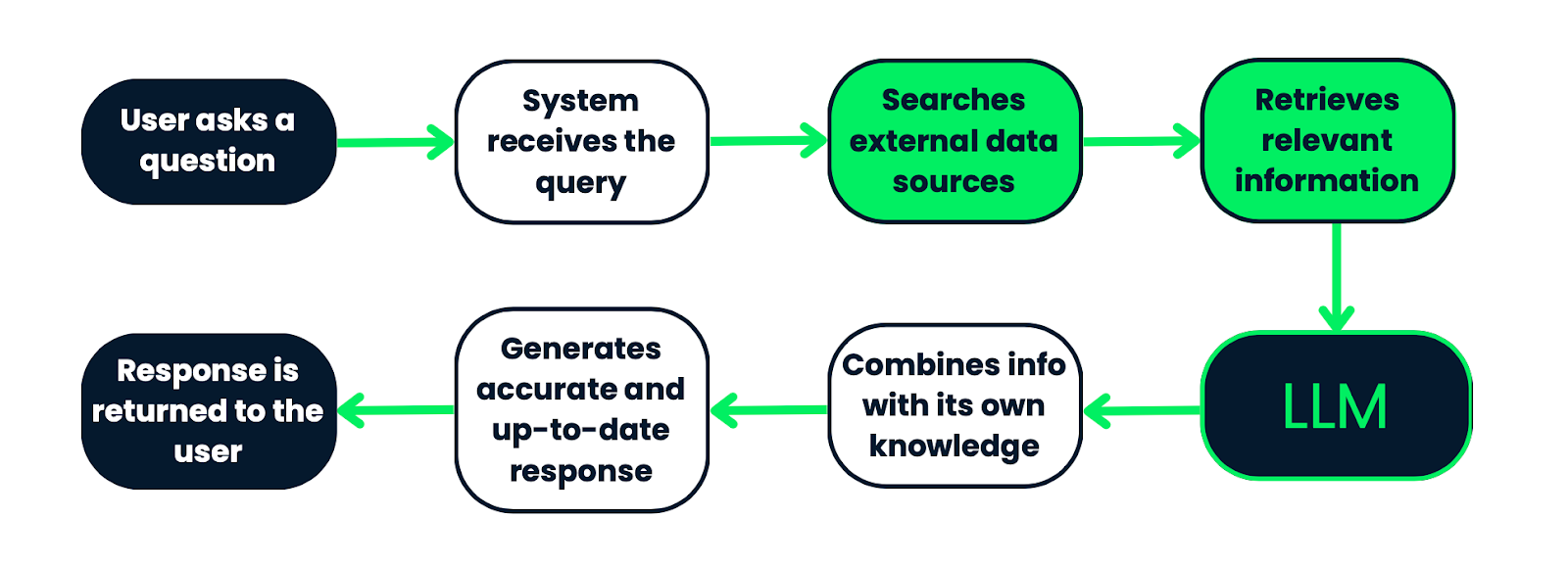
Workflow van een RAG-systeem. Het begint met een gebruikersvraag, die door het systeem wordt verwerkt om externe databronnen te doorzoeken naar relevante informatie. De opgehaalde informatie wordt vervolgens ingevoerd in een LLM, dat deze combineert met zijn bestaande kennis om een accuraat en actueel antwoord te genereren. Tot slot wordt het antwoord aan de gebruiker teruggegeven. Dit proces zorgt ervoor dat antwoorden zijn gebaseerd op feitelijke, contextueel relevante data.
Als je een RAG-systeem bouwt, zijn er een paar essentiële onderdelen nodig om het werkend te krijgen: documentloaders, tekstsplitsing, indexering, retrievalmodellen en generatieve modellen. Laten we het uitsplitsen:
De eerste stap is je data gereedmaken. Dat is wat documentloaders, tekstsplitsing en indexering doen:
Dit zijn het hart van het RAG-systeem. Ze zijn verantwoordelijk voor het doorspitten van alle geïndexeerde data om te vinden wat je nodig hebt.
Hier gebeurt de magie. Zodra de relevante data is opgehaald, nemen de generatieve modellen het over en produceren ze een eindantwoord.
|
Component |
Beschrijving |
|
Document Loaders |
Halen data op uit bronnen zoals tekstbestanden, pdf’s of databases en zetten de info om in een bruikbaar formaat voor het systeem. |
|
Text Splitting |
Knipt geladen data in kleinere brokken, waardoor zoeken en verwerken binnen de limieten van taalmodellen makkelijker wordt. |
|
Indexing |
Organiseert gesplitste data in vectorrepresentaties, wat snelle en efficiënte zoekacties mogelijk maakt om relevante informatie voor een query te vinden. |
|
Vector Stores |
Gespecialiseerde databases die vectorrepresentaties opslaan en via vector similarity search de meest relevante informatie ophalen op basis van de query. |
|
Retrievers |
Zoekcomponenten die de query omzetten in een vector, de vectorstore doorzoeken en de meest relevante databrokken ophalen voor de volgende stap. |
|
Language Models |
Genereren coherente en contextueel passende antwoorden met zowel opgehaalde data als interne kennis. |
|
Contextual Response Generation |
Combineert de vraag van de gebruiker met de opgehaalde data om een gedetailleerd antwoord te creëren dat de vraag beantwoordt en de relevante informatie integreert. |
Voordat we ons RAG-systeem bouwen, moeten we zorgen dat de ontwikkelomgeving goed is ingericht. Dit heb je nodig:
python --versionpython3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For WindowsInstalleer dependencies: Installeer nu de benodigde packages met pip.
pip install fastapi uvicorn langchain langchain-community openai langchain-openai faiss-cpu|
FastAPI |
Uvicorn |
LangChain |
OpenAI API |
|
Een modern webframework voor het bouwen van API’s. |
Een ASGI-server om je FastAPI-app te draaien. |
De hoofdbibliotheek die het RAG-systeem aandrijft. |
Om GPT-modellen te gebruiken voor het genereren van antwoorden. |
Pro tip: Maak een requirements.txt-bestand aan om de benodigde packages voor je project vast te leggen. Als je gebruikt: pip freeze > requirements.txt
Dit commando genereert een requirements.txt met alle geïnstalleerde packages en hun versies, die je kunt gebruiken voor deployment of om de omgeving met anderen te delen.
Voeg je OpenAI API-sleutel toe: Om het OpenAI-taalmodel te integreren in je RAG-systeem, moet je je OpenAI API-sleutel opgeven:
OPENAI_API_KEY=your-openai-api-keypip install python-dotenvfrom dotenv import load_dotenv
import os
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")Nu wordt je OpenAI API-sleutel veilig uit de omgeving geladen en ben je klaar om die in je RAG-systeem te gebruiken!
PostgreSQL en PGVector (optioneel): Als je van plan bent PGVector te gebruiken voor vectoropslag, installeer en configureer dan PostgreSQL op je machine. Je kunt FAISS gebruiken (dat we in dit artikel gebruiken) of andere vectordatabases die LangChain ondersteunt.
Docker (optioneel): Docker kan je helpen je applicatie te containerizen voor consistente uitrol in verschillende omgevingen. Als je Docker wilt gebruiken, zorg dan ook dat het op je machine is geïnstalleerd.
De eerste stap bij het bouwen van een RAG-systeem is het voorbereiden van de data die het systeem gebruikt om relevante informatie op te halen. Dit omvat het laden van documenten in het systeem, ze verwerken en er vervolgens voor zorgen dat ze in een formaat staan dat eenvoudig te indexeren en op te vragen is.
LangChain biedt verschillende documentloaders voor uiteenlopende databronnen, zoals tekstbestanden, pdf’s of webpagina’s. Je kunt deze loaders gebruiken om je documenten in het systeem te brengen.
Ik heb een fascinatie voor ijsberen, dus ik heb besloten het volgende tekstbestand (my_document.txt) te uploaden met deze informatie:“IJsberen: de Arctische giganten
IJsberen (Ursus maritimus) zijn de grootste landroofdieren op aarde en ze zijn perfect aangepast aan het leven in de extreme kou van het Noordpoolgebied. Bekend om hun dikke witte vacht, die hen helpt op te gaan in het besneeuwde landschap, zijn ijsberen krachtige jagers die afhankelijk zijn van zee-ijs om zeehonden te vangen, hun voornaamste voedselbron.
Wat fascinerend is aan ijsberen, zijn hun ongelooflijke aanpassingen aan hun omgeving. Onder die dikke vacht zit een vetlaag die wel 11,5 cm dik kan zijn, die isolatie biedt en energiereserves tijdens de barre wintermaanden. Hun grote poten helpen hen zowel over ijs als open water te lopen, waardoor het sterke zwemmers zijn—in staat om grote afstanden af te leggen op zoek naar voedsel of nieuw territorium.
Helaas worden ijsberen ernstig bedreigd door klimaatverandering. Naarmate het Noordpoolgebied opwarmt, smelt het zee-ijs eerder in het jaar en vormt het later, waardoor de tijd die ijsberen hebben om zeehonden te jagen afneemt. Zonder voldoende voedsel hebben veel beren moeite om te overleven en hun populaties nemen in sommige gebieden af.
IJsberen spelen een cruciale rol in het behoud van de gezondheid van het Arctische ecosysteem en hun benarde situatie is een krachtige herinnering aan de bredere impact van klimaatverandering op ’s werelds wilde dieren. Er zijn inspanningen gaande om hun habitat te beschermen en ervoor te zorgen dat deze majestueuze dieren in het wild kunnen blijven floreren.”
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()Hier is een eenvoudig tekstbestand dat in het systeem is geladen, puur als didactisch voorbeeld, maar je kunt elk type document toevoegen dat je wilt! Je kunt bijvoorbeeld interne documentatie van je organisatie toevoegen. De variabele documents bevat nu de inhoud van het bestand, klaar voor verwerking.
Grote documenten worden vaak opgesplitst in kleinere chunks om ze makkelijker te indexeren en op te vragen. Dit proces is superbelangrijk omdat kleinere chunks beter hanteerbaar zijn voor het taalmodel en preciezere retrieval mogelijk maken. Je kunt meer leren in onze gids over chunking-strategieën voor AI en RAG.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)Hier wordt de tekst opgesplitst in chunks van 500 tekens met een overlap van 50 tekens tussen chunks. Die overlap helpt de context te behouden tijdens retrieval.
Zodra de data is voorbereid, is de volgende stap indexeren voor efficiënte retrieval. Indexeren houdt in dat de tekstchunks worden omgezet in vector-embeddings en opgeslagen in een vectorstore.
LangChain ondersteunt het maken van vector-embeddings met verschillende modellen, zoals OpenAI of HuggingFace-modellen. Deze embeddings representeren de semantische betekenis van de tekstchunks, waardoor ze geschikt zijn voor gelijkeniszoektochten.
Simpel gezegd: embeddings zijn een manier om tekst, bijvoorbeeld een alinea uit een document, om te zetten in getallen die een AI-model kan begrijpen. Deze getallen, of vectors, representeren de betekenis van de tekst op een manier die het voor AI-systemen makkelijker maakt om te verwerken.
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()We gebruiken OpenAI’s embeddings om die transformatie te doen. Eerst halen we de embeddingtool van OpenAI binnen en vervolgens initialiseren we die zodat hij klaar is voor gebruik.
Na het genereren van de embeddings is de volgende stap ze opslaan in een vectorstore zoals PGVector, FAISS of een andere die door LangChain wordt ondersteund. Dit maakt snelle en accurate retrieval van relevante documenten mogelijk wanneer een query wordt gedaan.
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)In dit geval gebruiken we FAISS, een geweldige tool die is ontworpen om door grote sets vectors te zoeken. FAISS helpt ons supersnel de meest vergelijkbare vectors te vinden.
Wat gebeurt hier: we halen FAISS binnen uit LangChain en gebruiken het om een zogeheten vectorstore te maken. Dat is een speciale database die is gebouwd om vectors efficiënt op te slaan en door te zoeken.
Het mooie van deze setup is dat FAISS later, wanneer we gaan zoeken, al die vectors kan doorlopen, de meest vergelijkbare bij een query kan vinden en de corresponderende documentchunks kan teruggeven.
Met de data geïndexeerd kun je nu de retrievalcomponent implementeren, die verantwoordelijk is voor het ophalen van relevante informatie op basis van gebruikersvragen.
Nu stellen we een retriever in. Dat is de component die door de geïndexeerde documenten gaat en de meest relevante vindt voor de vraag van een gebruiker.
Het toffe is dat je niet zomaar willekeurig zoekt — je zoekt slim met de kracht van embeddings, zodat de resultaten semantisch lijken op wat de gebruiker vraagt. Laten we de coderegel bekijken:
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)Eerst zetten we de vectorstore om in een retriever. Je hebt die FAISS-vectorstore al vol met documentembeddings, toch? Nu zeggen we: "Hé, gebruik dat om dingen te zoeken wanneer een gebruiker een vraag stelt."
search_type is waar de magie gebeurt. De retriever kan op verschillende manieren zoeken en je hebt hier een paar opties. Similarity search is de standaard werkwijze. Die checkt welke documenten qua betekenis het dichtst bij de query liggen.
Dus als je zegt "search_type='similarity'", vertel je de retriever: "Vind documenten die het meest lijken op de query op basis van de gegenereerde embeddings."
Met search_kwargs={"k": 5} verfijn je de boel. De k-waarde vertelt de retriever hoeveel documenten uit de vectorstore moeten worden opgehaald. In dit geval betekent k=5: “Geef me de top 5 meest relevante documenten.”
Dit is superkrachtig omdat het ruis vermindert. In plaats van een berg misschien-wel-relevante resultaten, pak je alleen de belangrijkste stukken informatie.
In dit deel van de code zetten we de kernmotor van je RAG-systeem op met LangChain. Je hebt je retriever al, die relevante documenten kan ophalen op basis van een query.
Nu voegen we de LLM toe en gebruiken we die om daadwerkelijk het antwoord te genereren op basis van de opgehaalde documenten.
from langchain_openai import OpenAI # Updated import
from langchain.chains import RetrievalQAHier importeren we twee kernelementen:
llm = OpenAI(openai_api_key=openai_api_key)Deze regel initialiseert de LLM met je OpenAI API-sleutel. Zie het als het laden van het brein van je systeem — het is het model dat tekst inneemt, begrijpt en antwoorden genereert.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)Hier begint het echt leuk te worden. We zetten de QA Chain op, die alles aan elkaar knoopt. De methode RetrievalQA.from_chain_type() maakt een vraag-en-antwoord-keten aan, oftewel: “Combineer de retriever en de LLM om vragen te beantwoorden op basis van de opgehaalde documenten.”
Daarna vertellen we de chain om de OpenAI-LLM te gebruiken die we net initialiseerden om antwoorden te genereren. Vervolgens koppelen we de retriever die je eerder bouwde. De retriever is verantwoordelijk voor het vinden van de relevante documenten op basis van de vraag van de gebruiker.
Dan stellen we chain_type="stuff" in: wat is "stuff"? Dat is een type chain in LangChain. "Stuff" betekent dat we alle relevante opgehaalde documenten in de LLM laden en die een antwoord laten genereren op basis van alles.
Het is alsof je een stapel notities op het bureau van de LLM gooit en zegt: "Hier, gebruik al deze info om de vraag te beantwoorden."
Er zijn ook andere chaintypes (zoals "map_reduce" of "refine"), maar "stuff" is de eenvoudigste en meest directe.
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})Hier stellen we het systeem daadwerkelijk een vraag en krijgen we een antwoord terug. De methode invoke() triggert de hele pijplijn.
Die neemt je query, stuurt die naar de retriever om relevante documenten op te halen en geeft die documenten door aan de LLM, die het uiteindelijke antwoord genereert.
print(response)Deze laatste regel print het antwoord dat door de LLM is gegenereerd. Op basis van de opgehaalde documenten genereert het systeem een compleet, goed onderbouwd antwoord op de query, dat wordt geprint.
Het uiteindelijke script ziet er zo uit:
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# FAISS expects document objects and the embedding model
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Use the vector store's retriever
retriever = vector_store.as_retriever()
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Set up the retrieval-based QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# Example query
query = "Are polar bears in danger?"
response = qa_chain.invoke({"query": query})
# Print the response
print(response)Nu is het tijd om een API te bouwen om met je RAG-systeem te communiceren. Maar waarom is deze stap nodig bij de uitrol?
Stel je voor dat je deze tutorial hebt gevolgd en je een geweldig RAG-systeem hebt opgezet, afgestemd op jouw documenten en behoeften — het haalt relevante info op, verwerkt queries en genereert slimme antwoorden. Maar hoe laat je gebruikers of andere systemen er daadwerkelijk mee interageren?
FastAPI is je tussenpersoon. Het creëert een eenvoudige, gestructureerde manier voor gebruikers of apps om je RAG-systeem vragen te stellen en antwoorden terug te krijgen.
FastAPI is asynchroon en high-performance. Dat betekent dat het veel requests tegelijk kan afhandelen zonder te vertragen, wat superbelangrijk is bij AI-systemen die grote hoeveelheden data moeten ophalen of complexe queries uitvoeren.
In deze sectie passen we het vorige script aan en maken we extra scripts zodat je RAG-systeem toegankelijk, schaalbaar en klaar is voor echt verkeer.Laten we beginnen met het maken van de routes die inkomende requests naar het RAG-systeem afhandelen.
Maak in je werkdirectory een main.py-bestand. Dit is je entrypoint voor de FastAPI-app. Dit wordt het brein van je FastAPI — dit bestand trekt alle API-routes, dependencies en het RAG-systeem bij elkaar.
from fastapi import FastAPI
from endpoints import router
app = FastAPI()
app.include_router(router)Dit is een vrij simpele setup, maar wel strak. We maken hier een FastAPI-instance en halen vervolgens alle routes (of API-paden) op uit een ander bestand, dat we hierna maken.
Hier komt alles samen. We gaan een functie schrijven die je RAG-systeem daadwerkelijk uitvoert wanneer een gebruiker een query indient.
async def get_rag_response(query: str):Deze functie is gemarkeerd als async, wat betekent dat die asynchroon is. Dit houdt in dat hij andere dingen kan afhandelen terwijl hij op een reactie wacht.
Zo’n eigenschap is vooral handig bij retrieval-gebaseerde systemen waar het ophalen van documenten of het bevragen van een LLM even kan duren. Zo kan FastAPI andere requests verwerken terwijl deze op de achtergrond draait.
retriever = setup_rag_system()Hier roepen we de functie setup_rag_system() aan, die — zoals eerder besproken — de hele retrieverpijplijn initialiseert. Dat betekent:
Deze retriever haalt de relevante tekstbrokken op op basis van de vraag van de gebruiker.
Wanneer een gebruiker een vraag stelt, gaat de retriever door alle documenten in de vectorstore en haalt de meest relevante op, op basis van de query.
retrieved_docs = retriever.get_relevant_documents(query)Deze methode invoke(query) haalt die relevante documenten op. Achter de schermen matcht hij de query met de embeddingvectors en pikt de beste overeenkomsten eruit op basis van gelijkenis.
Nu we de relevante documenten hebben, moeten we ze formatteren voor de LLM.
context = "\n".join([doc.page_content for doc in retrieved_docs])Hier voegen we alle opgehaalde documenten samen tot één string. Dit is belangrijk omdat de LLM een nette lap tekst verwacht om mee te werken, niet een hoop losse stukjes.
We gebruiken de Python-functie join() om deze documentchunks samen te voegen tot één samenhangend informatieblok. De inhoud van elk document staat in het veld doc.page_content, en we voegen ze samen met nieuwe regels (\n).
Nu maken we de prompt voor de LLM.
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]De prompt is zo opgezet dat hij de LLM vertelt de opgehaalde informatie te gebruiken om de vraag van de gebruiker te beantwoorden.
Nu is het tijd om een antwoord te genereren.
generated_response = llm.generate(prompt) # Pass as a list of stringsHier krijgt het OpenAI-model de taak om de prompt te nemen en een contextbewust antwoord te genereren op basis van zowel de vraag als de relevante documenten.
Tot slot geven we het gegenereerde antwoord terug aan degene die de functie aanriep (of dat nu een gebruiker, een frontend-app of een ander systeem is).
return generated_responseDit antwoord is volledig gevormd, contextueel en klaar voor gebruik in praktische toepassingen.
Kort samengevat voert deze functie de volledige retrieval-en-generatie-loop uit. Een snelle recap van de flow:
1. Hij zet de retriever op om relevante documenten te vinden.
2. Die documenten worden op basis van de query opgehaald.
3. De context uit die documenten wordt voorbereid voor de LLM.
4. De LLM genereert een eindantwoord met die context.
5. Het antwoord wordt aan de gebruiker teruggegeven.
from dotenv import load_dotenv
import os
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
# Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
# Initialize the LLM (using OpenAI)
llm = OpenAI(openai_api_key=openai_api_key)
# Function to set up the RAG system
def setup_rag_system():
# Load the document
loader = TextLoader('data/my_document.txt')
documents = loader.load()
# Split the document into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
# Initialize embeddings with OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Create FAISS vector store from document chunks and embeddings
vector_store = FAISS.from_documents(document_chunks, embeddings)
# Return the retriever for document retrieval with specified search_type
retriever = vector_store.as_retriever(
search_type="similarity", # or "mmr" or "similarity_score_threshold"
search_kwargs={"k": 5} # Adjust the number of results if needed
)
return retriever
# Function to get the response from the RAG system
async def get_rag_response(query: str):
retriever = setup_rag_system()
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs = retriever.get_relevant_documents(query)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context = "\n".join([doc.page_content for doc in retrieved_docs])
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt = [f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"]
# Generate the final response using the language model (LLM)
generated_response = llm.generate(prompt)
return generated_responseendpoints.pyLaten we vervolgens het bestand endpoints.py maken. Hier definiëren we de daadwerkelijke paden die gebruikers aanroepen om met je RAG-systeem te interageren.
from fastapi import APIRouter, HTTPException
from rag import get_rag_response
router = APIRouter()
@router.get("/query/")
async def query_rag_system(query: str):
try:
# Pass the query string to your RAG system and return the response
response = await get_rag_response(query)
return {"query": query, "response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))We maken een APIRouter om onze API-routes te beheren. De endpoint /query/ is gedefinieerd om een GET-request met een querystring te accepteren. Hij roept de functie get_rag_response aan uit je rag.py-bestand, die de volledige RAG-pijplijn afhandelt (documentopvraging + taalgeneratie). Gaat er iets mis, dan geven we een HTTP 500-fout met een gedetailleerde melding.
Met alles ingesteld kun je je FastAPI-app nu draaien met Uvicorn. Dit is de webserver die gebruikers toegang geeft tot je API.
Ga naar de terminal en voer uit:
uvicorn app.main:app --reloadapp.main:app vertelt Uvicorn dat hij de app-instance moet zoeken in het bestand main.py en --reload schakelt automatisch herladen in als je je code wijzigt.
Zodra de server draait, open je je browser en ga je naar http://127.0.0.1:8000/docs. FastAPI genereert automatisch Swagger UI-documentatie voor je API, zodat je die rechtstreeks in je browser kunt testen!
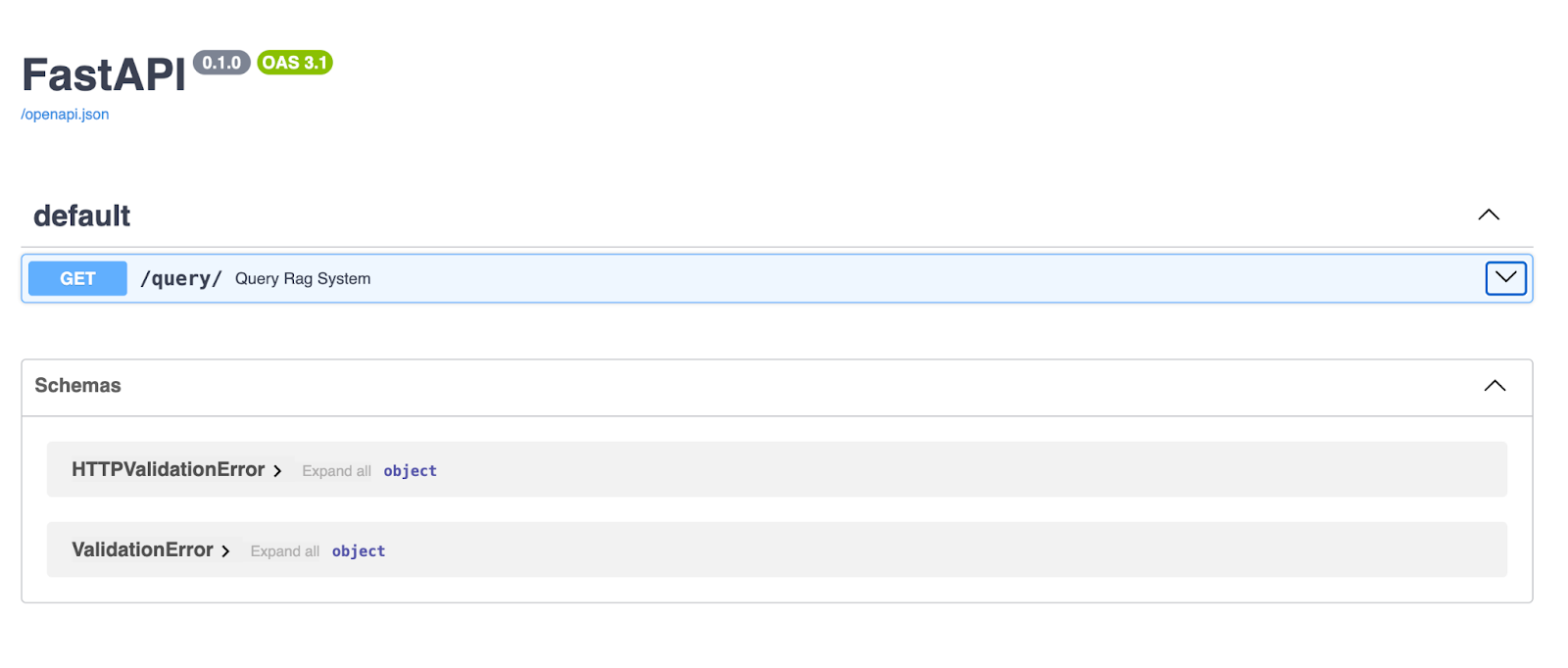
De FastAPI Swagger UI biedt een overzichtelijke, interactieve interface om je API-endpoints te verkennen en te testen. Hier laat de /query/-endpoint gebruikers een querystring invoeren en een antwoord ontvangen dat is gegenereerd door de RAG-pijplijn.
Met je FastAPI-server draaiende, ga je naar je browser of gebruik je Postman of Curl om een GET-request te doen naar je /query/-endpoint.
In je browser, via Swagger:
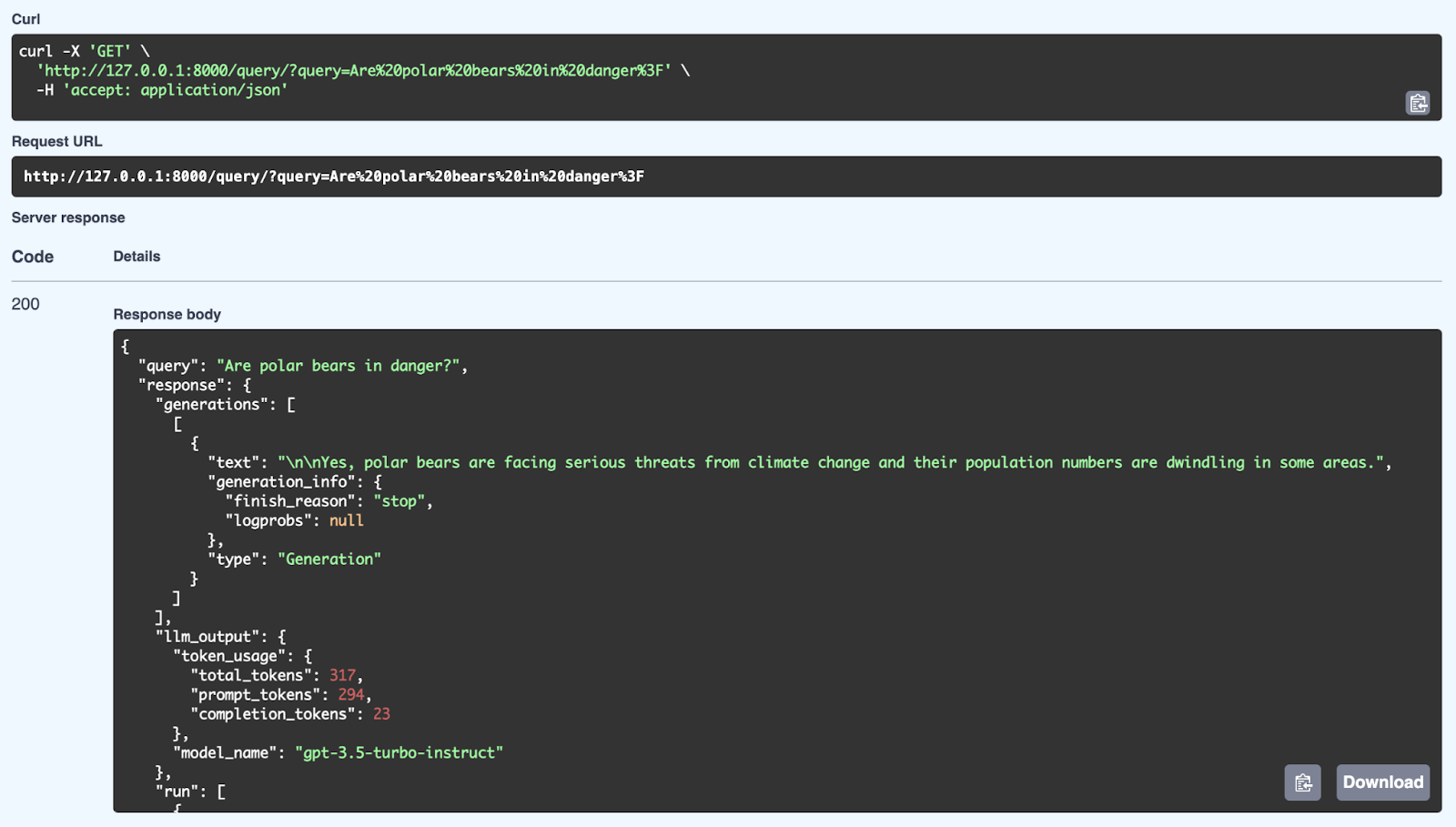
Hier zien we een succesvolle reactie van het RAG-systeem op de query: "Are polar bears in danger?". Het systeem haalt relevante informatie op uit zijn kennisbank en genereert een coherent antwoord met het model GPT-3.5 Turbo-Instruct. De gedetailleerde reactie bevat niet alleen het antwoord (Ja, ijsberen worden ernstig bedreigd door klimaatverandering en hun populaties nemen af), maar ook metadata zoals tokengebruik (aantal verwerkte tokens) en het gebruikte model. De API kan goed gestructureerde, contextbewuste antwoorden geven door zowel retrieval als generatie te gebruiken via FastAPI.
Laten we het nu hebben over de voordelen van asynchrone verwerking in FastAPI en waarom dat zo’n groot verschil maakt bij het afhandelen van echte API-requests.
Je RAG-systeem draait. De API neemt vragen aan, haalt relevante info op uit de kennisbank en genereert vervolgens antwoorden met een taalmodel.
Als dat hele proces synchroon zou zijn, zou het systeem blijven wachten tot elke taak is afgerond voordat de volgende begint. Bijvoorbeeld: terwijl documenten worden opgehaald, zou het geen nieuwe requests kunnen verwerken.
|
Non-blocking I/O |
Verbeterde performance |
Betere gebruikerservaring |
|
Async-functies laten de server meerdere requests tegelijk afhandelen, in plaats van te wachten tot er één klaar is voordat de volgende start. |
Voor taken als documenten ophalen uit een vectorstore of tekst genereren zorgt async-verwerking ervoor dat de API hoge loads efficiënt kan managen. |
Clients krijgen snellere antwoorden en je API blijft responsief, zelfs bij zware belasting. |
Laten we het hebben over deploymentstrategieën — een heel belangrijke stap om je RAG-systeem van prototype naar een volledig operationeel product te brengen. Het doel is om te zorgen dat je systeem verpakt, uitgerold en klaar is om op te schalen, zodat het echte gebruikers aankan.
Eerst: Docker. Docker is als een magische doos die alles wat je RAG-systeem nodig heeft — code, dependencies, configuraties — inpakt in een nette container.
Dit zorgt ervoor dat je app waar je hem ook uitrolt, zich precies hetzelfde gedraagt. Je kunt je app in verschillende omgevingen draaien, maar omdat hij in een container zit, hoef je je niet druk te maken over het “maar op mijn machine werkt het wel”.

Je maakt een Dockerfile, een set instructies die Docker vertelt hoe het de omgeving van je app moet opzetten, de nodige packages moet installeren en hem moet starten. Zodra dat klaar is, kun je er een Dockerimage van bouwen en je applicatie in een container draaien. Efficiënt, reproduceerbaar en super draagbaar.
Zodra je systeem is ingepakt en klaar voor gebruik, wil je het waarschijnlijk in de cloud uitrollen. Dat is interessant, want je RAG-systeem in de cloud uitrollen betekent dat het overal ter wereld toegankelijk is. Bovendien krijg je schaalbaarheid, betrouwbaarheid en toegang tot andere clouddiensten die je systeem kunnen versterken.
Laten we een paar populaire cloudplatforms bekijken, waaronder Azure en Google Cloud:
AWS biedt tools zoals Elastic Beanstalk, waarmee uitrol heel eenvoudig wordt. Je levert in feite je Dockercontainer aan en AWS regelt schalen, load balancing en monitoring. Wil je meer controle, dan kun je Amazon ECS gebruiken, waarmee je je Dockercontainers op een cluster servers kunt draaien en op- of afschalen naar behoefte.
Heroku is een andere optie die uitrol vereenvoudigt. Je pusht je code en Heroku beheert de infrastructuur voor je. Het is een goede keuze als je niet te diep wilt duiken in de finesses van cloudresources beheren.
Azure biedt Azure App Service, waarmee je je RAG-systeem eenvoudig kunt uitrollen en beheren, met ingebouwde ondersteuning voor autoschalen, load balancing en continuous deployment.
Voor meer flexibiliteit kun je Azure Kubernetes Service (AKS) gebruiken om je Dockercontainers op schaal te beheren, zodat je systeem hoge traffic aankan met de mogelijkheid om resources dynamisch aan te passen.
GCP heeft Google Cloud Run, een volledig beheerd platform waarmee je je containers kunt uitrollen en automatisch kunt schalen op basis van verkeer.
Wil je meer controle over je infrastructuur, kies dan voor Google Kubernetes Engine (GKE), waarmee je je Dockercontainers over meerdere nodes kunt beheren en schalen, met als extra voordeel een diepe integratie met Google’s clouddiensten zoals AI- en machinelearning-API’s.
Elk platform heeft zijn sterke punten, of je nu eenvoud en automatisering wilt of juist meer fijnmazige controle over je uitrol.
We hebben in dit artikel veel behandeld en het proces doorlopen van het bouwen van een RAG-systeem met LangChain en FastAPI. RAG-systemen zijn een grote stap vooruit in natural language processing omdat ze externe informatie binnenhalen, waardoor AI accuratere, relevantere en contextbewustere antwoorden kan genereren.
Met LangChain hebben we een solide framework dat alles afhandelt: van documenten laden, tekst splitsen en embeddings maken tot het ophalen van informatie op basis van gebruikersqueries.
Vervolgens biedt FastAPI ons een snel, async-ready webframework waarmee we het RAG-systeem als schaalbare API kunnen uitrollen.
Samen maken deze tools het eenvoudiger om AI-toepassingen te bouwen die complexe vragen aankunnen, precieze antwoorden leveren en uiteindelijk een betere gebruikerservaring bieden.
Nu is het aan jou om wat je hebt geleerd toe te passen op je eigen projecten.
Denk aan de mogelijkheden: je eigen interne kennisbank bevragen, documentreviewprocessen automatiseren of slimme chatbots maken voor klantondersteuning.
Vergeet niet — er zijn zoveel manieren om deze setup uit te breiden! Je kunt experimenteren met POST-requests om complexere datastructuren te versturen, of zelfs WebSocket-verbindingen verkennen voor realtime-interacties.
Ik moedig je aan om dieper te duiken, te experimenteren en te ontdekken waar dit je kan brengen. Dit is pas het begin van wat je kunt bereiken met LangChain, FastAPI en moderne AI-tools! Hier zijn een paar bronnen die ik aanbeveel:
Topcursussen op DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
