Kursus
Bekerja dengan Data Geospasial di Python
4 Hr
17.8K
Pada bagian ini, kita akan mempelajari teknik data augmentation untuk audio, teks, gambar, dan teknik lanjutan.
Pelajari lebih lanjut tentang transformasi dan manipulasi gambar dengan latihan langsung di skill track Image Processing with Python kami.
Data augmentation dapat diterapkan pada semua aplikasi machine learning di mana perolehan data berkualitas merupakan tantangan. Selain itu, teknik ini dapat membantu meningkatkan ketangguhan dan kinerja model di semua bidang kajian.
Mengumpulkan dan memberi label dataset citra medis memakan waktu dan mahal. Anda juga memerlukan pakar materi untuk memvalidasi dataset sebelum melakukan analisis data. Menggunakan transformasi geometris dan transformasi lainnya dapat membantu Anda melatih model machine learning yang tangguh dan akurat.
Misalnya, pada kasus Klasifikasi Pneumonia, Anda dapat menggunakan cropping acak, zoom, stretching, dan transformasi ruang warna untuk meningkatkan performa model. Namun, Anda perlu berhati-hati terhadap augmentasi tertentu karena dapat memberikan hasil sebaliknya. Sebagai contoh, rotasi acak dan refleksi sepanjang sumbu x tidak direkomendasikan untuk dataset citra X-ray.
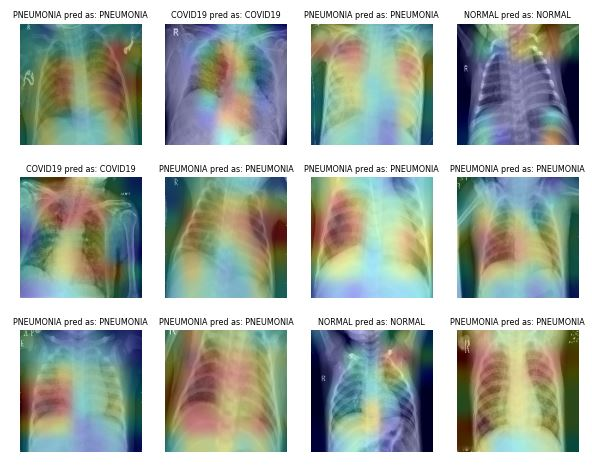
Gambar dari ibrahimsobh.github.io | kaggle-COVID19-Classification
Data untuk mobil otonom terbatas, dan perusahaan menggunakan lingkungan simulasi untuk menghasilkan data sintetis menggunakan reinforcement learning. Ini dapat membantu Anda melatih dan menguji aplikasi machine learning ketika keamanan data menjadi isu.

Gambar oleh David Silver | Autonomous Visualization System from Uber ATG
Kemungkinan penggunaan data augmented sebagai simulasi tidak terbatas, karena dapat digunakan untuk menghasilkan skenario dunia nyata.
Augmentasi data teks umumnya digunakan saat data berkualitas terbatas, dan peningkatan metrik kinerja menjadi prioritas. Anda dapat menerapkan augmentasi sinonim, word embedding, penukaran karakter, serta penyisipan dan penghapusan acak. Teknik-teknik ini juga bermanfaat untuk bahasa dengan sumber daya rendah.
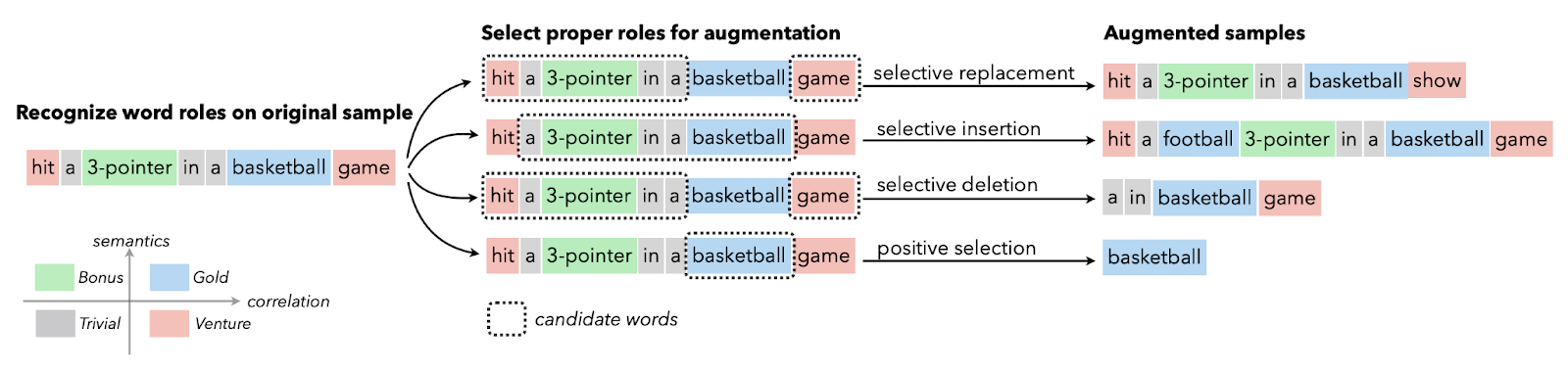
Gambar dari Papers With Code | Selective Text Augmentation with Word Roles for Low-Resource Text Classification.
Peneliti menggunakan augmentasi teks untuk model bahasa pada skenario pengenalan dengan tingkat kesalahan tinggi, pembuatan data sequence-to-sequence, dan klasifikasi teks.
Pada klasifikasi suara dan pengenalan ucapan, data augmentation sangat efektif. Teknik ini meningkatkan performa model bahkan pada bahasa dengan sumber daya rendah.
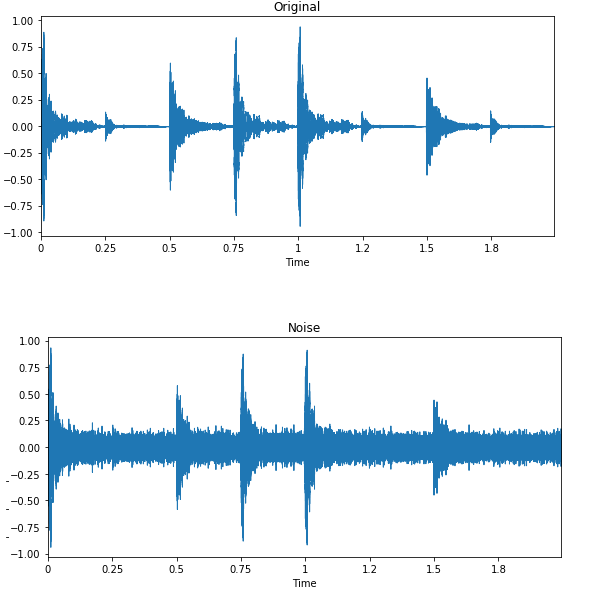
Gambar oleh Edward Ma | Noise Injection
Penyuntikan noise acak, pergeseran, dan perubahan pitch dapat membantu Anda menghasilkan model speech-to-text mutakhir. Anda juga dapat menggunakan GAN untuk menghasilkan suara realistis untuk aplikasi tertentu.
Meskipun data augmentation adalah alat yang kuat untuk meningkatkan model machine learning, teknik ini menimbulkan beberapa kekhawatiran etis yang perlu dipertimbangkan secara cermat:
Untuk memanfaatkan data augmentation secara bertanggung jawab, praktisi harus memvalidasi data yang di-augment, mengatasi bias, dan memastikan kepatuhan terhadap standar etika dan hukum yang relevan.
Dalam tutorial ini, kita akan mempelajari cara meng-augmentasi data gambar menggunakan Keras dan TensorFlow. Selain itu, Anda akan mempelajari cara menggunakan data augmented untuk melatih pengklasifikasi biner sederhana. Kode di bawah ini adalah versi modifikasi dari contoh resmi TensorFlow.
Kami menyarankan Anda mengikuti tutorial pengkodean dengan berlatih sendiri. Sumber kode beserta keluarannya tersedia di DataLab workbook ini.
Kita akan menggunakan TensorFlow dan Keras untuk data augmentation serta matplotlib untuk menampilkan gambar.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Koleksi TensorFlow Dataset sangat besar. Anda dapat menemukan dataset teks, audio, video, graf, deret waktu, dan gambar. Dalam tutorial ini, kita akan menggunakan dataset cats_vs_dogs. Ukuran dataset adalah 786,68 MiB, dan kita akan menerapkan berbagai augmentasi gambar serta melatih pengklasifikasi biner.
Pada kode di bawah, kita memuat 80% pelatihan, 10% validasi, dan 10% set uji dengan label dan metadata.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Terdapat dua kelas dalam dataset, yaitu ‘cat’ dan ‘dog’.
num_classes = metadata.features['label'].num_classes
print(num_classes)2Kita akan menggunakan iterator untuk mengekstrak empat gambar acak dengan label dari set pelatihan dan menampilkannya menggunakan fungsi matplotlib `.imshow()`.
try:
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x + 1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label))
except StopIteration:
print("Dataset iterator is empty!")
Seperti terlihat, kita mendapatkan berbagai gambar anjing dan satu gambar kucing.

Kita biasanya menggunakan keras.Sequential() untuk membangun model, tetapi kita juga dapat menggunakannya untuk menambahkan lapisan augmentasi.
Pada contoh ini, kita mengubah ukuran dan menskalakan ulang gambar menggunakan Keras Sequential dan lapisan augmentasi gambar. Pertama, kita akan mengubah ukuran gambar menjadi 180x180 lalu menskalakannya ulang dengan 1/255. Ukuran gambar yang kecil akan membantu menghemat waktu, memori, dan komputasi.
Seperti terlihat, kita berhasil meneruskan gambar melalui lapisan augmentasi, dan keluaran akhirnya telah diubah ukuran dan diskalakan ulang.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Mari terapkan flip dan rotasi acak pada gambar yang sama. Kita akan menggunakan loop, subplot, dan imshow untuk menampilkan enam gambar dengan augmentasi geometris acak.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Catatan: jika Anda mengalami “WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).”, coba konversi gambar Anda ke numpy dan bagi dengan 255. Ini akan menampilkan keluaran yang jelas alih-alih gambar yang pudar.

Selain augmentasi sederhana, Anda juga dapat menerapkan RandomContrast, RandomCrop, CenterCrop, dan RandomZoom pada gambar.
Ada dua cara untuk menerapkan augmentasi pada gambar. Metode pertama adalah dengan langsung menambahkan lapisan augmentasi ke model.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Catatan: data augmentation tidak aktif selama fase pengujian. Ini hanya akan bekerja untuk Model.fit, bukan untuk Model.evaluate atau Model.predict.
Metode kedua adalah menerapkan data augmentation ke seluruh set pelatihan menggunakan Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Kita akan membuat fungsi prapemrosesan data untuk memproses set train, valid, dan test.
Fungsi ini akan:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Kita akan membuat model sederhana dengan lapisan konvolusi dan dense. Pastikan bentuk masukan serupa dengan bentuk gambar.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Sekarang kita akan melakukan kompilasi model dan melatihnya selama satu epoch. Optimizer yang digunakan adalah Adam, fungsi loss adalah Binary Cross Entropy, dan metriknya adalah akurasi.
Seperti terlihat, kita memperoleh akurasi validasi 51% pada satu kali jalan. Anda dapat melatihnya untuk beberapa epoch dan mengoptimalkan hiperparameter untuk mendapatkan hasil yang lebih baik.
Bagian pembuatan dan pelatihan model ini hanya untuk memberi gambaran bagaimana Anda dapat meng-augmentasi gambar dan melatih model.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Pelajari cara melakukan analisis gambar, serta membangun, melatih, dan mengevaluasi jaringan konvolusional dengan mengikuti kursus Image Processing with Keras.
Pada bagian ini, kita akan mempelajari cara meng-augmentasi gambar menggunakan TensorFlow untuk mendapatkan kontrol yang lebih halus atas data augmentation.
Kita akan memuat kembali dataset cats_vs_dogs beserta label dan metadata.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Alih-alih gambar kucing, kita akan menggunakan gambar anjing dan menerapkan berbagai teknik augmentasi.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Kita akan membuat fungsi visualize() untuk menampilkan perbedaan antara gambar asli dan gambar yang di-augment.
Fungsinya cukup langsung. Fungsi ini menerima gambar asli dan fungsi augmentasi sebagai masukan, lalu menampilkan perbedaannya menggunakan matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Seperti terlihat, kita telah membalik gambar dari kiri ke kanan menggunakan fungsi tf.image. Ini lebih sederhana dibandingkan keras.Sequential().
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Mari ubah gambar menjadi skala keabuan menggunakan tf.image.rgb_to_grayscale().
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Anda juga dapat menyesuaikan saturasi dengan faktor 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Sesuaikan kecerahan dengan memberikan faktor kecerahan.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Crop gambar dari tengah menggunakan fraksi pusat 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Putar gambar sebesar 90 derajat menggunakan fungsi tf.image.rot90().
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Sama seperti lapisan Keras, tf.image() juga memiliki fungsi augmentasi acak. Pada contoh di bawah, kita akan menerapkan kecerahan acak pada gambar dan menampilkan beberapa hasil.
Seperti terlihat, gambar pertama sedikit lebih gelap, dan dua gambar berikutnya lebih terang.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Sama seperti Keras, kita dapat menerapkan fungsi data augmentation ke seluruh dataset menggunakan Dataset.map().
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)ImageDataGenerator() Keras bahkan lebih sederhana. Ini bekerja paling baik ketika Anda memuat data dari direktori lokal atau CSV.
Pada contoh ini, kita akan mengunduh dan memuat dataset CIFAR10 kecil dari pustaka dataset bawaan Keras.
Setelah itu, kita akan menerapkan augmentasi menggunakan keras.preprocessing.image.ImageDataGenerator(). Fungsi ini akan secara acak melakukan rotasi, mengubah tinggi dan lebar, serta membalik gambar secara horizontal.
Terakhir, kita akan melakukan fit ImageDataGenerator() pada dataset pelatihan dan menampilkan enam gambar dengan augmentasi acak.
Catatan: ukuran gambar adalah 32x32, sehingga tampilannya beresolusi rendah.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
Pada bagian ini, kita akan mempelajari alat open-source lain yang dapat Anda gunakan untuk melakukan berbagai teknik data augmentation dan meningkatkan performa model.
Transformasi gambar tersedia di modul torchvision.transforms. Mirip dengan Keras, Anda dapat menambahkan lapisan transform dalam torch.nn.Sequential atau menerapkan fungsi augmentasi secara terpisah pada dataset.
Augmentor adalah paket Python untuk augmentasi gambar dan pembuatan gambar artifisial. Anda dapat melakukan Perspective Skewing, Elastic Distortions, Rotating, Shearing, Cropping, dan Mirroring. Augmentor juga dilengkapi fungsionalitas prapemrosesan gambar dasar.
Albumentations adalah alat Python untuk augmentasi gambar yang cepat dan fleksibel. Alat ini banyak digunakan dalam kompetisi machine learning, industri, dan penelitian untuk meningkatkan performa deep convolutional neural networks.
Imgaug adalah alat open-source untuk augmentasi gambar. Alat ini mendukung beragam teknik augmentasi, seperti noise Gaussian, kontras, ketajaman, crop, affine, dan flip. Imgaug memiliki antarmuka stokastik yang sederhana namun kuat, serta dilengkapi dengan keypoints, bounding boxes, heatmaps, dan segmentation maps.
OpenCV adalah pustaka open-source besar untuk visi komputer, machine learning, dan pemrosesan gambar. Umumnya digunakan untuk membangun aplikasi waktu nyata. Anda dapat menggunakan OpenCV untuk meng-augmentasi gambar dan video dengan mudah.
Fungsi augmentasi gambar yang disediakan oleh TensorFlow dan Keras sangat praktis. Anda hanya perlu menambahkan lapisan augmentasi, tf.image(), atau ImageDataGenerator() untuk melakukan augmentasi. Selain kerangka kerja deep learning, Anda dapat menggunakan alat mandiri seperti Augmentor, Albumentations, OpenCV, dan Imgaug untuk melakukan data augmentation.
Dalam tutorial ini, kita telah mempelajari kelebihan, keterbatasan, aplikasi, dan teknik data augmentation. Selain itu, kita telah mempelajari cara menerapkan augmentasi gambar pada dataset cats_vs_dogs menggunakan Keras dan TensorFlow. Jika Anda tertarik mempelajari lebih lanjut tentang pemrosesan gambar, lihat skill track Image Processing with Python kami. Anda akan mempelajari dasar-dasar transformasi dan manipulasi gambar, analisis citra medis, serta pemrosesan gambar lanjutan menggunakan Keras.
Kursus Teratas
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
