Curso
Trabalhando com Dados Geoespaciais em Python
4 h
17.7K
Nesta seção, aprenderemos sobre áudio, texto, imagem e técnicas avançadas de aumento de dados.
Saiba mais sobre transformação e manipulação de imagens com exercícios práticos em nosso curso de habilidades em Processamento de imagens com Python.
O aumento de dados pode ser aplicado a todos os aplicativos de aprendizado de máquina em que a aquisição de dados de qualidade é um desafio. Além disso, ele pode ajudar a melhorar a robustez e o desempenho do modelo em todos os campos de estudo.
A aquisição e a rotulagem de conjuntos de dados de imagens médicas são demoradas e caras. Você também precisa de um especialista no assunto para validar o conjunto de dados antes de realizar a análise de dados. O uso de transformações geométricas e outras transformações pode ajudar você a treinar modelos de aprendizado de máquina robustos e precisos.
Por exemplo, no caso da Classificação de Pneumonia, você pode usar o corte aleatório, o zoom, o alongamento e a transformação do espaço de cores para melhorar o desempenho do modelo. No entanto, você precisa ter cuidado com certos aumentos, pois eles podem resultar em resultados opostos. Por exemplo, a rotação aleatória e a reflexão ao longo do eixo x não são recomendadas para o conjunto de dados de imagens de raios X.
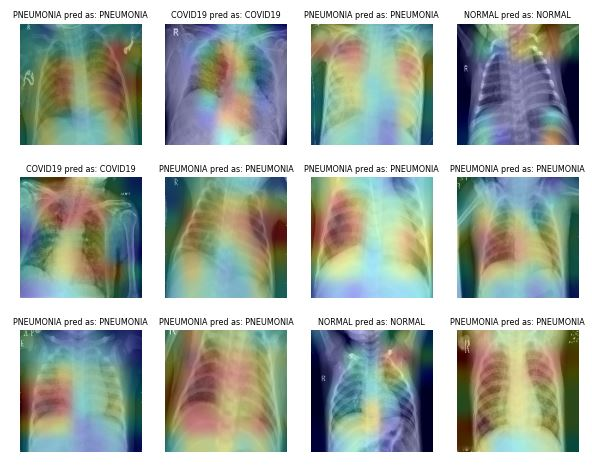
Imagem de ibrahimsobh.github.io | kaggle-COVID19-Classification
Há poucos dados disponíveis sobre carros autônomos, e as empresas estão usando ambientes simulados para gerar dados sintéticos usando o aprendizado por reforço. Ele pode ajudar você a treinar e testar aplicativos de aprendizado de máquina em que a segurança dos dados é um problema.

Imagem de David Silver | Sistema de visualização autônoma do Uber ATG
As possibilidades dos dados aumentados como uma simulação são infinitas, pois podem ser usados para gerar cenários do mundo real.
O aumento de dados de texto é geralmente usado em situações com dados de qualidade limitada, e o aprimoramento da métrica de desempenho tem prioridade. Você pode aplicar o aumento de sinônimos, a incorporação de palavras, a troca de caracteres e a inserção e exclusão aleatórias. Essas técnicas também são valiosas para idiomas com poucos recursos.
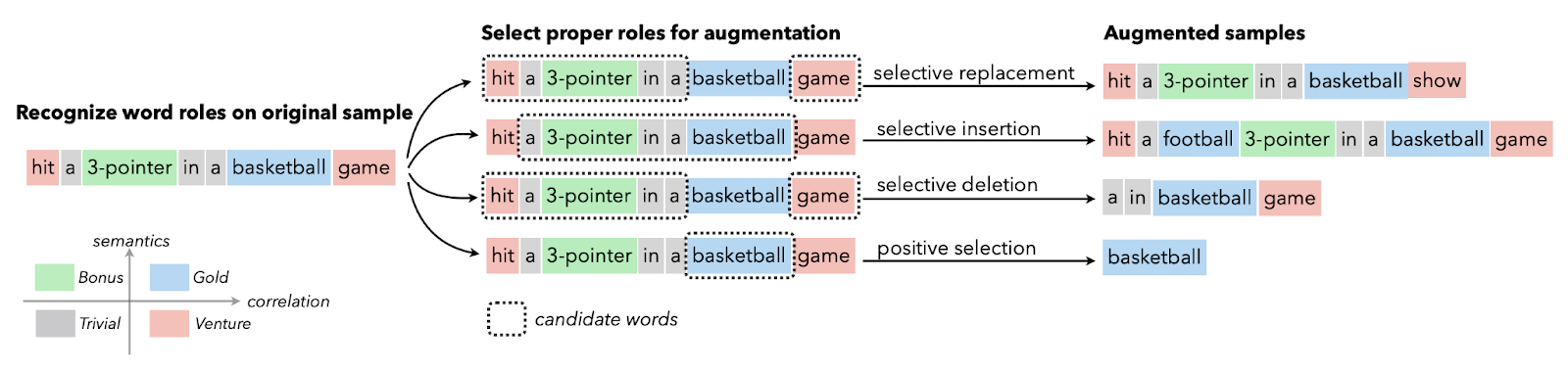
Imagem de Papers With Code | Aumento seletivo de texto com funções de palavras para classificação de textos com poucos recursos.
Os pesquisadores usam o aumento de texto para os modelos de linguagem em cenários de reconhecimento de alto erro, geração de dados de sequência para sequência e classificação de texto.
Na classificação de sons e no reconhecimento de fala, o aumento de dados faz maravilhas. Ele melhora o desempenho do modelo mesmo em idiomas com poucos recursos.
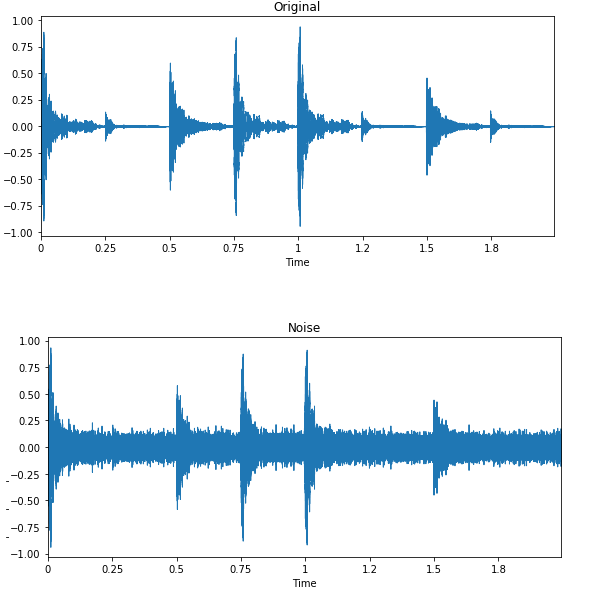
Imagem de Edward Ma | Noise Injection
A injeção de ruído aleatório, a mudança e a alteração do tom podem ajudar você a produzir modelos de fala para texto de última geração. Você também pode usar GANs para gerar sons realistas para um determinado aplicativo.
Embora o aumento de dados seja uma ferramenta poderosa para aprimorar os modelos de aprendizado de máquina, ele levanta várias questões éticas que exigem uma análise cuidadosa:
Para aproveitar o aumento de dados de forma responsável, os profissionais devem validar os dados aumentados, abordar os vieses e garantir a conformidade com os padrões éticos e legais relevantes.
Neste tutorial, aprenderemos como aumentar os dados de imagem usando o Keras e o Tensorflow. Além disso, você aprenderá a usar seus dados aumentados para treinar um classificador binário simples. O código mencionado abaixo é a versão modificada do exemplo oficial do TensorFlow.
Recomendamos que você siga o tutorial de codificação e pratique por conta própria. O código-fonte com os resultados está disponível nesta pasta de trabalho do DataLab.
Usaremos o TensorFlow e o Keras para aumentar os dados e o matplotlib para exibir as imagens.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
A coleção de conjuntos de dados do TensorFlow é enorme. Você pode encontrar conjuntos de dados de texto, áudio, vídeo, gráficos, séries temporais e imagens. Neste tutorial, usaremos o conjunto de dados "cats_vs_dogs". O tamanho do conjunto de dados é de 786,68 MiB, e aplicaremos vários aprimoramentos de imagem e treinaremos o classificador binário.
No código abaixo, carregamos 80% de treinamento, 10% de validação e 10% de um conjunto de teste com rótulos e metadados.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Há duas classes no conjunto de dados: "gato" e "cachorro".
num_classes = metadata.features['label'].num_classes
print(num_classes)2Usaremos iteradores para extrair apenas quatro imagens aleatórias com rótulos do conjunto de treinamento e exibi-las usando a função matplotlib `.imshow()`.
try:
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x + 1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label))
except StopIteration:
print("Dataset iterator is empty!")
Como você pode ver, obtivemos várias imagens de cães e uma imagem de gato.

Normalmente, usamos o keras.Sequential() para criar o modelo, mas também podemos usá-lo para adicionar camadas de aumento.
No exemplo, estamos redimensionando e redimensionando a imagem usando o Keras Sequential e as camadas de aumento de imagem. Primeiro, redimensionaremos a imagem para 180X180 e depois a redimensionaremos em 1/255. O tamanho reduzido da imagem nos ajudará a economizar tempo, memória e computação.
Como você pode ver, passamos a imagem com sucesso pela camada de aumento, e a saída final é redimensionada e redimensionada.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Vamos aplicar a inversão e a rotação aleatórias à mesma imagem. Usaremos loop, subplot e imshow para exibir seis imagens com aumento geométrico aleatório.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Observação: se você estiver vendo a mensagem "WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).", tente converter sua imagem para numpy e dividi-la por 255. Ele mostrará a você a saída clara em vez de uma imagem desbotada.

Além do aumento simples, você também pode aplicar RandomContrast, RandomCrop, HeightCrop, WidthCrop e RandomZoom às imagens.
Há duas maneiras de aplicar o aumento às imagens. O primeiro método consiste em adicionar diretamente as camadas de aumento ao modelo.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Observação: o aumento de dados fica inativo durante a fase de teste. Isso só funcionará para Model.fit, não para Model.evaluate ou Model.predict.
O segundo método é aplicar o aumento de dados a todo o conjunto de trens usando Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Criaremos uma função de pré-processamento de dados para processar conjuntos de treinamento, válidos e de teste.
A função irá:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Criaremos um modelo simples com convolução e camadas densas. Certifique-se de que a forma de entrada seja semelhante à forma da imagem.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Agora, vamos compilar o modelo e treiná-lo para uma época. O otimizador é o Adam, a função de perda é a Binary Cross Entropy e a métrica é a precisão.
Como podemos observar, obtivemos 51% de precisão de validação em uma única execução. Você pode treiná-lo para várias épocas e otimizar os hiperparâmetros para obter resultados ainda melhores.
A parte de construção e treinamento do modelo serve apenas para lhe dar uma ideia de como você pode aumentar as imagens e treinar o modelo.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Aprenda a realizar análises de imagens e a construir, treinar e avaliar redes de convolução fazendo o curso Processamento de imagens com Keras.
Nesta seção, aprenderemos a aumentar as imagens usando o TensorFlow para ter um controle mais preciso do aumento de dados.
Carregaremos o conjunto de dados cats_vs_dogs novamente com rótulos e metadados.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Em vez de uma imagem de gato, usaremos a imagem de um cachorro e aplicaremos várias técnicas de aumento.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Criaremos a função visualize para exibir a diferença entre a imagem original e a imagem aumentada.
A função é bastante simples. Ele usa a imagem original e a função de aumento como entrada e exibe a diferença usando matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Como você pode ver, invertemos a imagem da esquerda para a direita usando a função tf.image. Ele é muito mais simples do que o keras.Sequential.
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Vamos converter a imagem em escala de cinza usando `tf.image.rgb_to_grayscale`.
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Você também pode ajustar a saturação em um fator de 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Ajuste o brilho fornecendo um fator de brilho.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Corte a imagem a partir do centro usando uma fração central de 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Gire a imagem em 90 graus usando a função `tf.image.rot90`.
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Assim como as camadas do Keras, o tf.image também tem funções de aumento aleatório. No exemplo abaixo, aplicaremos o brilho aleatório à imagem e exibiremos vários resultados.
Como você pode ver, a primeira imagem é um pouco mais escura, e as duas imagens seguintes são mais claras.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Assim como o keras, podemos aplicar uma função de aumento de dados a todo o conjunto de dados usando Dataset.map.
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)O Keras ImageDataGenerator é ainda mais simples. Ele funciona melhor quando você está carregando dados de um diretório local ou CSV.
No exemplo, faremos o download e carregaremos um pequeno conjunto de dados CIFAR10 da biblioteca de conjuntos de dados padrão do Keras.
Depois disso, aplicaremos o aumento usando o `keras.preprocessing.image.ImageDataGenerator`. A função girará aleatoriamente, alterará a altura e a largura e inverterá horizontalmente as imagens.
Por fim, ajustaremos o ImageDataGenerator ao conjunto de dados de treinamento e exibiremos seis imagens com aumento aleatório.
Observação: o tamanho da imagem é 32x32, portanto, temos uma tela de baixa resolução.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
Nesta seção, aprenderemos sobre outras ferramentas de código aberto que você pode usar para executar várias técnicas de aumento de dados e melhorar o desempenho do modelo.
A transformação de imagens está disponível no módulo torchvision.transforms. De forma semelhante ao Keras, você pode adicionar camadas de transformação no torch.nn.Sequential ou aplicar uma função de aumento separadamente no conjunto de dados.
O Augmentor é um pacote Python para aumento de imagens e geração de imagens artificiais. Você pode realizar distorção de perspectiva, distorções elásticas, rotação, cisalhamento, corte e espelhamento. O Augmentor também vem com a funcionalidade básica de pré-processamento de imagens.
O Albumentations é uma ferramenta Python rápida e flexível para aumentar imagens. Ele é amplamente usado em competições de aprendizado de máquina, no setor e em pesquisas para melhorar o desempenho de redes neurais convolucionais profundas.
Imgaug é uma ferramenta de código aberto para aumento de imagens. Ele oferece suporte a uma ampla variedade de técnicas de aumento, como ruído gaussiano, contraste, nitidez, corte, afinidade e inversão. Ele tem uma interface estocástica simples, porém avançada, e vem com pontos-chave, caixas delimitadoras, mapas de calor e mapas de segmentação.
O OpenCV é uma enorme biblioteca de código aberto para visão computacional, aprendizado de máquina e processamento de imagens. Geralmente, ele é usado na criação de aplicativos em tempo real. Você pode usar o OpenCV para aumentar imagens e vídeos sem complicações.
Uma plataforma de integração de dados para pipelines de dados ETL/ELT que conectam várias fontes de dados a destinos como data warehouses e lagos. Ele facilita a movimentação de dados não estruturados e semiestruturados para bancos de dados vetoriais e grandes estruturas de modelos de linguagem para aplicativos de IA.
O LangChain é uma estrutura de orquestração para o desenvolvimento de aplicativos de IA generativa alimentados por grandes modelos de linguagem (LLMs). Ele permite que as empresas carreguem dados proprietários nos LLMs, aumentando o valor derivado da IA generativa.
As funções de aumento de imagem fornecidas pelo Tensorflow e pelo Keras são convenientes. Você só precisa adicionar uma camada de aumento, tf.image ou ImageDataGenerator para realizar o aumento. Além das estruturas de aprendizagem profunda, você pode usar ferramentas independentes, como Augmentor, Albumentations, OpenCV e Imgaug, para realizar o aumento de dados.
Neste tutorial, aprendemos sobre as vantagens, limitações, aplicativos e técnicas de aumento de dados. Além disso, aprendemos a aplicar o aumento de imagens no conjunto de dados de cães e gatos usando o Keras e o Tensorflow. Se você estiver interessado em saber mais sobre processamento de imagens, confira a faixa de habilidades Processamento de imagens com Python. Ele ensinará a você os conceitos básicos de transformação e manipulação de imagens, análise de imagens médicas e processamento avançado de imagens usando o Keras.
Principais cursos
Curso
Curso
Curso
blog
Elena Kosourova
15 min
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Vidhi Chugh
